AlphaGo在对阵Lee Sedol的比赛中是否有机会:这位职业球员的意见和评分
Google的专业比赛第9场和AI将于3月举行
 在亚洲棋盘游戏中,没有计算机能够击败专业玩家。关键在于游戏的功能:位置过多,很难用算法描述人类的直觉。直到1月27日,世界都持类似观点。几天前,Google 发布了DeepMind部门的研究数据。它谈到了AlphaGo系统,该系统去年10月在五场比赛中有五场击败了职业第二手Dan Fan。但是,专业的玩家和熟人对游戏的质量有疑问。Hui是三届冠军,但他是欧洲冠军,比赛水平不太高。不仅表现出AlphaGo功能的玩家选择会引发疑问,而且游戏中还会有一些动作。
在亚洲棋盘游戏中,没有计算机能够击败专业玩家。关键在于游戏的功能:位置过多,很难用算法描述人类的直觉。直到1月27日,世界都持类似观点。几天前,Google 发布了DeepMind部门的研究数据。它谈到了AlphaGo系统,该系统去年10月在五场比赛中有五场击败了职业第二手Dan Fan。但是,专业的玩家和熟人对游戏的质量有疑问。Hui是三届冠军,但他是欧洲冠军,比赛水平不太高。不仅表现出AlphaGo功能的玩家选择会引发疑问,而且游戏中还会有一些动作。演算法
长期以来,郭一直被认为是一种训练比赛的游戏,由于巨大的搜索空间和动作选择的复杂性,人工智能很难实现。围棋属于具有完美信息的游戏类,也就是说,玩家知道其他玩家之前所做的所有举动。解决找到游戏结果的问题的解决方案涉及在包含大约b d个可能移动的搜索树中计算最佳值函数。这里b是每个位置的正确移动次数,d是游戏时间。对于国际象棋,这些值为b≈35和d≈80,因此不可能进行完全搜索。因此,对图形的位置进行评估,然后在搜索中考虑评估。 1996年,计算机首次在国际象棋比赛中赢得冠军,而自2005年以来,没有冠军能击败计算机。对于go b≈250,d≈150。在标准板上,石头的可能位置比象棋中的googol(10 100)倍多。可能的位置数量大于宇宙中的原子。使情况复杂化的是,由于游戏的复杂性,很难预测状态的价值。两个玩家将两种颜色的石头放在一定大小的板上,标准区域为19×19线。规则在细节上各有不同,但游戏的主要目标很简单:您需要用比对手色泽更大的彩色石头来挡住棋盘上更大的区域。现有程序可以在业余级别播放。他们使用蒙特卡罗树中的搜索来评估搜索树中每个状态的值。该计划还包括预测强大参与者行动的政策。最近,深度卷积神经网络已经能够在人脸识别和图像分类中取得良好的效果。在Google,AI甚至学会了自己玩49款古老的Atari游戏。在AlphaGo中,类似的神经网络会解释棋子在棋盘上的位置,这有助于评估和选择移动。在Google,研究人员采用以下方法:他们使用了价值网络和政策网络。然后,这些深层神经网络在一组人的聚会上以及在针对他们的副本的游戏中都受到训练。搜索也是一种新方法,将蒙特卡洛方法与政治和价值网络相结合。神经网络训练方案和体系结构。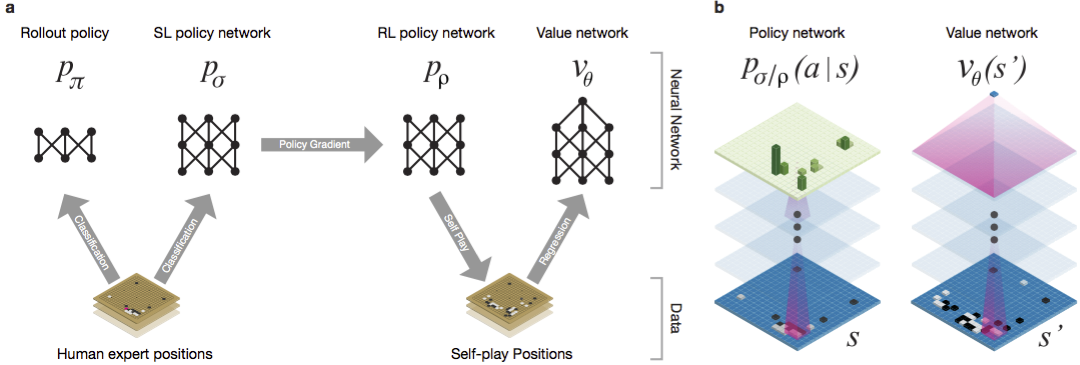 在机器学习的多个阶段对神经网络进行了训练。首先,直接利用人类参与者的行动对政策网络进行受控培训。另一个政策网络已加强学习。第二个则与第一个一起发挥作用并对其进行了优化,以使政策转变为胜利,而不仅仅是预测行动。最后,进行了培训,并通过价值网络进行了强化,该网络可以预测政策网络所玩游戏的获胜者。最终结果是AlphaGo,它是蒙特卡洛方法与政治和价值网络的结合。正确预测下一步行动的结果在57%的情况下得以实现。在AlphaGo之前,最好的结果是44%。来自KGS服务器的16万个游戏(拥有2940万个位置)被用作培训的输入。参加了从第六届到第九届的球员聚会。分配了100万个职位进行测试,培训本身进行了2840万个职位。网络策略和价值观的强度和准确性。
为了使算法起作用,它们需要比传统搜索大几个数量级的计算能力。 AlphaGo是一个异步多线程程序,它在中央处理器的内核上执行仿真,并在视频芯片上运行策略和值的网络。最终版本看起来像一个运行在48个处理器上的40线程应用程序(可能意味着独立的内核甚至是超线程)和8个图形加速器。还创建了一个分布式版本的AlphaGo,该版本使用多台计算机,40个搜索流,1202个内核和176个视频加速器。
在机器学习的多个阶段对神经网络进行了训练。首先,直接利用人类参与者的行动对政策网络进行受控培训。另一个政策网络已加强学习。第二个则与第一个一起发挥作用并对其进行了优化,以使政策转变为胜利,而不仅仅是预测行动。最后,进行了培训,并通过价值网络进行了强化,该网络可以预测政策网络所玩游戏的获胜者。最终结果是AlphaGo,它是蒙特卡洛方法与政治和价值网络的结合。正确预测下一步行动的结果在57%的情况下得以实现。在AlphaGo之前,最好的结果是44%。来自KGS服务器的16万个游戏(拥有2940万个位置)被用作培训的输入。参加了从第六届到第九届的球员聚会。分配了100万个职位进行测试,培训本身进行了2840万个职位。网络策略和价值观的强度和准确性。
为了使算法起作用,它们需要比传统搜索大几个数量级的计算能力。 AlphaGo是一个异步多线程程序,它在中央处理器的内核上执行仿真,并在视频芯片上运行策略和值的网络。最终版本看起来像一个运行在48个处理器上的40线程应用程序(可能意味着独立的内核甚至是超线程)和8个图形加速器。还创建了一个分布式版本的AlphaGo,该版本使用多台计算机,40个搜索流,1202个内核和176个视频加速器。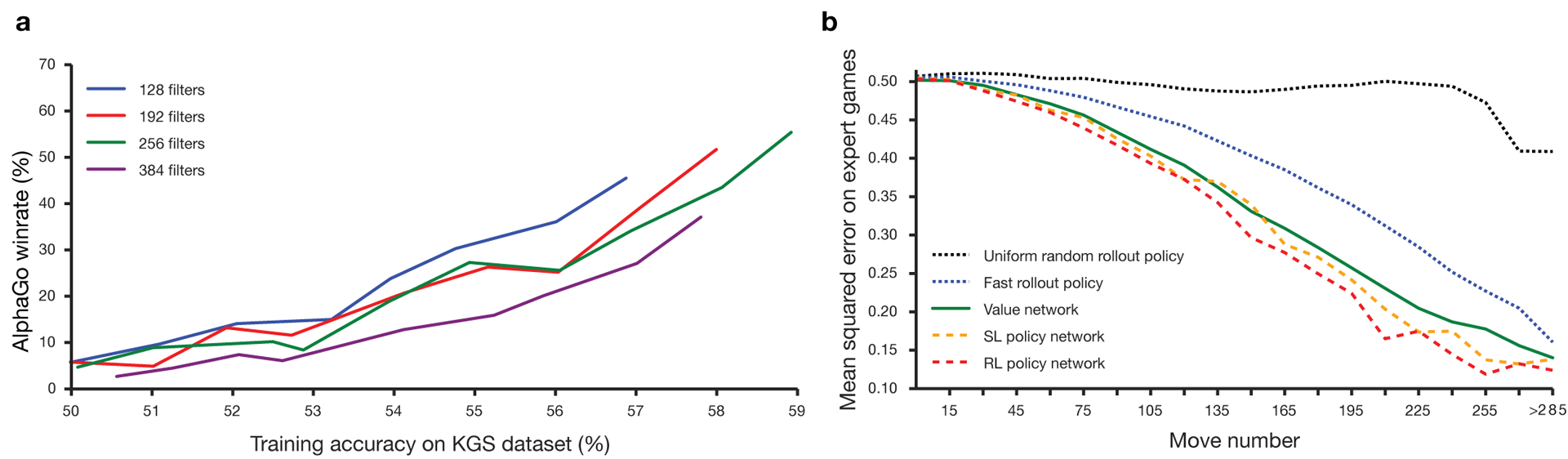 完整的DeepMind报告可在文档中找到。在AlphaGo中搜索Monte Carlo。
为了评估AlphaGo的能力,针对该程序的其他版本以及其他类似产品进行了内部匹配。其中包括与诸如Crazy Stone和Zen之类的流行商业程序以及最强大的开源项目Pachi和Fuego进行的比较。它们全部基于高性能的蒙特卡洛算法。而且AlphaGo与非Monte Carlo GnuGo相比。程序每次移动5秒。比较了在一台计算机上运行的AlphaGo和该算法的分布式版本。
完整的DeepMind报告可在文档中找到。在AlphaGo中搜索Monte Carlo。
为了评估AlphaGo的能力,针对该程序的其他版本以及其他类似产品进行了内部匹配。其中包括与诸如Crazy Stone和Zen之类的流行商业程序以及最强大的开源项目Pachi和Fuego进行的比较。它们全部基于高性能的蒙特卡洛算法。而且AlphaGo与非Monte Carlo GnuGo相比。程序每次移动5秒。比较了在一台计算机上运行的AlphaGo和该算法的分布式版本。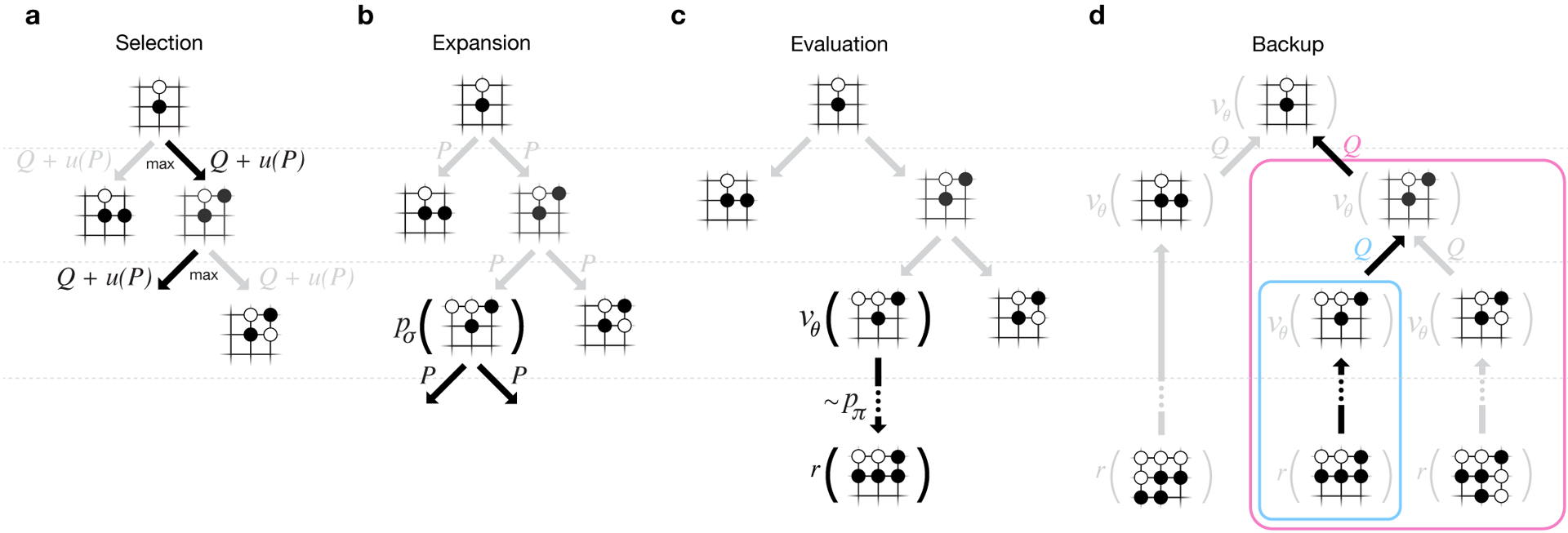 根据开发人员的说法,结果表明AlphaGo比以前的任何go程序都要强大得多。 AlphaGo赢得495场比赛中的494场,占与其他同类产品比赛的99.8%。允许规则赔率,盘口:在球场上,你可以设置9个黑子变白。但是,即使有4个障碍球,AlphaGo单机游戏也分别对付Crazy Stone,Zen和Pachi分别赢得了77%,86%和99%的时间。 AlphaGo的分布式版本明显更强大:在77%的游戏中,它击败了单机版本,在100%的游戏中击败了所有其他程序。AlphaGo与其他程序。
根据开发人员的说法,结果表明AlphaGo比以前的任何go程序都要强大得多。 AlphaGo赢得495场比赛中的494场,占与其他同类产品比赛的99.8%。允许规则赔率,盘口:在球场上,你可以设置9个黑子变白。但是,即使有4个障碍球,AlphaGo单机游戏也分别对付Crazy Stone,Zen和Pachi分别赢得了77%,86%和99%的时间。 AlphaGo的分布式版本明显更强大:在77%的游戏中,它击败了单机版本,在100%的游戏中击败了所有其他程序。AlphaGo与其他程序。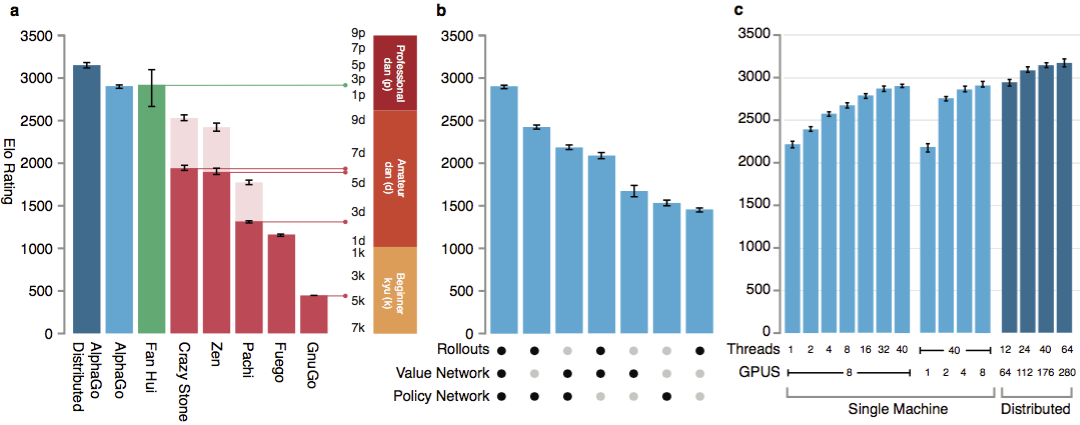 最后,将创建的产品与人进行比较。职业玩家2 dan与2013年,2014年和2015年欧洲围棋锦标赛获胜者Al Hui的分布式版本对抗。参加比赛的有英国围棋联合会的法官和《自然》杂志的编辑。从2015年10月5日到9日,举行了5场比赛。他们所有人都赢得了Google DeepMind开发算法。正是这些游戏促使人们宣称,计算机是第一款能够击败专业玩家的计算机。除5个正式政党外,还举行了5个非官方政党,这不算在内。范赢得了其中的两个。可记录移动的五场比赛,观看在Web控件和YouTube上的视频。
最后,将创建的产品与人进行比较。职业玩家2 dan与2013年,2014年和2015年欧洲围棋锦标赛获胜者Al Hui的分布式版本对抗。参加比赛的有英国围棋联合会的法官和《自然》杂志的编辑。从2015年10月5日到9日,举行了5场比赛。他们所有人都赢得了Google DeepMind开发算法。正是这些游戏促使人们宣称,计算机是第一款能够击败专业玩家的计算机。除5个正式政党外,还举行了5个非官方政党,这不算在内。范赢得了其中的两个。可记录移动的五场比赛,观看在Web控件和YouTube上的视频。来自职业选手的批评
质疑职业球员的选择和冠军的弱势。选择的规则也不清楚:每场比赛一个小时,而不是严肃的比赛几个小时。但是,格式是由Hui自己选择的。 3月,AlphaGo将与Lee Sedola比赛。该算法能否击败被认为是世界上最佳选手之一的第九届韩国职业选手?赌注是一百万美元。如果某人获胜,那么李·塞多尔将获得奖励;如果该算法获胜,他将去慈善事业。研究人员说,在与人类的10月战斗中,与Kasparov进行的历史性比赛中,AlphaGo系统所考虑的位置比深蓝少数千倍。相反,该程序使用策略网络来进行更明智的选择,并使用值网络来更准确地衡量头寸。研究人员说,也许这种方法更接近人们的游戏方式。此外,深蓝分级系统是手动编程的,而AlphaGo神经网络是使用监督学习和强化学习的通用算法直接从游戏中训练的。Lee Sedoll将在三月与AlphaGo对抗。 职业球员有不同的观点。在某些人看来,Google特别选择了不是一个非常强大的公司,有人确信Sedol会在今年3月输掉比赛。金孟旺(第9丹)是目前英语中最强的职业球员之一,他认为范慧没有发挥出全力。在视频的第51分钟,他给出了第二期的具体示例。 Kim说,Fan可能在测试计算机性能方面都表现较弱。 Mengvan 承认这AlphaGo -令人震惊的强大的程序,但它是不可能有能力击败李世乭。比赛裁判托比·曼宁( Toby Manning)告诉英国围棋杂志。他分析了所有五场比赛,并强调了一些要点。 AlphaGo在第二,第三和第四局中犯了错误,但Fan并未使用它们。三届欧洲冠军都用自己的答案。该杂志上的文章以AlphaGo给出的总体正面评价作为结尾:该程序很强大,但尚不清楚有多少。另外,在准备材料时,我收到了来自俄罗斯专业人士和爱好者的评论。亚历山大·迪纳斯坦(喀山),第三名(专业),七次获得欧洲冠军:
职业球员有不同的观点。在某些人看来,Google特别选择了不是一个非常强大的公司,有人确信Sedol会在今年3月输掉比赛。金孟旺(第9丹)是目前英语中最强的职业球员之一,他认为范慧没有发挥出全力。在视频的第51分钟,他给出了第二期的具体示例。 Kim说,Fan可能在测试计算机性能方面都表现较弱。 Mengvan 承认这AlphaGo -令人震惊的强大的程序,但它是不可能有能力击败李世乭。比赛裁判托比·曼宁( Toby Manning)告诉英国围棋杂志。他分析了所有五场比赛,并强调了一些要点。 AlphaGo在第二,第三和第四局中犯了错误,但Fan并未使用它们。三届欧洲冠军都用自己的答案。该杂志上的文章以AlphaGo给出的总体正面评价作为结尾:该程序很强大,但尚不清楚有多少。另外,在准备材料时,我收到了来自俄罗斯专业人士和爱好者的评论。亚历山大·迪纳斯坦(喀山),第三名(专业),七次获得欧洲冠军:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC),在该框架中始终会进行计算机程序竞赛。俄罗斯围棋协会邀请了所有实力最强的节目参加比赛。如果他们接受邀请,那么Google和Facebook程序可能将首次参加本次比赛。与竞争对手不同,后者正在遵循诚实的道路。DarkForest机器人在KGS服务器上玩数千种游戏。最强大的版本已接近服务器上的第六个版本。这是一个很好的水平。范辉和他这个级别的球员-这大约是服务器上的第8个丹(可能有9个丹)。区别大约有两个障碍。由于存在这种差异,程序有时可以真正打败一个人。如果相等,则大约十个批次中的一个。
俄罗斯围棋协会副主席马克西姆·波多利亚克(圣彼得堡):, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
游戏的爱好者亚历山大·克兰诺夫(莫斯科):由于我的专业活动,我“从另一侧”非常了解情况。
2012年,机器学习总体上发生了质的飞跃。用于训练的数据量,算法的水平和训练的能力已经达到了这样的水平,使得人工神经网络(作为长期的原理而发展)开始产生令人赞叹的结果。
训练神经网络之间的根本区别在于,不需要为它们提供输入因子(例如,使用go时,请说明哪种形式是好的)。在极限范围内,即使是规则也无法向他们解释。最主要的是给出大量正面(获胜方的动作)和负面(败方的动作)示例。网络将学习自己。
, , . . : , , ( ) , .
, .
, , , . . . . , , .
李·塞多尔本人说的
职业围棋选手不是争夺世界冠军,而是争夺冠军。大师的认可度和地位取决于他一年中所能获得的头衔数量。李·塞多尔(Lee Sedol)是世界上五个最强的棋手之一,今年三月他将不得不与AlphaGo系统搏斗。韩国冠军本人预计他将以4-1或5-0的比分获胜。但李说,在2-3年后,谷歌将要报仇,然后带有更新版本的AlphaGo的游戏将变得更加有趣。
创建这种算法的任务提出了关于什么是学习和思考的新问题。正如埃梅里亚诺夫(M. Emelyanov)提醒的那样,按照古代汉语分类,从上至下的第三级技能(“别针”)被称为“完全清晰”。如此高的游戏水平表明,决策是凭直觉做出的,几乎没有选择权。20世纪最强大的大师之一,郭世根(Guo Seigen)表示,在他看来,只要拿走两到三个障碍球,他就会赢得“上帝”的胜利。Seigan认为他几乎已经达到了了解游戏的极限。神经网络可以做到这一点吗?也许人类的直觉是天生就有的算法?作者感谢Alexander Dinerstein和公众go_secrets对本文的评论和帮助。Source: https://habr.com/ru/post/zh-CN389825/
All Articles