 碰巧,使用微控制器的主要语言是C。上面写了许多大型项目。但是生活不会停滞不前。长期以来,现代开发工具在为嵌入式系统开发软件时便能够使用C ++。但是,这种方法仍然很少。不久前,我在另一个项目上工作时尝试使用C ++。我将在本文中讨论这种经验。
碰巧,使用微控制器的主要语言是C。上面写了许多大型项目。但是生活不会停滞不前。长期以来,现代开发工具在为嵌入式系统开发软件时便能够使用C ++。但是,这种方法仍然很少。不久前,我在另一个项目上工作时尝试使用C ++。我将在本文中讨论这种经验。参赛作品
我对微控制器的大部分工作都与C有关。首先,这是客户的要求,然后就成了一种习惯。同时,在Windows应用程序中,首先在此使用C ++,然后在一般情况下使用C#。很长时间以来,对C或C ++一直没有疑问。甚至发布了带有ARM的C ++支持的Keil MDK的下一版本,也丝毫不困扰我。如果您查看Keil演示项目,那么所有内容都用C编写。与此同时,C ++与Blinky项目一起移到了单独的文件夹中。 CMSIS和LPCOpen也是用C编写的。如果“每个人”都使用C,则有一些原因。但是,.Net Micro Framework发生了很大变化。如果没有人知道,那么这是一个.Net实现,可让您在Visual Studio中使用C#编写用于微控制器的应用程序。您可以在中了解有关他的更多信息这些文章。因此,.Net Micro Framework是使用C ++编写的。对此印象深刻,我决定尝试用C ++编写另一个项目。我必须马上说,我没有找到任何支持C ++的明确参数,但是这种方法有一些有趣和有用的要点。C和C ++项目之间有什么区别?
C和C ++之间的主要区别之一是第二种是面向对象的语言。众所周知的封装,多态和继承在这里很常见。C是一种过程语言。只有功能和过程,并且对于代码的逻辑分组,使用了模块(一对.h + .c)。但是,如果仔细研究微控制器中C的用法,您会看到通常的面向对象方法。让我们看一下使用MCB1000的Keil示例中的LED进行工作的代码(Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
如果仔细观察,可以与OOP打个比方。LED是具有一个公共常量,构造函数,3个公共方法和一个私有字段的对象:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
尽管代码是用C编写的,但它还是使用对象编程的范例。 .C文件是一个对象,它允许您封装在.h文件中描述的公共方法的实现机制中。但是这里没有继承,因此也有多态性。我遇到的项目中的大多数代码都是用相同的样式编写的。如果使用了OOP方法,那为什么不使用完全支持它的语言呢?同时,大体上,当切换到C ++时,只会改变语法,而不会改变开发原理。考虑另一个例子。假设我们有一个使用通过I2C连接的温度传感器的设备。但是该设备的新版本发布了,并且同一传感器现在已连接到SPI。怎么办 必须同时支持该设备的第一版和第二版,这意味着代码必须灵活地考虑这些更改。在C语言中,您可以使用#define预定义来避免编写两个几乎相同的文件。举个例子#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
等等。在C ++中,您可以更优雅地解决此问题。制作界面class ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
并实现2class Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
然后根据修订版本使用该实现:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
似乎C和C ++代码之间的差异不是很大。面向对象的选项看起来更加麻烦。但这使您可以做出更灵活的决定。使用C时,可以区分两个主要解决方案:- 如上所示使用#define。此选项不是很好,因为它“侵蚀”了模块的责任。事实证明,他负责该项目的多个修订。当有许多这样的文件时,很难维护它们。
- 2 , C++. “” , . , #ifdef. , , . , . , , .
多态性的使用给出了更漂亮的结果。一方面,每个类都解决了一个明显的原子问题,另一方面,代码不乱且易于阅读。在第一种情况和第二种情况下,仍必须在修订版上“分支”代码,但是使用多态性可以更轻松地在程序层之间转移分支位置,而不会用#ifdef重载代码。使用多态可以使做出更有趣的决定变得容易。假设发布了一个新版本,其中安装了两个温度传感器。只需进行很少的更改即可使用相同的代码,您只需使用Init(&temperature)方法即可实时选择SPI和I2C实现。该示例非常简化,但是在一个实际项目中,我使用了相同的方法在两个不同的物理数据传输接口之上实现了相同的协议。这样可以轻松在设备设置中选择接口。但是,使用上述所有方法,使用C和C ++之间的差异仍然不是很大。与OOP相关的C ++的优势不是那么明显,而是来自“业余”类别。但是,在微控制器中使用C ++存在相当严重的问题。为什么使用C ++很危险?
C和C ++之间的第二个重要区别是内存使用情况。 C语言大部分是静态的。所有功能和过程都有固定的地址,并且仅在必要时才进行处理。 C ++是一种更具动态性的语言。通常,它的使用意味着需要进行分配和释放内存的积极工作。这就是C ++的危险。微控制器的资源很少,因此对其进行控制非常重要。对RAM的无节制使用会严重破坏那里存储的数据,而且程序工作中的此类“奇迹”是没人能想到的。许多开发人员都遇到过此类问题。如果仔细查看上面的示例,可以注意到类没有构造函数和析构函数。这是因为它们从未动态创建。使用动态内存时(以及使用new时),始终会调用malloc函数,该函数从堆中分配所需的字节数。即使您仔细考虑(尽管这很困难)并控制内存的使用,也可能会遇到碎片问题。一束可以表示为一个数组。例如,我们为其选择20个字节: 每次分配内存时,将扫描整个内存(从左到右或从右到左-这并不重要),以查看是否存在给定数量的未占用字节。此外,这些字节都应该位于附近:
每次分配内存时,将扫描整个内存(从左到右或从右到左-这并不重要),以查看是否存在给定数量的未占用字节。此外,这些字节都应该位于附近: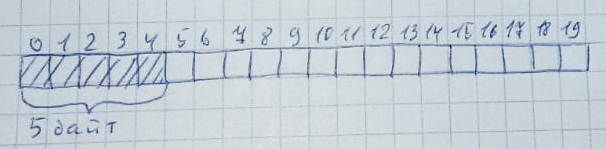 当不再需要内存时,它将返回其原始状态:当有足够的可用字节,但是没有将它们排成一行时,很容易发生这种情况。分配10个区域,每个区域2个字节:
当不再需要内存时,它将返回其原始状态:当有足够的可用字节,但是没有将它们排成一行时,很容易发生这种情况。分配10个区域,每个区域2个字节: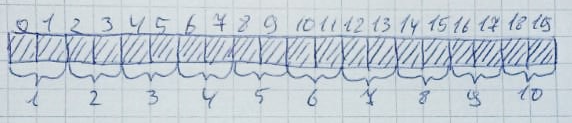 然后,将释放2、4、6、8、10个区域:
然后,将释放2、4、6、8、10个区域: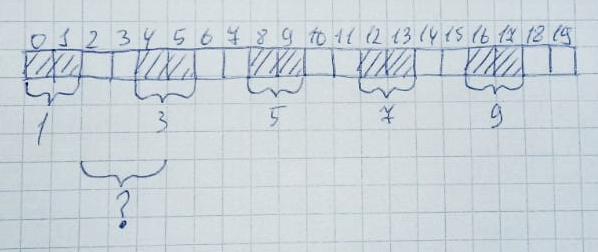 形式上,整个堆的一半(10个字节)保持空闲。但是,分配3个字节的内存区域仍将失败,因为该阵列连续没有3个空闲单元。这称为内存碎片。在没有内存虚拟化的系统上处理此问题非常困难。特别是在大型项目中。这种情况可以很容易地模拟。我是在Keil mVision的LPC11C24微控制器上完成此操作的。将堆大小设置为256个字节:
形式上,整个堆的一半(10个字节)保持空闲。但是,分配3个字节的内存区域仍将失败,因为该阵列连续没有3个空闲单元。这称为内存碎片。在没有内存虚拟化的系统上处理此问题非常困难。特别是在大型项目中。这种情况可以很容易地模拟。我是在Keil mVision的LPC11C24微控制器上完成此操作的。将堆大小设置为256个字节: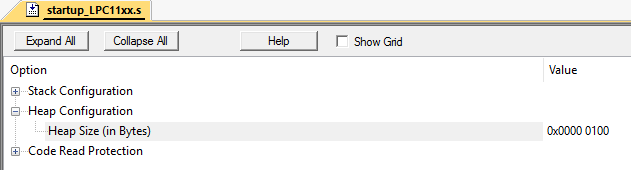 假设我们有2个类:
假设我们有2个类:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
如您所见,bar类将比foo占用更多的内存。bar类的14个实例放置在堆中,而foo类的实例不再适合:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
如果仅创建7个bar实例,则foo也将正常创建:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
但是,如果首先创建bar的14个实例,然后删除0、2、4、6、8、10和12个实例,则由于堆的碎片化,foo将无法分配内存:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
事实证明,您不能完全使用C ++,这是一个很大的缺点。从体系结构的角度来看,尽管C ++优于C,但它并不重要。结果,向C ++的过渡不会带来明显的好处(尽管也没有很大的负面影响)。因此,由于差异很小,语言的选择将仍然只是开发人员的个人喜好。但是对于我自己,我发现使用C ++有一个重要的积极意义。事实是,使用正确的C ++方法,可以在Visual Studio中用单元测试轻松涵盖微控制器的代码。C ++的一大优点是可以使用Visual Studio。
就我个人而言,微控制器的代码测试主题一直非常复杂。自然地,会以各种可能的方式对代码进行检查,但是创建完整的自动测试系统始终需要巨额成本,因为必须组装硬件支架并为其编写专用固件。尤其是涉及由数百个设备组成的分布式物联网系统时。当我开始用C ++编写项目时,我立即想尝试将代码放在Visual Studio中,并仅将Keil mVision用于调试。首先,在Visual Studio中,它是一个功能强大且方便的代码编辑器,其次,在Keil mVision中,它与版本控制系统完全不方便集成,而在Visual Studio中,它都是自动完成的。第三,我希望我可以设法用单元测试覆盖至少部分代码,Visual Studio也很好地支持了单元测试。第四,这是Resharper C ++的外观-一种使用C ++代码的Visual Studio扩展,因此,您可以提前避免许多潜在的错误并监视代码的样式。在Visual Studio中创建项目并将其连接到版本控制系统不会引起任何问题。但是我不得不修改单元测试。从硬件抽象的类(例如,协议解析器)易于测试。但是我想要更多!在外围项目中,我使用Keil头文件。例如,对于LPC11C24,它是LPC11xx.h。这些文件描述了根据CMSIS标准的所有必需的寄存器。通过#define直接定义特定的寄存器:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
事实证明,如果您正确地覆盖了寄存器并创建了两个存根,那么使用外围设备的代码就可以很好地编译到VisualStudio中。不仅如此,如果您创建一个静态类并将其字段指定为寄存器地址,您将获得一个成熟的微控制器仿真器,该仿真器可让您全面测试甚至使用外设:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
然后执行以下操作:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
这样,您只需很少的更改就可以编译和测试VisualStudio中微控制器的所有项目代码。在用C ++开发项目的过程中,我编写了300多个测试,涵盖了纯硬件方面以及从硬件中提取的代码。而且,预先发现了大约20个相当严重的错误,由于项目的规模,如果没有自动测试,将很难发现这些错误。结论
在使用微控制器时使用或不使用C ++是一个相当复杂的问题。我在上面已经表明,一方面,成熟的OOP的体系结构优势不是很大,并且不能完全与一堆对象一起工作是一个很大的问题。鉴于这些方面,使用微控制器工作的C和C ++之间没有太大区别,开发人员的个人偏好很可能证明它们之间的选择是合理的。但是,我设法在与Visaul Studio一起使用C ++方面找到了很大的积极点。由于版本控制系统的完整工作,使用完整的单元测试(包括用于外围设备的测试)以及Visual Studio的其他优点,因此,您可以显着提高开发的可靠性。希望我的经验对您有所帮助,并能帮助某人提高工作效率。更新:在评论的英文版本,本文介绍了这个话题有用的链接: