AI在素材中产生逼真的声音
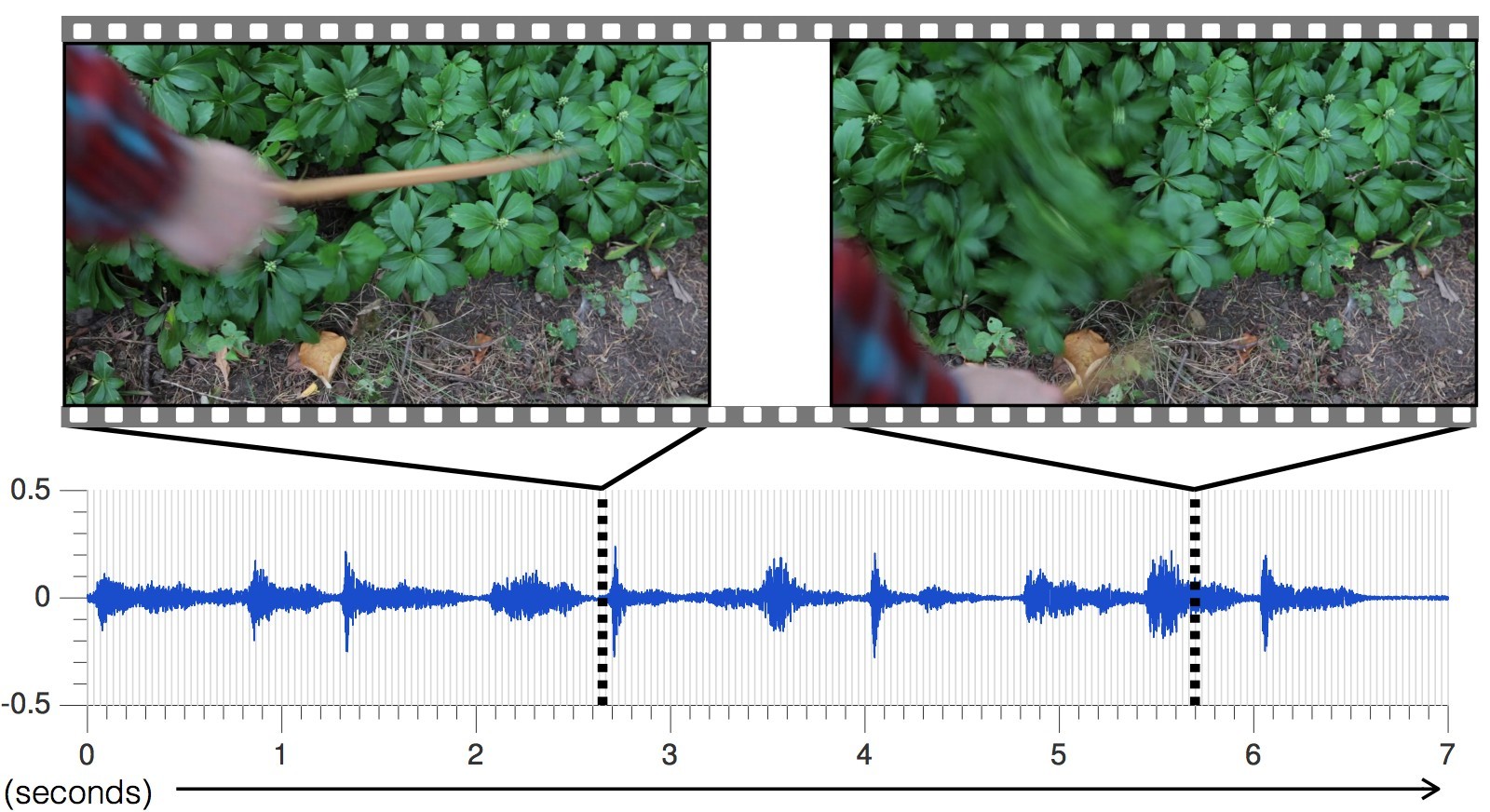 的员工信息与人工智能实验室(CSAIL)麻省理工学院和谷歌研究部设计了训练神经网络,以健全的任意视频,生成逼真的声音和预测对象的属性。该程序分析视频,识别物体,物体的运动和接触类型-震动,滑动,摩擦等。根据此信息,它会产生一种声音,在40%的情况下,一个人认为比真实的声音更真实。科学家建议,这种发展将广泛用于电影院和电视中,以从没有声音的视频序列中产生声音效果。此外,它对于训练机器人更好地了解世界的特性可能很有用。
的员工信息与人工智能实验室(CSAIL)麻省理工学院和谷歌研究部设计了训练神经网络,以健全的任意视频,生成逼真的声音和预测对象的属性。该程序分析视频,识别物体,物体的运动和接触类型-震动,滑动,摩擦等。根据此信息,它会产生一种声音,在40%的情况下,一个人认为比真实的声音更真实。科学家建议,这种发展将广泛用于电影院和电视中,以从没有声音的视频序列中产生声音效果。此外,它对于训练机器人更好地了解世界的特性可能很有用。, — , , , , . , — , .
. « , , », —
(Andrew Owens), , ,
在arXiv.org上公开可用。科学工作的介绍将在本月在拉斯维加斯举行的机器视觉和模式识别(CVPR)年度会议上进行。科学家们选择了977个视频,其中人们对周围的物体进行动作,这些物体由各种材料组成:刮擦,用棍子殴打等。这些视频总共包含46,577个动作。 CSAIL学生手动标记所有动作,指示材料的类型,接触的位置,动作的类型(冲击/刮擦/其他)以及材料或物体的反应类型(变形,静态形状,剧烈运动等)。带有声音的视频用于训练神经网络,而手动放置的标签仅用于分析训练神经网络的结果,而不用于训练神经网络。 神经网络分析了与对象互动的每种类型相对应的声音特征-音量,音高和其他特征。在训练期间,系统逐帧研究视频,分析该帧中的声音,并在已累积的数据库中找到与最相似声音的匹配项。最重要的是教神经网络将声音扩展为帧。
神经网络分析了与对象互动的每种类型相对应的声音特征-音量,音高和其他特征。在训练期间,系统逐帧研究视频,分析该帧中的声音,并在已累积的数据库中找到与最相似声音的匹配项。最重要的是教神经网络将声音扩展为帧。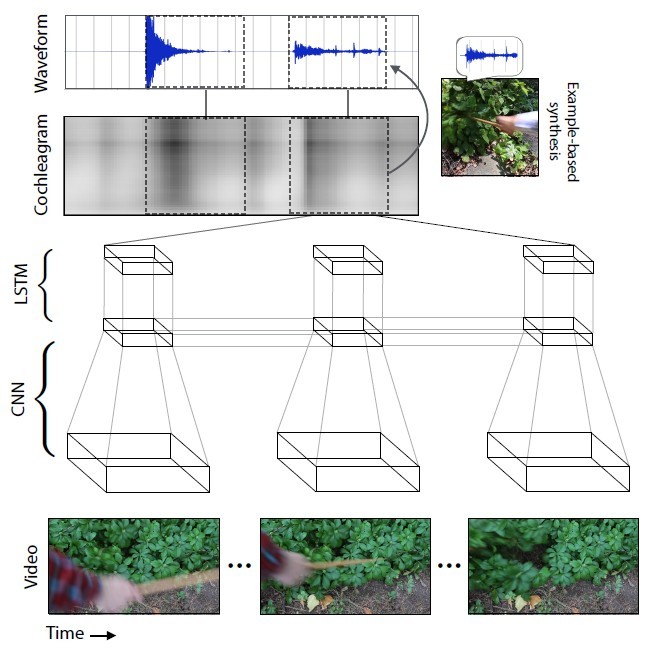 每增加一个新视频,声音预测的准确性就会提高。与真实场景相比,神经网络针对不同场景生成的声音,
每增加一个新视频,声音预测的准确性就会提高。与真实场景相比,神经网络针对不同场景生成的声音, 因此,神经网络学会了准确地预测各种声音的最多样化声音:从敲碎石头到沙哑的常春藤。卡内基大学机器人学助理教授Abhinav Gupta 表示:
“人工智能领域的研究人员当前的方法仅关注五种感官之一:机器视觉专家研究视觉图像,语音识别专家研究声音,等等。” 梅隆“这项研究是朝正确方向迈出的一步,模仿人们的学习过程就像整合声音和视觉一样。”为了测试AI的有效性,科学家在Amazon Mechanical Turk上进行了在线研究,要求参与者比较特定视频的声音的两种选择,并确定哪种声音是真实的而哪些不是。实验的结果是,人工智能成功欺骗了40%的人。但是,据论坛上的一些评论家说,欺骗一个人并不那么困难,因为现代人从故事片和计算机游戏中获得了关于世界声像的很大一部分知识。电影和游戏的音域是由专家使用标准样本的集合组成的。也就是说,我们不断听到相同的事情。在一项在线实验中,五分之二的情况下,人们认为程序产生的声音比视频中的真实声音更真实。这是比其他用于合成逼真的声音的方法更好的结果。
因此,神经网络学会了准确地预测各种声音的最多样化声音:从敲碎石头到沙哑的常春藤。卡内基大学机器人学助理教授Abhinav Gupta 表示:
“人工智能领域的研究人员当前的方法仅关注五种感官之一:机器视觉专家研究视觉图像,语音识别专家研究声音,等等。” 梅隆“这项研究是朝正确方向迈出的一步,模仿人们的学习过程就像整合声音和视觉一样。”为了测试AI的有效性,科学家在Amazon Mechanical Turk上进行了在线研究,要求参与者比较特定视频的声音的两种选择,并确定哪种声音是真实的而哪些不是。实验的结果是,人工智能成功欺骗了40%的人。但是,据论坛上的一些评论家说,欺骗一个人并不那么困难,因为现代人从故事片和计算机游戏中获得了关于世界声像的很大一部分知识。电影和游戏的音域是由专家使用标准样本的集合组成的。也就是说,我们不断听到相同的事情。在一项在线实验中,五分之二的情况下,人们认为程序产生的声音比视频中的真实声音更真实。这是比其他用于合成逼真的声音的方法更好的结果。 多数情况下,人工智能用树叶和污垢等材料的声音欺骗了实验的参与者,因为这些声音更复杂,并且不如木头或金属制成的声音“干净”。作为研究的副产品,返回到神经网络的训练中,发现该算法可以通过简单地预测声音来区分软硬材料,准确度为67%。换句话说,机器人可以观察沥青路径和它前面的草,并得出结论,沥青是硬的,草是软的。机器人将通过预测的声音知道这一点,甚至无需踩到沥青和草地上。然后,他可以按自己的意愿行事-通过与数据库核对来测试自己的感受,并在必要时在声音样本库中进行更正。这样,未来,机器人将学习并掌握周围的世界。但是,研究人员仍有许多工作要做以改进技术。现在,神经网络经常被误认为是物体的快速运动,而没有陷入确切的接触时刻。此外,人工智能只能基于直接接触来产生声音,并记录在视频中,而我们周围有如此多的声音并非基于视觉接触:树木的噪音,计算机风扇的嗡嗡声。“真正酷的是模拟以某种方式与素材没有那么密切关系的声音,” 安德鲁·欧文斯( Andrew Owens)说。
多数情况下,人工智能用树叶和污垢等材料的声音欺骗了实验的参与者,因为这些声音更复杂,并且不如木头或金属制成的声音“干净”。作为研究的副产品,返回到神经网络的训练中,发现该算法可以通过简单地预测声音来区分软硬材料,准确度为67%。换句话说,机器人可以观察沥青路径和它前面的草,并得出结论,沥青是硬的,草是软的。机器人将通过预测的声音知道这一点,甚至无需踩到沥青和草地上。然后,他可以按自己的意愿行事-通过与数据库核对来测试自己的感受,并在必要时在声音样本库中进行更正。这样,未来,机器人将学习并掌握周围的世界。但是,研究人员仍有许多工作要做以改进技术。现在,神经网络经常被误认为是物体的快速运动,而没有陷入确切的接触时刻。此外,人工智能只能基于直接接触来产生声音,并记录在视频中,而我们周围有如此多的声音并非基于视觉接触:树木的噪音,计算机风扇的嗡嗡声。“真正酷的是模拟以某种方式与素材没有那么密切关系的声音,” 安德鲁·欧文斯( Andrew Owens)说。Source: https://habr.com/ru/post/zh-CN395243/
All Articles