什么是差异隐私
Google最初使用复杂的随机响应技术来收集Chrome统计信息。苹果会效仿吗?
关于作者。马修·格林(Matthew Green):加密学家,约翰·霍普金斯大学教授,加密系统博客作者,2016年6月14日发布 昨天,在WWDC的演讲中,苹果公司推出了许多用于保护和保护机密数据的新功能,其中包括引起特别关注的……混乱。也就是说,Apple宣布使用一种称为“差异隐私”的新技术(简称DP)来改善收集用户机密数据时的隐私保护。对于大多数人来说,这引起了一个愚蠢的问题:“……是什么?”,因为很少有人听说过差异性隐私,甚至更多地了解它的含义。不幸的是,关于平台运行的秘密成分,苹果公司并不清楚,因此希望将来它将决定发布更多信息。目前,我们所知道的一切都包含在Apple iOS 10 Preview手册中。“从iOS 10开始,Apple使用差异隐私技术来帮助识别大量用户的用户行为模式,而不会危害每个用户的隐私。为了隐藏人的身份,差异性隐私会为特定用户的单个用户行为模板的一小部分样本添加数学噪声。随着越来越多的人显示相同的模式,常见的模式开始出现,这些信息可以告诉我们并改善整体用户体验。在iOS 10中,这项技术将有助于改善QuickType和表情符号提示,Spotlight提示以及Notes中的查找提示。”简而言之,苹果似乎想从您的手机中收集更多数据。基本上,他们这样做是为了改善他们的服务,而不是收集有关每个用户的个人习惯和特征的信息。为了保证这一点,Apple打算使用复杂的统计技术来确保汇总基数(处理完所有信息后计算统计函数的结果)不会散布单个参与者。原则上,这听起来不错。但是,当然,魔鬼总是隐藏在细节中。尽管我们没有这些细节,但现在看来至少应该讨论什么是差异性隐私,如何实现以及对苹果以及您的iPhone意味着什么。
昨天,在WWDC的演讲中,苹果公司推出了许多用于保护和保护机密数据的新功能,其中包括引起特别关注的……混乱。也就是说,Apple宣布使用一种称为“差异隐私”的新技术(简称DP)来改善收集用户机密数据时的隐私保护。对于大多数人来说,这引起了一个愚蠢的问题:“……是什么?”,因为很少有人听说过差异性隐私,甚至更多地了解它的含义。不幸的是,关于平台运行的秘密成分,苹果公司并不清楚,因此希望将来它将决定发布更多信息。目前,我们所知道的一切都包含在Apple iOS 10 Preview手册中。“从iOS 10开始,Apple使用差异隐私技术来帮助识别大量用户的用户行为模式,而不会危害每个用户的隐私。为了隐藏人的身份,差异性隐私会为特定用户的单个用户行为模板的一小部分样本添加数学噪声。随着越来越多的人显示相同的模式,常见的模式开始出现,这些信息可以告诉我们并改善整体用户体验。在iOS 10中,这项技术将有助于改善QuickType和表情符号提示,Spotlight提示以及Notes中的查找提示。”简而言之,苹果似乎想从您的手机中收集更多数据。基本上,他们这样做是为了改善他们的服务,而不是收集有关每个用户的个人习惯和特征的信息。为了保证这一点,Apple打算使用复杂的统计技术来确保汇总基数(处理完所有信息后计算统计函数的结果)不会散布单个参与者。原则上,这听起来不错。但是,当然,魔鬼总是隐藏在细节中。尽管我们没有这些细节,但现在看来至少应该讨论什么是差异性隐私,如何实现以及对苹果以及您的iPhone意味着什么。动机
在过去的几年中,“普通用户”已经习惯于将大量个人信息从他的设备发送到他所使用的各种服务的想法。民意测验还表明,由于这个原因,公民开始感到不自在。如果您考虑使用我们的个人信息从我们那里赚钱的那些公司,这种不适感就很有意义。但是,有时有充分的理由收集有关用户操作的信息。例如,Microsoft最近推出了一种可通过分析Bing中的搜索查询来诊断胰腺癌的工具。 Google支持著名的Google Flu Trends服务通过不同地区的搜索查询频率来预测传染病的传播。当然,我们所有人都将从众包数据中受益,这些数据改善了我们使用的服务的质量,从地图应用程序到餐厅的评论。不幸的是,即使出于良好目的收集数据也可能有害。例如,在2000年代后期,Netflix宣布了一项竞赛,以开发最佳故事片推荐算法。为了帮助比赛的参与者,他们发布了“匿名”数据集,其中包含电影用户的观看统计数据,并从中删除了所有个人信息。不幸的是,这样的“去识别”是不够的。在Narayan和Shmatikov的著名科学著作中显示了这样的数据集可用于对特定用户进行匿名处理-甚至可以预测其政治观点!-只要您了解有关这些用户的一些额外信息即可。这样的事情应该困扰我们。不仅因为商业公司习惯性地交换了收集到的有关用户的信息(尽管他们确实这样做了),还因为发生了黑客攻击,而且因为即使收集到的数据库上的统计信息也可以以某种方式澄清所使用的特定个人记录的详细信息汇编汇总样本。差异隐私是旨在解决此问题的一组工具。什么是差异隐私?
差异隐私是最初由Cynthia Dwork在2006年提出的对用户数据保护的定义。粗略地讲,它可以简述如下:假设您在所有其他方面都有两个相同的数据库,一个数据库内部包含您的信息,另一个数据库内部没有信息。差异隐私可确保对一个数据库和第二个数据库的统计查询将产生(几乎)相同概率的特定结果。可以表示为:DP使您可以了解您的数据是否对查询结果有统计上的显着影响。如果没有,则可以将它们安全地添加到数据库中,因为这样做几乎不会造成任何危害。考虑这个愚蠢的例子:假设您已经在iPhone上激活了通知Apple您经常 在iMessage聊天会话中使用表情符号的选项。此报告包含一点信息:1表示您喜欢,0 表示您不喜欢。苹果可以接收这些报告并将其输入到巨大的数据库中。结果,该公司希望能够找出喜欢某种表情符号的用户数量。不用说,对结果求和并发布的简单过程并不满足DP的定义,因为对包含您的信息的数据库中的值求和的算术运算可能会产生与对信息缺失的数据库中的值求和不同的结果。因此,尽管这样的金额只会提供有关您的一些信息,但仍有一部分个人信息会泄露出去。研究差异隐私的主要结论是,在许多情况下,可以通过添加随机噪声来实现DP原理。结果。例如,报告方可以实施高斯分布或拉普拉斯分布,而不是简单地报告最终结果,因此结果将不那么准确-但是它将掩盖数据库中的每个特定值。(还有许多 其他 技术可以实现其他有趣的功能)。更有价值的是,可以在不知道数据库本身的内容(甚至数据库的大小)的情况下进行增加的噪声量的计算。即,可以仅基于所执行的功能本身的知识以及可接受的数据泄漏水平来进行噪声计算。
在iMessage聊天会话中使用表情符号的选项。此报告包含一点信息:1表示您喜欢,0 表示您不喜欢。苹果可以接收这些报告并将其输入到巨大的数据库中。结果,该公司希望能够找出喜欢某种表情符号的用户数量。不用说,对结果求和并发布的简单过程并不满足DP的定义,因为对包含您的信息的数据库中的值求和的算术运算可能会产生与对信息缺失的数据库中的值求和不同的结果。因此,尽管这样的金额只会提供有关您的一些信息,但仍有一部分个人信息会泄露出去。研究差异隐私的主要结论是,在许多情况下,可以通过添加随机噪声来实现DP原理。结果。例如,报告方可以实施高斯分布或拉普拉斯分布,而不是简单地报告最终结果,因此结果将不那么准确-但是它将掩盖数据库中的每个特定值。(还有许多 其他 技术可以实现其他有趣的功能)。更有价值的是,可以在不知道数据库本身的内容(甚至数据库的大小)的情况下进行增加的噪声量的计算。即,可以仅基于所执行的功能本身的知识以及可接受的数据泄漏水平来进行噪声计算。隐私与准确性之间的权衡
现在很明显,计算用户中的粉丝数量是一个非常糟糕的例子。对于DP,重要的是,可以将相同的通用方法应用于更有趣的功能,包括复杂的统计计算,例如机器学习系统中使用的那些。即使在同一数据库上计算出许多不同的函数,也可以应用它。但是有一个陷阱。事实是,单个请求的“信息泄漏”的大小可以在很小的范围内最小化,但不会为零。每次将查询发送到具有某些功能的数据库时,总“泄漏”会增加-永远不会减少。随着时间的流逝,随着请求数量的增加,泄漏可能开始增加。这是DP最困难的方面之一。它以两种主要方式表现出来:- 您打算“询问”数据库的次数越多,为了使信息泄漏最小化,您就必须添加更多的噪声。实际上,这意味着DP是在准确性和保护个人数据之间的根本折衷,这在训练复杂的机器学习模型时可能会导致很大的问题。
- , . , , , — , . . .
允许的泄漏总量通常称为“隐私预算”,它确定了允许进行的请求数量(以及结果的准确性)。 DP的主要教训是,魔鬼躲在预算中。设置得太高,重要数据将泄漏。将其设置得太低,查询结果可能会毫无用处。现在,在某些应用程序中,例如我们iPhone中的大多数应用程序,准确性不足将不再成为一个特殊的问题。我们已经习惯了我们的智能手机会犯错误的事实。但是有时在复杂的应用程序中使用DP时,例如训练机器学习模型,这确实很重要。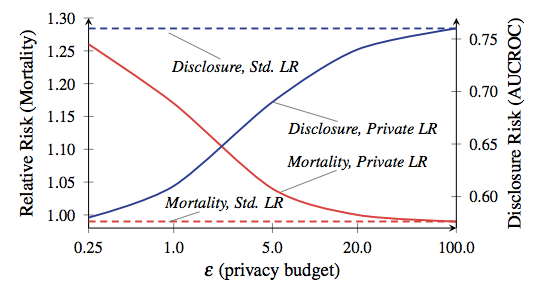 死亡率与披露的比率,摘自Frederickson等人的工作(自2014年起)。红线对应于患者的死亡率。为了给您一个绝对疯狂的例子,说明隐私和准确性之间的折衷可能有多么重要,请看一下 Frederickson等人在 2014年发表的科学论文。作者首先将华法林开放数据库中的药物剂量数据与特定的遗传标记相关联。然后,他们应用了机器学习技术来开发一个用于从数据库计算剂量的模型-但是他们在模型训练过程中将DP与各种隐私预算选项结合使用。然后,他们评估了信息泄漏的程度以及使用该模型治疗虚拟“患者”的成功性。结果表明,该模型的准确性很大程度上取决于训练期间建立的隐私预算。如果预算设置过高,则会从数据库中泄漏大量机密患者信息-但是生成的模型做出的剂量决策与标准临床实践一样安全。另一方面,当预算减少到可以接受的隐私水平时,经过嘈杂数据训练的模型往往会杀死其“患者”。在开始恐慌之前,让我解释一下:您的iPhone不会杀死您。没有人说这个例子与苹果将在智能手机上做的事情几乎没有相似之处。这项研究的结论仅在于以下事实:在每个基于DP的系统中,效率和隐私保护之间存在一个有趣的折衷-这种折衷很大程度上取决于系统开发人员的特定决策,所选的运行参数等。我们希望苹果能尽快告诉我们这些选择是什么。
死亡率与披露的比率,摘自Frederickson等人的工作(自2014年起)。红线对应于患者的死亡率。为了给您一个绝对疯狂的例子,说明隐私和准确性之间的折衷可能有多么重要,请看一下 Frederickson等人在 2014年发表的科学论文。作者首先将华法林开放数据库中的药物剂量数据与特定的遗传标记相关联。然后,他们应用了机器学习技术来开发一个用于从数据库计算剂量的模型-但是他们在模型训练过程中将DP与各种隐私预算选项结合使用。然后,他们评估了信息泄漏的程度以及使用该模型治疗虚拟“患者”的成功性。结果表明,该模型的准确性很大程度上取决于训练期间建立的隐私预算。如果预算设置过高,则会从数据库中泄漏大量机密患者信息-但是生成的模型做出的剂量决策与标准临床实践一样安全。另一方面,当预算减少到可以接受的隐私水平时,经过嘈杂数据训练的模型往往会杀死其“患者”。在开始恐慌之前,让我解释一下:您的iPhone不会杀死您。没有人说这个例子与苹果将在智能手机上做的事情几乎没有相似之处。这项研究的结论仅在于以下事实:在每个基于DP的系统中,效率和隐私保护之间存在一个有趣的折衷-这种折衷很大程度上取决于系统开发人员的特定决策,所选的运行参数等。我们希望苹果能尽快告诉我们这些选择是什么。无论如何,如何收集数据?
您已经注意到,在以上所有示例中,我都假定查询是由可访问所有原始“原始”基础数据的受信任的数据库操作员执行的。我之所以选择该模型,是因为它是几乎所有文献中都使用的传统模型,而不是因为它不是一个好主意。实际上,如果苹果真的实施了,就会引起警报您的系统以类似的方式。这将要求Apple在一个大型的集中式数据库中收集有关用户操作的所有初始信息,然后(“信任我们!”)以一种安全的方式计算其统计信息,同时保护用户的隐私。至少,此方法使信息可用于获取司法传票,以及外国黑客,苹果公司好奇的高级管理人员等。幸运的是,这不是实施差异隐私系统的唯一方法。从理论上讲,可以使用高级加密技术(例如机密计算协议或完全同态加密)来计算统计信息)不幸的是,这些技术可能效率太低,无法按Apple所需的规模使用。一种更有希望的方法似乎根本是不收集原始数据。最近,这种方法是第一个使用Google 在Chrome浏览器中收集统计信息的方法。他们的系统称为RAPPOR,基于50年的随机响应技术。随机响应的工作方式如下:- ( : « Bing?»), , «», — . .
- ( , «»), «» .
在直觉上,随机响应可以保护单个用户报告的隐私,因为答案为“是”可以表示“是,我使用必应”,也可以只是随机投掷硬币的结果。在形式上,随机响应的确提供了差异化的隐私,并且可以通过调整硬币的特性来定制特定的保证。RAPPOR采用了这种相对古老的技术,并将其转变为功能更强大的工具。系统不仅可以简单地回答一个问题,还可以针对复杂的问题向量编写报告,甚至返回复杂的答案,例如字符串-例如,浏览器中的首页是什么。实现后者,以便首先通过字符串布隆过滤器 -使用哈希函数以非常特定的方式生成的一系列位。然后将接收到的比特与噪声混合并求和,然后使用(相当复杂的)解码过程恢复响应。 尽管没有明确的证据表明Apple使用RAPPOR之类的系统,但有一些小技巧指出了这一点。例如,克雷格·费德里希(Craig Federighi)(生活中与照片完全一样)将差异化隐私描述为“使用散列,二次采样和噪声激活...众包培训,同时保持个人用户数据完全私有”。这可能是任何东西的相当微弱的证据,但是此引用中“散列”的存在至少表明建议使用RAPPOR样式的过滤器。随机响应系统的主要困难在于,如果用户多次回答相同的问题,它们会发出敏感数据。 RAPPOR尝试以多种方式解决此问题。其中之一是确定信息的静态部分,然后计算“永久响应”,而不是每次都将其随机化。但是可以想象这种保护不起作用的情况。再一次,魔鬼常常隐藏在细节中-您只需要查看它们即可。我相信无论如何都会发表许多有趣的科学论文。
尽管没有明确的证据表明Apple使用RAPPOR之类的系统,但有一些小技巧指出了这一点。例如,克雷格·费德里希(Craig Federighi)(生活中与照片完全一样)将差异化隐私描述为“使用散列,二次采样和噪声激活...众包培训,同时保持个人用户数据完全私有”。这可能是任何东西的相当微弱的证据,但是此引用中“散列”的存在至少表明建议使用RAPPOR样式的过滤器。随机响应系统的主要困难在于,如果用户多次回答相同的问题,它们会发出敏感数据。 RAPPOR尝试以多种方式解决此问题。其中之一是确定信息的静态部分,然后计算“永久响应”,而不是每次都将其随机化。但是可以想象这种保护不起作用的情况。再一次,魔鬼常常隐藏在细节中-您只需要查看它们即可。我相信无论如何都会发表许多有趣的科学论文。苹果对DP的使用是好是坏?
作为科学家和信息安全专家,我对此感到百感交集。一方面,作为一名科学家,我了解到观察实际产品中先进科学技术的实施是多么有趣。苹果公司为此类实验提供了非常大的平台。另一方面,作为一名务实的安全专家,我有责任保持怀疑态度-该公司至少应该提出一个对安全至关重要的代码(就像Google对RAPPOR所做的那样),或者至少要明确说明其实现的方式。如果苹果正计划收集上,我们是如此依赖于设备的新的海量数据,我们必须真正确保他们做的一切正确-并不要为实施如此绝妙的想法而大加赞赏。(我曾经犯过这样的错误,因此仍然觉得自己很傻)。但是也许所有这些都是太深的细节。最后,苹果看起来确实是在诚实地尝试做一些事情来保护用户的机密信息,并且考虑到其他选择,这可能是最重要的事情。Source: https://habr.com/ru/post/zh-CN395313/
All Articles