糟糕的研究获得越来越多的钱
 维克多·彼得里克(Victor Petrik)展示了他的纳米过滤器(来源:rusphysics.ru),
维克多·彼得里克(Victor Petrik)展示了他的纳米过滤器(来源:rusphysics.ru),
1963年,纽约大学的心理学家雅各布·肯(Jacob Ken)分析了《异常与社会心理学杂志》上发表的约70篇文章,发现了一个有趣的事实。只有少数科学家认识到他们研究工作的失败。对于这些材料,他计算了它们的“统计能力”。术语“统计能力”是指如果无效假设被拒绝的概率。据统计,只有20%的实验过程证明了研究人员期望的结果。事实证明,在科恩研究的几乎所有研究中,作者均表示研究的积极预期结果。事实证明,作者根本不报告失败。此外,一些作者歪曲了他们的研究结果,即使没有,也表明了积极的效果。检验统计假设时的功效取决于以下因素:- 用希腊字母α(alpha)表示的显着性水平,在此基础上决定拒绝或接受替代假设;
- 效果的大小(即比较平均值之间的差异);
- 确认统计假设所需的样本量。
自从雅各布·科恩(Jacob Cohen)的著作出版以来已经过去了半个多世纪,但是科学研究的作者仍然谈论他们的成功,掩盖了失败。最近在皇家学会开放科学杂志上发表的另一项研究结果证明了这一点。这项工作的作者是加利福尼亚大学的Paul Smaldino和马克斯·普朗克协会进化人类学研究所的 Richard Mac Elres 。据研究人员称,现代文章并没有变得更好。至少,有关心理学,神经病学和医学的文章。在研究了1960年至2011年发表的数十篇文章之后,科学家们确定这种情况下的平均统计功效为24%。这仅略高于Cohen计算的参数。尽管有这样一个事实,近年来,科学研究的方法已经变得更加准确,并且越来越多的书籍和文章为研究人员描述了科学工作的原理和方法。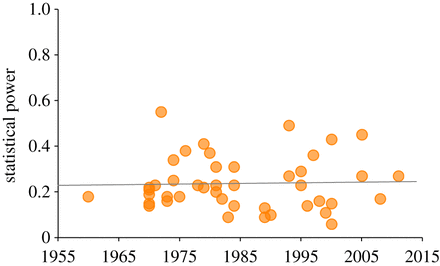 1960年至2011年在科学期刊上发表的出版物的平均统计能力获得了这样的结果后,科学家们思考了什么可以改变事物的现状,从而使科学著作的作者变得更加认真。为此,Mac Elres和Smaldino创建了计算机进化模型。在这种模式下,约有100个虚拟实验室竞争获得报酬的权利。如果在研究框架内实验室团队收到了非常显着的结果,则将获得报酬。为了确定薪酬数额,科学家使用了诸如出版物数量之类的指标。正如事实证明,有些实验室的工作效率比其他实验室更高,显示出更多的结果。同时,这些实验室经常给人以期望值。在这种情况下,结果被证实较差,结果被解释为阳性。如果对工作结果进行了更彻底的验证,那么发表的作品将减少。在每个模拟周期中,所有模拟实验室都进行了实验并发布了结果。之后,科学家从许多随机选择的实验室中清理了最古老的实验室。来自另一个随机列表(选择标准-获得的最大奖励数量)的实验室使我们有可能创建自己的部门,该部门积极参与科学材料的出版。对计算机模型进行分析的初步结果表明:发表最多研究成果的实验室仅花费一小部分时间来检查结果,并成为最权威的实验室,从而在科学界传播了他们的研究方法。但是还有一件事。事实证明,另一个团队重复一个实验室的工作结果可以提高第一个实验室的声誉。但是,如果无法重复任何实验的结果,则会导致问题并降低实验室的声誉,后者首先进行了此类实验。在这种情况下,将触发一个过滤器,以防止伪造的研究在科学界以修改后的研究结果出现。对发表未经证实的结果的人的惩罚越强,发现劣质研究的过滤器越强大。带有伪造数据的实验室最高可得到100分的惩罚,具有真实结果的出版物数量急剧增加。另外,其他实验室为了重复某人获得的结果而进行的重复实验的数量也在增加。让我提醒您,上述所有内容都是在PC上模拟的情况。该研究的作者得出以下结论:与以往一样,现在出版比其他出版物更多的科学组织被认为是最权威的。不幸的是,在虚拟世界中工作的低质量出版物筛选器在现实世界中不能很好地工作。事实是,研究机构和个人研究人员并不经常检查彼此的结果。如果更频繁地进行旨在重复合作伙伴获得的结果的此类检查,那么科学界的“错误结果”将变得更少。该研究的作者认为,计算机模型显示出改变当前事物状态的可能性。如果资金和科学组织不向发表未经证实的研究结果的科学家和实验室提供金钱,并以积极的结果将其通过,那么欺骗者将很快变得更少。但是在现实世界中实现这样的模型非常困难。“说起来容易做起来难,” Smaldino说。因此,目前,那些发表许多文章的组织处在积极的领域。但是仔细核实其结果的组织发布的频率较低。DOI:10.1098 / rsos.160384
1960年至2011年在科学期刊上发表的出版物的平均统计能力获得了这样的结果后,科学家们思考了什么可以改变事物的现状,从而使科学著作的作者变得更加认真。为此,Mac Elres和Smaldino创建了计算机进化模型。在这种模式下,约有100个虚拟实验室竞争获得报酬的权利。如果在研究框架内实验室团队收到了非常显着的结果,则将获得报酬。为了确定薪酬数额,科学家使用了诸如出版物数量之类的指标。正如事实证明,有些实验室的工作效率比其他实验室更高,显示出更多的结果。同时,这些实验室经常给人以期望值。在这种情况下,结果被证实较差,结果被解释为阳性。如果对工作结果进行了更彻底的验证,那么发表的作品将减少。在每个模拟周期中,所有模拟实验室都进行了实验并发布了结果。之后,科学家从许多随机选择的实验室中清理了最古老的实验室。来自另一个随机列表(选择标准-获得的最大奖励数量)的实验室使我们有可能创建自己的部门,该部门积极参与科学材料的出版。对计算机模型进行分析的初步结果表明:发表最多研究成果的实验室仅花费一小部分时间来检查结果,并成为最权威的实验室,从而在科学界传播了他们的研究方法。但是还有一件事。事实证明,另一个团队重复一个实验室的工作结果可以提高第一个实验室的声誉。但是,如果无法重复任何实验的结果,则会导致问题并降低实验室的声誉,后者首先进行了此类实验。在这种情况下,将触发一个过滤器,以防止伪造的研究在科学界以修改后的研究结果出现。对发表未经证实的结果的人的惩罚越强,发现劣质研究的过滤器越强大。带有伪造数据的实验室最高可得到100分的惩罚,具有真实结果的出版物数量急剧增加。另外,其他实验室为了重复某人获得的结果而进行的重复实验的数量也在增加。让我提醒您,上述所有内容都是在PC上模拟的情况。该研究的作者得出以下结论:与以往一样,现在出版比其他出版物更多的科学组织被认为是最权威的。不幸的是,在虚拟世界中工作的低质量出版物筛选器在现实世界中不能很好地工作。事实是,研究机构和个人研究人员并不经常检查彼此的结果。如果更频繁地进行旨在重复合作伙伴获得的结果的此类检查,那么科学界的“错误结果”将变得更少。该研究的作者认为,计算机模型显示出改变当前事物状态的可能性。如果资金和科学组织不向发表未经证实的研究结果的科学家和实验室提供金钱,并以积极的结果将其通过,那么欺骗者将很快变得更少。但是在现实世界中实现这样的模型非常困难。“说起来容易做起来难,” Smaldino说。因此,目前,那些发表许多文章的组织处在积极的领域。但是仔细核实其结果的组织发布的频率较低。DOI:10.1098 / rsos.160384Source: https://habr.com/ru/post/zh-CN397897/
All Articles