用于人类演讲的“ Photoshop”
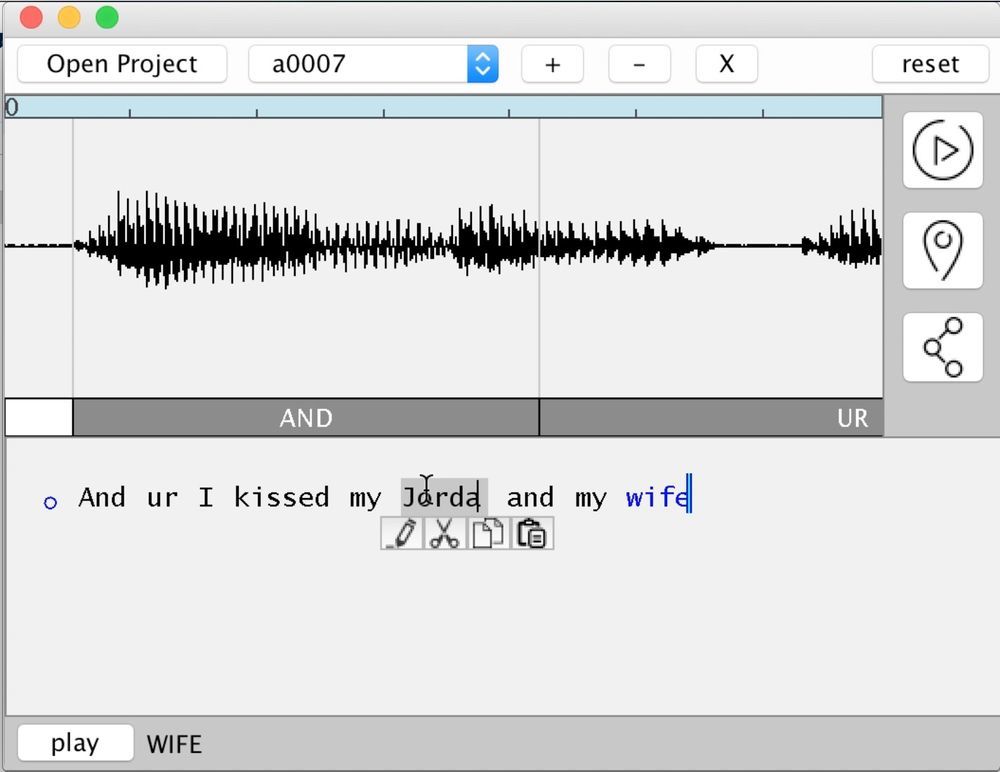 在2016年11月3日的Adobe MAX技术会议上,Adobe 提出了非常有趣的科学技术发展,将来它可能会变成流行的软件应用程序。简而言之,本发明是用于人类语音的语义编辑的程序。在这种情况下,不仅使用从收集的音素合成的标准方法(编译合成),还使用了增加真实感的辅助方法。这是trifons的明智选择,并且是使用样本语音的特定特征。结果,用户编写了任意文本-程序便用经过训练的语音来发声。您可以在语音中快速添加任何单词,也可以删除不必要的单词。实际上,作为VoCo项目的一部分介绍的程序的工作原理如下。首先,将音素库组装成特定语言的特定人的语音。为了获得逼真的结果,该程序至少需要20分钟的人类语音。越多越好。然后,基于收集的音素(trifons),该程序可以收集几乎所有新单词,就像从砖头一样。MAX会议上VoCo演示的片段从某种意义上说,VoCo的工作原理类似于Photoshop中的上下文画笔。她还从图片的不同位置获取片段-并从这些片段中收集新图像。一张森林的照片上的一块木头,另一张照片上的一块草,以及第三张照片的一个女孩-我们得到了一个全新的真实感作品,前景是森林,草和一个女孩。如果工作是专业完成的,则很难确定安装。因此在苏联时期,突然成为人民敌人的人们被从历史中抹去了。照片中有一个人-现在有一个空白或另一个人。因此,VoCo技术使您可以使用任意单词和短语来补充人类语音。在MAX会议上,开发人员之一Zeze Jin作了介绍。在先前发表的科学论文中,他与同事Adam Finkelstein一起被列为普林斯顿大学的雇员。该技术由Adobe Research与普林斯顿大学合作开发。正如Adobe所构思的那样,该技术将帮助内容创建者更轻松地编辑音轨:对话框和配音文本可以快速修复错误或更改情节。Adobe强调,在这种情况下,谈论“语音转换”比讨论经典语音合成更为合适。语音转换的目的是转换原始语音,以便对于收听者来说,它似乎是遵循后者声音模型的另一个人的声音。语音转换的技术基础在上述科学工作中有更详细的描述。与普林斯顿大学联合编写。它的作者表明,所开发的CUTE技术在质量上优于其他语音转换方法。替代转换方法通常基于对源和目标的相同短语进行并行分析,然后计算任何地址空间中的某些转换向量。之后,可以使用获得的向量来转换原始语音的任意片段。但是这些方法都有令人不快的副作用-以这种方式合成的语音充耳不闻,含糊不清。Adobe研究人员能够使用混合CUTE方法克服其他技术的缺点。标题加密了该技术的四个主要组成部分:编译综合(连接合成);单位选择; Trifons的初步选择,即三个音素的单位(Triphone预选择);使用示例属性(基于示例的功能)。编译合成被简化为根据预先记录的音素字典来编写消息。这是使用语音合成器的主要方法,这些语音合成器配备了各种设备:从军用飞机到家用设备,移动运营商的帮助服务等。顾名思义,已开发的混合技术结合了几种语音合成和语音转换方法。科学工作展示了其他语音转换方法的对比测试结果,其中CUTE明显优于竞争对手。同时,提到了他的一些缺点:与其他所有人一样,他在合成新单词时遭受数据库中音素数量不足的困扰,因此在语音上正确,但生成的结果并不十分真实。此外,它取决于语音识别引擎的操作以进行正确的语音分割。尚不清楚Adobe是否将以真正的商业产品形式实现这一有希望的发展。但是现在我们可以说,只要音素的语音合成是现实的,这样的程序将变得非常流行。例如,播客可以使用它从文本生成播客。它也可以用于使用任意人(例如,您自己的女孩)的声音为有声读物提供声音。在没有演员的情况下,这种技术很可能会在好莱坞找到声音表演的应用。例如,如果与他的合同违约,或者他在拍摄过程中死亡。
在2016年11月3日的Adobe MAX技术会议上,Adobe 提出了非常有趣的科学技术发展,将来它可能会变成流行的软件应用程序。简而言之,本发明是用于人类语音的语义编辑的程序。在这种情况下,不仅使用从收集的音素合成的标准方法(编译合成),还使用了增加真实感的辅助方法。这是trifons的明智选择,并且是使用样本语音的特定特征。结果,用户编写了任意文本-程序便用经过训练的语音来发声。您可以在语音中快速添加任何单词,也可以删除不必要的单词。实际上,作为VoCo项目的一部分介绍的程序的工作原理如下。首先,将音素库组装成特定语言的特定人的语音。为了获得逼真的结果,该程序至少需要20分钟的人类语音。越多越好。然后,基于收集的音素(trifons),该程序可以收集几乎所有新单词,就像从砖头一样。MAX会议上VoCo演示的片段从某种意义上说,VoCo的工作原理类似于Photoshop中的上下文画笔。她还从图片的不同位置获取片段-并从这些片段中收集新图像。一张森林的照片上的一块木头,另一张照片上的一块草,以及第三张照片的一个女孩-我们得到了一个全新的真实感作品,前景是森林,草和一个女孩。如果工作是专业完成的,则很难确定安装。因此在苏联时期,突然成为人民敌人的人们被从历史中抹去了。照片中有一个人-现在有一个空白或另一个人。因此,VoCo技术使您可以使用任意单词和短语来补充人类语音。在MAX会议上,开发人员之一Zeze Jin作了介绍。在先前发表的科学论文中,他与同事Adam Finkelstein一起被列为普林斯顿大学的雇员。该技术由Adobe Research与普林斯顿大学合作开发。正如Adobe所构思的那样,该技术将帮助内容创建者更轻松地编辑音轨:对话框和配音文本可以快速修复错误或更改情节。Adobe强调,在这种情况下,谈论“语音转换”比讨论经典语音合成更为合适。语音转换的目的是转换原始语音,以便对于收听者来说,它似乎是遵循后者声音模型的另一个人的声音。语音转换的技术基础在上述科学工作中有更详细的描述。与普林斯顿大学联合编写。它的作者表明,所开发的CUTE技术在质量上优于其他语音转换方法。替代转换方法通常基于对源和目标的相同短语进行并行分析,然后计算任何地址空间中的某些转换向量。之后,可以使用获得的向量来转换原始语音的任意片段。但是这些方法都有令人不快的副作用-以这种方式合成的语音充耳不闻,含糊不清。Adobe研究人员能够使用混合CUTE方法克服其他技术的缺点。标题加密了该技术的四个主要组成部分:编译综合(连接合成);单位选择; Trifons的初步选择,即三个音素的单位(Triphone预选择);使用示例属性(基于示例的功能)。编译合成被简化为根据预先记录的音素字典来编写消息。这是使用语音合成器的主要方法,这些语音合成器配备了各种设备:从军用飞机到家用设备,移动运营商的帮助服务等。顾名思义,已开发的混合技术结合了几种语音合成和语音转换方法。科学工作展示了其他语音转换方法的对比测试结果,其中CUTE明显优于竞争对手。同时,提到了他的一些缺点:与其他所有人一样,他在合成新单词时遭受数据库中音素数量不足的困扰,因此在语音上正确,但生成的结果并不十分真实。此外,它取决于语音识别引擎的操作以进行正确的语音分割。尚不清楚Adobe是否将以真正的商业产品形式实现这一有希望的发展。但是现在我们可以说,只要音素的语音合成是现实的,这样的程序将变得非常流行。例如,播客可以使用它从文本生成播客。它也可以用于使用任意人(例如,您自己的女孩)的声音为有声读物提供声音。在没有演员的情况下,这种技术很可能会在好莱坞找到声音表演的应用。例如,如果与他的合同违约,或者他在拍摄过程中死亡。Source: https://habr.com/ru/post/zh-CN398865/
All Articles