神经网络读取电视上嘴唇上的单词的46.8%,而只有12.4%的人
 研究该程序的四个程序的框架以及“下午”这个词,由两个不同的发言人说出。两周前,他们谈论了LipNet神经网络,该技术在嘴唇上显示了93.4%的人类语音识别记录,创下了记录质量。即便如此,此类计算机系统仍应有许多应用程序:具有语音识别功能的新一代医疗助听器,在公共场所进行无声演讲的系统,生物特征识别,用于间谍活动信息的秘密传输的系统,通过监视摄像机的视频进行语音识别等。现在,牛津大学的专家与Google DeepMind的员工一起介绍了他们在这一领域的发展。新的神经网络接受了在BBC电视频道上表演的任意文本的训练。有趣的是,培训是自动完成的,而无需先手动注释语音。系统本身可以识别语音,为视频添加注释,在帧中找到人脸,然后学习确定单词(声音)与嘴唇运动之间的关系。结果,该系统有效地识别了任意文本,而不是像LipNet那样识别来自GRID特殊语料库的实例。 GRID案例的结构和词汇严格受限;因此,只能有33,000个句子。因此,选项的数量减少了数量级,并且简化了识别。GRID的特殊情况由以下组成:命令(4)+颜色(4)+介词(4)+字母(25)+数字(10)+副词(4),其中数字对应于六个言语类别中每个词变体的数目。与LipNet不同,DeepMind和牛津大学专家的发展致力于电视图像质量的任意语音流。它更像是一个可以实际使用的真实系统。AI训练了从2010年1月至2015年12月从英国BBC电视频道的六个电视节目中录制的5,000小时视频:这些是常规新闻发布(1584小时),早晨新闻(1997小时),新闻之夜广播(590小时),世界新闻(194)小时),提问时间(323小时)和“今日世界”(272小时)。这些视频总共包含118,116个连续的人类语音句子。之后,该节目在2016年3月至2016年9月间播放的广播中进行了检查。该程序显示出相当高的阅读质量。她正确地识别出即使是非常复杂的句子,也具有不寻常的语法结构和专有名词的使用。完美识别的句子示例:
研究该程序的四个程序的框架以及“下午”这个词,由两个不同的发言人说出。两周前,他们谈论了LipNet神经网络,该技术在嘴唇上显示了93.4%的人类语音识别记录,创下了记录质量。即便如此,此类计算机系统仍应有许多应用程序:具有语音识别功能的新一代医疗助听器,在公共场所进行无声演讲的系统,生物特征识别,用于间谍活动信息的秘密传输的系统,通过监视摄像机的视频进行语音识别等。现在,牛津大学的专家与Google DeepMind的员工一起介绍了他们在这一领域的发展。新的神经网络接受了在BBC电视频道上表演的任意文本的训练。有趣的是,培训是自动完成的,而无需先手动注释语音。系统本身可以识别语音,为视频添加注释,在帧中找到人脸,然后学习确定单词(声音)与嘴唇运动之间的关系。结果,该系统有效地识别了任意文本,而不是像LipNet那样识别来自GRID特殊语料库的实例。 GRID案例的结构和词汇严格受限;因此,只能有33,000个句子。因此,选项的数量减少了数量级,并且简化了识别。GRID的特殊情况由以下组成:命令(4)+颜色(4)+介词(4)+字母(25)+数字(10)+副词(4),其中数字对应于六个言语类别中每个词变体的数目。与LipNet不同,DeepMind和牛津大学专家的发展致力于电视图像质量的任意语音流。它更像是一个可以实际使用的真实系统。AI训练了从2010年1月至2015年12月从英国BBC电视频道的六个电视节目中录制的5,000小时视频:这些是常规新闻发布(1584小时),早晨新闻(1997小时),新闻之夜广播(590小时),世界新闻(194)小时),提问时间(323小时)和“今日世界”(272小时)。这些视频总共包含118,116个连续的人类语音句子。之后,该节目在2016年3月至2016年9月间播放的广播中进行了检查。该程序显示出相当高的阅读质量。她正确地识别出即使是非常复杂的句子,也具有不寻常的语法结构和专有名词的使用。完美识别的句子示例:- 参与攻击的许多人
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
AI大大超出了一个人的工作效率,他是一位唇读专家,他试图从记录的验证视频档案中识别200个随机视频片段。专业人士仅能无误地注释单词的12.4%,而AI则正确记录了46.8%。研究人员指出,许多错误可以称为次要错误。例如,单词末尾缺少“ s”。如果我们不那么严格地对结果进行分析,那么实际上该系统会识别出一半以上的直播单词。有了这个结果,DeepMind明显优于所有其他的唇读器,包括上述的LipNet,它也是由牛津大学开发的。但是,现在谈论最终的优势还为时过早,因为LipNet并未接受过如此庞大的数据集的培训。据专家介绍,DeepMind是朝着开发全自动唇读系统迈出的一大步。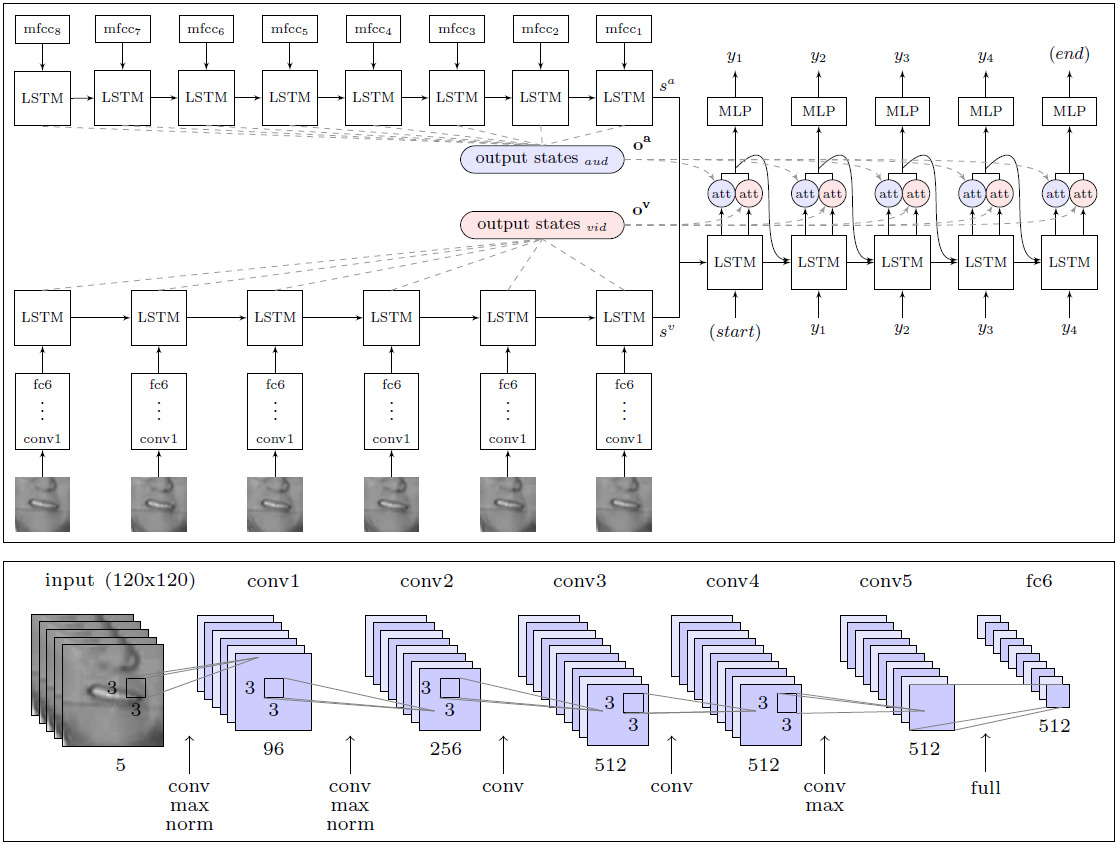 WLAS模块的结构(观看,聆听,参加和咒语)以及用于读取嘴唇的卷积神经网络研究人员的长处在于,他们编辑了一个庞大的数据集,用于使用17,500个唯一的单词来训练和测试系统。毕竟,这不仅是连续五年以优质英语连续录制电视节目,而且还具有清晰的视频和声音同步(在电视上,甚至在专业英语电视上,通常也可以同步到1秒),以及语音识别模块的开发在视频上使用,并用于教授唇读系统(WLAS模块,请参见上图)。在最短的同步时间下,由于程序无法确定声音和嘴唇运动的正确对应关系,因此训练该系统几乎没有用。经过全面的准备工作,该程序的培训是完全自动化的-它独立处理了所有5000个视频。以前,这样的集合根本不存在,因此,同样的LipNet作者被迫将自己限制在GRID基础上。值得DeepMind开发人员称赞的是,他们承诺在公共领域发布用于训练其他AI的数据集。 LipNet开发团队的同事已经表示,他们对此表示期待。科学工作在arXiv网站(arXiv:1611.05358v1)上以公共领域发布。如果在市场上出现商业化的唇读系统,那么普通人的生活将变得更加简单。可以假设这样的系统将立即内置在电视和其他家用电器中,以改善语音控制和几乎无错误的语音识别。
WLAS模块的结构(观看,聆听,参加和咒语)以及用于读取嘴唇的卷积神经网络研究人员的长处在于,他们编辑了一个庞大的数据集,用于使用17,500个唯一的单词来训练和测试系统。毕竟,这不仅是连续五年以优质英语连续录制电视节目,而且还具有清晰的视频和声音同步(在电视上,甚至在专业英语电视上,通常也可以同步到1秒),以及语音识别模块的开发在视频上使用,并用于教授唇读系统(WLAS模块,请参见上图)。在最短的同步时间下,由于程序无法确定声音和嘴唇运动的正确对应关系,因此训练该系统几乎没有用。经过全面的准备工作,该程序的培训是完全自动化的-它独立处理了所有5000个视频。以前,这样的集合根本不存在,因此,同样的LipNet作者被迫将自己限制在GRID基础上。值得DeepMind开发人员称赞的是,他们承诺在公共领域发布用于训练其他AI的数据集。 LipNet开发团队的同事已经表示,他们对此表示期待。科学工作在arXiv网站(arXiv:1611.05358v1)上以公共领域发布。如果在市场上出现商业化的唇读系统,那么普通人的生活将变得更加简单。可以假设这样的系统将立即内置在电视和其他家用电器中,以改善语音控制和几乎无错误的语音识别。Source: https://habr.com/ru/post/zh-CN399429/
All Articles