 基于名人面孔训练后的神经网络的示例。 左侧是神经网络输入端的初始图像集8×8像素,中间是根据模型的预测最多可插值32×32像素的结果。 右边是名人面孔的真实照片,缩小为32×32,从中获得了左列的样本
基于名人面孔训练后的神经网络的示例。 左侧是神经网络输入端的初始图像集8×8像素,中间是根据模型的预测最多可插值32×32像素的结果。 右边是名人面孔的真实照片,缩小为32×32,从中获得了左列的样本是否可以将照片的分辨率提高到无限远? 是否可以基于64像素生成逼真的图像? 逻辑表明这是不可能的。
Google Brain的新神经网络的看法有所不同。 它确实将照片的分辨率提高到了令人难以置信的水平。
这样的“超分辨率”并不是从低分辨率副本中恢复原始图像。 这是
可能是原始图像的可信照片的合成。 这是一个概率过程。
当任务是“提高照片的分辨率”,但没有细节需要改进时,该模型的任务是从人的角度生成最合理的图像。 反过来,在模型创建轮廓并做出关于图像的不同部分中将出现哪些纹理,形状和图案的“强烈意愿”决定之前,不可能生成真实的图像。
例如,仅查看KDPV,其中左列是神经网络的真实测试图像。 他们缺乏皮肤和头发的细节。 它们决不能通过线性或双三次之类的传统插值方法恢复。 但是,如果您首先对面孔的多样性和其典型轮廓有深入的了解(并且知道有必要在此处提高面孔的分辨率),那么神经网络将能够完成一件奇妙的事情-并“绘制”出最有可能出现的缺失细节。
Google Brain的专家发表了一篇名为“
递归像素超分辨率 ”的科学论文,该论文描述了一种完全概率模型,该模型基于一组高分辨率照片及其缩减的8×8副本进行训练,从而可以从8×8的小样本生成32×32的图像。
该模型由同时训练的两个组件组成:条件神经网络和先验网络。 它们中的第一个有效地将低分辨率图像叠加在相应的高分辨率图像的分布上,第二个模型对高分辨率细节进行建模以使最终版本更逼真。 空调神经网络由
ResNet单元组成,而先前的是
PixelCNN体系结构。
在示意图中,该模型在图示中进行了描述。
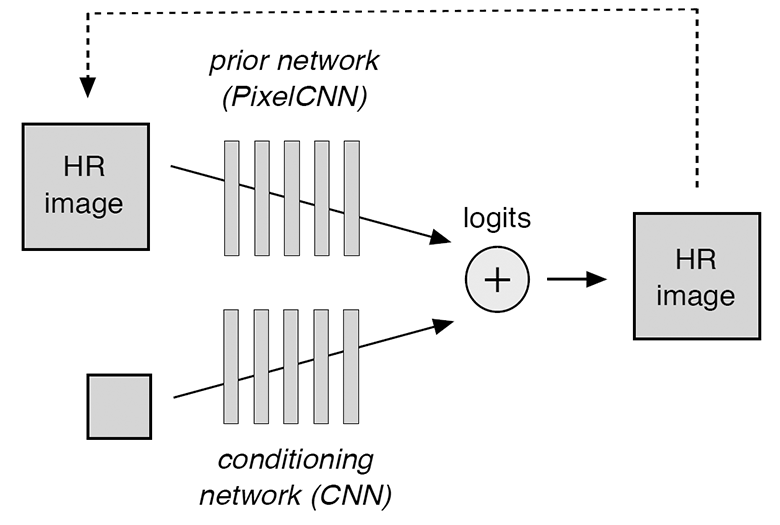
有条件的卷积神经网络在输入处接收低分辨率图像并产生logit-值,这些值预测高分辨率图像中每个像素的条件logit概率。 反过来,卷积神经网络事先根据先前的随机预测(在图中的虚线表示)进行预测。 整个模型的概率分布计算为softmax运算符,它来自条件神经网络和先验条件的两组logit之和。
但是如何评估这种网络的质量呢? 科学工作的作者得出的结论是,诸如峰值信噪比(pSNR)和结构相似性(SSIM)之类的标准度量标准无法正确评估此类分辨率超强问题的预测质量。 根据这些度量标准,可以得出最好的结果是模糊的图片,而不是真实感逼真的图像在放置位置与真实图像的清晰细节不一致的真实感图像。 也就是说,这些pSNR和SSIM指标非常保守。 研究表明,人们可以轻松地将真实照片与通过回归方法创建的模糊选项区分开,但要区分神经网络从真实照片生成的样本并不容易。
让我们看看由Google Brain开发并在一组200,000名名人脸(CelebA照片集)和2,000,000间卧室(LSUN Bedrooms照片集)上进行训练的模型显示了什么结果。 在所有情况下,训练系统之前的照片均缩小为32×32像素,然后使用双三次插值方法再次缩小为8×8。 TensorFlow神经网络在8个GPU上进行训练。
在两个主要基础上对结果进行了比较:1)具有类似于
SRResNet神经网络的体系结构的独立逐像素回归(Regression),在评估插值质量的标准指标上显示出出色的结果; 2)搜索最近邻元素(NN),该元素通过欧几里得空间中像素的接近度在低分辨率教育样本数据库中搜索最相似的图像,然后返回从中生成该教育样本的相应高分辨率图像。
应该注意的是,根据softmax温度,概率模型会产生不同质量的结果。 手动确定最佳值
介于1.1和1.3之间。 但是即使您安装
那么无论如何结果每次都会有所不同。
 使用softmax温度启动模型时结果不同
使用softmax温度启动模型时结果不同 您可以通过扰流器下的样本来评估概率模型的工作质量。
为了验证结果的真实性,科学家对众包进行了调查。 为参与者显示了两张照片:一张是真实照片,第二张是通过各种方法从8×8的缩小副本中生成的,并被要求指出相机拍摄了哪张照片。
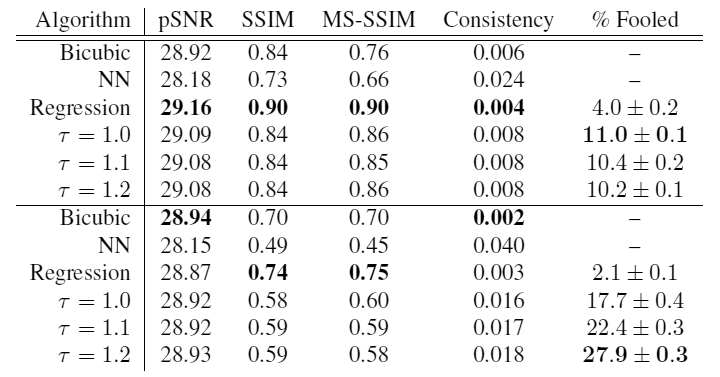
在表的顶部是名人基础的结果,在下面是卧室的结果。 如您所见,在温度
在卧室的照片中,该模型显示出最大的效果:在27.9%的情况下,该模型的交付比实际图像更真实! 这是明显的成功。
下图显示了神经网络最成功的工作,其中它以真实性“击败”了原始对象。 为客观起见-还有一些最坏的情况。

在使用神经网络生成逼真的图像的领域中,现在观察到非常快速的发展。 在2017年,我们当然会听到很多与此主题相关的新闻。