与其他有意义的人类职业形式一样,在科学研究中,一项行动计划很重要。 有些人从事纯科学,但这是一个完全不同的故事。 在实际应用中,即在日常生活中使用科学方法时,需要明确的动作顺序,传送带将根据该动作进行工作。 Genotek从事应用遗传学研究,分析和解释DNA中记录的数据。 我们的研究部门发表
了一篇文章 ,介绍了如何选择正确的基因以及为什么可以信任这些基因的分析结果。 这是出版物的摘要。

有时在我们的生活中会发生意想不到的事情(甚至是麻烦),但是如果我们负责任地采取行动,我们可以承认正在发生的事情的很大一部分是我们自己的行动的结果,而不是一连串的随机事件。 一般来说,这是一个自信心的问题。 您可以完全不用担心,不要怀疑,不要考虑这些事情,做一些美丽的事情。 另一方面,找到自己的有效操作指令的能力开辟了新的可能性。 一切都非常简单:一个人肯定想知道几件事。
- 第一:他最容易患什么疾病。 与年龄有关的疾病是生活方式的结果,而不是其他人的意图。
- 第二:儿童的健康。 再说一次,如果我们谈论的是一个负责任的人,他有意识地计划自己的家庭,却不顾避孕而忽略后果,那么谈论这一点就很有意义。
- 第三:怎样做才能更好地生活。 人体是一种机制。 尽管每个人的工作原理都相同,但每个机构的工作原理可能略有不同。 适合一个人的东西可能对另一个人有害。
- 第四:“我”是什么。 在功能方面,知道一个人的来历将无助于更长寿或更美好。 相反,它将使您感觉自己像人类历史上的角色,英雄,行动和发展,无论某人的短期利益或个人信念如何。
通过阅读基因的某些部分,可以从DNA中了解所有这些信息。 基因是一个单独的语义DNA片段,在最简单的情况下,该片段编码一个字符。 顺便说一句,“表型”一词应理解为所观察到的病状的所有迹象的总和(例如,眼睛的颜色,肺叶的形状,糖尿病的倾向,乳糖的消化率)。 然后出现了与学年相同的问题:究竟需要阅读什么,有可能不阅读所有内容以及如何处理已阅读的内容。
为了利用预测性DNA测试技术提供大规模的医疗服务,您需要注意数据分析中的一些细微之处。 首先,这是一个个性化问题:必须仔细选择令牌。 大多数旨在建立“基因型-表型”关联的研究都是在大样本上进行的。 通常,样本(被分析的人群)
不是很异构 :它们可以是大量的,但是由一个民族的代表组成。 一方面,这简化了研究框架内的统计分析,另一方面,提出了所发现的联想与其他人群的相关性的问题。
第二个问题是标记的数量-当您需要找到中间立场时就是这种情况。 在这里,您离不开两个测试参数之间的永恒平衡:敏感性和特异性。 遗传标记数量的增加无疑会增加分析对某些疾病的敏感性。 同时,测试的特异性可能会下降。 例如,由于我们正在谈论确定严重疾病的诱因,因此在确定可怕的诊断时出现假阳性错误要比阐明患病的可能性更加危险。 另外,标记数量的增加导致测试系统成本的增加,这也使得难以进入大众市场。
不存在针对这些问题的通用解决方案。 在工作的初始阶段,研究人员面临的情况是“有很多文章,而且都需要阅读。” 因此,Genotek科学部门提出了一种选择算法,该算法大大简化了用于字符分析的多态性的选择。 重要的是,我们谈论的是多态性,而不是整体的基因:每个X染色体上的两个男人都有相同的雄激素受体基因,但是第一个男人在
rs6152位点具有腺嘌呤(AA),第二个男人具有鸟嘌呤。 (GG)。 到40岁时,最后一根头发仍保持壮观的可能性
约为30% 。 在这种情况下,要了解这一点,您无需读取整个基因序列-只需找到并读取DNA上的一个点,然后将其与相反的一个点进行比较即可。
寻找什么
遗传学将我们的特征称为祖先的表型特征。 整体上生物学的基本问题是基因型和表型之间的关系,以及一个人如何编码另一个人。 在我们的案例中,关于表型特征的遗传性有两种观点。 一方面,继承的性质可能有所不同。 因此,单个特征可能根本不会被继承,并且其表现也不会与遗传贡献有任何联系。 在生活方式或环境条件的影响下出现的此类信号对于DNA测试开发人员而言并不重要。
另一方面,如果遗传了一个性状,则重要的是要了解什么样的遗传相互作用是观察状态的基础。 在最简单的情况下,只有一个基因可以影响疾病的发展-那么我们在谈论单基因遗传。 例如,苯丙酮尿症是一种与一种基因的“分解”有关的代谢性疾病。 在这种情况下,人们无法说出易患病的倾向:如果一个人已经有两个断裂基因的拷贝,他仍然会患上疾病。 但是,在这种情况下,遗传诊断可以明确诊断,以便选择更合适的治疗方法。
当几个基因促成表型性状时,将更加困难。 重要的是要了解性状的形成是如何发生的,无论它是多基因的还是多因素的。 多基因性状是由于多种多态性而形成的-该性状的发展也没有概率性。 通过多态性的某种组合,可以可靠地获得人眼的某种颜色。 现在,预测眼睛颜色(和其他外部特征)的问题在于法医。 它可以借助数学模型来解决,也可以通过在大型数据集上训练神经网络来解决。 除遗传基础外,多因素表型还受某些环境条件的影响。 这些迹象对于医学预后分析最为重要,因为这些状况可以通过某种生活方式得到纠正。
该算法本身看起来像这样:
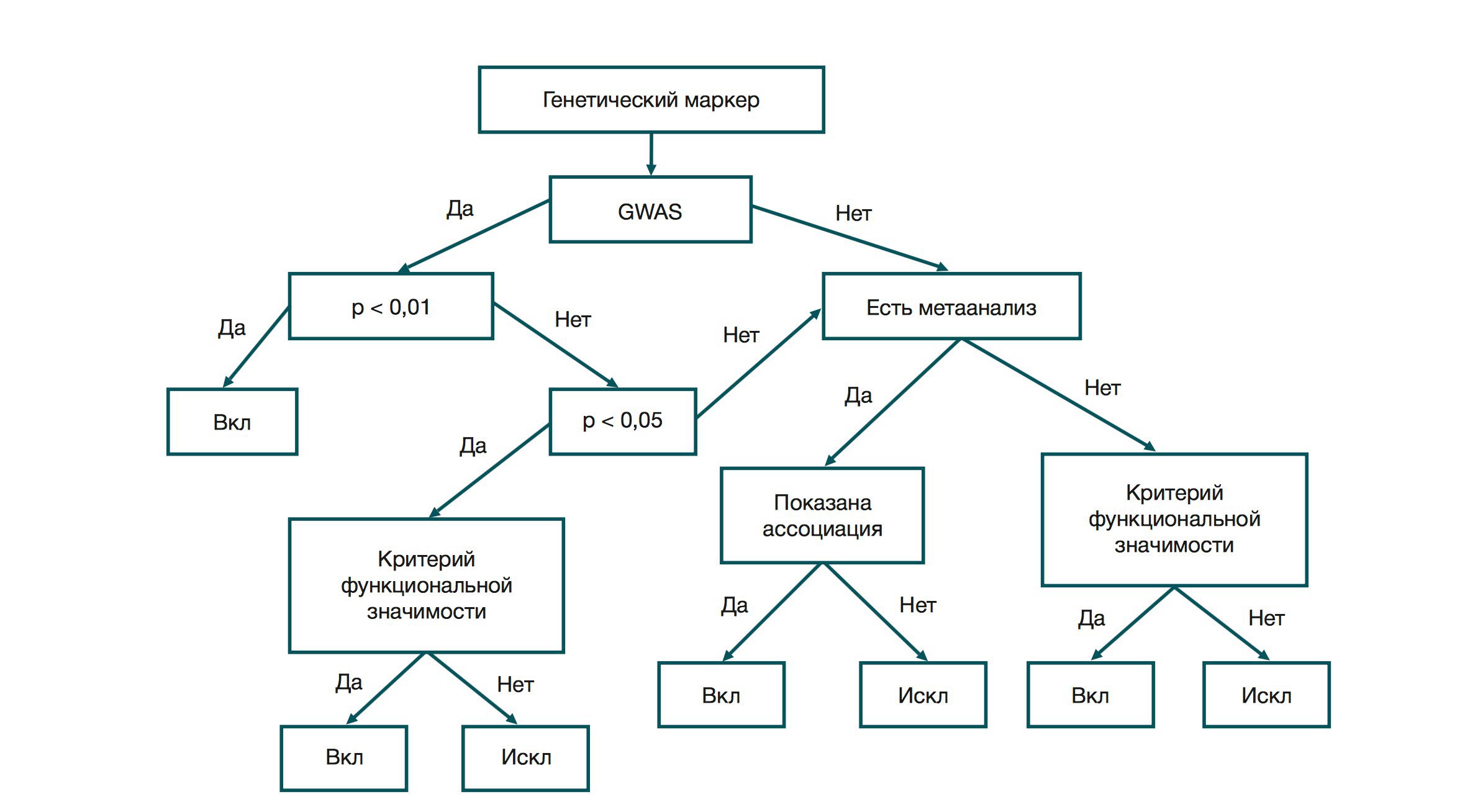
第一步是检查是否存在全基因组关联研究(GWAS)。 随着微芯片技术的发展,这一基因研究领域开始被积极使用。 该研究的目的是发现具有和没有特定特征的人的基因组之间的差异。 GWAS研究的特点是样本量大。 例如,大约30万人参加了
GIANT (人体测量学特征的基因组研究-人体测量学特征的基因组研究)。 该研究证实了遗传因素对肥胖症发展的严重影响。 如果关联假设不正确,则在患者和健康受试者中观察到关联“基因型-体征”的概率是实验的p值。 如果GWAS研究的该值小于0.01(针对多重性进行了调整),则多态性将成为疾病标记的简短清单。 如果它落在0.01-0.05的范围内,则必须符合功能重要性标准之一。
仅存在一个标准:已知多态性对性状产生影响的直接或间接机制。 如果某种物质的代谢途径是已知的(即,物质A转化为物质X的转化链),则知道该链中涉及哪些酶可能表明该多态性的相关性。 例如,我们知道一种激活叶酸以催化高半胱氨酸向蛋氨酸转化的酶。 蛋氨酸是一种必需氨基酸,随着同型半胱氨酸的积累,血管内皮可能受到损害。 即,我们可以说在编码酶活性中心的基因座处的取代是高半胱氨酸代谢降低的原因。 而且,这种单一多态性的存在不能保证疾病的发展。
如果根据GWAS结果,关联的p值大于0.05,则需要进行荟萃分析。 荟萃分析是一项研究,其中通过总结许多研究的结果来进行关联的识别。 如果在荟萃分析中显示出“基因型-表型”的关联,那么多态性就可以发挥作用。 如果没有荟萃分析数据,则通过功能重要性标准再次测试多态性。
由于这项工作的主要部分是研究出版物,因此有严格的标准来选择科学文章以寻找关联。 对于这些标准的GWAS研究:
- 样本量-初始研究中至少有750名患者;
- P值<0.01;
- 必须在至少一项研究中确认关联(对于罕见疾病不是必需的),并且出版物的影响因子必须至少为2。
对于旨在确定是否符合功能重要性标准的出版物,标准如下:
- 在研究参与者的组织(活体活检,尸检材料,术后材料)或生物体液的研究中应获取数据;
- 关联性应在有关科学出版物中通过实验获得;
- P值<0.05;
- 参与者的样本量应足够大,以便能够检测出遗传标记与特定发生频率的关联;
- 如果有几本出版物研究了该遗传标记与患病风险之间的关系,则进行分析选择:a)稍后(例如,2009年和2015年的两篇文章-2015年的一篇文章); b)对大量样本进行研究的出版物。
荟萃分析的结果(如果有)是优先事项。 荟萃分析的要求也很高:在出版物本身中,必须仔细选择来源,其中既要确认也要否认多态性与符号的关联。 应该指出用于搜索的信息和关键字的来源,以及包括和排除出版物的标准的依据(样本量,仅英文文章,参与者的人口统计特点等)。 要特别注意使用漏斗形图或敏感性分析对各个出版物进行所谓的偏差分析。 当分析中包含标记时,我们将重点关注哪些人群参与了研究。
尽管该技术本身早已投放市场,但这并不是某种“例行实践”,根据该实践,会编写大量手册。 DNA测试管道有效,这是其部分内容之一。 我们将逐步向您介绍其每个片段。