研究表明,越来越多的应用中使用了称为神经网络的计算机模型,可以学会使用与人脑相同的算法来识别数据中的序列。

大脑通过根据一组未知的规则调整许多化合物来解决其经典问题-训练。 为了揭示这些规则,科学家在30年前开始开发计算机模型,试图重现学习过程。 如今,在越来越多的实验中,很明显,这些模型在某些任务中的行为与真实大脑非常相似。 研究人员说,这种相似性表明大脑和计算机学习算法之间的基本契合。
计算机模型使用的算法称为
Boltzmann机 。 它是Jeffrey Hinton和Terry Seinowski于1983年
发明的 [事实上,在
1985年 -大约 翻译]。 作为对大脑中发生的多个过程的简单理论解释,它看起来很有希望,包括发育,记忆形成,物体和声音的识别,睡眠和唤醒周期。
“这是我们今天了解大脑的最好机会,”大学心理学,神经生物学和行为学教授苏·贝克尔说。 安大略省汉密尔顿市的麦克马斯特。 “我不知道一个模型来描述与学习和大脑结构有关的更广泛的现象。”
人工智能领域的先驱Hinton一直想了解大脑增强或减弱交流的规则-即学习算法。 他说:“我认为,为了理解某些东西,必须先构建它。” 多伦多大学计算机科学教授兼谷歌公司的欣顿说,按照物理学家的简化主义方法,他计划使用不同的学习算法来创建简单的大脑计算机模型,并查看其中的哪种算法会起作用。
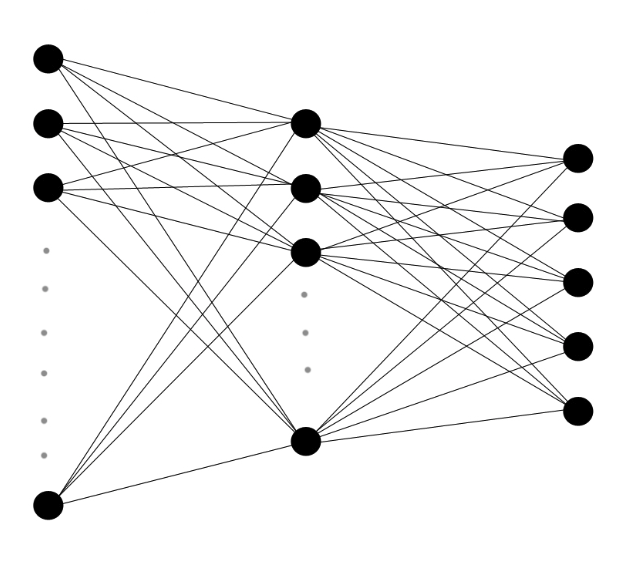 多层神经网络由人工神经元层与它们之间的加权连接组成。 我向传入的数据发送分层的一系列信号,然后算法确定每个连接的权重变化。
多层神经网络由人工神经元层与它们之间的加权连接组成。 我向传入的数据发送分层的一系列信号,然后算法确定每个连接的权重变化。在1980年代和1990年代,Hinton是19世纪逻辑的曾孙。GeorgeBoole的工作构成了现代计算机科学的基础,他发明了几种机器学习算法。 控制计算机如何从数据中学习的算法被用在称为“人工神经网络”的计算机模型中,该模型是由相互连接的虚拟神经元组成的网,这些网将信号传输到邻居,打开或关闭或“触发”。 当数据馈送到网络时,这会导致级联响应,并且基于这些响应的图片,算法会选择增加或减少每对神经元之间连接或突触的权重。
数十年来,许多欣顿计算机模型一直在繁琐。 但是,由于处理器能力的提高,对大脑和算法的了解的不断进步,神经网络在神经生物学中的作用日益增强。 Sejnowski [Sejnowski],生物研究所神经生物学计算实验室负责人。 加利福尼亚拉荷亚的萨尔卡说:“三十年前,我们有很粗略的想法; 现在我们开始测试其中一些。”
脑机
欣顿早期重塑大脑的尝试是有限的。 计算机可以在小型神经网络上执行其学习算法,但是缩放模型很快使处理器超负荷。 在2005年,Hinton发现,如果将神经网络划分为多个层,并在每个层上分别运行算法,从而大致重复大脑的结构和发育,则该过程将变得更加高效。
尽管欣顿在
两 本著名杂志上发表了他的发现,但那时神经网络已经过时了,他“努力使人们感兴趣”,微软研究院首席研究员李登说。 但是,邓小平认识了欣顿,并决定在2009年测试他的“深度学习”方法,从而迅速意识到他的潜力。 在接下来的几年中,学习算法已在越来越多的应用程序中得到实际应用,例如Google Now的个人助手或Microsoft Windows手机上的语音搜索功能。
玻尔兹曼机是最有前途的算法之一,它以19世纪的奥地利物理学家路德维希·玻尔兹曼(Ludwig Boltzmann)的名字命名,他开发了处理大量粒子的物理学分支,称为统计力学。 玻尔兹曼发现了一个方程,该方程给出了分子气体达到平衡时具有一定能量的概率。 如果用神经元替换分子,则结果将趋于相同的方程式。
网络突触始于权重的随机分布,然后根据一个相当简单的过程逐渐调整权重:将机器接收数据(例如图像或声音)过程中生成的响应电路与未输入数据时发生的机器随机响应电路进行比较。
 乔佛里·欣顿(Joffrey Hinton)认为,了解大脑学习过程的最佳方法是构建以相同方式学习的计算机。
乔佛里·欣顿(Joffrey Hinton)认为,了解大脑学习过程的最佳方法是构建以相同方式学习的计算机。每个虚拟突触都跟踪两个统计集。 如果在接收数据时比随机操作更频繁地触发与其连接的神经元,则突触的权重将增加一个与差异成比例的值。 但是,如果两个神经元在随机操作期间更经常一起触发,那么将它们连接起来的突触被认为太强和弱了。
在“训练”之后,最常用的Boltzmann机器版本工作得更好,它已在每一层上顺序处理了数千个样本数据。 首先,网络的下层以图像或声音的形式接收原始数据,并且以视网膜细胞的方式,如果神经元检测到其数据区域中的对比度,例如从亮到暗,则会触发它们。 它们的触发可以触发与它们相关的神经元的触发,具体取决于连接它们的突触的重量。 随着对成对虚拟神经元的触发与背景统计数据的不断比较,神经元之间有意义的联系逐渐出现并加剧。 指定突触的权重,并将声音和图像的类别内置到连接中。 使用来自其下一层的数据,以相似的方式训练每个后续层。
如果将汽车的图像馈送到经过训练可以检测图像中某些对象的神经网络,则下层如果检测到表明面部或终点的对比度,则将起作用。 这些信号将进入确定角度,车轮部分等的更高级别的神经元。 在较高级别,仅通过对汽车图像做出反应来触发神经元。
纽约大学数据科学中心主任Yann LeCun说:“网络上发生的事情的神奇之处在于它可以总结。” “如果您向她展示她从未见过的汽车,并且如果该汽车具有在培训期间向她展示的机器所共有的某些形式和特征,那么她可以确定这是一辆汽车。”
最近,由于Hinton多层模式,使用高速计算机芯片来处理图形以及可用于训练的图像和语音记录数量的爆炸性增长,神经网络加快了其发展速度。 网络能够正确识别88%的英语口语单词,而普通人可以识别96%的单词。 他们可以以相似的精度检测汽车和成千上万个其他物体,并且在过去的几年中,它们在机器学习竞赛中占据了主导地位。
建立大脑
没有人知道如何直接找出训练大脑的规则,但是大脑的行为与玻耳兹曼机器之间有许多间接的巧合。
两者都仅使用数据中的现有模式进行培训,无需监督。 欣顿说:“您的母亲没有告诉您一百万次有关图片显示的内容的信息。” -您必须学会在没有他人指导的情况下识别事物。 您研究类别之后,它们会告诉您这些类别的名称。 因此,孩子们了解了狗和猫,然后他们知道狗被称为“狗”,猫被称为“猫”。
成人的大脑不像年轻的大脑那样灵活,就像玻尔兹曼机器一样,它已经训练了100,000张汽车图像,看到另一个大脑后,它的变化不会太大。 她的突触已经具有对汽车进行分类的正确权重。 但是培训并没有结束。 新信息可以集成到大脑和玻尔兹曼机器的结构中。
在过去的二十年中,对梦中大脑活动的研究提供了第一个证据,表明大脑使用类似于玻耳兹曼算法的算法将新的信息和记忆纳入其结构。 神经科学家早就知道,睡眠在记忆巩固中起着重要作用,并有助于整合新信息。 1995年,Hinton和同事
提出 ,睡眠在算法中起基本作用,表示在没有输入数据的情况下神经元的活动。
欣顿说:“在睡眠期间,您只需弄清楚神经元的基本频率即可。” -在系统独立工作的情况下,您可以找到他们工作的相关性。 然后,如果神经元之间的相关性更高,则只需增加它们之间的权重即可。 如果减少的话,减轻体重。”
在突触层面,“该算法可以通过多种方式提供,”作为
BRAIN计划一部分的总统府顾问Sezhnowski说,这项研究获得了1亿美元的赠款,旨在开发研究大脑的新技术。
他说,大脑最容易使用玻耳兹曼算法,从白天建立突触到晚上减少突触。 威斯康星大学麦迪逊分校睡眠与意识研究中心主任
朱利奥·托诺尼 (
Giulio Tononi)发现,根据这种假设,突触中的基因表达改变了它们:突触生长相关的基因在白天更活跃,而收缩相关的基因突触-在晚上。
另一个选择是,“可以在梦中计算基线,然后可以在白天进行相对于基线的更改,” Sezhnowski说。 在他的实验室中,建立了详细的突触计算机模型及其所支持的网络,以确定它们如何收集有关清醒和睡眠模式的统计信息,以及何时突触强度发生变化以显示这种差异。
脑部困难
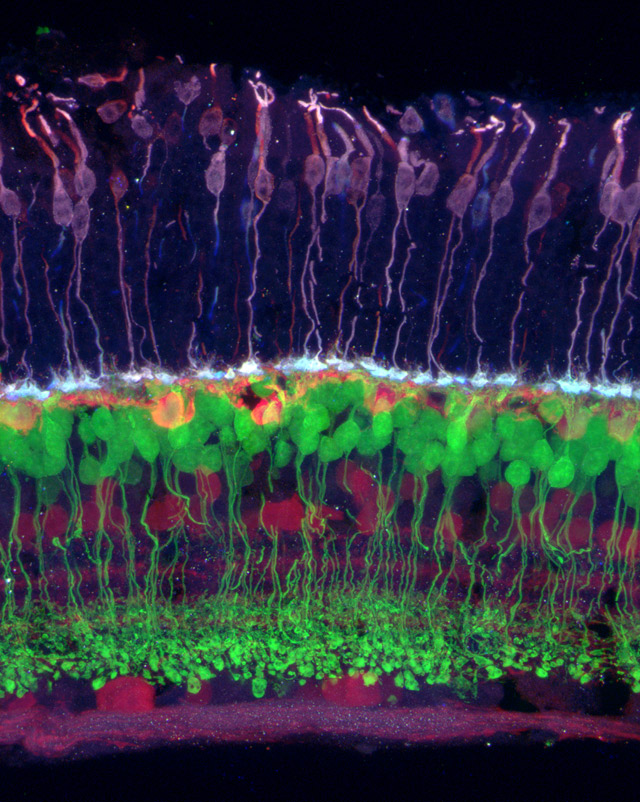 视网膜的图像,其中不同类型的细胞以不同的颜色表示。 颜色敏感(紫色)连接到水平(橙色),水平连接到双极(绿色),而后者-视网膜和神经节细胞(紫色)。
视网膜的图像,其中不同类型的细胞以不同的颜色表示。 颜色敏感(紫色)连接到水平(橙色),水平连接到双极(绿色),而后者-视网膜和神经节细胞(紫色)。玻耳兹曼算法可能是大脑用来微调突触的众多算法之一。 在1990年代,几个独立的小组开发了一个理论模型,说明视觉系统如何有效地编码流向视网膜的信息流。 该理论假定,在视觉皮层的较低层中存在类似于图像压缩的“分散编码”过程,因此,视觉系统的后期工作效率更高。
该模型的预测逐渐通过越来越严格的测试。 在《 PLOS计算生物学》
上发表的
一篇论文中,来自英国和澳大利亚的计算神经科学家发现,当使用由欣顿在2002年发明的专家产品分散编码算法的神经网络处理与活猫一样的异常视觉数据时, (例如,猫和神经网络研究条纹图像),它们的神经元产生几乎相同的异常连接。
加州大学伯克利分校红木理论神经生物学中心主任,计算神经科学家布鲁诺·奥尔斯豪森(Bruno Olshausen)说:“我们认为,信息到达视觉皮层时,大脑会将其呈现为分散的代码。”零散编码理论。 “仿佛一台Boltzmann机器正坐在您的脑海中,试图理解分散代码元素之间存在的联系。”
奥尔斯豪森(Olshausen)和研究小组使用视觉皮层较高层的神经网络模型来显示尽管图像运动,但大脑如何能够
保持视觉输入的稳定感知 。 在另
一项研究中,他们发现用Boltzmann机器很好地描述了看着黑白胶片的猫的视皮层中神经元的活动。
这项工作的可能应用之一是创建神经假体,例如人造视网膜。 奥尔斯豪森说,如果您观察“信息在大脑中的格式,您将了解如何刺激大脑使其认为自己正在看到图像”。
Sezhnowski说,了解突触的生长和减少算法将使研究人员能够改变它们,并了解神经网络的功能是如何被破坏的。 他说:“然后可以将它们与人们众所周知的问题进行比较。” -几乎所有的精神障碍都可以用突触的问题来解释。 如果我们能更好地理解突触,我们就能了解大脑如何正常运作,如何处理信息,如何学习以及例如在患精神分裂症时出了什么问题。”
使用神经网络研究大脑的方法与“
人类脑计划”的方法形成鲜明对比。 这是瑞士神经科学家亨利·马尔克拉姆(Henry Marcram)公布的计划,该计划使用超级计算机创建人脑的精确模拟。 与欣顿的方法不同,欣顿的方法从一个大大简化的模型开始并遵循逐步复杂化的道路,马克兰姆希望立即包含尽可能多的数据,直至单个分子,并希望因此他将具有完整的功能和意识。
该项目从欧盟委员会获得了13亿美元的资金,但欣顿认为,这种大型仿真将失败,陷入太多没人知道的运动部件中。
另外,欣顿不相信仅凭其图像就能理解大脑。 此类数据应用于创建和完善算法。 他说:“要创建类似的理论,就需要对学习算法空间进行理论思考和研究,”博尔兹曼的机器说道。 Hinton的下一步是开发用于训练甚至更多类似于大脑的神经网络的算法,其中突触将神经元连接在一层内,而不仅仅是在不同层之间。 他说:“主要目标是了解使每个阶段的计算复杂化所能获得的好处。”
假设是,更多的连接将导致更强的反向循环,根据奥尔斯豪森(Olshausen)的说法,这很可能有助于大脑“填补缺失的细节”。 上层干扰来自下层的处理部分信息的神经元的工作。 他说:“所有这些都与意识密切相关。”
人脑仍然比任何模型都复杂得多。 它更大,更密集,效率更高,具有更多的互连关系和复杂的神经元-并且可以同时使用多种算法。 Olshausen建议我们了解视觉皮层活动的大约15%。 他说,尽管模型正在发展,但是神经科学仍然“类似于牛顿之前的物理学”。 尽管如此,他仍然相信,基于这些算法的工作过程将有一天能够解释大脑的主要难题-来自感官器官的数据如何转化为主观的现实感。 奥尔斯豪森说,“意识是从现实中产生的,它是一种非常复杂的玻尔兹曼机器。”