
尽管存在明显的障碍和困难,这些障碍有时会阻碍基因工程(GI)产品的开发和实施,但是如果没有现代生物学家的这项重要而多样化的技术成果,就无法想象21世纪。 胃肠道中最常用的生物是细菌。
什么是地理标志,为什么我们需要它? 为什么细菌在基因工程师中如此受欢迎? 将所需基因导入细菌的最简单方法是什么? 使用这些生物体会遇到什么困难? 之前发生了什么:创造了第一个基因工程细菌或发现了DNA和基因组的结构? 了解有关此内容以及更多内容的信息。
0.生物学简短教育计划
本段简要介绍了所谓
的分子生物学中央教条 。 如果您具有分子生物学的基础知识,请随时跳至步骤1。
 一张图片中分子生物学的中心教条
一张图片中分子生物学的中心教条因此,让我们开始吧。 关于发育的所有阶段以及任何生物的特性的所有信息,无论是
原核生物 (细菌),
古细菌还是
真核生物 (其余均为单细胞和多细胞),均由基因组DNA编码,DNA是两条相互互补的多核苷酸链的复合物,形成双螺旋(互补DNA核苷酸:AT和GC)。 真核染色体是线性双链DNA分子,原核染色体是环状的。 通常,基因只占整个基因组的一小部分(在人类中约为1.5%)。
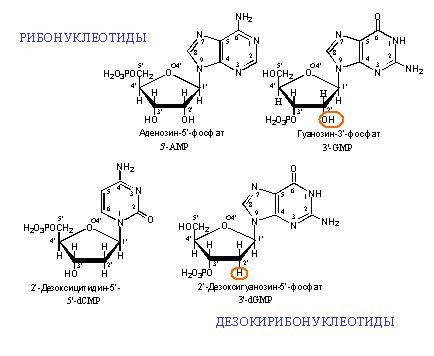 DNA和RNA单体的例子。 DNA名称中的“脱氧”表示在位置2'处不存在氧原子(在图中,位置2'用红色圈出)。
DNA和RNA单体的例子。 DNA名称中的“脱氧”表示在位置2'处不存在氧原子(在图中,位置2'用红色圈出)。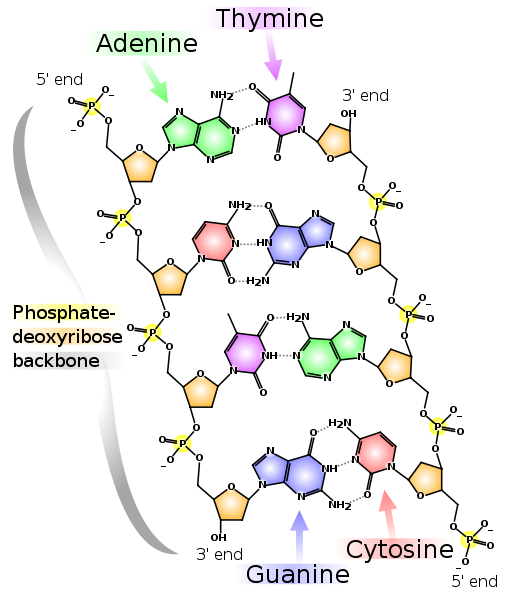 两条互补的DNA链。 虚线显示了碱基之间的氢键。 可以看出,腺嘌呤和胸腺嘧啶在彼此之间形成两个氢键,而鸟嘌呤和胞嘧啶形成三个氢键。 因此,GC键更牢固,并且富含GC的双链DNA片段更难分离成两条链。
两条互补的DNA链。 虚线显示了碱基之间的氢键。 可以看出,腺嘌呤和胸腺嘧啶在彼此之间形成两个氢键,而鸟嘌呤和胞嘧啶形成三个氢键。 因此,GC键更牢固,并且富含GC的双链DNA片段更难分离成两条链。请注意,每个链都有一个5'末端和一个3'末端。 可以看出,在左链的5'端附近是右链的3'端,反之亦然,因此这些链称为“反平行”。 RNA也有一个5'和3'末端。 选择位置5'和3'本身是为了指示开始和结束,因为正是通过它们,在DNA和RNA的链中形成了共价键。
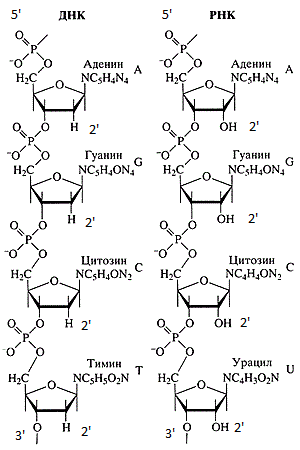 DNA和RNA链。
DNA和RNA链。DNA和RNA序列始终从5'端到3'端记录。 造成这种情况的原因有很多:
- 新的DNA和RNA链的合成从5'端开始( DNA聚合酶 (酶在DNA或RNA基质上合成互补的DNA链)和RNA聚合酶 (在DNA或RNA基质上合成互补RNA链的酶)方向3'-> 5',因此在方向5'-> 3')上合成了一条新链。
- 核糖体读取密码子,沿着mRNA以5'-> 3'的方向移动。
- 氨基酸序列沿5'-> 3'方向写在DNA编码链中(mRNA的重要部分是DNA编码区的精确复制,当然是胸腺嘧啶被尿嘧啶代替,在2'位置带有羟基(-OH)而不是氢);
- 最后,拥有一个普遍接受的记录规则是很方便的。
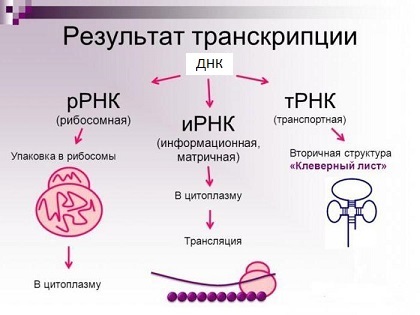
基因是基因组DNA的一部分,它定义了RNA分子核苷酸的序列:
- 编码RNA:信使RNA(mRNA),其中相应蛋白质的氨基酸序列被编码为密码子。 您还可以找到名称“ informational RNA”,其缩写看起来像“ mRNA”;
- 非编码RNA:转运RNA,核糖体RNA等。
tRNA的作用是将氨基酸递送至mRNA-核糖体复合物。 此外,tRNA负责识别mRNA密码子;为此,每个tRNA都包括所谓的“反密码子”(anticodon)-与mRNA密码子互补的三联体。
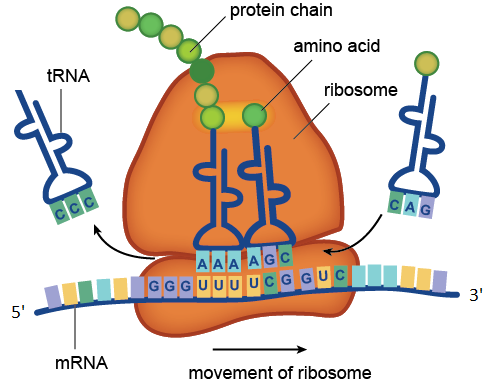 核糖体催化翻译过程。 在图中,mRNA中包含的UUU和UCG密码子被tRNA分子中包含的AAA和AGC反密码子识别。 带有反密码子CCC的运输RNA已经将其氨基酸赋予了不断增长的蛋白质链,带有反密码子CAG的tRNA正在排队等待。 图中所示的mRNA分子图由四个密码子组成:GGGUUUUCGGUC。 密码子GGG对应于氨基酸甘氨酸,UUU对应于苯丙氨酸,UCG对应于丝氨酸,GUC对应于缬氨酸。 因此,该mRNA区域编码具有氨基酸序列甘氨酸-苯丙氨酸-丝氨酸-缬氨酸的蛋白质片段。
核糖体催化翻译过程。 在图中,mRNA中包含的UUU和UCG密码子被tRNA分子中包含的AAA和AGC反密码子识别。 带有反密码子CCC的运输RNA已经将其氨基酸赋予了不断增长的蛋白质链,带有反密码子CAG的tRNA正在排队等待。 图中所示的mRNA分子图由四个密码子组成:GGGUUUUCGGUC。 密码子GGG对应于氨基酸甘氨酸,UUU对应于苯丙氨酸,UCG对应于丝氨酸,GUC对应于缬氨酸。 因此,该mRNA区域编码具有氨基酸序列甘氨酸-苯丙氨酸-丝氨酸-缬氨酸的蛋白质片段。核糖体RNA是核糖体必不可少的成分。 rRNA的主要功能是确保翻译过程:它涉及使用tRNA的衔接子分子从mRNA中读取信息,并催化与tRNA相连的氨基酸与不断增长的蛋白链之间肽键的形成。
 RNA分子的主要类型(实际上,还有更多)。
RNA分子的主要类型(实际上,还有更多)。另一方面,蛋白质是通过肽键共价连接在一起的氨基酸链(您可以在扰流板中进一步看到它的样子)。 合成后,氨基酸链应具有一定的空间结构-“
构象 ”(
他们已经告诉我有关
Geektimes蛋白质的空间结构)。 另外,许多大蛋白质实际上由疏水相互作用和氢键结合成单个稳定结构的几种蛋白质组成。 在这种情况下,每个“构建蛋白”被称为“亚基”,而所得的大蛋白被称为“多亚基”。
 核糖体复合物。 图片取自OlegKovalevskiy出版的“蛋白质分子模型的3D打印” 。
核糖体复合物。 图片取自OlegKovalevskiy出版的“蛋白质分子模型的3D打印” 。对于编码蛋白质的基因,解码遗传信息的过程如下所示:
- RNA聚合酶识别启动子并与其结合(如果它是“开放的”,我们将进一步讨论启动子活性的调节);
- 根据互补原理,DNA基质上的RNA聚合酶合成模板RNA(真核生物中的pre-mRNA)或现成的功能性mRNA(原核生物)中的“空白”。 这个过程称为“转录” ;
- (仅在真核生物中)前mRNA分子经过修饰(“成熟”)并成为功能性mRNA;
- mRNA被核糖体识别, 核糖体是一种酶,可解码mRNA的三联体密码,并以此为基础合成肽/蛋白质。 核糖体从中构建蛋白质的氨基酸与转运RNA( tRNA )形成复合物。 这个过程称为“广播” ;
- 肽/蛋白质可以经历翻译后修饰(类似于mRNA的“成熟”)并具有功能。 一个重要因素是,真核生物的翻译后修饰系统比原核生物更为复杂和多样,因此,并非每种真核蛋白都能被细菌正确合成。
除了编码区,基因组还包含许多片段,它们也以一种或另一种方式参与转录。 RNA聚合酶可识别位于该基因附近且称为启动子的图(他们说该基因处于该启动子的控制之下)。 不同的启动子被不同的RNA聚合酶识别。 例如,如果其中不合成相应噬菌体的RNA聚合酶,则在
噬菌体启动子控制下的基因将不会被转录成细菌。
一般而言 。
每个基因还可以具有几个调节序列,其可以直接位于启动子附近(甚至与启动子重叠),也可以位于距启动子数万个核苷酸对的位置。 转录增强元件被称为
“增强子”,转录抑制元件被称为沉默子,与之相互作用的蛋白质被称为
转录因子 。 尽管习惯上将转录因子称为转录起始复合物的必需成分,但如果没有转录因子,则原则上不可能进行转录。 事实是,只有在真核生物和古细菌中开始在DNA基质上合成RNA分子时,整个超分子复合物的组装才是必需的。 最简单的此类复合物包括RNA聚合酶全酶和六个所谓的
“常见转录因子” (TFIIA,TFIIB,TFIID,TFIEE,TFIFF和TFIIH)。 该复合体本身称为
“转录预初始化复合体” (
视频 ,复合体的每个组成部分都以一种颜色或另一种颜色突出显示)。
原核转录复合体是完全不同的,因此将真核基因与真核启动子嵌入细菌中没有任何意义。 真核生物和古细菌的常见转录因子的原核类似物可以称为蛋白质,称为
“σ因子” 。
 原核转录复合体。 图中所示的字母是相应子单元的公认名称。 大肠杆菌家庭基因的 σ70-σ因子
原核转录复合体。 图中所示的字母是相应子单元的公认名称。 大肠杆菌家庭基因的 σ70-σ因子原核生物和真核生物的基因组具有许多共同特征,而前面提到的分子生物学中央教义对于两个王国都是正确的。 但是,也存在许多重大差异。 例如,一种细菌的特征是操纵子系统-操纵基因组成的一组基因,它们参与同一过程,并且不会单独转录,而是作为一个长mRNA的一部分而转录的。 在真核生物中,一切都完全不同:一个过程中涉及的基因分散在不同的染色体上,并且基因本身被
内含子的非编码区分为
外显子的编码片段。 在这种情况下,首先基因被完全转录,然后已经在RNA阶段被内含子切除,外显子交联形成编码mRNA。 此过程称为
拼接 。 同时,并非所有可用的外显子都可以缝合到完成的mRNA中,但是在这种情况下,只有其中一部分称为
“替代剪接” 。 因此,真核细胞可以在转录同一基因的同时合成几种蛋白质。 除其他事项外,这产生了非常重要的后果:“将真核基因“如在染色体上”插入到细菌中通常是没有意义的,因为细菌根本无法剪接。
还有另一个重要的区别。 原核生物的特征是在环“染色体”(所谓的
“质粒”) -小环状双链DNA分子外部存在基于DNA的遗传物质。 另外,原核生物缺乏包括细胞核在内的细胞器:细菌细胞的所有成分都可以自由穿越细胞内空间。 然而,真核生物没有质粒,但是基因组中存在
质体和
线粒体 ,其中包含质粒(根据最充分的假说,质体和线粒体是古代单核细胞捕获的蓝细菌和细菌的基因组原核结构的“后裔”)。 而且,真核生物已经典型地存在被其自身的膜包围的核和其他细胞内区室。 因此,与细菌的基因工程相比,真核细胞的基因工程需要不同的方法。
遗传密码本身的结构如下。 每个基因/外显子由一组三联体/密码子组成-三核苷酸的序列,它们之间没有缺口。 三联体组织对于DNA中的基因和mRNA的编码部分均有效。 在翻译过程中,带有特定氨基酸的转运RNA(tRNA)可“识别”其相应的三字母三联体。 核糖体将氨基酸与tRNA断开连接,并将其连接至正在生长的氨基酸链,在翻译结束时,核糖体将立即变成成熟的功能齐全的蛋白质,或者在其进行一系列修饰之前。 在这种情况下,每个三联体仅对应一个氨基酸,但是几个不同的密码子可对应一个氨基酸。 这是可以理解的,因为在标准遗传密码中,有61个编码密码子,而
只有20个蛋白原性氨基酸 (总密码子为4 * 4 * 4 = 64,但是其中三个是非编码的,相反,它们充当停止翻译的信号,被称为“停止密码子”)。
 标准遗传密码中的密码子。 感谢维基百科的图片。
标准遗传密码中的密码子。 感谢维基百科的图片。因此,蛋白质正是那些正是基因组DNA与人体特性之间链中的最后一个环节的元素,即所谓的
“表型” 。 因此,为了以某种方式改变对我们很重要的生物的特征,我们需要以某种方式改变其DNA,从而某些蛋白质出现在其细胞中,这将为我们提供目标结果。 这是所有基因工程的基本思想。
1)基因工程中使用细菌的目的是什么,为什么?
因此,我们弄清楚了基因组DNA序列如何以及为什么会影响人体的特性和特征。 当然,如果仅由一个基因完全决定性状,那将是非常好的-插入一个小片段不再是一个严重的问题。 例如,植物对除草剂或害虫的抗性通常由单个基因决定,因此在这种情况下创造具有所需抗性的品种并不困难(与将这种植物推向市场相反)。 对于细菌的许多抗生素抗性也是如此(实际上,细菌具有许多针对抗生素的保护机制,但它们以独立的方式起作用)。 相反的例子是,例如,科学家试图教植物从大气中吸收氮。 事实是,植物的唯一氮源是土壤,其中微生物通过微生物合成了适合植物吸收的含氮化合物(或由经过照顾的园丁或路过的狗以肥料的形式引入)。 显然,创建具有替代营养机制的植物对农业非常有益。 但是,不幸的是,该过程非常复杂,以至于其从微生物“转移”到植物的问题至今尚未解决。
最后,如果我们的目标是获得用于任何特定目的的蛋白质(研究蛋白质的结构和功能,基于该蛋白质创建药物或实验室试剂等),那么显然,我们也很高兴将单个基因整合到细胞中,在这种情况下,习惯上将其称为“生产者有机体”。
基因工程中的细菌是产生以下物质的潜在来源:
- 在实验室或工业规模上我们需要的蛋白质的生产者;
- 在某种程度上将一种化合物化学转化为另一种化合物的活性剂,无论这是食品工业中的发酵过程,还是通过向土壤中引入“细菌肥料生产者”或利用废钢为植物生长创造了更有利的条件;
- 基因的klonotek (一个主题,对其进行良好的描述会增加文章的大小,以致不雅);
- 具有医学意义的药物,例如用于恢复消化道微生物群的药物;
- 根癌土壤杆菌的细菌菌株,用于植物的后续遗传修饰。
*我可能会忘记一些东西,因此欢迎在评论中添加内容。
一个有趣的事实是,细菌基因工程领域的第一个成功实验早在Watson和Crick具有里程碑意义的工作之前就进行了。 而且,在这些实验的基础上,事实证明信息包含在DNA中,此后科学家无法将时间花在有关RNA和蛋白质的假设上。
这项工作是在1944年进行的,以
弗雷德里克·格里菲斯(Frederick Griffith)的
工作为基础,被称为
艾弗里(Avery),麦克劳德(MacLeod)和麦卡锡(McCarthy)实验 ,在此期间,发现死亡的致病性和存活性非致病性肺炎球菌菌株的感染会导致疾病的发展,而单独地,它们不会引起明显的症状。 从该实验得出的结论是,被杀死的细菌能够将某种东西传播给非致病性的“同事”,结果使其变得危险。 但是,它们彼此之间会传递什么呢? 到1944年,已经有了三种主要候选药物:DNA,RNA和蛋白质。 为了建立转运蛋白,进行了一项优雅的实验:当时,已经有能够分别破坏DNA(DNase),分别破坏RNA(RNase)和分别破坏蛋白质(蛋白酶)的酶。 结果表明,只有在用DNase处理死的致病菌株时,才不会发生致病特性的转移,并且不依赖于用RNase和蛋白酶处理药物。
因此,证明了DNA是有关体征信息的载体。 另外,清楚地表明外源DNA分子自发渗透到细菌细胞中是可能的。
为什么细菌如此流行并带有明显的缺陷(例如,缺乏真核翻译后修饰)? 一切都很简单。
它们操作简单,易于使用,不需要昂贵的营养培养基。2)如何创建遗传结构并将其引入细菌
现代细菌的遗传工程主要是引入质粒载体(包含靶基因和一组其他必需元件的修饰细菌质粒,将在下面进行讨论)。改变细菌染色体的可能性较小,但是这种方法也不奇怪:例如,在创建实验室斑块中流行的一种菌株的过程中,使用基于噬菌体 λ 的载体将T7噬菌体RNA聚合酶基因引入了大肠杆菌染色体中。研究人员通常会选择将基因导入质粒载体的三个原因:一种典型的与细菌相互作用的质粒载体是一个小的环状双链DNA分子,该分子在特定启动子的控制下携带目标蛋白质基因,并带有许多必要的基因和调控元件,其存在确保了细胞中质粒的量恒定(``复制控制'')。显然,即使在超高效合成mRNA的情况下,如果载体在细菌中以一对碎片的形式存在,该载体也几乎没有用:在分裂过程中,没有必要质粒的子细胞形成的可能性将是微不足道的。除基因和启动子外,质粒载体的主要成分还有:- ori是质粒复制的起源区域。需要保持恒定数量的质粒及其子细胞的遗传;
- — , , , . , , (« »). , , . , .
, β- (GUS). , . , . — (GFP) ( GUS GFP );
- , ( — , — );
- — , ( ). , «» .
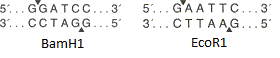 由图可知限制的站点内切酶BamH1位和的EcoRⅠ小。两种酶都从六个碱基对中识别一个特定位点,并在不同位置引入单链断裂(由三角形箭头指示)。在这种情况下,链断裂的点不一致,这意味着形成了“粘性末端”(如果一致,则形成了“钝末端”)。
由图可知限制的站点内切酶BamH1位和的EcoRⅠ小。两种酶都从六个碱基对中识别一个特定位点,并在不同位置引入单链断裂(由三角形箭头指示)。在这种情况下,链断裂的点不一致,这意味着形成了“粘性末端”(如果一致,则形成了“钝末端”)。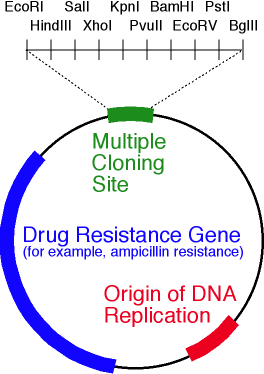 质粒载体的简化方案。该图显示了ori,抗生素抗性基因和含有10个限制性核酸内切酶位点的多接头。好吧,载体就在我们手中。如何在其中嵌入基因?无论如何,我在哪里可以得到这个基因?假设我们知道所需基因的核苷酸序列。然后执行以下操作:
质粒载体的简化方案。该图显示了ori,抗生素抗性基因和含有10个限制性核酸内切酶位点的多接头。好吧,载体就在我们手中。如何在其中嵌入基因?无论如何,我在哪里可以得到这个基因?假设我们知道所需基因的核苷酸序列。然后执行以下操作:- , ;
- .
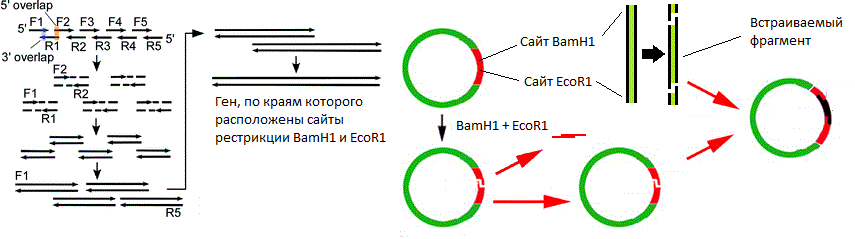 ( ). .
( ). ., , , . , (
BamH1 EcoR1 ) , , « » . , . ,
-,消除了双链DNA分子的链断裂。基因装配的另一个重要因素是不同生物体的各种密码子频率不同的事实,而在细胞中通常有更多的tRNA对应于更多的“流行”密码子。由于许多氨基酸是由多个密码子编码的,因此很容易将基因从一种生物体复制到另一种生物体中,我们很有可能会在翻译过程中遭受严重的延迟。的确,如果这种基因的许多密码子在新生物中很少见,那么当所需的tRNA最终到达时,核糖体将等待更长的时间。 , , , , , . E. coli .现在关于启动器的几句话。合适的启动子的选择非常重要,因为转录过程很大程度上取决于它。启动子有条件地分为强,中和弱。启动子的“强度”取决于基因在其控制下的转录活性,在所有其他条件相同的情况下:转录越活跃,启动子越强。显然,当我们要创建蛋白质生产者时,我们应该从强大的启动子开始。在某些情况下,过快的转录(因此,主动翻译)会损害细胞,在这种情况下,您可以尝试使用较弱的启动子。尽管实际上,影响一个现有生产者的转录活性比创建一个新生产者要容易得多。
, , , , , . E. coli .现在关于启动器的几句话。合适的启动子的选择非常重要,因为转录过程很大程度上取决于它。启动子有条件地分为强,中和弱。启动子的“强度”取决于基因在其控制下的转录活性,在所有其他条件相同的情况下:转录越活跃,启动子越强。显然,当我们要创建蛋白质生产者时,我们应该从强大的启动子开始。在某些情况下,过快的转录(因此,主动翻译)会损害细胞,在这种情况下,您可以尝试使用较弱的启动子。尽管实际上,影响一个现有生产者的转录活性比创建一个新生产者要容易得多。. . , ( 10% ), -
! . , «» « ». :
- 基于乳糖操纵子大肠杆菌 ( lac- peron)和强启动子的调控元件的系统。
事实是大肠杆菌有其自身的营养规则。 首先,存在一种抑制lac- peron活性的机制,其仅在乳糖不进入细胞时才被激活。 这是合乎逻辑的:为什么浪费能源对合成没有什么用呢? 但是,一旦乳糖开始以足够的量进入细胞,这种机制就会关闭。
但是,存在抑制lac- peron活性的第二种机制。 如果培养基中存在葡萄糖,则细胞仅以葡萄糖为食,因为它激活了抑制lac- peron转录的第二种机制。 因此,只有细胞周围的空间只有乳糖时, lac- peron才有活性。 乳糖操纵子的负号是一个非常弱的启动子,因此,在生产菌株中,它被一个强启动子代替。 强启动子通常来自病原体。 从细菌病毒- 噬菌体中分离出最广泛用于原核生物基因工程的最强启动子。 例如,T7噬菌体启动子被广泛使用。
顺便说一下,还从病毒中分离出一些用于植物基因工程的强启动子,例如,这是花椰菜花叶病毒的启动子。

如上所述, 大肠杆菌不具有识别噬菌体启动子的RNA聚合酶;因此,预先将相应噬菌体的RNA聚合酶基因插入生产者中。
流行的基于大肠杆菌的蛋白质合成系统在细菌RNA聚合酶启动子的控制下携带T7噬菌体RNA聚合酶基因,该启动子受lacperon机制调控。 如果在“噬菌体T7启动子+启动子型lacperon的调控”复合物的控制下用携带靶基因的载体转化该菌株,那么就会出现抑制靶基因转录的两级机制。
使用这种设计时,葡萄糖和乳糖会同时添加到营养培养基中。 在一段时间内,细胞将以葡萄糖为食并安静地分裂,因为完全抑制了外源蛋白质的合成。 等到葡萄糖耗尽并且细胞转变为乳糖代谢时,培养物中就已经有足够的生物量,这正是开始合成所需蛋白质的时候。 该过程称为“自动感应”。
您可以用另一种方法来做:不要将葡萄糖和乳糖添加到营养培养基中,然后,当培养物达到所需密度时,添加细胞摄取乳糖所需要的量,但是不能代谢或破坏它。 现在, IPTG被用作这种电感器。
- 基于噬菌体 λpL启动子调控机制的系统。
此启动子被cI阻遏蛋白灭活。 同时,发现了这种蛋白的热敏形式,称为cI857:该转录因子在约30°C的温度下仍保留功能,而在42°C时失去该功能。 因此,当使用这样的系统时,细菌培养物首先在30℃下生长至所需密度,然后将温度升高至42℃,从而开始合成靶蛋白。
好了,向量是设计好的。 然后,小的事情是找到一种合适的方法将其引入细菌细胞。 但这是一个完全不同的故事。