在哈布雷(Habré)上有大量关于神经网络的文章,其中有一个带有箭头的圆圈形式的神经元图片,带有神经元线条的图片以及权重和符号乘积之和的强制性公式。 这些文章经常因其与学习如何画猫头鹰的明显性和相似性而惹怒了一位受人尊敬的公众。 在本文中,我将走得更远-即使在这里也不会。 没有数学,就没有与大脑的比较。 您不太可能从本文中学到一些实用的知识,而且上述所有内容对于您来说似乎太明显了。 本文的目的是一个问题:借助神经网络可以做什么? 不是Yandex,不是Google,不是Facebook,而是您-拥有五年的网络开发人员和三年的笔记本电脑经验。
现在,在神经网络(以下简称为NS)周围存在很多噪声。 因此,我决定根据它们来制造一些产品。 然后他问自己:我需要什么? 然后他回答了自己(是的,我想和一个聪明的人聊天):需要三件事-神经网络领域的知识,用于训练的数据和用于训练神经网络的硬件。 顺便说一句,在我听到youtube上的许多视频后,演讲者说这些是NS复兴的原因:改进的算法(知识),大量数据的可用性以及现代计算机(硬件)的功能。 我的想法和专家的话语如此吻合,这令人鼓舞,因此,我将进一步讨论这三件事:数据,知识和硬件。
资料
数据的性质和类型取决于您要应用NS的区域。
现代的NS开始解决诸如图像,面部,语音识别中的对象识别之类的艰巨任务,能够自己玩电子游戏并赢得了成功。
抒情离题当然,在许多方面,NS周围的炒作和泡沫是时尚,病毒性,浪漫名称,与大脑的类比和强大的AI梦想的影响。 确实,您会同意,如果将这些技术称为“通过梯度下降法进行矩阵乘法和参数优化”,那么所有这些听起来就不会那么令人印象深刻,并且也许不会引起太多关注。 有人会说,用他的名字命名地狱,不仅因为它们如此受欢迎,而且还引起了令人惊讶的效果-看看这些网络在做什么,他们就赢了! 是的,但是当AI赢得国际象棋时,很少有人开始对搜索进行深入的崇拜,并且记者没有写出A-star将接管世界,并且程序员也没有大量研究它。
国民议会除其他外,笼罩在一个神秘的光环中-没有人确切地了解他们如何执行工作:一系列非线性功能,许多重量的矩阵,神秘的术语和因素-所有这些看起来都像是女巫的大桶,在那里她抛出了各种根,蝙蝠的翅膀和龙血。 但是回到文章的问题。
要训练NA,需要大量数据-数十万,数百万个示例。 您可以使用自制的Internet采集卡找到并下载这样的堆吗? 我也这么认为 但是有一些问题:
- 为了与老师一起训练,必须为数据加上标签。 有人应标记此数据,将其分配给不同的类别,并提供数值估计。 如果最初不是出于某种原因(例如,您只有音频,而没有成绩单),则需要付出巨大的努力。 当然,有些培训没有老师,也有增援等,但是它们可以解决其他问题(简化,而不是分类和回归(实际上,确定未知功能的价值),而是聚类或选择最佳措施)。 鉴于本文的篇幅有限,我将不涉及这个问题。
- 无论什么意思,数据都应均匀分布。 这意味着,如果您甚至拥有数百万条包含有关宝马和道奇的信息的数据,但几乎没有有关福特和马自达的信息,那么国民议会将永远无法充分汇总这些数据,甚至更糟的是,这会抬高价格或吸引大笔资金。好斗的外观。
- 您需要对数据的性质有很多了解,以便能够突出显示重要功能并可能对NS施加一些限制。 是的,多层NS是任何连续函数的通用逼近器,但是没有人说它会很快。 看起来很奇怪,但是限制越多,NS就能学习得越快。 为什么NS在图像处理方面变得如此出色? 因为聪明人将信息放在这些网络的体系结构中的图像上。 他们创建了单独的一类网络-卷积网络,该网络从一组像素中获取数据,以不同的方式压缩图像,进行数学变换,其目的是抵消偏移,变换和不同摄像机角度的影响。 这是否适合其他数据类型? 几乎没有 它适用于角度携带重要信息的图片吗? 谁知道
知识点
在国民议会中,存在许多超参数,它们在原理上强烈影响工作的速度和收敛。 您可以重新训练,陷于局部最大值,进行数周甚至更多的拉伸训练。 您将拥有NS架构知识,操作原理,并且您是一名程序员。 有大量的机器学习框架-theano,tensorflow和其他框架。 但是设置诸如学习速度,选择时间,选择正则化及其参数,选择激活函数等参数是一个耗时的实验过程。 由于缺乏精确的策略以及需要为每个任务手动配置和选择参数,许多人将其称为学习NS艺术的过程。
资源资源
您需要多次处理大量的例子,很多次:您给出了例子,NS稍微调整了权重,您再次给出了相同的例子,NS再次调整了权重-并且有很多“时代”。 如果使用交叉验证,则还将不同分区的数据提供给训练样本和验证样本,以便NS不会对同一数据进行再训练。
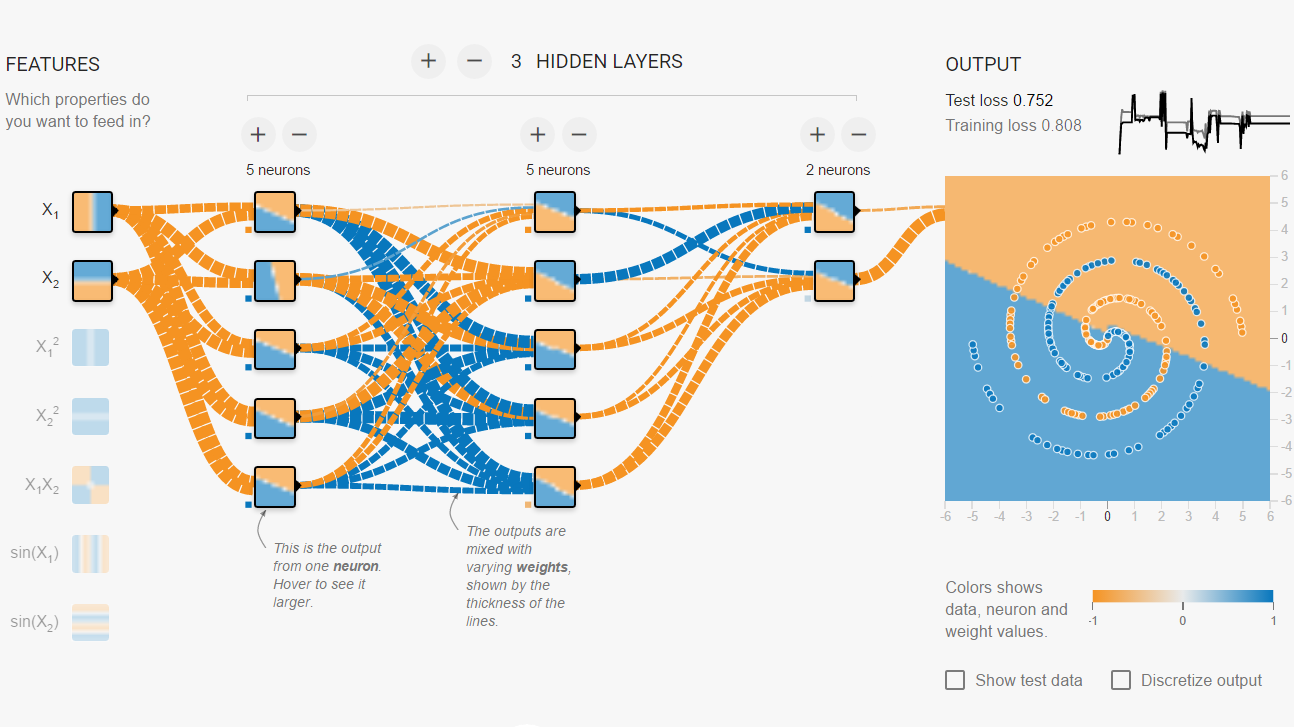
您可以负担大约什么资源? 我想购买一台基于Kaby Lake 7700K(或Razen 1800X)的高端计算机,其中有两块NVidia GTX 1080图形卡使用SLI一起工作。 而且,它的性能与Top500排行榜中已有十年历史的超级计算机的性能相当的想法让我深深着迷。 对国民议会进行培训需要多长时间? 当然,这取决于网络的体系结构(层数,层中神经元的数量,连接),用于训练的示例数和超参数。 但是令我吃惊的是,我花了几个小时在site.tensorflow.org网站上,以便一个小型网络可以正确地对二维空间中螺旋形的点进行分类。 只有二维,不是那么多数据,而是那么多时间。 ImageNet竞赛的获胜者花了一周时间使用两个视频卡学习网络,他对超参数了解很多。 几乎不买十几台服务器。 你有耐心学习NA吗?
摘要 :在我看来,在国民议会的帮助下,您可以在家里解决
一些问题。
- 训练样本的大小可以等于数十万个示例。
- 您可以达到约80-90%的精度。
- NS培训可能需要几天的时间。
这是我的直觉和粗略的估计,可能是错误的,如果有人在评论中写出他在家中完成的任务,数据量和熨斗的特性,我将感到高兴。
感谢您的关注!