
如今,图形是描述机器学习系统中创建的模型的最可接受的方法之一。 这些计算图由神经元顶点组成,这些神经元顶点由描述顶点之间连接的突触边连接。
与标量中央或矢量图形处理器不同,IPU是一种专为机器学习而设计的新型处理器,可让您构建此类图形。 设计用于图形管理的计算机是用于将计算机学习过程中创建的计算图形模型理想的计算机。
描述机器智能如何工作的最简单方法之一就是可视化它。 Graphcore的开发团队创建了这些图像的集合,这些图像显示在IPU上。 基础是Poplar软件,该软件可视化人工智能的工作。 该公司的研究人员还发现了为什么深层网络需要这么多的内存,以及存在哪些解决方案。
Poplar包括一个从头开始创建的图形编译器,用于将机器学习的一部分标准操作转换为IPU的高度优化的应用程序代码。 它使您可以按照组装POPNN的相同原理一起收集这些图。 该库包含一组用于通用图元的不同类型的顶点。
图形是所有软件所基于的范例。 在Poplar中,图形允许您定义计算过程,其中顶点执行操作,边描述它们之间的关系。 例如,如果要将两个数字相加,则可以定义一个顶点,其中包含两个输入(要添加的数字),一些计算(将两个数字相加的函数)和输出(结果)。
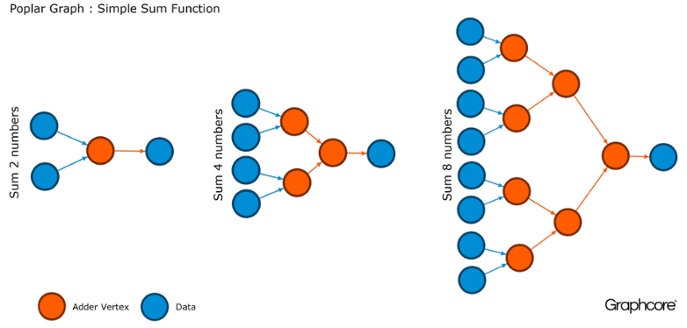
通常,顶点操作比上述示例复杂得多。 通常,它们由称为小代码(代码名)的小型程序定义。 图形抽象很吸引人,因为它不对计算结构进行任何假设,并且将计算分解为IPU处理器可以用来工作的组件。
Poplar使用这种简单的抽象来构建非常大的图形,这些图形表示为图像。 以编程方式生成图意味着我们可以将其适应必要的特定计算,以确保最有效地使用IPU资源。
编译器将机器学习系统中使用的标准操作转换为IPU的高度优化的应用程序代码。 图编译器创建部署在一个或多个IPU设备上的计算图的中间映像。 编译器可以显示此计算图,因此在神经网络结构级别编写的应用程序将显示在IPU上运行的计算图的图像。
 AlexNet全周期学习图前进和后退
AlexNet全周期学习图前进和后退图形编译器Poplar将
AlexNet的描述转换为1870万个顶点和1.158亿条边的计算图。 清晰可见的群集是网络各层中各流程之间紧密连接的结果,而各层之间的连接更容易。
另一个示例是具有完整连接性的简单网络,该网络在
MNIST进行了培训-一种简单的计算机视觉数据集,是机器学习中的“世界,你好”。 一个探索此数据集的简单网络有助于理解由Poplar应用程序控制的图形。 通过将图库与TensorFlow等环境集成,该公司提供了在机器学习应用程序中使用IPU的最简单方法之一。
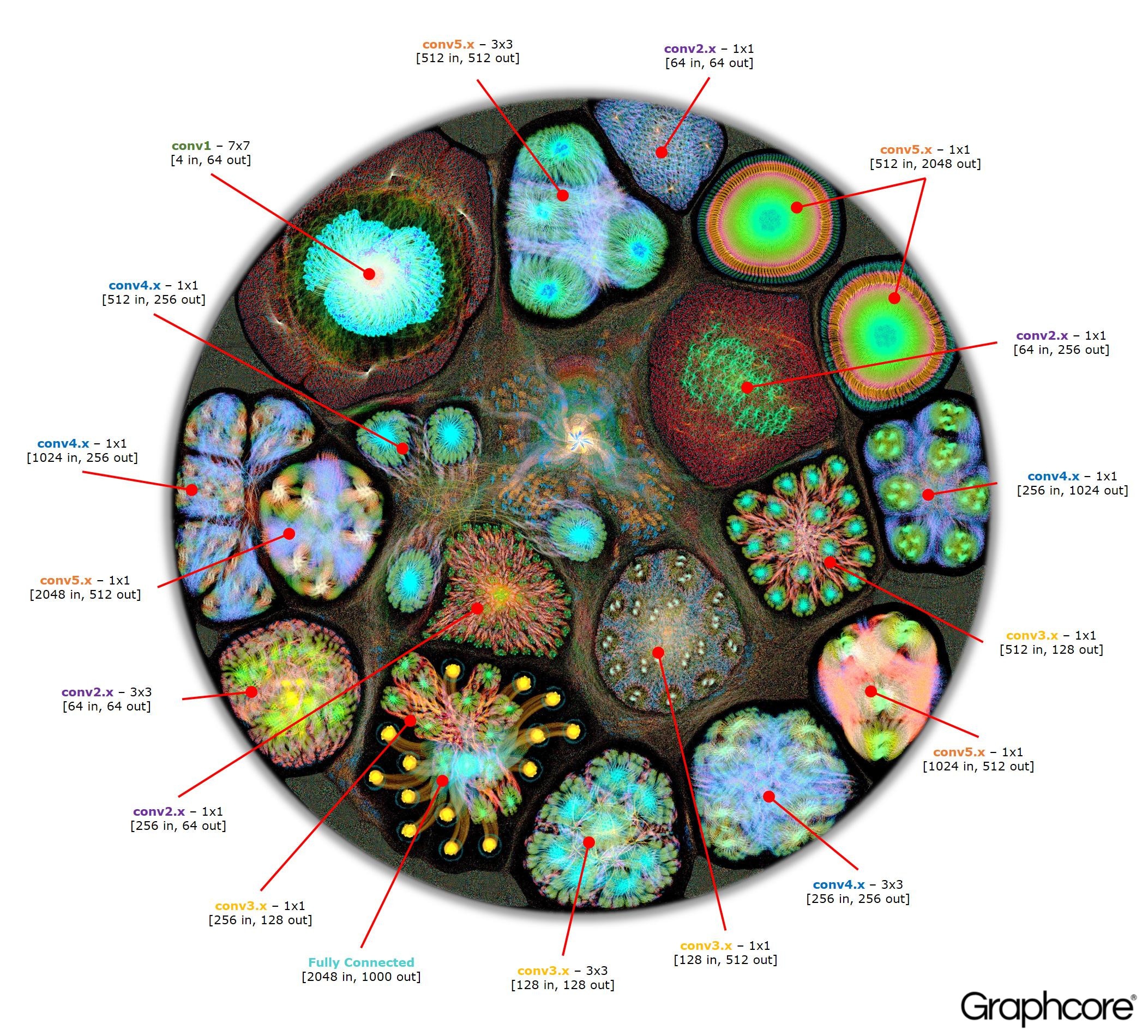
使用编译器构建图形后,需要执行它。 使用图形引擎可以做到这一点。 以ResNet-50为例,演示其操作。
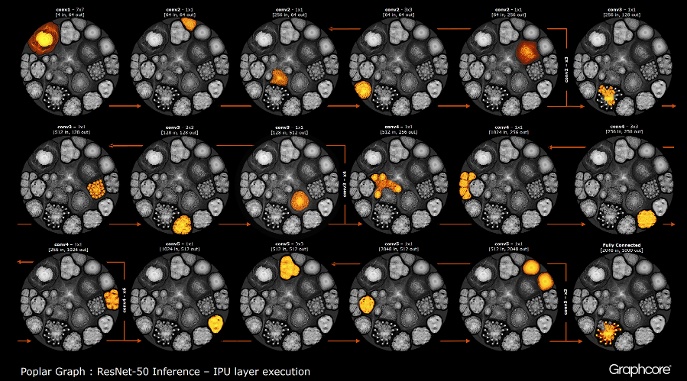 计数ResNet-50
计数ResNet-50ResNet-50体系结构使您可以从重复的分区创建深度网络。 处理器只需要确定一次这些分区并重新调用它们。 例如,一个conv4级别的集群执行了六次,但仅应用于图形一次。 该图像还演示了卷积层的各种形状,因为它们每个都具有根据计算的自然形式构造的图形。
引擎使用由编译器创建的图来创建并控制机器学习模型的执行。 部署后,Graph Engine将监视并响应应用程序使用的IPU或设备。
ResNet-50图像显示了整个模型。 在此级别上,很难区分各个顶点,因此值得查看放大的图像。 以下是神经网络各层中的部分示例。


为何深层网络需要那么多内存?
大量占用的内存是深度神经网络的最大问题之一。 研究人员正在尝试解决DRAM设备的有限带宽问题,现代系统应使用它来在深度神经网络中存储大量权重和激活信息。
该架构是使用处理器芯片开发的,该处理器芯片设计用于顺序处理和优化用于高密度存储器的DRAM。 这两个设备之间的接口是一个瓶颈,它引入了带宽限制并增加了能耗的开销。
尽管我们还没有人脑及其工作原理的完整图片,但是通常很明显,没有大型的独立存储设备可以存储内存。 据信,人脑中长期和短期记忆的功能嵌入在神经元+突触的结构中。 即使是简单的生物,如具有300多个神经元的大脑神经结构的
蠕虫 ,
也具有一定程度的记忆功能。
在常规处理器中建立内存是通过以低得多的功耗打开巨大的带宽来解决内存瓶颈的一种方法。 但是,芯片上的内存是昂贵的东西,它并不是为真正大量的内存而设计的,而这些内存已连接到当前用于准备和部署深度神经网络的中央处理器和图形处理器。
因此,有必要了解一下当今在图形加速器上的中央处理单元和深度学习系统中如何使用内存,并问自己:如果没有它们,人脑可以正常工作,为什么它们需要这么大的存储设备?
当输入是通过网络分配时,神经网络需要内存来存储输入数据,重量参数和激活功能。 在训练中,必须保留输入上的激活,直到可以将其用于计算输出上的梯度误差为止。
例如,一个50层的ResNet网络具有约2600万个加权参数,并计算1600万个前向激活。 如果使用32位浮点数存储每个权重和激活值,则将需要约168 MB的空间。 使用较低的精度值来存储这些比例和激活,我们可以将存储需求减少一半甚至四倍。
GPU依赖于表示为密集向量的数据这一事实引起了严重的内存问题。 因此,他们可以使用单个指令流(SIMD)来实现高密度计算。 中央处理器使用类似的矢量块进行高性能计算。
在GPU中,突触的宽度为1024位,因此它们使用32位浮点数据,因此通常将它们分成32个样本的并行微型批处理,以创建1024位数据向量。 这种组织矢量并行性的方法将激活次数增加了32倍,并且需要容量超过2 GB的本地存储。
专为矩阵代数设计的GPU和其他机器也会因权重或神经网络激活而承受内存负荷。 GPU无法有效执行深度神经网络中使用的小型卷积。 因此,使用一种称为“降级”的转换将这些卷积转换为矩阵矩阵乘法(GEMM),图形加速器可以有效地对其进行处理。
还需要额外的存储器来存储输入数据,时间值和程序指令。 在高性能GPU上训练ResNet-50时,测量内存使用情况表明,它需要超过7.5 GB的本地DRAM。
也许有人会认为较低的精度可以减少所需的内存量,但事实并非如此。 将权重和激活的数据值切换为半精度时,仅填充SIMD的向量宽度的一半,而消耗一半的可用计算资源。 为了弥补这一点,当您在GPU上从全精度转换为半精度时,您将必须使迷你批处理的大小增加一倍,以使足够的数据并行性来使用所有可用的计算。 因此,向精度较低的标度过渡和在GPU上激活仍然需要超过7.5GB的动态内存并可以自由访问。
由于要存储如此多的数据,因此根本不可能将所有这些数据都适合GPU。 在卷积神经网络的每一层上,有必要保存外部DRAM的状态,加载下一个网络层,然后将数据加载到系统中。 结果,已经受存储器带宽限制的外部存储器接口承受着不断地重新加载天平以及保存和获取激活功能的额外负担。 这会大大减慢训练时间并显着增加能量消耗。
有几种解决方案。 首先,诸如激活功能之类的操作可以在现场进行,从而使您可以将输入直接覆盖为输出。 因此,现有的内存可以重复使用。 其次,可以通过分析网络上操作之间的数据依赖性以及当前不使用该操作的同一存储器的分布来获得内存重用的机会。
当可以在编译阶段分析整个神经网络以创建固定分配的内存时,第二种方法特别有效,因为内存管理的成本几乎降低为零。 事实证明,这些方法的组合将神经网络的内存使用量减少了两到三倍。
百度深度语音团队最近发现了第三种重要方法。 他们应用了各种节省内存的方法,通过激活功能将内存消耗降低了16倍,从而使他们可以训练100层网络。 以前,使用相同的内存量,他们可以训练具有9层的网络。
将内存和处理资源组合在一个设备中,对于提高卷积神经网络以及其他形式的机器学习的生产力和效率具有巨大的潜力。 您可以在内存和计算资源之间做出折衷,以平衡系统的功能和性能。
其他机器学习方法中的神经网络和知识模型可以视为数学图。 在这些图中,大量的并行度被集中。 设计为在图形中使用并发的并行处理器不依赖小型批处理,并且可以显着减少所需的本地存储量。
现代研究结果表明,所有这些方法都可以显着提高神经网络的性能。 现代图形和中央处理器的内部存储器非常有限,总共只有几兆字节。 专为机器学习而设计的新处理器体系结构在内存和片上计算之间取得了平衡,与现代中央处理器和图形加速器相比,性能和效率有了显着提高。