试想一下,全球所有智能手机的总计算能力是多少? 这是一个巨大的计算资源,甚至可以模仿人脑的工作。 这样的资源不能闲着闲着,在聊天室和社交媒体源上愚蠢地燃烧千瓦的能量。 如果将这些计算资源提供给单个分布式世界AI,甚至向其提供来自用户智能手机的数据以进行培训,那么这样的系统可以在这一领域实现飞跃。
标准的机器学习方法要求将用于训练模型的数据集(“主要”)收集在一个地方-一台计算机,服务器或一个数据中心或云中。 从这里开始,他接受了根据此数据训练的模型。 对于数据中心中的计算机集群,
将使用随机梯度下降(SGD)
方法 -一种优化算法,该算法始终在均匀分布在云服务器中的部分数据集中运行。
谷歌,苹果,Facebook,微软和其他AI厂商已经这样做了很长时间:他们从用户的计算机和智能手机中收集数据(有时是机密数据)到一个(大概是)安全的存储中,以对其神经网络进行训练。
现在,来自Google Research的科学家提出了对该标准机器学习方法的有趣补充。 他们提出了一种称为联合学习的创新方法。 它允许所有参与机器学习的设备共享一个模型进行预测,但
不能共享主要数据进行模型训练 !
这种不寻常的方法也许会降低机器学习的效率(尽管事实并非如此),但它会大大降低Google维护数据中心的成本。 如果一家公司在全球拥有数十亿个可以分担负载的Android设备,为什么要在设备上投入大量资金呢? 用户可以为这样的负担感到满意,因为他们因此可以帮助他们自己使用更好的服务。 而且,他们无需将其发送到数据中心即可保护其机密数据。
Google强调,在这种情况下,不仅仅是经过训练的模型直接在用户设备上执行,而是在
Mobile Vision API和
设备上智能回复服务中发生的事实。 不,这是在终端设备上进行的模型
训练 。
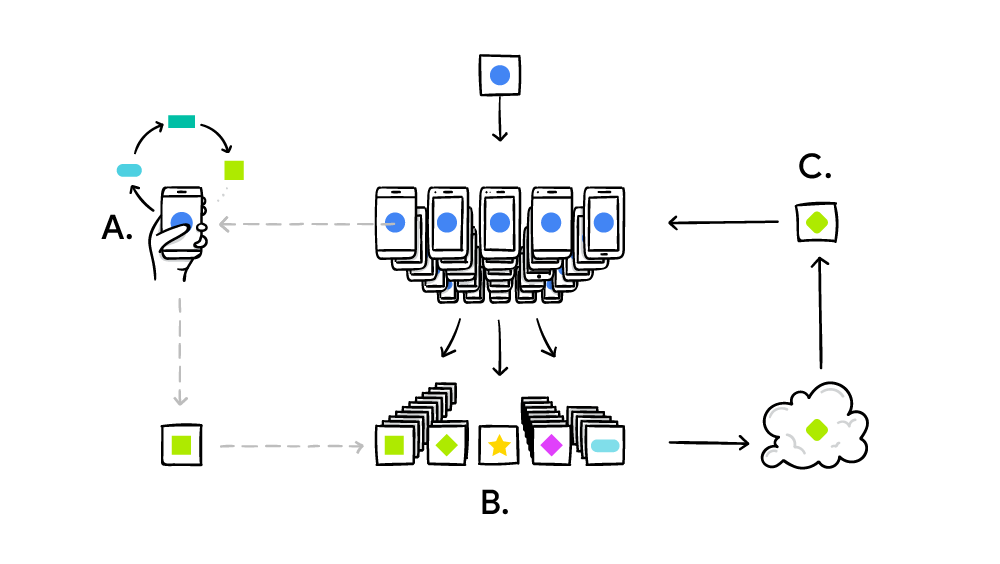
当数百万台计算机解决一个大的复杂问题时,联合学习系统将根据分布式计算的标准原理(例如SETI @ Home)工作。 在SETI @ Home的情况下,这是在整个频谱宽度上搜索来自空间的无线电信号中的异常情况。 在联邦机器学习的情况下,Google正在完善(迄今为止)弱AI的单一通用模型。 在实践中,培训周期的实施方式如下:
- 智能手机下载当前模型;
- 在迷你版本的帮助下, TensorFlow对特定用户的唯一数据进行了训练周期;
- 改进模型;
- 计算改进的源模型之间的差异,使用安全聚合加密协议编译补丁,该协议仅在有来自其他用户的成百上千个补丁时才允许解密数据;
- 发送补丁到中央服务器;
- 立即使用联合平均算法,将实验中其他参与者收到的数千个补丁平均为采用的补丁;
- 推出了该模型的新版本;
- 改进的模型将发送给实验参与者。
联合平均与上述随机梯度方法非常相似,仅在此处初始计算不是在云中的服务器上进行,而是在数百万个远程智能手机上进行。 联合平均的主要成果是使用随机梯度方法的客户端流量比服务器流量少10-100倍。 通过
高质量压缩从智能手机发送到服务器
的更新 ,实现了优化。 好吧,这里的好处是安全聚合加密协议。
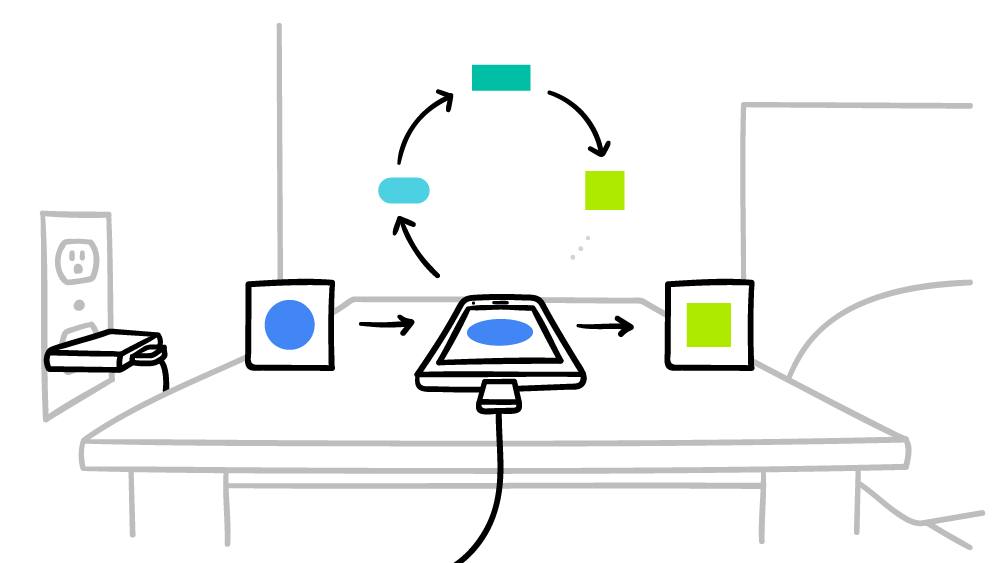
谷歌承诺,智能手机将仅在停机时间为分布式全球AI系统执行计算,因此不会以任何方式影响性能。 此外,您只能将智能手机连接到电源的时间设置操作时间。 因此,这些计算甚至不会影响电池寿命。 联合机器学习目前正在
Android上的Google键盘
-Gboard的上下文提示上进行测试。
联合平均算法在2016年2月17日在arXiv.org(arXiv:1602.05629)上发表的科学论文《
从分散数据进行深度网络的通信高效学习》中进行了详细描述。