 如何在Word中翻译文档而不进行格式化 ? 如何不翻译同一件事? 如何保持一致性? 如何不购买昂贵的软件? 如何高效快捷地工作?
如何在Word中翻译文档而不进行格式化 ? 如何不翻译同一件事? 如何保持一致性? 如何不购买昂贵的软件? 如何高效快捷地工作?如果您熟悉Trados,MemoQ或CrowdIn,请直接转到安装说明。 如果这些是您的新词汇,欢迎来到
计算机辅助翻译的美好世界
。关于计算机翻译
Google翻译 -机器翻译,计算机会为您翻译。 当计算机仅在工作中自动化日常流程时,CAT是工作原理。
CAT程序将源代码划分为
段 -行,句子,段落或段落。 一个人一页一页地翻译一段,然后将翻译存储在特殊的数据库中-翻译记忆库(
TM )。 如果翻译遇到
类似的片段 ,程序将显示提示或可能的翻译。 该程序
本身可以翻译相同的片段。
CAT特别擅长翻译
说明 ,
法律文件 ,
程序界面 ,在这些地方,
类似的用语非常普遍 。 在文学翻译中,帮助不会那么明显,但以后会更多。
您翻译的类似主题的文本越多
,数据库中积累的翻译越多,提示出现的频率就越高。 多年以来,这样的基础可能会积累下来,在新文档中,一半的翻译将“准备就绪”。
翻译完成后,程序将创建一个
与原始文档
相同的文档-保留结构和格式,但将源文本替换为您的翻译。
CAT程序不会修改原始文档,因此不可能永久损坏文档。 输出将是一个完全翻译的文件。
什么是CAT程序?
不一样
Trados ,
MemoQ-安装在计算机上的昂贵的公司系统。
CrowdIn ,
Tolmach等-直接在浏览器中工作。 通常,一切都会花费金钱,或者项目数量会受到限制。
但是,并非一切都那么糟糕:我已经使用
OmegaT 八年了 ,它是一个免费的开源程序,可以在Windows,Mac和Linux系统上运行,并且社区不断对其进行改进。 我用
中文 ,英文和俄文工作。
OmegaT可以做什么?
 欧米茄www.omegat.org
欧米茄www.omegat.org免费软件(GPLv3),开源
Windows,macOS,Linux
他知道第一章中描述的所有内容-帮助翻译人员工作,以及其他各种琐事。
档案格式- Microsoft Word,Excel,PowerPoint(仅新的.xlsx, .docx和* .pptx,旧的必须首先转换)
- OpenOffice .ods, .odt等
- 文本文件.txt, .rtf
- 键=值文本文件(* .ini等)
- 的HTML
- 具有XML结构的文件(您可以自己配置)
- 还有许多其他。
语言能力任何 Unicode几乎包含所有内容。 对于稀有语言,您可能需要调整分割规则,但一切都已解决。
我不会重复说明 。 它是完整且信息丰富的,熟悉它非常重要。 然后,该程序将只有基本的操作可以帮助您入门。
安装方式
从
omegat.org下载发行
版 。 我将使用Windows
最新分支的英文版
4.1.1 。 此内容需要Java才能运行。 如果不确定是否有一个,请下载标记为JRE的版本。 别为题词Beta感到震惊,该程序的工作稳定得多。
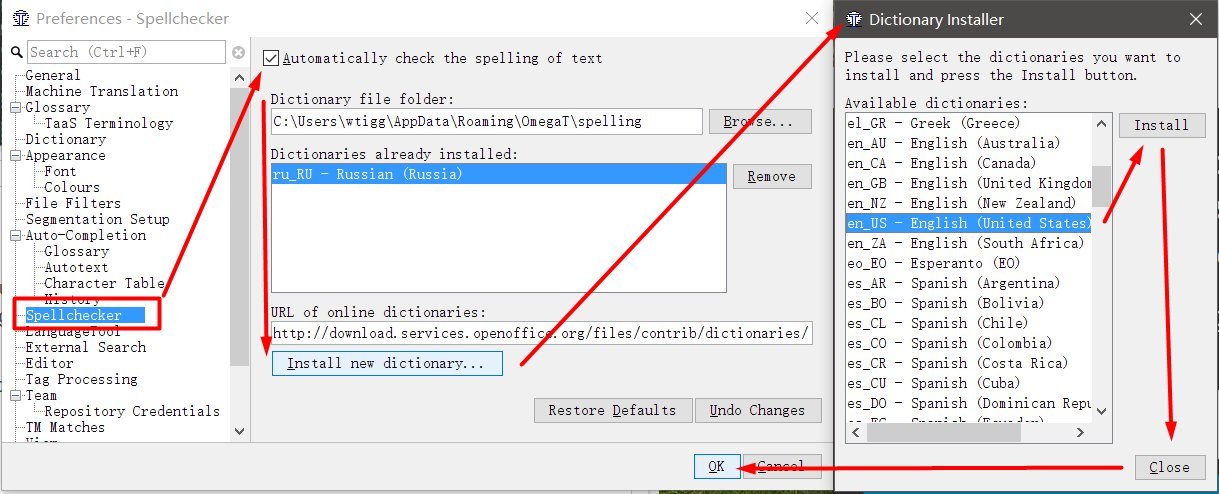
拼写检查
安装后,该程序即可工作,但是默认情况下没有足够的拼写检查。
- 启动OmegaT
- 转到选项→首选项→拼写检查器
- 选中框自动检查文本的拼写
- 点击安装新词典
- 选择一种语言(例如, ru_RU表示俄语),单击“ 安装”。
- 单击关闭 。 在列表中,我们看到了俄语。
- 我们退出设置。
如何建立专案
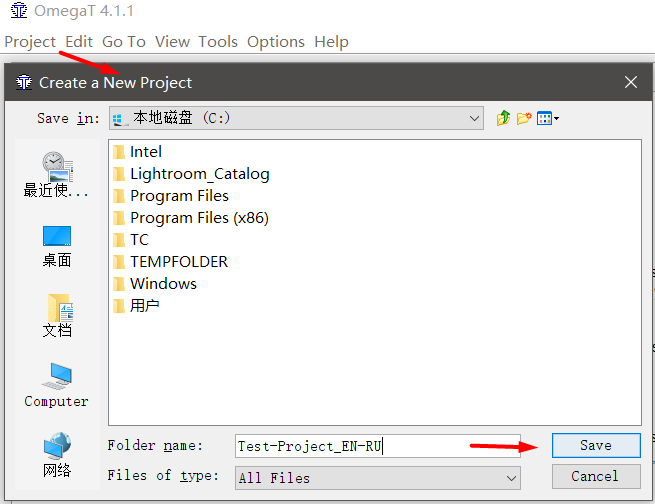
OmegaT不适用于单个文件,但适用于“项目”。 项目是一组具有特定结构的文件夹。 要翻译文件,您需要创建一个项目,然后在此处添加文件。
- 启动OmegaT
- 项目→新建 , 选择保存位置和项目名称。 我建议给项目取有意义的名称,并在项目中指定语言对。 例如, Test-Project_EN-RU 。
- 在出现的窗口中, 指定语言对
源文件语言 -您要翻译的语言; 目标文件语言是您要翻译的语言。 必须用两个或四个字母的代码表示。 例如, RU是俄文, RU-RU和RU-BY则说明是俄罗斯联邦的俄文,白俄罗斯的俄文。 为了使拼写检查有效,该代码必须与拼写设置中指定的代码匹配(如果在拼写中设置了RU-RU , 而在项目中设置了RU ,则该检查将不起作用)。
- 选中启用句子级分段 (按句段,而不是段落划分段)和翻译的自动传播 (自动翻译) 旁边的框 。 最好取消选中“ 删除标签”复选框,稍后再解释。
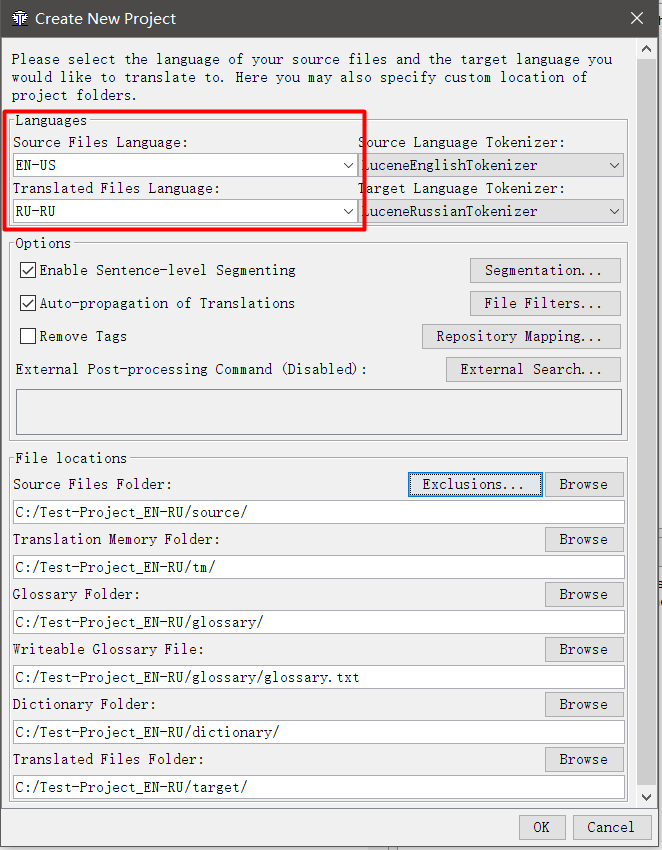
- 单击确定 。
这些文件夹是什么?
项目文件夹中有几个子目录:
- 字典 -您可以以StarDict格式添加字典; 该功能非常没用。
- 词汇表 -该项目的术语数据库,稍后会有更多介绍;
- omegat-翻译记忆库和项目备份;
- source-包含源文件的文件夹;
- target-将在其中显示翻译的文件夹;
- tm-附加翻译记忆库,稍后会有更多介绍。
以及带有当前项目配置的
omegat.project文件。
如何添加文件
创建项目后,您将看到以下窗口:
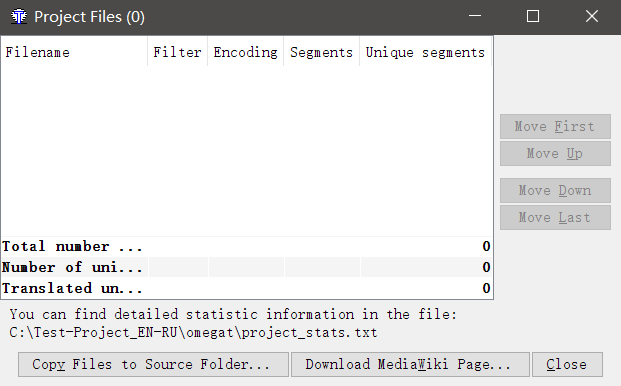
单击“
将文件复制到源文件夹”,然后选择要转换的文件。 文件将被复制到新创建的项目的
\ source \文件夹中。 您可以在此处手动添加文件。 只需通过资源管理器将文件复制到
\ source \ 。
例如,我创建了两个文件-Excel和Word,将在它们上显示OmegaT的工作。
介面
OmegaT正在运行,已添加文件。 让我们看看它们在程序中的外观。
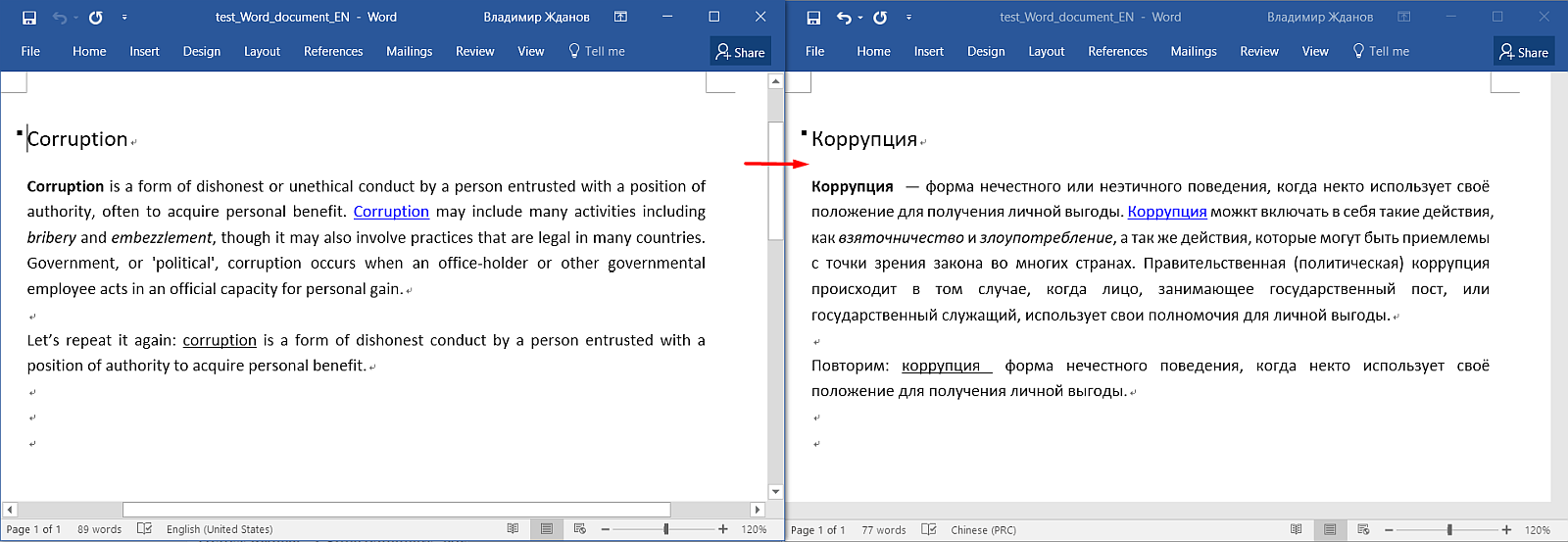
这是Word中的源文档。 在这里,您可以看到标题,段落,格式(粗体,链接,下划线)。

这是OmegaT中的样子:
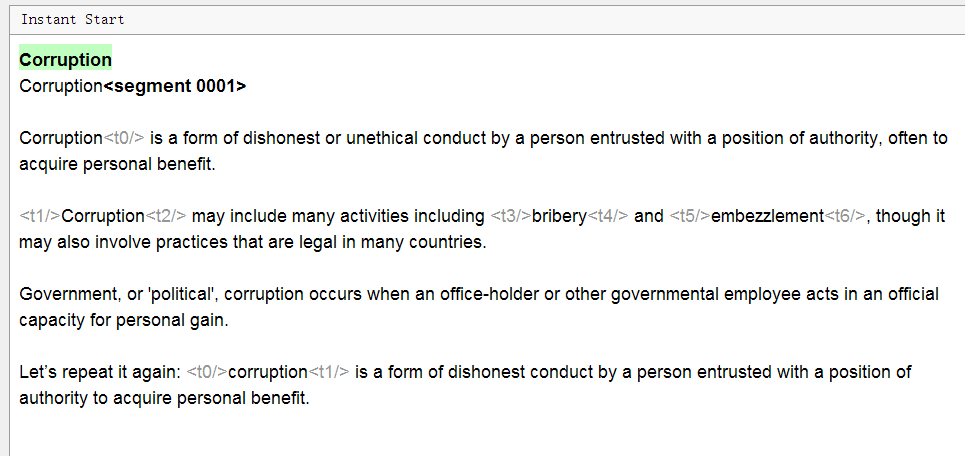
请注意:所有文本均分为句子,格式不可见,出现了一些灰色
标签 ,并且标题重复。 怎么了
- 文字分割
每个报价都分配到一个单独的细分中。 如有必要,可以独立配置细分规则。 - OmegaT中的格式不可见,标签将其替换
它们是Word中标签的缩写,否则可能看起来像<t>。 要保留原始格式,您需要保留这些标签的原样,并以与原始逻辑相同的逻辑输入标签之间的转换。
项目设置中的“ 删除标签”选项将删除标签以及格式。 如果保留原始格式很重要,则不建议使用。 - 标题没有重复。
实际上,源语言中的文本始终显示在顶部(绿色),您无法对其进行更改。 在它下面是一个文本框,默认情况下将复制相同的文本。 您需要删除它并输入翻译。
此外,在程序的右侧,还有两个扇区:
模糊匹配和
词汇表 (项目字典)。
模糊匹配 (模糊匹配)-在项目数据库中搜索结果。 根据您以前翻译的翻译提示将显示在此处。
词汇表 (项目词典)-您自己创建的词汇表搜索的结果。 与翻译记忆库不同,这不是现成的文本,而只是某些术语的提示。 这是一个功能强大的工具,有助于维护术语的一致性。
如何翻译
- 双击句段进行翻译
可编辑的文本行将出现在原始文本下方,光标将在其开始处,并且原始文本将在该行中重复。 - 输入您的翻译
- 按Enter
按下后,翻译将被保存,光标将移至下一段。
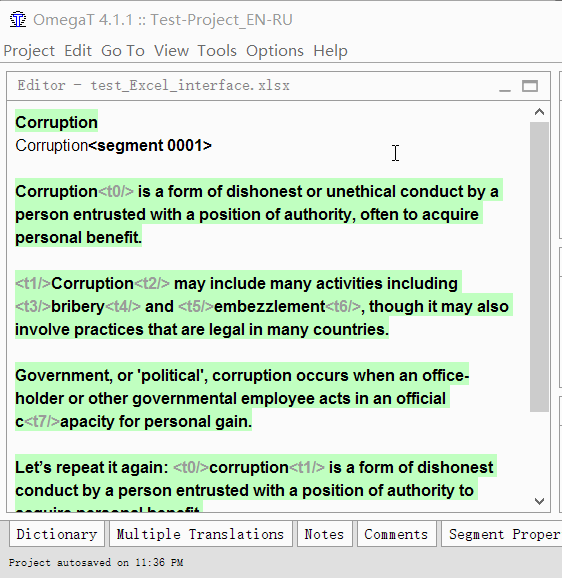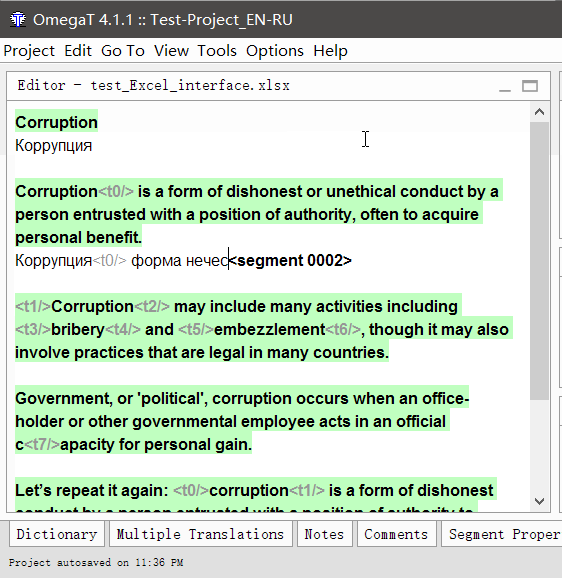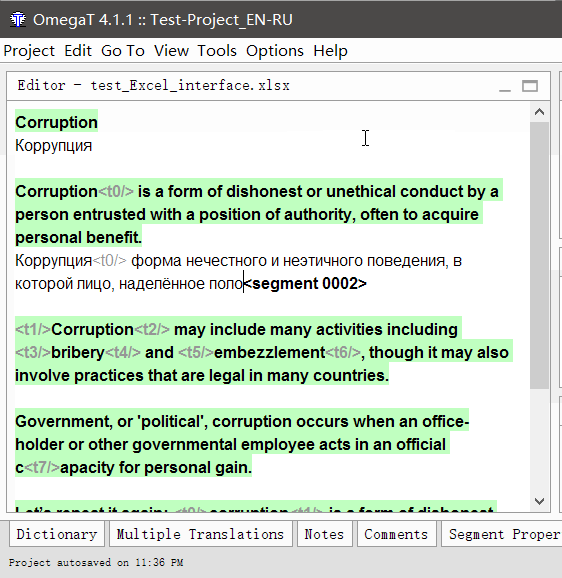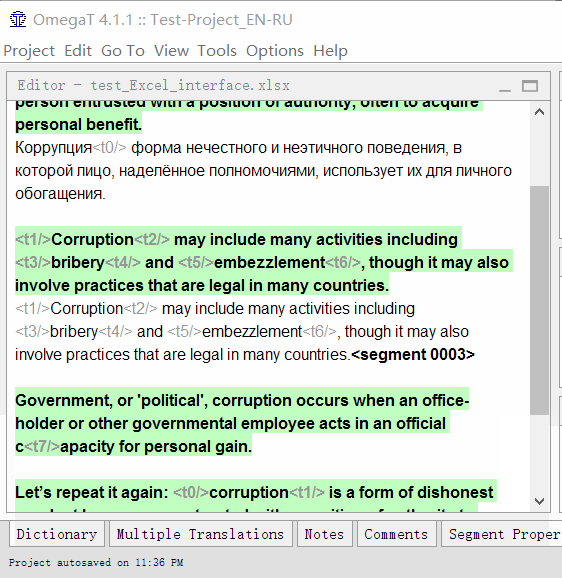
重复直到完成文档。 您随时可以通过双击它来返回上一个段。
右下角有一个
方便的进度指示器 。 单击它以切换查看模式。

当前文件:已翻译的细分受众群(剩余的细分受众群)/项目:已翻译的细分受众群(剩余的细分受众群),细分总数
该行表明当前文件中5.8%的唯一句段已被翻译,尚待翻译1382件,该项目中总共63%的句段已被翻译,剩余1756件,在项目中的总数为5979。

文件:已翻译的唯一句段/唯一句段总数(项目:已翻译的唯一句段/总唯一句段,项目中的全部句段)[/标题]
在
第二种模式下,插图显示在1592个唯一片段的文件中,翻译了146个片段,在4748个唯一片段的项目中,翻译了2992个片段,总共翻译了5979个片段(包括重复片段)。
最后的数字14/14不代表项目计数器。 这是您正在处理的段的长度的指示器。 他说原文中有14个字符,翻译中有14个字符,此功能在需要严格观察字符串长度的情况下很有用,例如在翻译程序界面时。
模糊匹配模糊匹配
为此,它们是任何CAT应用程序中最重要的工具。
我将举例说明:
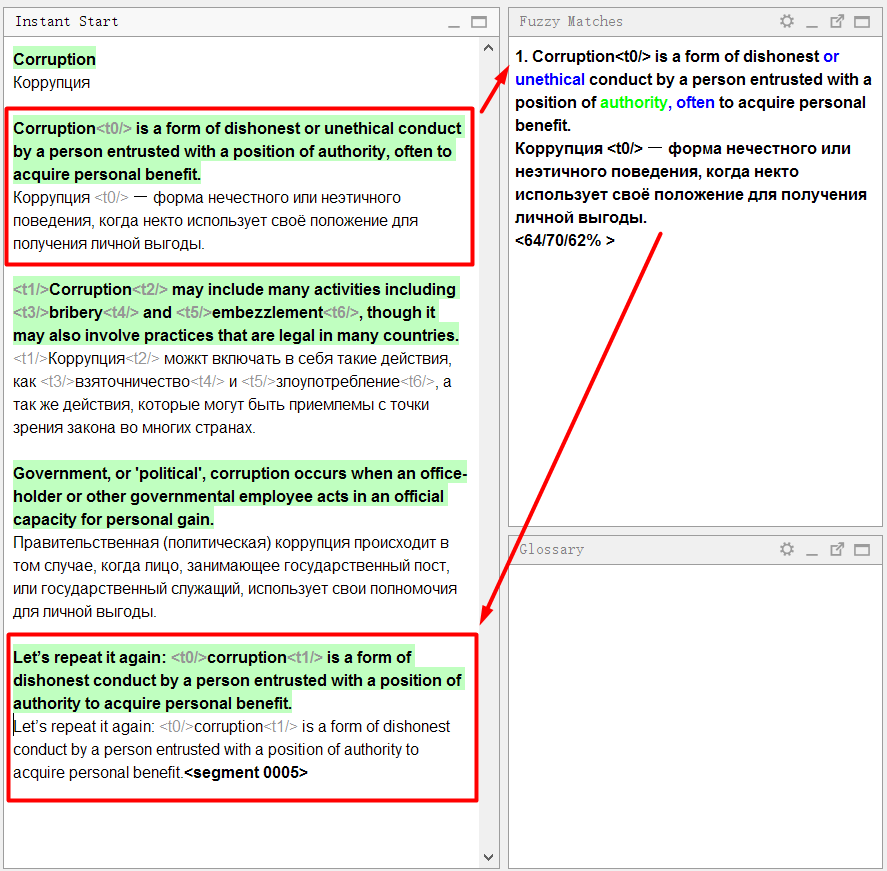
在样本文档中,
第一句话与
第四句话非常相似。 我按顺序走了,翻译了第一句话。 当我到达第四位时,该程序立即显示出一个
模糊的巧合 :
仔细查看“比赛”面板:
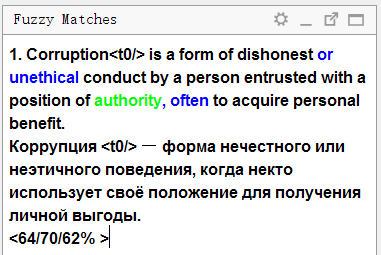
上部显示
源语言的文本,该文本已
保存在翻译记忆库中 。 翻译记忆库中存在但当前句子中不存在的单词(与之进行比较的单词)以蓝色突出显示,位于缺失部分旁边的单词以绿色突出显示。
下面是存储在内存中的翻译。 如果按
Ctrl + R ,它将被复制到要翻译的字段中。
下面显示了三个数字的百分比。 它们表示句子和翻译记忆之间的一致程度。 您可以
在OmegaT帮助中了解有关计算引擎的更多信息。
自动翻译相同的句段
当然,如果
模糊匹配引擎发现
100%匹配 ,它可以
自己插入 。 例如,这次在Excel中获取另一个文件。 大约以这种形式,通常会下达命令来翻译站点或程序的界面。
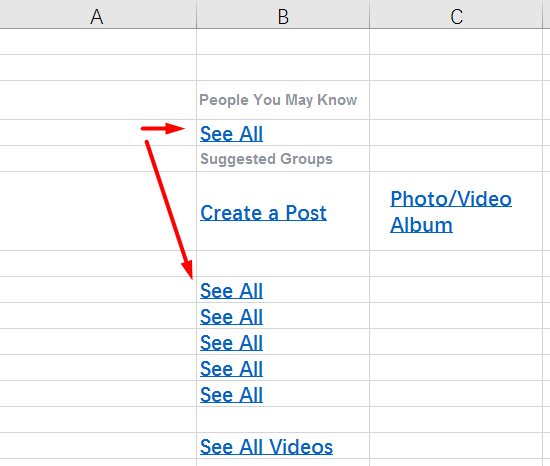
这是OmegaT中文件的外观:
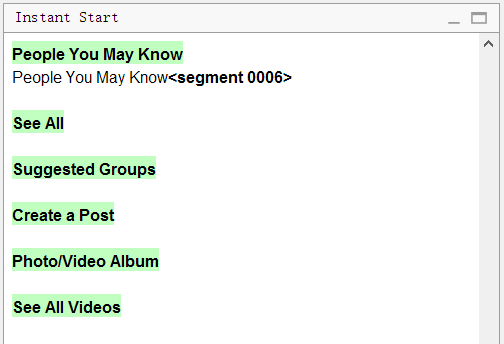
请注意,原始文档中有
六行“
查看全部” 。 该程序将删除所有重复项,仅保留一行。 单独翻译就足够了,其余的片段也将被翻译。
词汇表
该词汇表的工作非常简单。 首先
,向其中添加单词 (原始和翻译)。 现在,当单词出现在文本中时,提示将立即出现在“
词汇表”窗口中。
因此,当一个术语出现在新句子中时,您将立即知道如何翻译它。 例如,如果在翻译程序界面时总是需要写“ Good”而不是“ OK”,则只需在字典中添加单词“ OK”和翻译“ Good”即可。 通过在项目中添加几百个单词,您将大大简化您的生活。
要将
单词添加到词汇表中 ,请选择它,右键单击并选择
添加词汇表条目 。
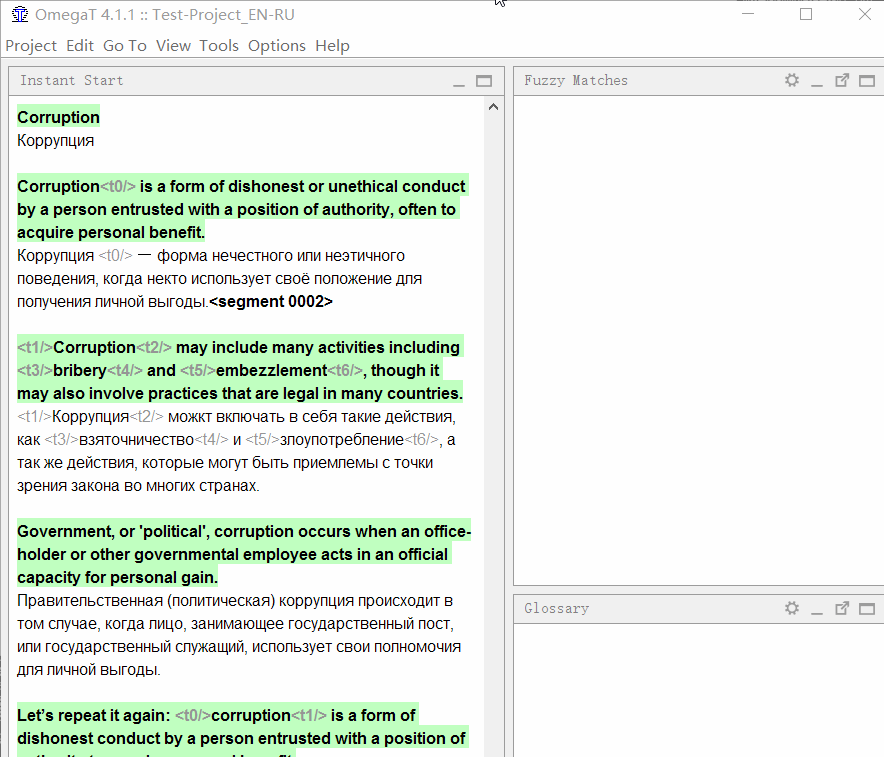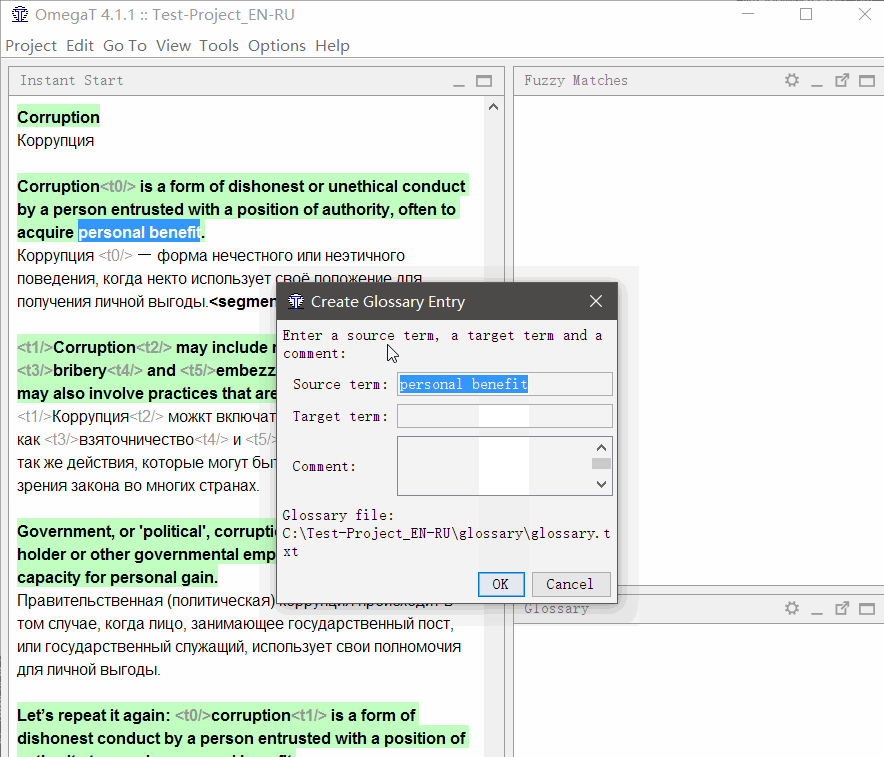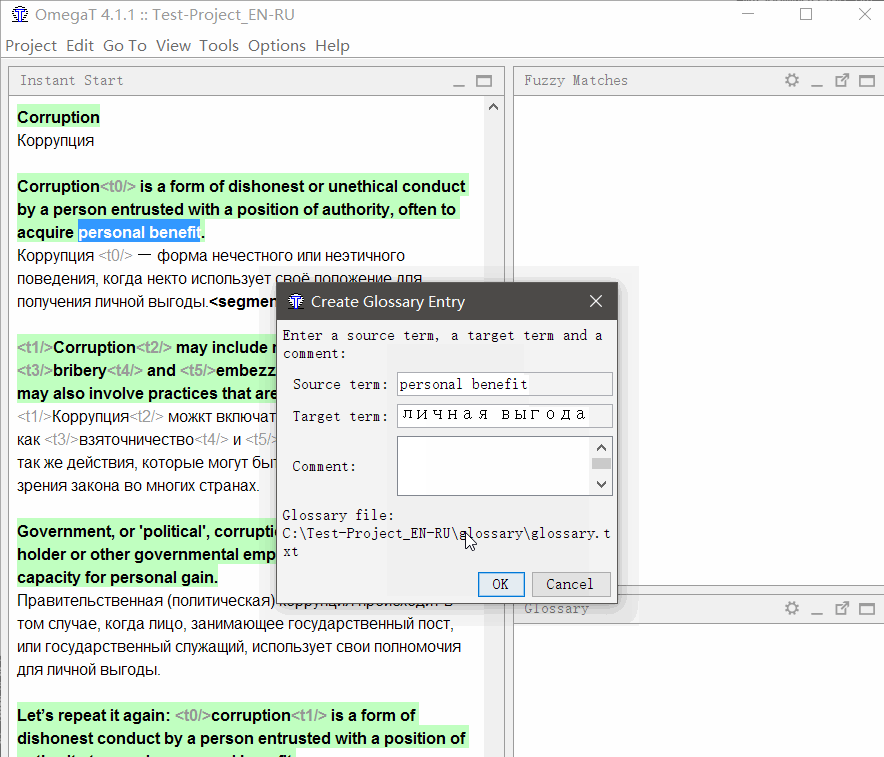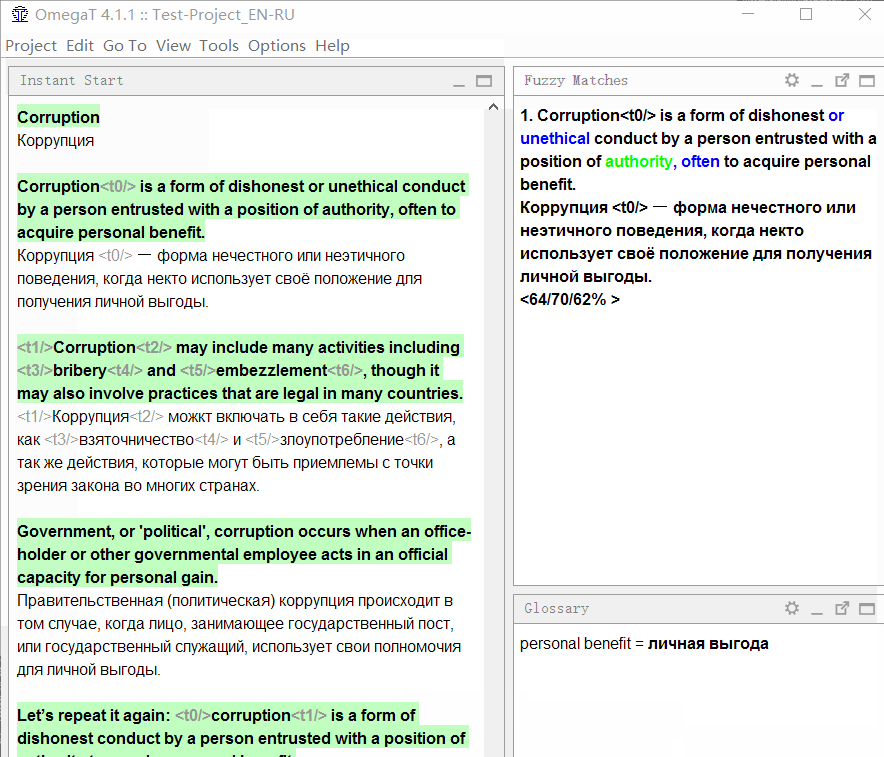
此外,可以将单词大量地以“原始翻译标签”的格式添加到
\ lossary \ lossary.txt文件中(以制表符分隔的* .csv格式保存的Excel表可以)
如何保存
项目→保存的意思是“保存项目”,即 将所有传输写入数据库文件。 要
获得完成的文件 ,您需要选择
项目→创建翻译的文档 。
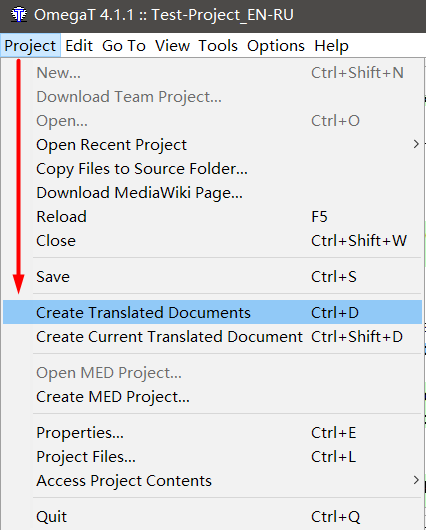
使用此命令,OmegaT将在
\ target \文件夹中创建一个与原始文件同名的新文件,并将
所有文本更改为translation 。 如果您没有翻译任何句段,那么在文件中的位置将是原始文本。
如何添加机器翻译
在某些情况下,机器翻译(例如
Google Translate )可以帮助更快地翻译。 可以对OmegaT进行配置,以便直接在其界面中显示段的机器翻译,您可以直接使用它或进行快速编辑。
在OmegaT中,您可以连接
Google Translate ,
Microsoft Translator和
Yandex.Translator等系统 。 您将需要为前两个支付,
Yandex.Translator免费提供其服务(在合理的使用范围内)。 现在,我将告诉您如何操作。
- 在Yandex中注册一个帐户。
例如,获取邮件。 - 在此链接 转到 “翻译器”部分中 的开发人员页面 。
- 单击创建新密钥 ,输入描述(自己输入),然后单击创建。
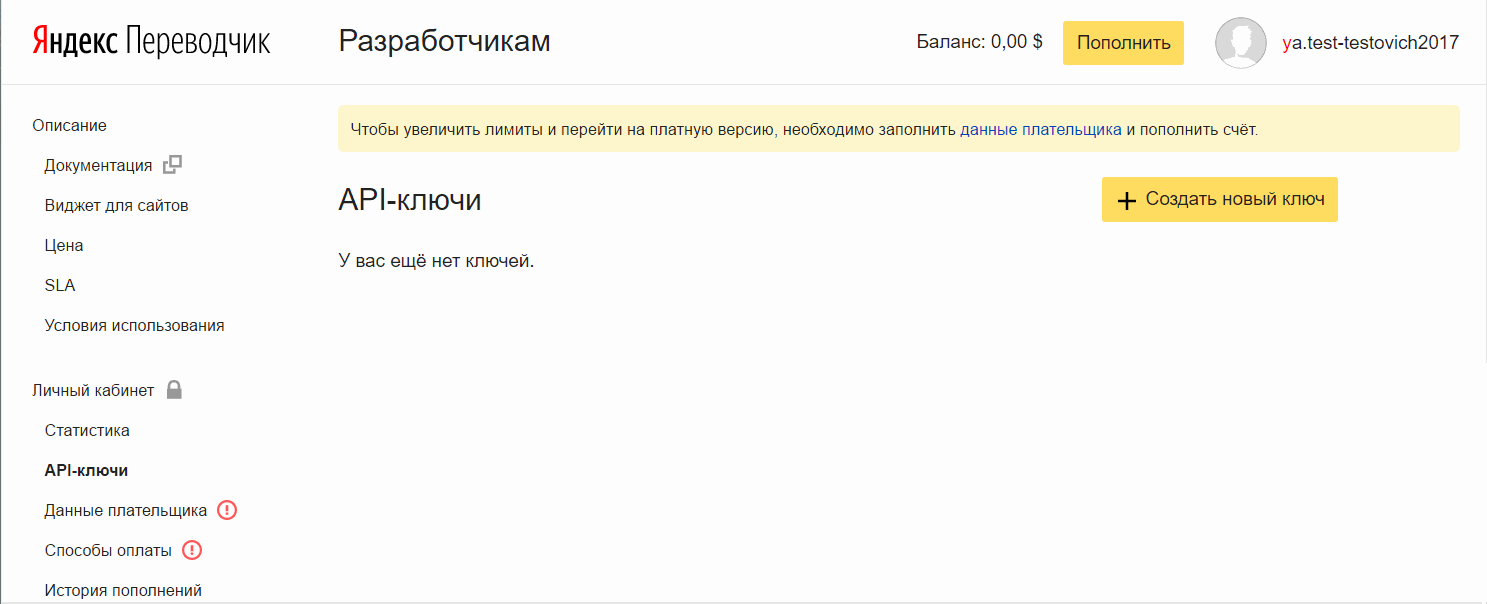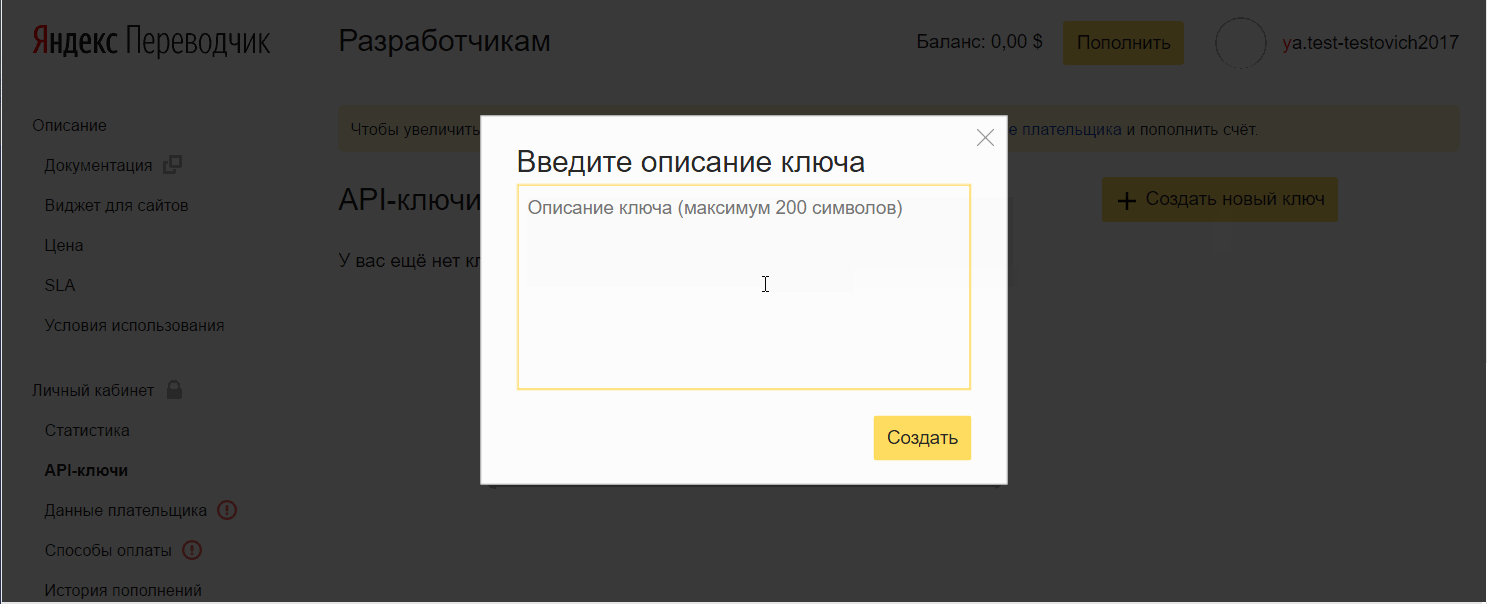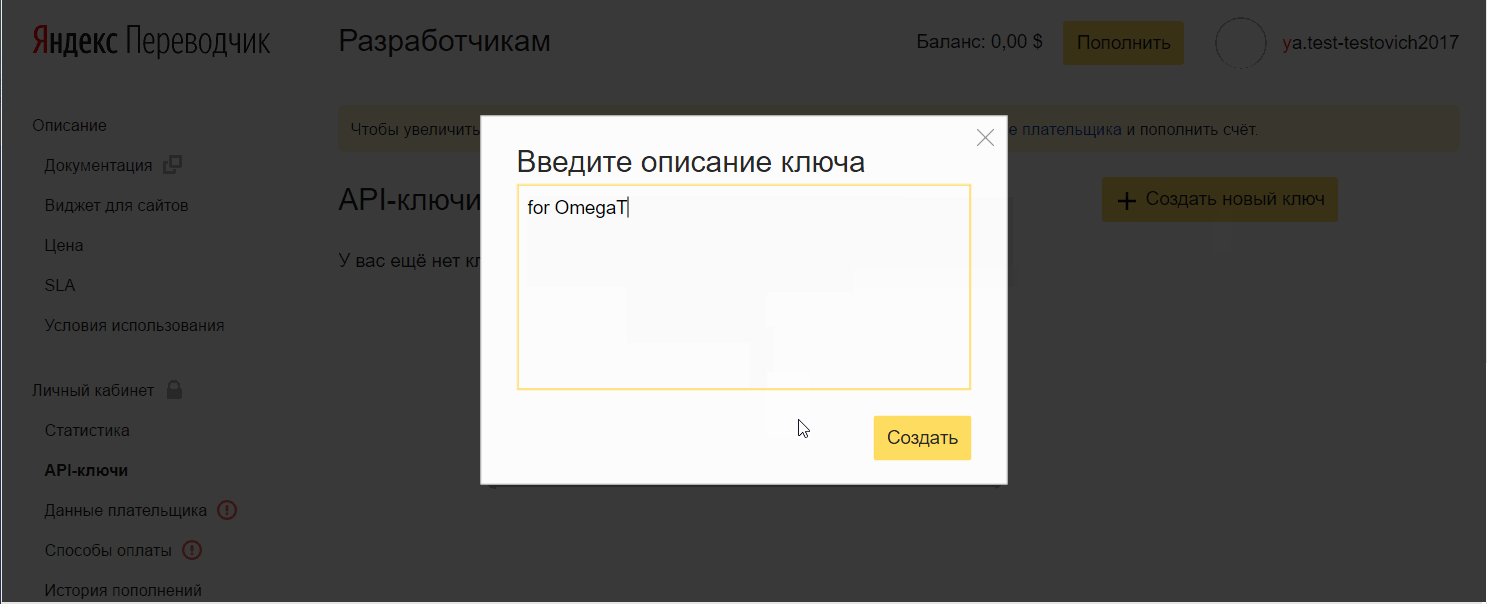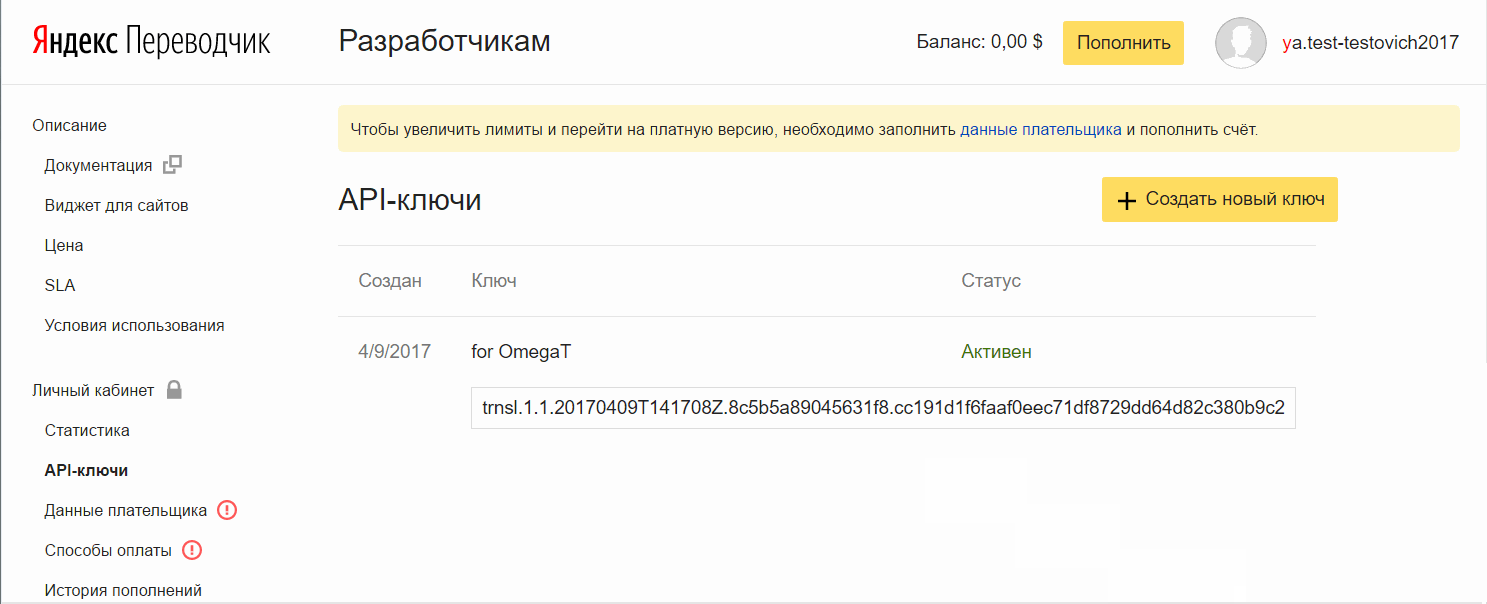 将密钥添加
将密钥添加到OmegaT:
- 在OmegaT中,转到选项→首选项→机器翻译
- 选择Yandex Translate ,选中它,然后单击Configure。
- 在出现的字段中复制API密钥 ,然后单击“ 确定”。
- 在出现的窗口中,您可以设置密码或跳过此操作。
需要密码来保护您的API密钥。 实际用于付费翻译系统。
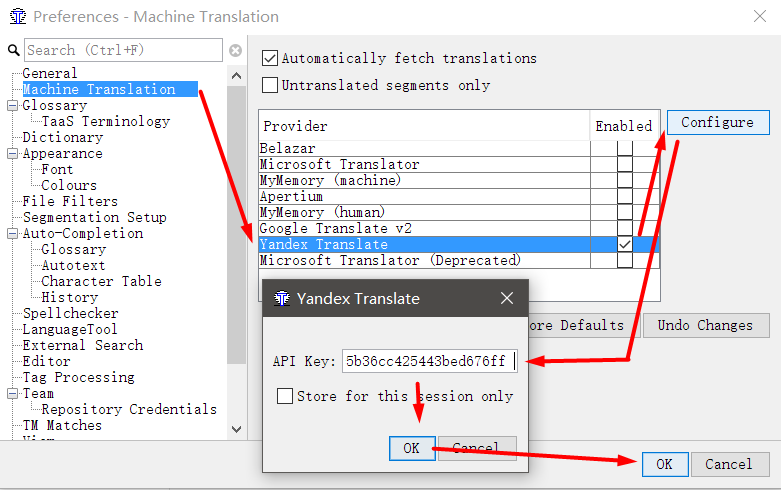
关闭设置。 现在,在程序的主窗口中,您可以
单击窗口底部的“
机器翻译”选项卡 。 为了使机器翻译窗口始终可见,请单击带有两个窗口的小图标。
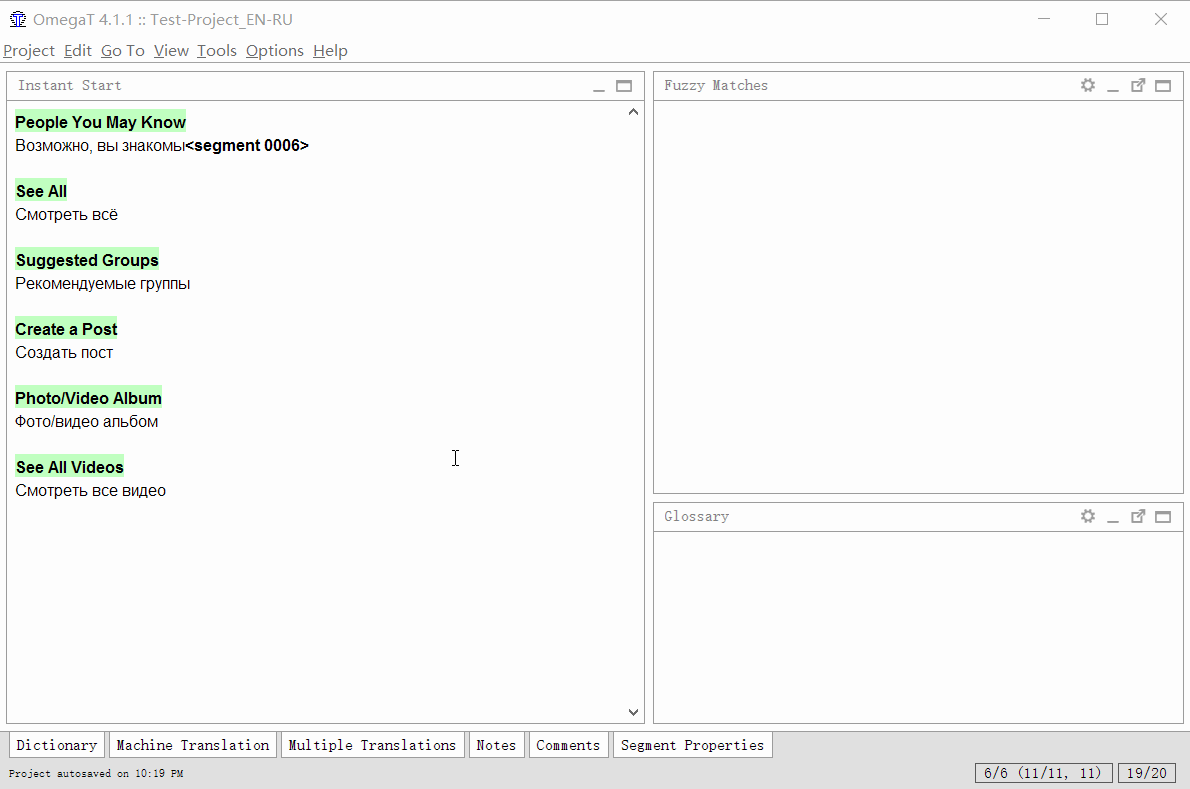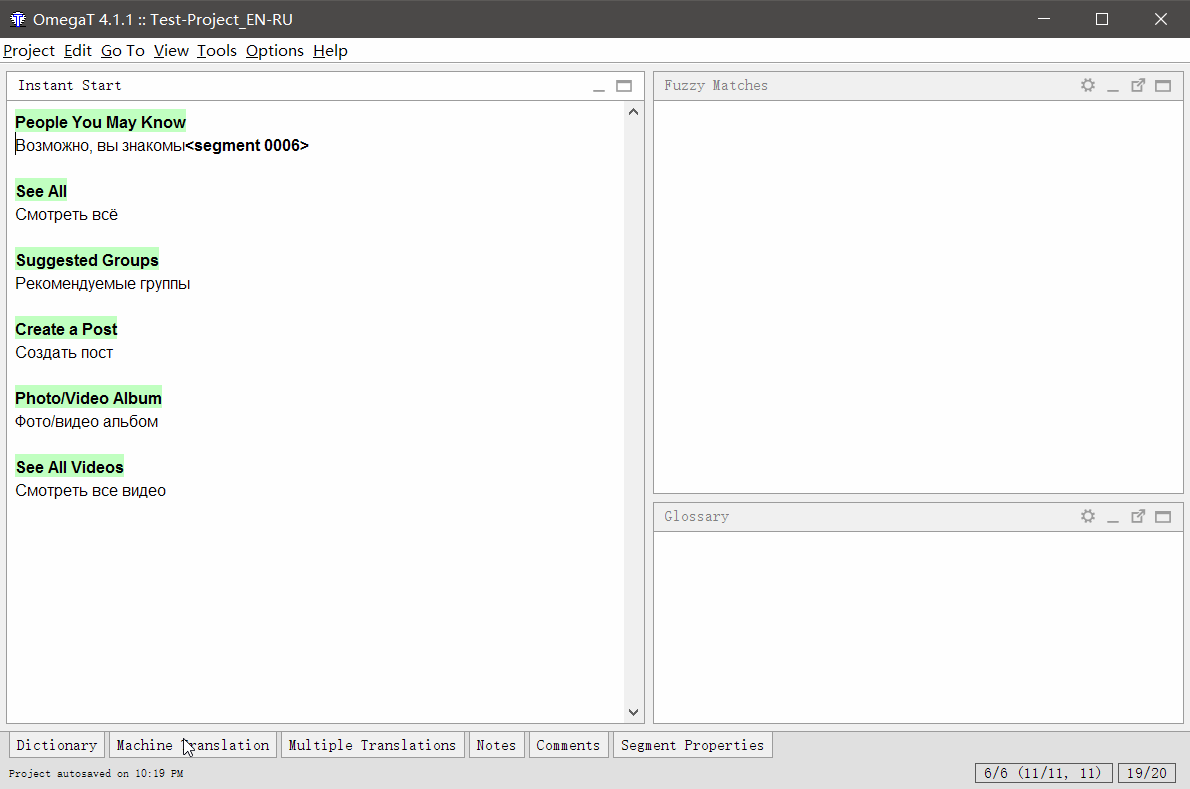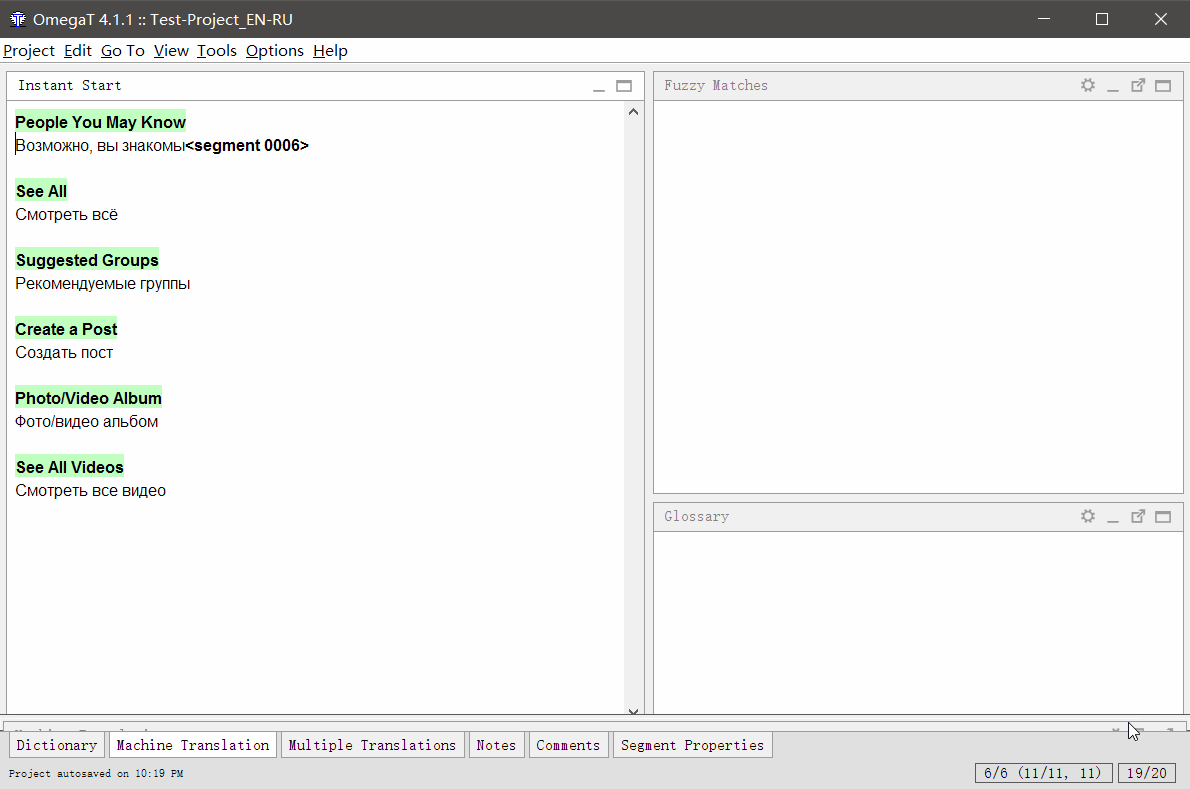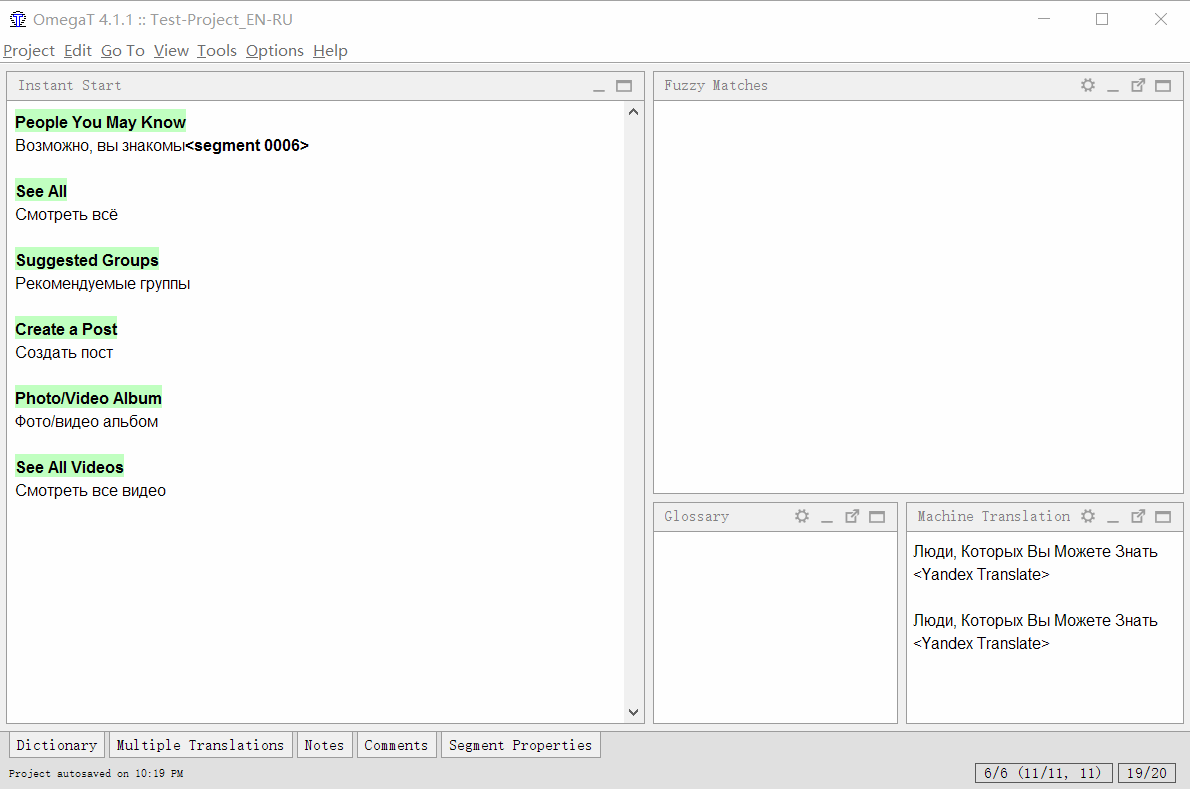
现在,当移至新段时,程序将向Yandex.Translator发出请求,接收响应并将其显示在窗口中。 热键Ctrl + M可以将结果粘贴到翻译字段中。
如何检查文本中的错误?
除了我们之前设置的简单拼写检查之外,您还可以检查从样式到丢失标签的更复杂的错误。 为此,OmegaT使用了开放的
语言工具 。 它与OmegaT一起提供,可以单独安装,也可以连接到远程服务器。
- 工具→检查问题 (或Ctrl + Shift + V )
- 双击列表中的错误以转到要编辑的段。
通过右键单击,您可以在词典中添加一个单词,或者禁用检查此类错误。
在
检查问题窗口的左侧,您可以选择
标签过滤器。 在翻译带有大量标签的文档时非常有用,这对于保存非常重要-例如在本地化软件时。
提示:如果您想不惜一切代价保存标签,可以防止OmegaT在标签有误的情况下创建最终文档。 这是在
工具→首选项→标记处理→不允许创建带有标记问题的翻译文档中完成的 。
可通过
工具→首选项→语言工具来微调语言工具
。 在这里,您可以选择使用内置语言工具还是连接到本地/远程服务器。 在下面,您可以选择程序将要响应的错误类型,例如,
复杂句子中的“介词” →“
介词前缺少逗号” ,或“
样式 ”→“
口语 ”。
如何打开TMX翻译记忆库?
碰巧您需要查看* .tmx文件中的内容,甚至进行编辑。 该文件的结构非常简单,可以在一定程度上使用记事本,但这不是很方便。 OmegaT无法打开
TMX进行编辑:翻译记忆库只能添加到项目中,而不能自己打开。
对于Windows用户,适合使用
Okapi软件包中的免费
Olifant实用程序,
您可以在此处下载 。
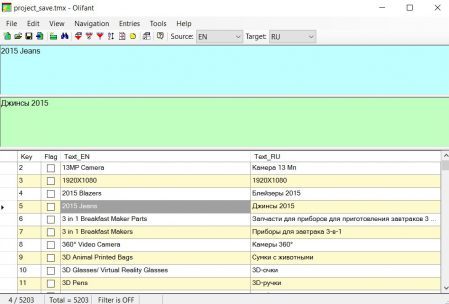
我认为没有理由为此程序编写分步说明,一切都很直观:
File→Open ,选择翻译记忆库。 在程序的顶部,原始和翻译在底部-所有段的列表。
通过
文件→TM属性,您可以更改翻译记忆库的属性,例如语言对,编码等。
如何创建自己的TM?
假设您已经有一个高质量的双语文件,并且您想在项目中将其用作参考资料。 如果文件为
Excel格式,原始文本位于一列中,而对应的翻译在相反的单元格中,则TM的创建非常容易。
我使用三种方式:
- 免费的Okapi Olifant实用程序
- 内置OmegaT对准器
- 在线服务 Translatum.gr
油脂
我们在上一章中讨论的程序不仅可以打开现成的
TMX ,还可以创建新的
TMX ,以及在一个内存中组合多个
* .tmx 。
安装并运行
Olifant ,单击
文件→新建,然后选择源语言和翻译语言。 现在,将双语句段添加到新的内存中:
文件→导入 。 您可以添加
Wordfast文件
,其他
* .tmx或
制表符分隔的文件 -换句话说,是文本文件,其中源片段及其翻译由制表符分隔。
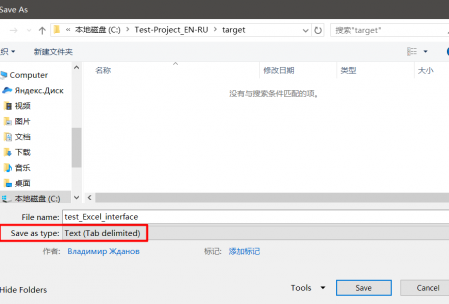
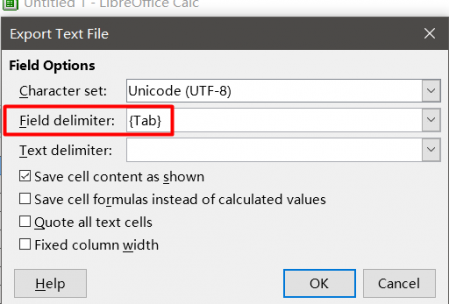
制表符分隔的文件可以在
MS Excel或
Libre Office Calc中创建 。 为此,请创建一个包含两列的表。 在第一行中,将源文本粘贴到第二列(翻译)相对的单元格中。
如果使用的是
Libre Office,则以
制表符分隔的文本格式(在
Microsoft Office中 )或使用参数
字段分隔符=制表符,字符集= UTF-8和
文本分隔符= *空*的 文本CSV保存文件。
导入所有必要的片段时,只需通过
文件→另存为 TMX格式 保存 。
OmegaT对准器
与Olifant不同,源代码不是具有两列的表,而是具有相同结构但使用不同语言的两个独立文件。 格式越复杂,差异越大,自动匹配的结果越差,但是可以在
Aligner中手动进行校正。
启动
OmegaT ,打开“
工具”→“对齐文件” 。 注明原文和译文的语言,并附上文件。
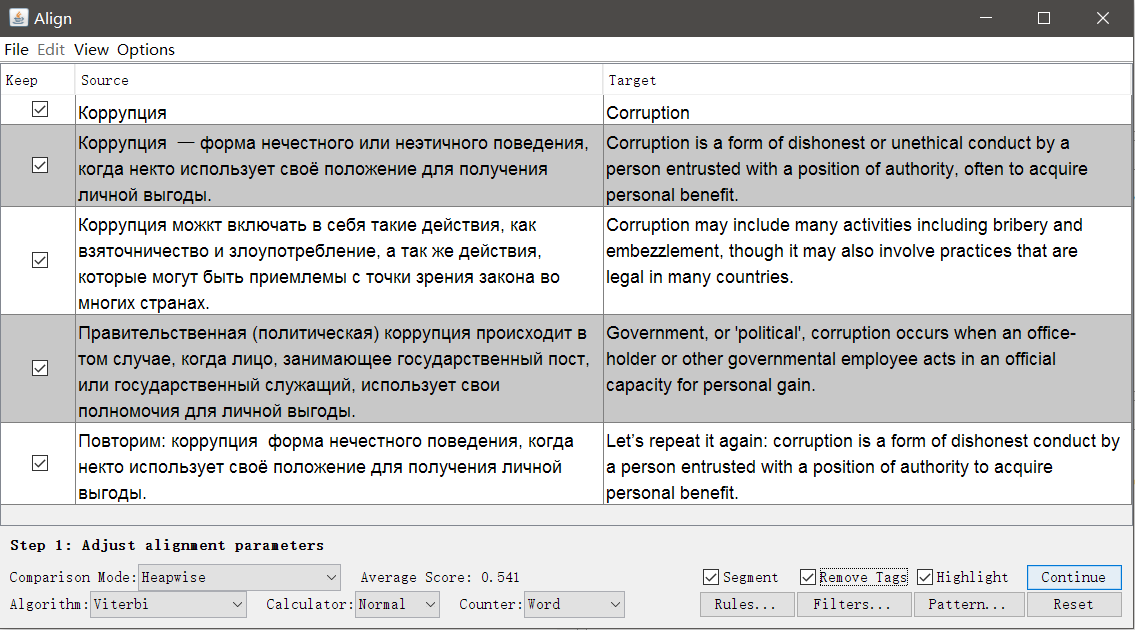
如有必要,您可以删除标签并更改细分设置。
点击继续,您将进入带手动调整线段的窗口:您可以上下分割,合并或移动线段。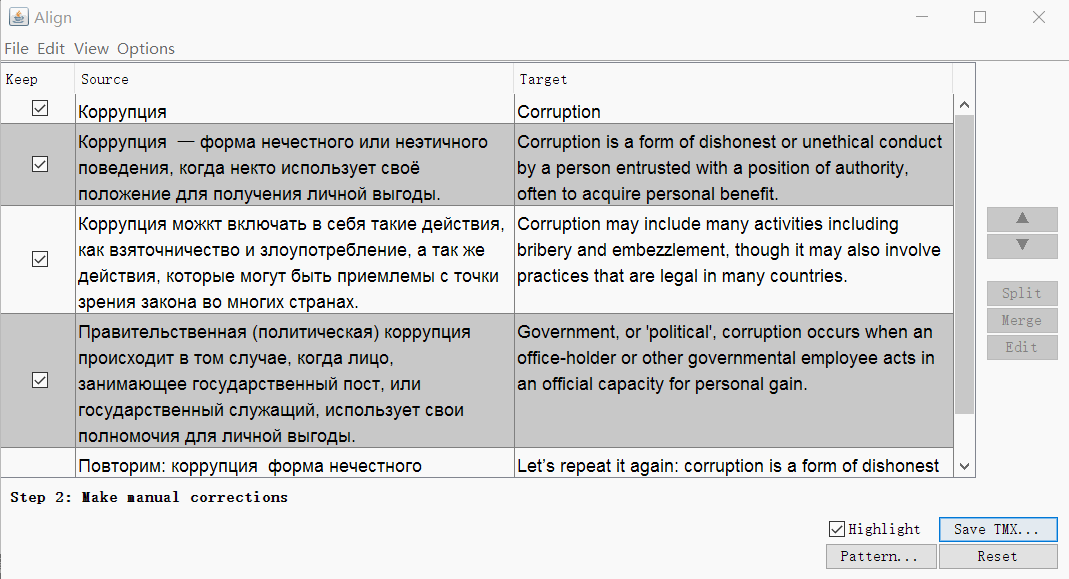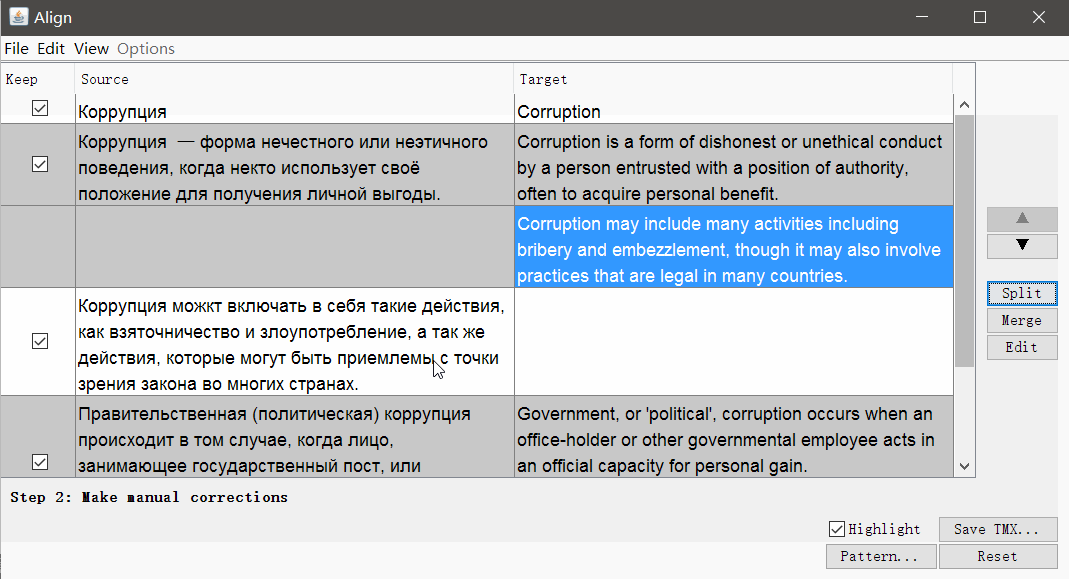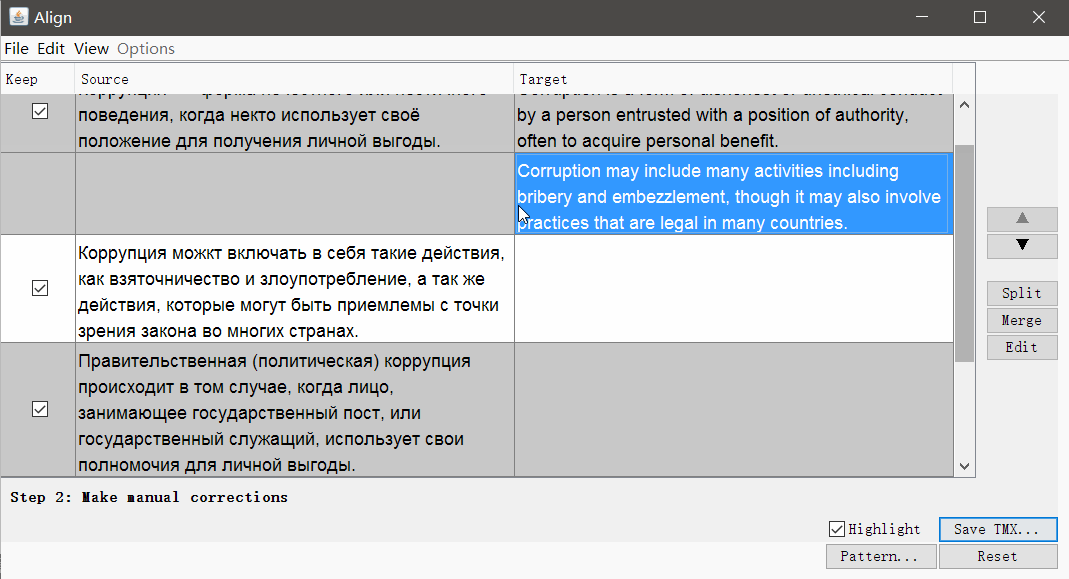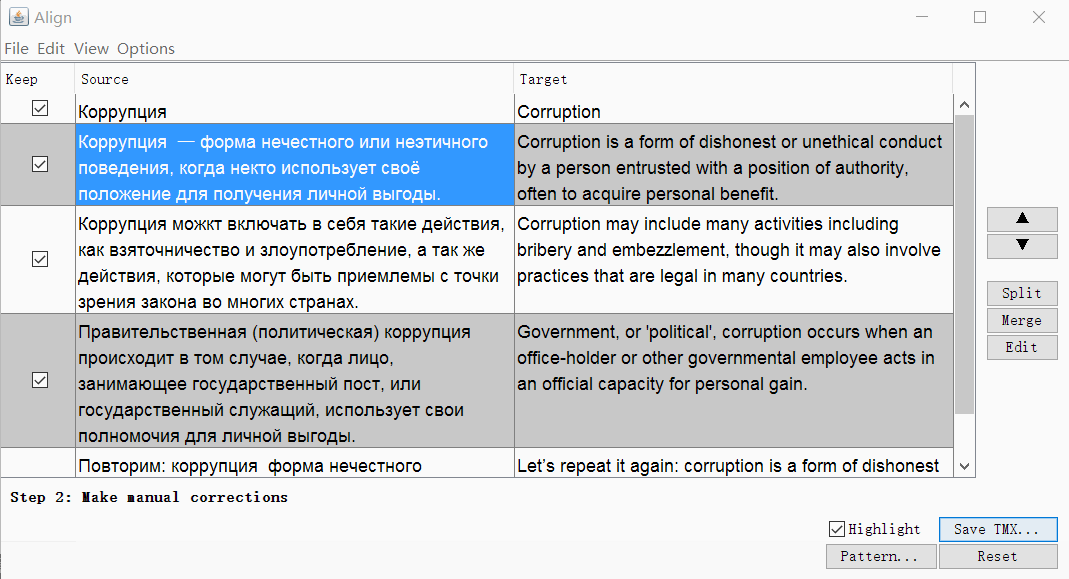 当一切看起来不错时,请使用“ 保存TMX”按钮保存结果。
当一切看起来不错时,请使用“ 保存TMX”按钮保存结果。翻译
它的工作方式与Olifant相似,在输入时,您需要提交包含两列文本的Excel文件。- 创建一个新的Excel文件(必填* .xlsx)
- 在第一列中插入原始文本,在第二列中-翻译
不要使用格式,它不会被保存 - 跟随转换器的链接
- 选择创建的文件
, - , EN-US RU-RU- Submit
- , .
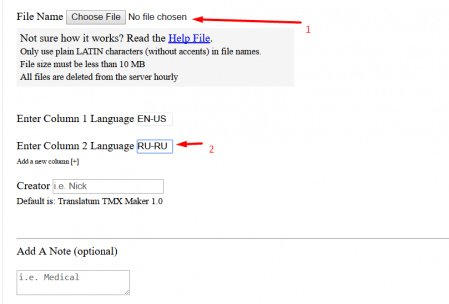 要在项目中使用翻译记忆库,请解压缩存档并将文件放在项目文件夹\ tm \(显示模糊匹配)或\ tm \ auto \(强制100%匹配)子目录中。注意!创建翻译记忆库时,有一个相当不愉快的错误,该错误使用特殊字符,例如“>”,“ <”甚至撇号。 TMX是XML结构,因此文档结构中使用的特殊字符将转换为“安全”的文本块。例如,撇号'将变成&pos;。 (和号,pos和分号)。在某些情况下,这会大大浪费翻译记忆库。实际上,我尚未找到解决该问题的方法。
要在项目中使用翻译记忆库,请解压缩存档并将文件放在项目文件夹\ tm \(显示模糊匹配)或\ tm \ auto \(强制100%匹配)子目录中。注意!创建翻译记忆库时,有一个相当不愉快的错误,该错误使用特殊字符,例如“>”,“ <”甚至撇号。 TMX是XML结构,因此文档结构中使用的特殊字符将转换为“安全”的文本块。例如,撇号'将变成&pos;。 (和号,pos和分号)。在某些情况下,这会大大浪费翻译记忆库。实际上,我尚未找到解决该问题的方法。如何计算项目量
我们必须告诉客户您将为转移支付多少费用!实际上,没有什么比这更容易了。在OmegaT中打开项目,请转到工具→统计。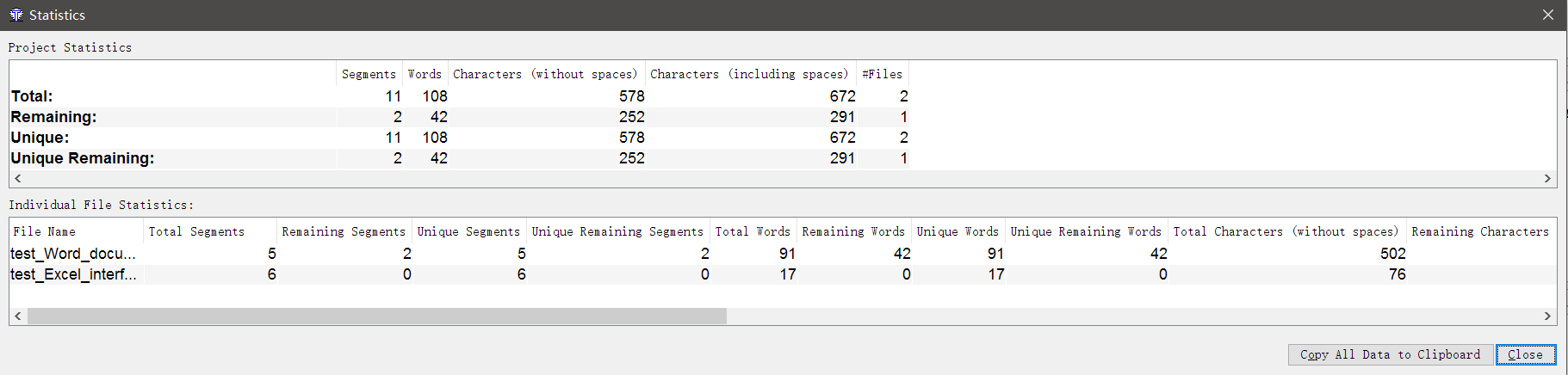 在这里,您将找到有关文件中有多少个单词和字符,此处有多少个重复项,已翻译了多少个以及还有多少个待翻译的内容的综合信息。不幸的是,OmegaT中没有计算器来计算翻译成本,您必须自己计算所有内容。
在这里,您将找到有关文件中有多少个单词和字符,此处有多少个重复项,已翻译了多少个以及还有多少个待翻译的内容的综合信息。不幸的是,OmegaT中没有计算器来计算翻译成本,您必须自己计算所有内容。如何合并和拆分细分?
碰巧您想将两个段合并为一个,反之亦然,迫使特定段拆分为两个部分。如果项目中的大量细分都遇到了问题,那么值得重新配置细分规则。如果需要按点合并或分割句段,请使用特殊的“ 合并或分割句段”脚本:- 安装脚本 在此处
下载,将其解压缩到\ scripts文件夹(在Windows上可以为C:\ Program Files(x86)\ OmegaT \ scripts \) - 制定细分规则项目特定
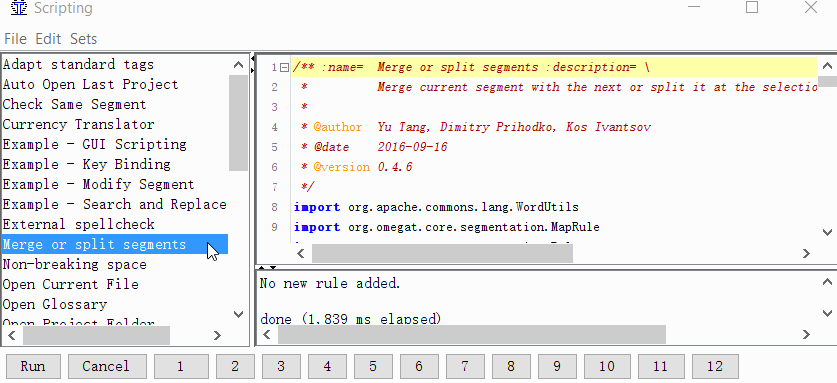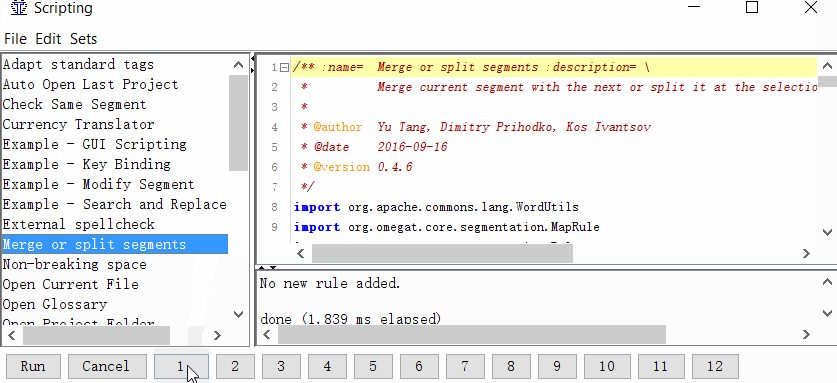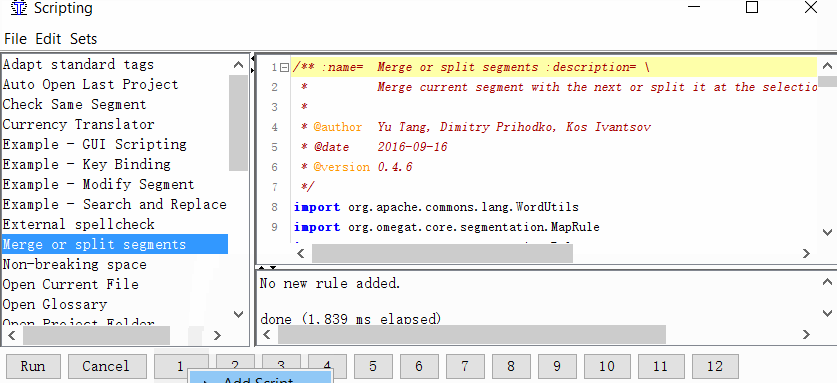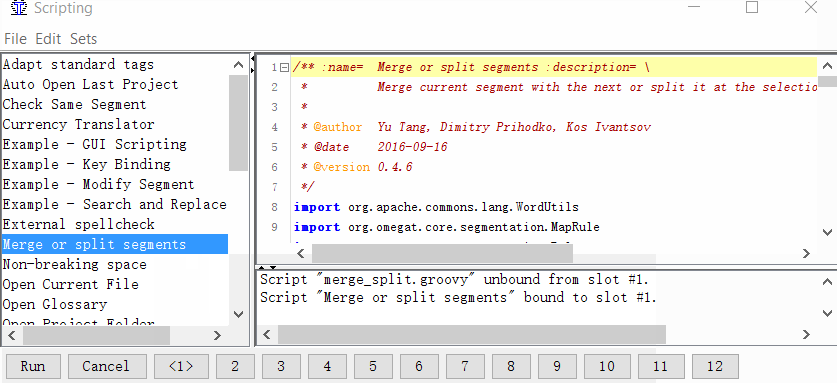
项目→属性→细分→选中复选框制定细分规则项目特定 - 给脚本一个按钮
Tools→Scripting,在窗口的左侧找到Merge或split segment,用鼠标单击选择它,然后右键单击窗口底部的数字之一。例如,每单位。然后单击添加脚本。
 现在,您可以合并或拆分细分。
现在,您可以合并或拆分细分。统合
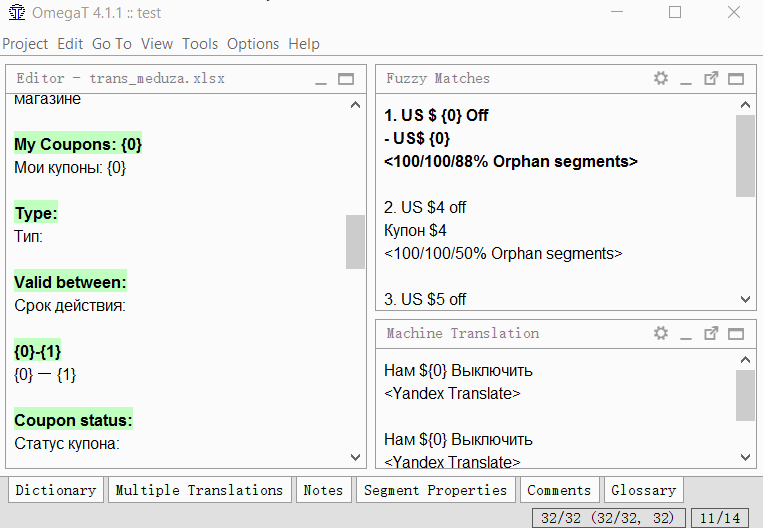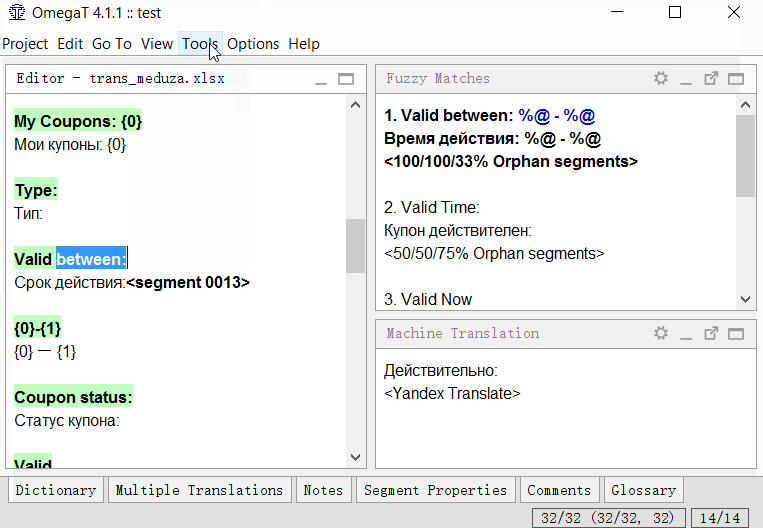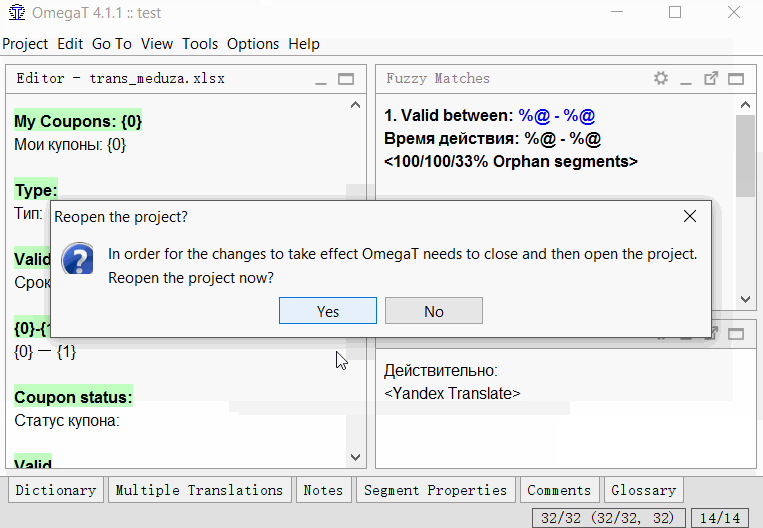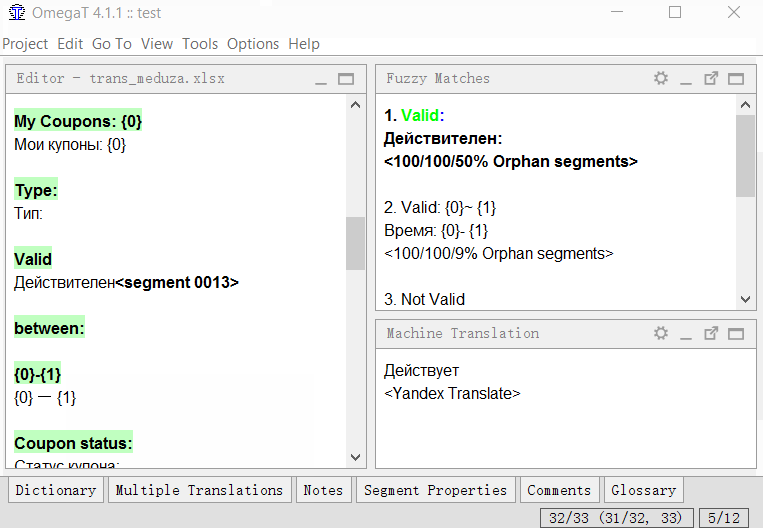
- 找到您要合并的两个分段;
- 转到第一段;
- 单击工具→1.合并或拆分细分
程序将显示警告以及合并结果。您可以单击“确定”以合并或取消操作。分离
- 找到您要拆分的细分;
- 在句段的源文本中(在翻译上方),选择要分割的文本的后半部分(从中间到最后)。
- 单击工具→1.合并或拆分细分
 程序将显示警告以及拆分结果。您可以单击“确定”拆分或取消操作。该脚本将创建一个新的细分规则,并将其应用于项目。该脚本与理想情况相去甚远,并且并非总是有效,但是到目前为止,在OmegaT中,这是按点分割/合并分段的唯一方法。
程序将显示警告以及拆分结果。您可以单击“确定”拆分或取消操作。该脚本将创建一个新的细分规则,并将其应用于项目。该脚本与理想情况相去甚远,并且并非总是有效,但是到目前为止,在OmegaT中,这是按点分割/合并分段的唯一方法。而不是结论
我将我舒适的小册子中的两个笔记合并成一张有关OmegaT的大纸页。我试图揭示其所有经常使用的主要功能。一定要在评论中写出为什么这篇文章很笨,以及它真正属于哪个中心。专业翻译人员应批评我的英俄翻译,并参加有关正常CAT程序的调查。PS:有谁知道为什么GT引擎不理解页面内的html链接?