 该任务的屏幕快照以及以自己的语言发布pix2code神经网络,然后编译器将其翻译为所需平台(Android,iOS)的代码
该任务的屏幕快照以及以自己的语言发布pix2code神经网络,然后编译器将其翻译为所需平台(Android,iOS)的代码新的
pix2code程序(
科学文章 )旨在促进从事繁琐的客户端GUI编码工作的程序员的工作。
设计人员通常会创建界面布局,而程序员必须编写代码以实现此设计。 这种工作占用了宝贵的时间,开发人员可以将这些时间花在更有趣和更具创造力的任务上,也就是花在实现程序的实际功能和逻辑上,而不是在GUI上。 很快,代码生成可以转移到程序的肩膀上。
pix2code项目是机器学习未来可能性的一个玩具演示,它已经
在GitHub上最热门的存储库列表中名列第一,尽管作者甚至没有发布用于训练神经网络的源代码和数据集! 对这个话题如此感兴趣。
编码GUI很无聊。 更糟糕的是,它们是不同平台上的不同编程语言。 也就是说,如果程序本机运行,则需要为Android编写单独的代码,为iOS编写单独的代码。 这会花费更多时间,并使您执行相同的无聊任务。 更准确地说,是以前。 pix2code程序为三个主要平台(Andriod,iOS和跨平台HTML / CSS)生成GUI代码,准确性为77%(通过程序的内置语言确定准确性-通过将生成的代码与每个平台的目标/预期代码进行比较)。
丹麦初创公司
UIzard Technologies的程序作者Tony Beltramelli称其为这一概念的演示。 他认为,进行缩放时,该模型将提高编码准确性,并有可能使人们不必手动编码GUI。
pix2code程序基于卷积神经网络和递归神经网络。 在Nvidia Tesla K80 GPU上的培训花费了不到五个小时的时间-在此期间,系统进行了优化
一个数据集的参数。 因此,如果您想在三个平台上训练她,则大约需要15个小时。
该模型能够通过仅从输入处的一个屏幕截图接受像素值来生成代码。 换句话说,神经网络不需要特殊的管道来提取特征并预处理输入数据。
可以将屏幕截图中计算机代码的生成与照片中文本描述的生成进行比较。 因此,pix2code模型的体系结构包括三个部分:1)一个计算机视觉模块,用于识别图像,在那里显示的对象,它们的位置,形状和颜色(按钮,标题,元素容器); 2)语言模块,用于理解文本(在这种情况下为编程语言)并生成句法和语义上正确的示例; 3)使用前面的两个模型为识别的对象(GUI元素)生成文本描述(代码)。
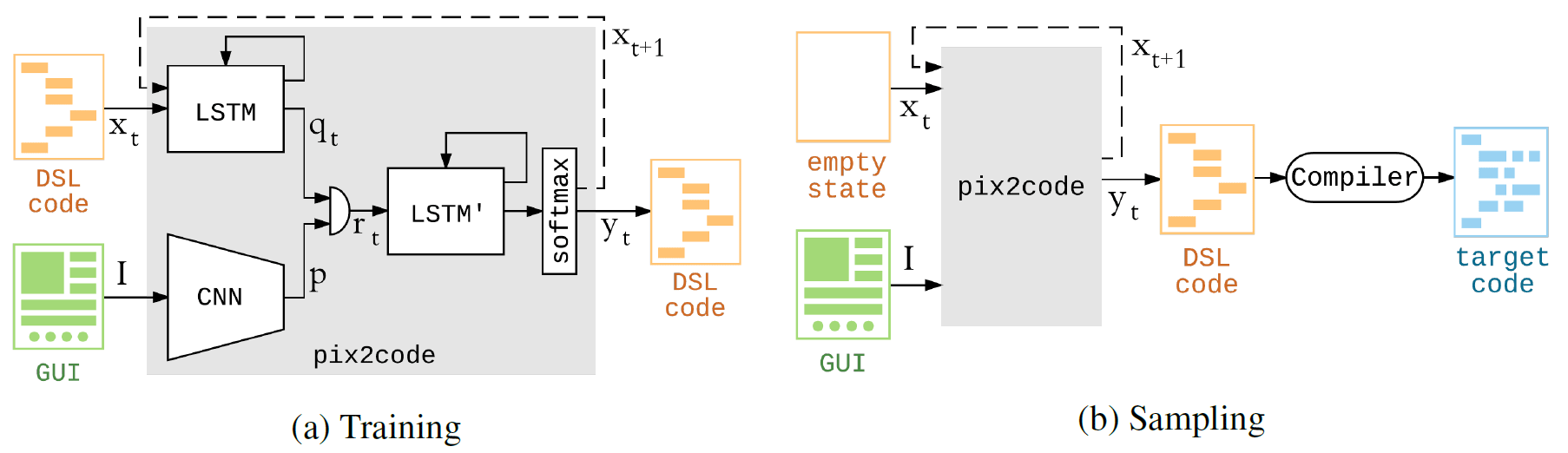
作者提请注意以下事实:可以在不同的数据集上训练神经网络-然后它将开始为其他平台生成其他语言的代码。 作者本人并不打算这样做,因为他将pix2code视为一种玩具,可以演示其创业公司正在研究的某些技术。 但是,任何人都可以创建该项目并为其他语言/平台创建实现。
Tony Beltramelli在科学论文中写道,他将在GitHub存储库中的公共领域发布用于训练神经网络的数据集。 存储库已创建。 作者在“常见问题解答”部分中阐明,他将在
NIPS 2017大会上发表(或拒绝发表)文章后发布数据集。 会议组织者将在9月初发出通知,因此数据集将同时出现在资源库中。 将提供GUI的屏幕快照,程序语言中的相应代码以及三个主要平台的编译器输出。
关于该程序的源代码,它的作者没有承诺要发布,但是鉴于对该程序的压倒性兴趣,他决定也将其打开。 这将与数据集的发布同时进行。
该科学文章于2017年5月22日在预印本网站arXiv.org(arXiv:1705.07962)上发表。