大多数现代台式计算机上的芯片都具有四个内核,但是芯片制造商已经宣布了升级到六个内核的计划,而如今,对于高性能服务器来说,16核处理器已经非常罕见。
内核越多,一起工作时所有内核之间的内存分配问题就越大。 随着内核数量的增加,最小化在数据处理过程中管理内核的时间损失变得越来越有利可图-因为数据交换速率落后于处理器和内存中数据处理的速度。 您可以从物理上转向其他人的快速缓存,也可以使用自己的慢速缓存,但可以节省数据传输时间。 程序所要求的内存量并不明显对应于每种类型的缓存大小,因此使任务变得复杂。
只能在物理上尽可能接近处理器地放置非常有限的内存-级别为L1的处理器高速缓存,其数量非常少。 麻萨诸塞州计算机科学研究院和人工智能实验室的研究人员Daniel Sanchez,Po-An Tsai和Nathan Beckmann
教计算机
如何配置不同类型的内存,以使其适应灵活的程序层次结构。实时的。 名为Jenga的新系统分析了访问程序到内存的容量需求和频率,并重新组合了三种类型的处理器高速缓存中的每一种的功能,从而提高了效率并节省了能源。

首先,研究人员在为单核处理器编写程序时使用静态和动态内存的组合测试了性能提升,并获得了主要层次结构-哪种组合最适合使用。 来自2种类型的内存或一种。 评估了两个参数-每个程序运行期间的信号延迟(延迟)和能耗。 结合多种类型的内存,大约40%的程序开始无法正常工作,其余的则更好。 研究人员确定了哪些程序“喜欢”混合性能以及哪些-内存大小后,便建立了他们的Jenga系统。
他们在具有36个内核的虚拟计算机上虚拟测试了4种类型的程序。 测试了程序:
- omnet-Objective Modular Network Testbed,C建模库和网络建模工具平台(图片中的蓝色)
- mcf-元内容框架(红色)
- astar-用于显示虚拟现实的软件(绿色)
- bzip2-存档器(紫色)
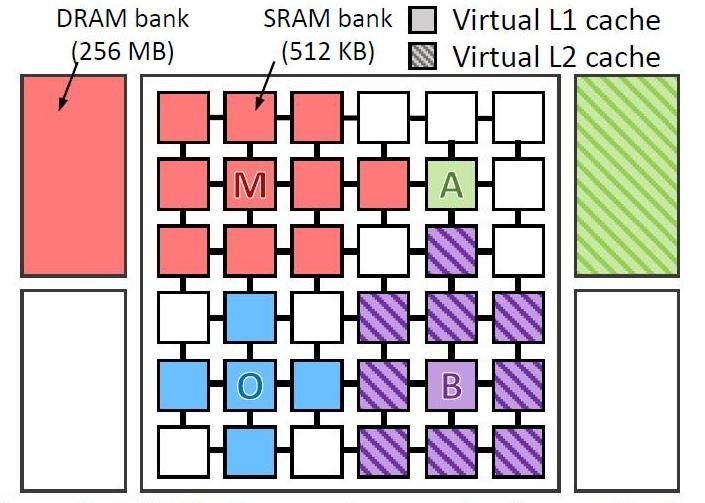
该图显示了在何处以及如何处理每个程序的数据。 字母表示每个应用程序的运行位置(每个象限一个),颜色表示其数据所在的位置,阴影线表示存在时虚拟层次结构的第二级。
缓存级别CPU缓存分为几个级别。 对于通用处理器-最多3个。最快的内存是一级缓存-L1缓存,因为它与处理器位于同一芯片上。 由命令缓存和数据缓存组成。 某些没有L1缓存的处理器无法运行。 L1高速缓存以处理器频率运行,并且可以在每个时钟周期对其进行访问。 通常可以同时执行多个读/写操作。 该卷通常很小-不超过128 KB。
L1缓存与第二级缓存L2交互。 这是第二快的。 通常,它位于芯片上(例如L1),或者位于内核的紧邻区域(例如,处理器盒中)。 在较旧的处理器中,主板上的芯片组。 L2缓存的大小从128 KB到12 MB。 在现代多核处理器中,位于同一芯片上的二级缓存是共享内存-总缓存大小为8 MB,每个内核2 MB。 通常,位于核心芯片上的L2缓存的等待时间介于8到20个时钟周期之间。 在与对有限内存区域的大量访问相关的任务(例如,DBMS)中,充分利用它可使生产率提高十倍。
L3高速缓存通常甚至更大,尽管比L2稍慢(由于L2和L3之间的总线比L1和L2之间的总线窄)。 L3通常与CPU内核分开放置,但可能很大-超过32 MB。 L3缓存比以前的缓存慢,但仍比RAM快。 在多处理器系统中是普遍使用的。 在非常窄的任务范围内使用第三级缓存是合理的,不仅可以提高生产率,反之亦然,并导致系统性能普遍下降。
当数据量小于缓存大小时,禁用第二级和第三级缓存在数学问题中最有用。 在这种情况下,您可以立即将所有数据加载到L1缓存中,然后进行处理。
在给定资源限制和应用程序行为的情况下,Jenga会定期在OS级别上重新配置虚拟层次结构,以最大程度地减少数据交换。 每个重新配置都包含四个步骤。
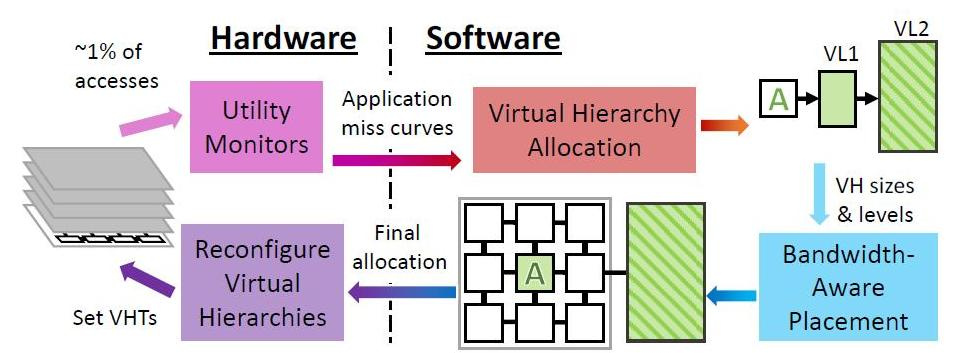
Jenga不仅根据分发的程序(喜欢大型单速内存或喜欢混合高速缓存的性能)来分发数据,还取决于存储单元与正在处理的数据的物理距离。 无论程序在默认情况下还是在层次结构中需要哪种缓存。 最主要的是使信号延迟和能量消耗最小化。 根据程序“喜欢”多少种内存,Jenga用一个或两个级别对每个虚拟层次的延迟进行建模。 两级层次结构形成一个曲面,单级层次结构形成一条曲线。 然后,Jenga设计了VL1尺寸的最小延迟,它给出了两条曲线。 最后,Jenga使用这些曲线来选择最佳的层次结构(即VL1大小)。
叠叠乐的使用产生了明显的效果。 36核虚拟芯片速度提高了30%,功耗降低了85%。 当然,虽然Jenga只是对工作计算机的模拟,但是要看到此缓存的真实示例,甚至在芯片制造商愿意接受它之前,还需要一些时间。
有条件的36核电机配置
- 处理器 。 36核,x86-64 ISA,2.4 GHz,类似于Silvermont的OOO:8B宽
ifetch; 2级bpred,具有512×10位BHSR + 1024×2位PHT,2路解码/发布/重命名/提交,32项IQ和ROB,10项LQ,16项SQ; 371 pJ /指令,163 mW /核心静态功率 - L1级缓存 。 32 KB,8路集关联,拆分数据和指令缓存,
3周期延迟; 每次击中/错过15/33 pJ - 预取器预取服务 。 对16个条目的流预取器进行建模并针对
Nehalem - 二级缓存 。 每核128 KB专用,8路集关联,包括在内的6周期延迟; 每次击中/未击中46/93 pJ
- 相干模式(Coherence) 。 Jenga的16路6周期延迟目录库; 他人的缓存L3目录
- 全球NoC 。 6×6网格,128位分支和链接,XY路由,2周期流水线路由器,1周期链接; 每个路由器/链路摆线遍历为63/71 pJ,路由器/链路静态功率为12 / 4mW
- SRAM静态存储块 。 18 MB,每个图块一个512 KB存储区,4路52候选zcache,9周期存储区延迟,Vantage分区; 每次命中/未命中时240/500 pJ,28 mW /库静态功率
- 多层动态存储器堆叠DRAM 。 1152MB,每4个磁贴一个128MB保管库,带有MAP-1 DDR3-3200(1600MHz)的Alloy,128位总线,16个等级,8个存储组/等级,2 KB行缓冲区; 每次命中/未命中时为4.4 / 6.2 nJ,88 mW /保险库静态功率
- 主存 。 4个DDR3-1600通道,64位总线,2个等级/通道,8个存储区/等级,8 KB行缓冲区; 20 nJ /访问,4W静态功率
- DRAM时序 。 tCAS = 8,tRCD = 8,tRTP = 4,tRAS = 24,tRP = 8,tRRD = 4,tWTR = 4,tWR = 8,tFAW = 18 )