 著名政客和演员的数字双打都受到“伪造者”的完全控制。 插图:华盛顿大学,2015年
著名政客和演员的数字双打都受到“伪造者”的完全控制。 插图:华盛顿大学,2015年结合神经网络的3D图形程序已经达到了这样的质量,即假视频几乎与真实视频没有区别。 很快将无法确定地说电视屏幕上的人是真正的政客,而不是计算机模拟。
2015年12月,华盛顿大学的科学家介绍了
“数字双打”技术 :从数百张一个角色的照片中创建“实时” 3D模型。 Internet上已经为名人和政客收集了巨大的照片档案。 该程序会创建一个模型,就像一个绳子上的玩偶一样-您可以随意控制它,给出不同的面部表情,用嘴唇说话。
现在,在
SIGGRAPH 2017计算机图形会议的前夕,同一组研究人员发表了具有先进版本“数字对等物”的新
科学著作 。
现在,在教程序时,不仅使用照片,还使用视频,因此培训变得更加有效。 为了演示这项技术,科学家们选择了一个著名人物-美国前总统奥巴马。 这是一个不错的选择,因为Internet上有大量的高清视频资料。 数百万个视频帧可用于训练神经网络。
这个神经网络已经详细研究了奥巴马面部表情的特征:每种声音的嘴唇运动,眼睛附近皱纹的出现,眉毛形状的变化和头的倾斜。 实验人物的面部表情与他的发音有关:神经网络不仅处理视频帧,还处理视频帧。
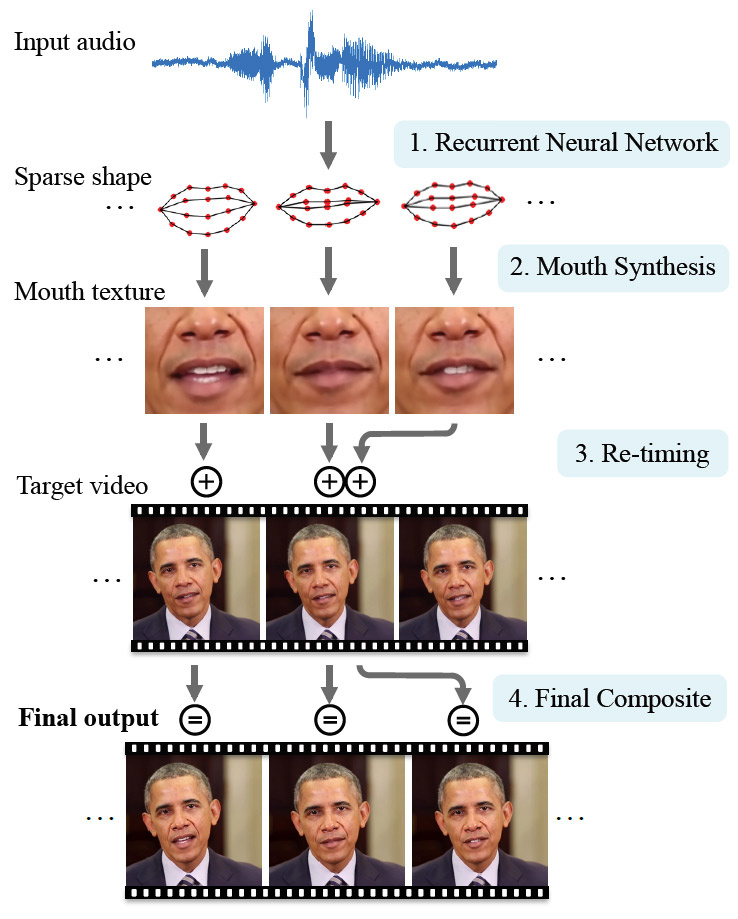
因此,弱小的AI学会了将面部表情和嘴唇动作与研究人员馈入神经网络输入的任意语音同步。
科学工作的预告片将奥巴马演讲的真实视频记录与神经网络合成的结果进行比较。
应该注意的是,合成结果与原始结果明显不同,但是看起来仍然很现实。
研究人员强调,为了获得“数字双打”,人们被迫在摄像机前重复重复相同的短语,以记录语素和面部表情的所有组合。 现在,您可以在公开视频上进行此操作。 的确,并非每个互联网人都拥有足够的视频材料来伪造自己的个性,但是随着时间的流逝,用户自己可以通过将数十亿字节的照片和视频上传到社交网络来解决此问题。
从实际的角度来看,也可以使用该技术。 例如,科学著作的合著者之一Ira Kemelmacher-Shlizerman
说 ,如果丢失的帧落在视频流中,她将通过合成丢失的帧来提高视频会议的质量。 如果声音不受干扰,并且视频滞后,则这种合成将补充图片或提高其分辨率。 当然,如果玩家与虚拟角色进行交流,则该技术可以在计算机游戏和虚拟现实中找到应用。 现在,虚拟角色的语音将变得更加逼真,并且可以是某些真实人物的数字副本。 例如,您只能通过录音来“复兴”最近的历史人物。 当然,将促进出于政治目的制造假货。 如果现在将它们
在“ Photoshop”中模制并投入社交网络 ,那么将来将在电视上播放假视频。
作者承认,到目前为止,该技术还不是完美的。 例如,如果奥巴马的脸稍微偏离相机,那么他的嘴巴部分可能会与脸分开并与背景重叠。 但是这些都是较小的错误,可以通过对神经网络进行额外的训练来纠正。
创建的模型的另一个缺点是它不能模拟情绪。 面部表情绝对是中立的,几乎总是一样。 因此,在某些情况下,数字双精度版会失去其真实感:对于其发音轻率的单词,其面部表情似乎过于严肃。 反之亦然-对于非常严肃的演讲太轻描淡写了。 但是,此类事件发生在现实生活中的真正政客中。

所创建的技术在原理上类似于
用于创建Face2Face数字双打程序的程序,该
程序将一个人的面部表情和语音转移到另一个人的面部。 在他们的科学工作中,华盛顿的作者将其神经网络的结果与Face2Face进行了比较。 他们解释说,在Face2Face的情况下,始终需要视频流来进行仿真,并且它们的模型仅通过录音来工作。