
20世纪初,德国驯马师和数学家威廉·冯·奥斯汀(Wilhelm von Austin)向世界宣布,他教过一匹数马。 多年来,冯·奥斯汀(von Austin)曾在这个现象的演示上环游德国。 他要求他的马(绰号
Clever Hans) (繁殖
奥尔洛夫猪蹄 )来计算简单方程的结果。 汉斯回答,踩了蹄。 二加二? 四命中。
但是科学家们并不认为汉斯像冯·奥斯丁所宣称的那样聪明。 心理学家
卡尔·斯托普夫(Karl Stumpf)进行了彻底的调查,被称为“汉斯委员会”。 他发现Smart Hans不会求解方程式,但会响应视觉信号。 汉斯轻拍蹄子直到得到正确答案,此后他的教练和热情的人群大声尖叫。 然后他停了下来。 当他没有看到这些反应时,他继续敲门。
计算机科学可以从汉斯那里学到很多东西。 该领域的发展步伐加快表明,我们创建的大多数AI都经过了足够的培训,可以提供正确的答案,但并不能真正理解信息。 而且很容易傻。
机器学习算法很快变成了全人类的牧羊人。 该软件将我们连接到Internet,监视我们邮件中的垃圾邮件和恶意内容,并将很快开车。 他们的欺骗改变了互联网的构造基础,并威胁到我们未来的安全。
来自宾夕法尼亚州立大学,来自谷歌,来自美国军方的小型研究小组正在制定计划,以防止对AI的潜在攻击。 该研究提出的理论认为,攻击者可以改变机器人的“视野”。 或激活电话上的语音识别,并使用只会对人产生噪音的声音,迫使其进入恶意网站。 或者让病毒通过网络防火墙泄漏。
 左侧是建筑物的图像,右侧是修改后的图像,深层神经网络与鸵鸟有关。 在中间,显示了应用于主图像的所有更改。
左侧是建筑物的图像,右侧是修改后的图像,深层神经网络与鸵鸟有关。 在中间,显示了应用于主图像的所有更改。代替控制机器人的控制,此方法向他显示了幻觉之类的东西-一种实际上不存在的图像。
此类攻击使用带有技巧的图像[对抗示例-没有确定的俄语术语,一字不漏地显示出类似“具有对比的示例”或“竞争示例”之类的内容。 翻译:]图像,声音,文字看起来很普通,但是却被完全不同的机器所感知。 攻击者所做的微小更改可能导致深度神经网络对其显示的内容得出错误的结论。
伯克利大学的研究员Alex Kanchelyan说:“任何使用机器学习来做出对安全性至关重要的决策的系统都可能受到此类攻击的威胁。”他使用欺骗性图像研究机器学习攻击。
了解AI开发早期的这些细微差别为研究人员提供了一种工具,以了解如何纠正这些缺陷。 一些人已经接受了这一点,他们说,因此,他们的算法变得越来越有效。
人工智能研究的大部分主流都基于深度神经网络,而深度神经网络又基于更广泛的机器学习领域。 MoD技术使用微分,积分和统计技术来创建我们大多数人使用的软件,例如邮件中的垃圾邮件过滤器或搜索Internet。 在过去的20年中,研究人员已开始将这些技术应用于新的想法,即神经网络,即模仿大脑功能的软件结构。 这个想法是将计算分散到成千上万个接收数据,处理并将其进一步传输到下一个成千上万个小方程层的小方程(“神经元”)中。
这些AI算法的训练方式与MO相同,而MO则复制了一个人的学习过程。 它们显示了不同事物及其相关标签的示例。 向计算机(或孩子)显示猫的图像,说猫看起来像这样,算法将学会识别猫。 但是为此,计算机将必须查看成千上万只猫和猫的图像。
研究人员发现,这些系统可能会受到特殊选择的欺骗性数据的攻击,他们称之为“对抗性例子”。
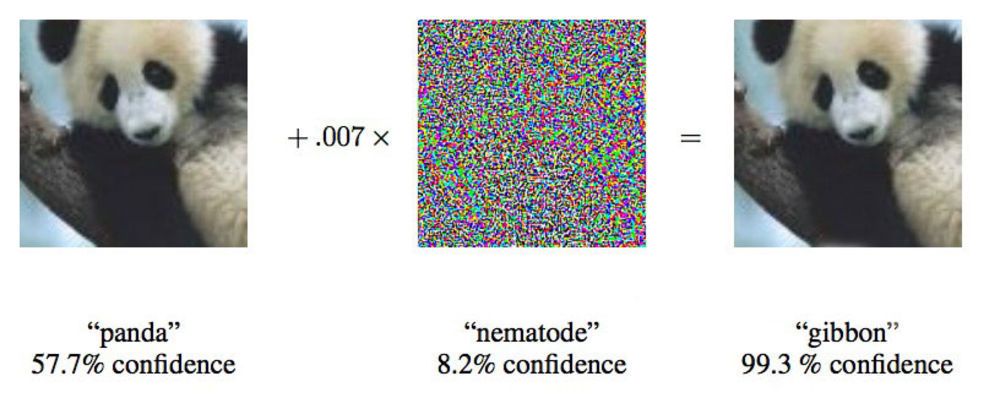 在2015年发表的一篇论文中,来自Google的研究人员表明,深度神经网络可能被迫将这种熊猫形象归因于长臂猿。
在2015年发表的一篇论文中,来自Google的研究人员表明,深度神经网络可能被迫将这种熊猫形象归因于长臂猿。Google研究人员伊恩·古德弗洛(Ian Goodfellow)积极致力于神经网络的此类攻击,他说:“我们为您提供了清晰地显示校车的照片,并使您认为它是鸵鸟。”
研究人员仅将提供给神经网络的图像更改了4%,就可以诱骗他们在97%的案例中使用分类进行错误处理。 即使他们不确切知道神经网络如何处理图像,他们也可能在85%的情况下欺骗它。 在网络体系结构上没有数据
的欺诈行为
的最后一个变种称为“黑匣子攻击”。 这是首次在深度神经网络上进行这种功能性攻击的案例记录,其重要性在于,在这种情况下,大约可以在现实世界中发生攻击。
在这项研究中,来自宾夕法尼亚州立大学,谷歌和美国海军研究实验室的研究人员攻击了一个神经网络,该网络对MetaMind项目支持的图像进行分类,并作为开发人员的在线工具。 该团队构建并训练了受攻击的网络,但是无论采用哪种架构,他们的攻击算法都有效。 通过这种算法,他们能够以84.24%的准确性欺骗黑盒神经网络。
 照片和字符的第一行-正确的字符识别。
照片和字符的第一行-正确的字符识别。
最底行-网络被迫识别完全错误的标志。向机器提供不准确的数据并不是一个新主意,但是相比之下,伯克利大学的教授道格·泰格(Doug Tygar)则研究机器学习已有10年之久,他说,这种攻击技术已经从简单的MO演变为复杂的深度神经网络。 恶意黑客多年来一直在垃圾邮件过滤器上使用此技术。
老虎的研究来自
他2006年与国防部在网络上进行的此类攻击的研究,他在2011年得到了加州大学伯克利分校和微软研究院的研究人员的帮助下进行了
扩展 。 Google团队是第一个使用深度神经网络的团队,在发现此类攻击的可能性两年后,于2014年发布了其
第一篇论文。 他们想确保这不是某种异常,而是真正的可能性。 2015年,他们发表了另一篇
著作 ,其中描述了一种保护网络并提高其效率的方法,此后,伊恩·古德费洛(Ian Goodfellow)就该领域的其他科学著作(包括
黑匣子攻击)提出了建议 。
研究人员将不可靠信息的更为笼统的概念称为“拜占庭数据”,并且由于研究的进展,他们进入了深度学习。 该术语来自著名的“
拜占庭将军的任务 ”,这是计算机科学领域的一项思想实验,其中一群将军必须在信使的帮助下协调其行动,而不必确信其中一个是叛徒。 他们不能信任从同事那里收到的信息。
Taigar说:“这些算法旨在处理随机噪声,但不能处理拜占庭数据。” 为了了解此类攻击的工作原理,Goodfello建议以色散图的形式想象一个神经网络。
图中的每个点代表神经网络处理的图像的一个像素。 通常,网络尝试通过最适合所有点集的数据划一条线。 实际上,这有点复杂,因为不同的像素对于网络具有不同的值。 实际上,这是由计算机处理的复杂多维图。
但是,以简单的散点图类比来说,通过数据绘制的线条的形状决定了网络认为看到的东西。 为了成功攻击此类系统,研究人员只需更改这些要点的一小部分,并使网络做出实际上不存在的决定。 在看起来像鸵鸟的公共汽车的例子中,校车的照片上点缀着像素,这些像素是根据与网络熟悉的鸵鸟照片的独特特征相关的图案排列的。 这是肉眼看不见的轮廓,但是当算法
处理并简化数据时 ,鸵鸟的极端数据点似乎是合适的分类选项。 在黑盒版本中,研究人员测试了使用不同的输入数据来确定算法如何看待某些对象。
通过为对象分类器提供虚假输入并研究机器做出的决策,研究人员能够恢复该算法以欺骗图像识别系统。 在这种情况下,这种自动驾驶汽车系统可能会看到“让步”标志,而不是停车标志。 当他们了解网络的工作原理后,便能够使机器看到任何东西。
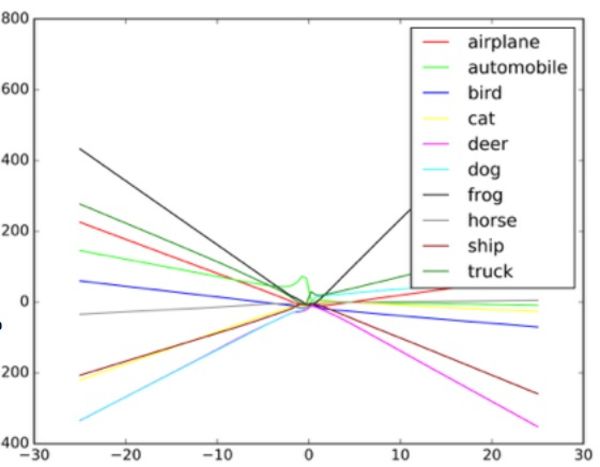 图像分类器如何根据图像中的不同对象绘制不同线条的示例。 伪造的示例可以视为图表上的极值。
图像分类器如何根据图像中的不同对象绘制不同线条的示例。 伪造的示例可以视为图表上的极值。研究人员说,这种攻击可以绕过相机直接输入到图像处理系统中,或者可以用真实的符号进行这些操作。
但是哥伦比亚大学的安全专家艾莉森·毕晓普(Alison Bishop)表示,这样的预测是不现实的,并且取决于机器人的使用系统。 如果攻击者已经可以从摄像机访问数据流,则他们可以为其提供任何输入。
她说:“如果他们能到达相机的入口,就不需要这些困难了。” “你可以给她看停车牌。”
除了绕过摄像机之外,其他攻击方法(例如,在真实标志上绘制视觉标记)对Bishop来说似乎不太可能。 她怀疑机器人上使用的低分辨率摄像头通常能否区分标志的微小变化。
 左侧的原始图像被分类为校车。 在右侧更正-像鸵鸟一样。 在中间-图片发生变化。
左侧的原始图像被分类为校车。 在右侧更正-像鸵鸟一样。 在中间-图片发生变化。有两个小组,一个在伯克利大学,另一个在乔治敦大学,已经成功开发了算法,可以向诸如Siri和Google Now之类的数字助理发出语音命令,听起来像听不到声音。 对于一个人来说,这样的命令看起来像是随机的杂音,但同时它们也可以将命令提供给Alexa之类的设备,而不是其所有者预见的。
拜占庭式音频攻击的研究人员之一尼古拉斯·卡利尼(Nicholas Carlini)说,在他们的测试中,他们能够激活开源音频识别程序Siri和Google Now,其准确率超过90%。
噪音就像某种科幻外星人的谈判。 这是白噪声和人声的混合,但根本不像语音命令。
根据Carlini的说法,在这种攻击中,任何听到电话噪音的人(虽然有必要分别计划对iOS和Android的攻击)都可以被迫进入同时播放噪音的网页,这将感染附近的电话。 或者此页面可能会悄悄下载恶意软件程序。 这样的噪声也有可能在无线电中丢失,并且会被白噪声或与其他音频信息并行隐藏。
发生这种攻击的原因是,机器训练有素,可以确保几乎所有数据都包含重要数据,并且一件事比另一件事更普遍(如Goodfello所解释)。
欺骗网络,强迫它认为自己看到了一个公共的对象,这很容易,因为它认为应该更频繁地看到这样的对象。 因此,Goodfellow和怀俄明大学的另一个小组得以使网络对根本不存在的图像进行分类-识别出白噪声中的物体,随机创建了黑白像素。
在Goodfellow的一项研究中,通过网络的随机白噪声被她归类为一匹马。 巧合的是,这使我们回到了聪明汉斯(Clever Hans)的故事,这匹马在数学上并不是很天赋。
Goodfellow说,像Smart Hans这样的神经网络实际上并不学习任何想法,而只是在发现正确的想法时才进行发现。 差异很小但很重要。 缺乏基础知识有助于恶意尝试重新创建发现“正确”算法结果的外观,而事实证明这是错误的。 要了解什么是机器,机器还必须了解它不是什么。
Goodfello在训练网络对自然图像和已处理(伪)图像上的图像进行排序后发现,他不仅可以将此类攻击的效率降低90%,而且可以使网络更好地应对初始任务。
Goodfellow说:“通过使人们能够解释真正不寻常的伪造图像,您可以获得对基础概念的更可靠的解释。”
两组音频研究人员使用了类似于Google团队的方法,通过过度训练来保护神经网络免受自身攻击。 他们也取得了类似的成功,攻击效率降低了90%以上。
毫无疑问,这一研究领域引起了美军的兴趣。 陆军研究实验室甚至赞助了关于该主题的两项最新作品,包括黑匣子袭击。 尽管该机构正在资助研究,但这并不意味着技术将用于战争。 根据该部门代表的说法,从研究到适合士兵使用的技术最多可以使用10年。
美国陆军实验室的研究员Ananthram Swami参与了几项有关AI欺骗的最新作品。 军队对我们世界中检测和阻止欺诈性数据的问题很感兴趣,因为在这个世界中并非所有信息源都可以得到仔细检查。 Swami指向一组数据,这些数据是从位于大学并在开源项目中工作的公共传感器获取的。
“我们并不总是控制所有数据。 “我们的对手很容易欺骗我们,”斯瓦米说。 “在某些情况下,这种欺诈的后果可能是轻浮的,在某些情况下则相反。”
他还说,军队对自动驾驶机器人,坦克和其他车辆感兴趣,因此研究的目标显而易见。 通过研究这些问题,陆军将能够在开发不受此类攻击影响的系统中赢得领先。
但是,任何使用神经网络的团体都应该担心AI欺骗攻击的可能性。 机器学习和AI尚处于起步阶段,此时安全漏洞可能会带来可怕的后果。 许多公司对尚未通过时间考验的AI系统信任高度敏感的信息。 我们的神经网络还太年轻,以至于我们都不了解我们需要的一切。
类似的疏忽导致
微软的Twitter机器人Tay迅速成为种族主义者,倾向于种族灭绝。 恶意数据的流动和“在我之后重复执行”功能导致Tay与预期路径有很大偏离。 该机器人被不合格的输入所欺骗,这是机器学习实施不佳的便利示例。
坎切尔扬说,他不认为Google团队成功进行研究后,已经将这种攻击的可能性穷尽了。
Kanchelyan说:“在计算机安全领域,攻击者始终领先于我们。” “宣称我们通过反复训练已经解决了神经网络欺骗的所有问题,将是非常危险的。”