从首次关于这个主题的科学研究到谷歌宣布
将谷歌翻译服务完全转移到深度学习的时刻,借助神经网络进行机器翻译已有
很长的路要走 。
如您所知,神经转换器的基础是建立在矩阵计算基础上的双向递归神经网络机制,与统计机器转换器相比,它使您可以建立更复杂的概率模型。 但是,始终认为神经翻译(如统计翻译)需要并行的双语文本进行训练。 正在这些建筑物上训练神经网络,以人工翻译为参考。
事实证明,即使没有平行的语料库,神经网络也能够掌握一种新的翻译语言! 关于此主题的
两部作品已在arXiv.org预印本网站上发布。
“想象一下,您给一个人很多中文书籍和很多阿拉伯语书籍-其中没有相同的书籍-并且这个人正在学习从中文译成阿拉伯语的过程。 似乎不可能吧? 但是我们证明了计算机可以做到这一点,”位于西班牙圣塞巴斯蒂安的巴斯克大学(University of the Basque Country)的计算机科学家Mikel Artetxe
说 。
大多数机器翻译神经网络都是由“老师”教的,其作用恰恰是人翻译的平行语料库。 粗略地说,在学习过程中,神经网络进行假设,对照标准进行检验,并在其系统中进行必要的设置,然后进一步学习。 问题在于,对于世界上的某些语言,没有大量的并行文本,因此它们不适用于传统的机器翻译神经网络。
两种新模型提供了一种新方法:在
没有老师的情况下教机器翻译神经网络。 系统本身正在尝试组成一种平行的文本语料库,将单词彼此聚集在一起。 事实是,世界上大多数语言都具有相同的含义,它们仅对应于不同的词。 因此,几乎所有语言都将所有这些含义分组为相同的类,即,将相同的单词含义围绕相同的单词含义进行分组(请参阅文章“
Google翻译神经网络汇编了人类单词含义的统一基础 ”) 。
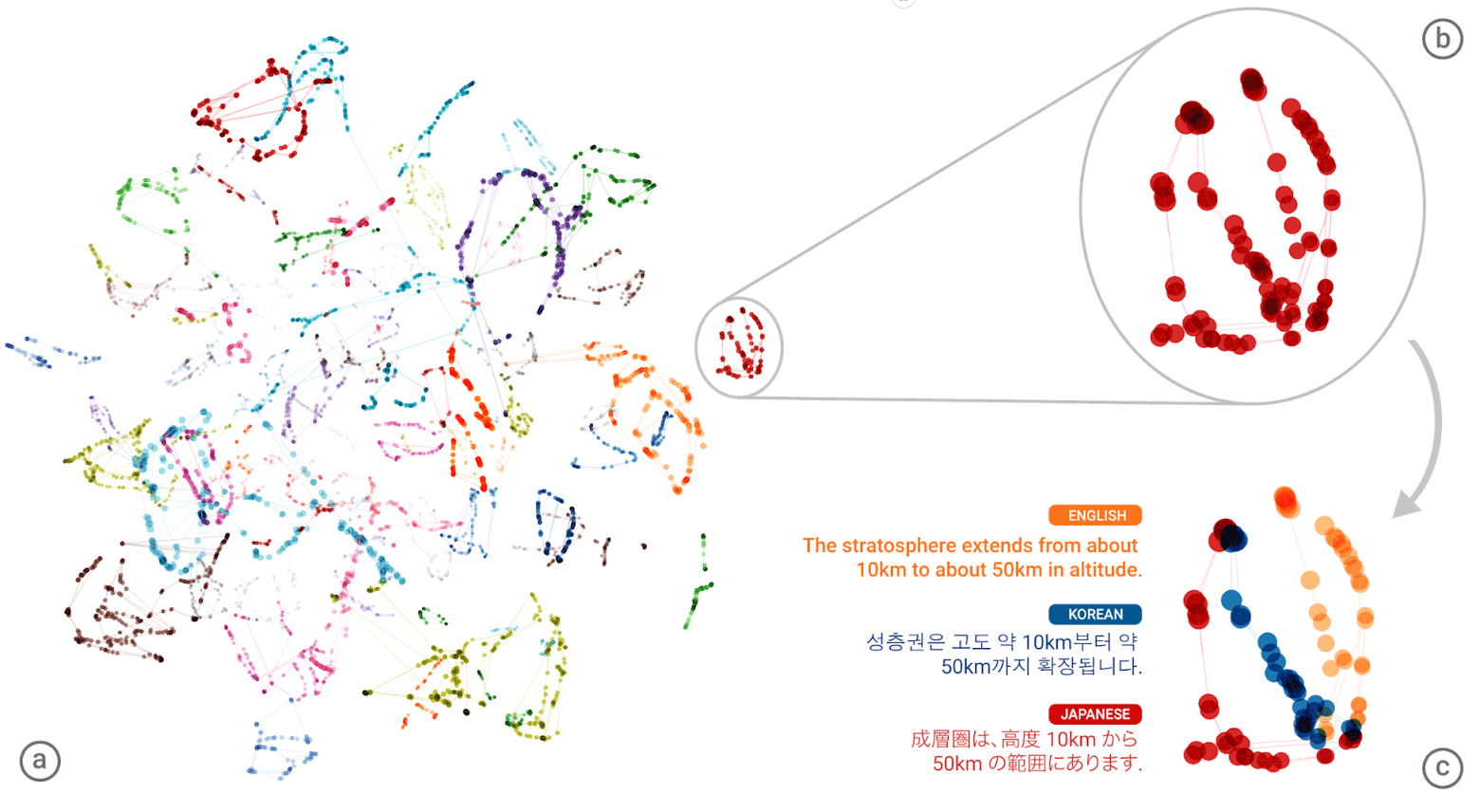 Google神经机器翻译(GNMT)神经网络的“通用语言”。 每个单词的含义簇在左侧插图中以不同的颜色显示,较低的含义是从不同的人类语言(英语,韩语和日语)获得的单词含义
Google神经机器翻译(GNMT)神经网络的“通用语言”。 每个单词的含义簇在左侧插图中以不同的颜色显示,较低的含义是从不同的人类语言(英语,韩语和日语)获得的单词含义为每种语言编写了一个巨大的“地图集”,然后系统尝试将一个这样的地图集覆盖在另一种地图集上-现在您已经准备好拥有某种并行文本语料库!
您可以比较两种建议的无老师学习架构的模式。
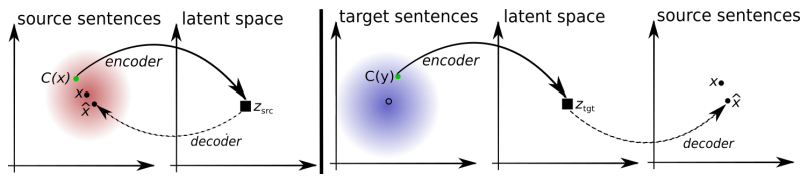
 拟议系统的体系结构。 对于L1语言中的每个句子,系统将学习两个步骤的交替:1) 去噪 ,优化使用通用编码器对句子的嘈杂版本进行编码的概率,并通过L1解码器对其进行重构; 2)逆向翻译,当句子以输出模式翻译(即由通用编码器编码并由L2解码器解码)时,然后可以使用通用编码器对该翻译后的句子进行编码并由L1解码器恢复原始句子的概率得到优化。 插图:Mikel Artetks等人的科学文章 。
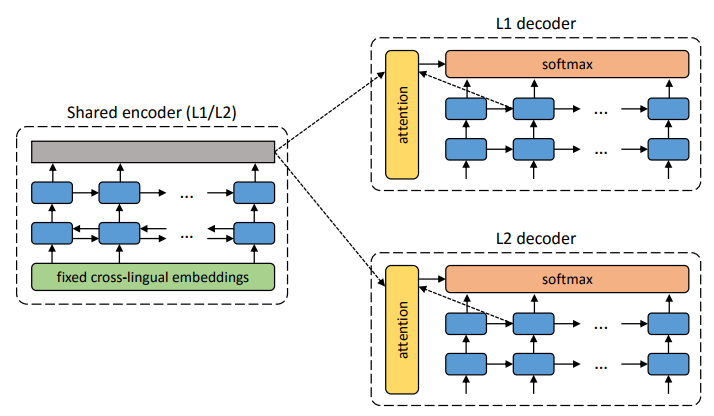
拟议系统的体系结构。 对于L1语言中的每个句子,系统将学习两个步骤的交替:1) 去噪 ,优化使用通用编码器对句子的嘈杂版本进行编码的概率,并通过L1解码器对其进行重构; 2)逆向翻译,当句子以输出模式翻译(即由通用编码器编码并由L2解码器解码)时,然后可以使用通用编码器对该翻译后的句子进行编码并由L1解码器恢复原始句子的概率得到优化。 插图:Mikel Artetks等人的科学文章 。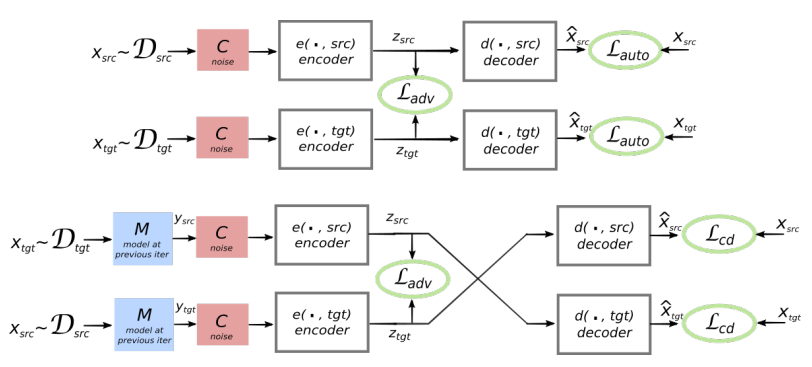 系统的拟议架构和学习目标(来自第二项科学工作)。 该体系结构是一个句子翻译模型,其中编码器和解码器均以两种语言工作,具体取决于输入语言的标识符,从而交换搜索表。 上方(自动编码):该模型正在学习如何在每个域中执行降噪。 下方(翻译):和以前一样,加上我们使用另一种语言编写的代码,使用模型在先前迭代中产生的翻译(蓝色矩形)作为输入。 绿色椭圆表示损失函数中的项。 插图:Guillaume Lampl等人的科学文章 。
系统的拟议架构和学习目标(来自第二项科学工作)。 该体系结构是一个句子翻译模型,其中编码器和解码器均以两种语言工作,具体取决于输入语言的标识符,从而交换搜索表。 上方(自动编码):该模型正在学习如何在每个域中执行降噪。 下方(翻译):和以前一样,加上我们使用另一种语言编写的代码,使用模型在先前迭代中产生的翻译(蓝色矩形)作为输入。 绿色椭圆表示损失函数中的项。 插图:Guillaume Lampl等人的科学文章 。这两篇科学论文都使用了明显相似的技术,只是稍有不同。 但是在两种情况下,翻译都是通过中间的“语言”或更佳的中间尺寸或空间进行的。 到目前为止,没有老师的神经网络的翻译质量还不是很高,但是作者说,如果您只需要老师的一点帮助,就很容易改进,只是出于实验纯正的目的。
请注意,第二项科学著作是由Facebook AI部门的研究人员发表的。
作品将提交给2018年国际学习代表大会。 这些文章尚未在科学出版社上发表。