2017年11月上旬,高通数据中心技术(QDT)完成了其新的发明-基于10纳米技术的处理器-Centriq 2400的工作。根据这项创新的创造者,该行业的未来还在等待什么? 获取服务器的好处是什么?为什么Centriq 2400如此独特? 阅读有关此内容的更多信息。
11月8日,QDT的新闻发布会在加利福尼亚州圣何塞举行,正式宣布了新处理器的交付日期。 高级副总裁兼首席执行官Anand Chandrasekher说:
今天的演讲是一项重要的成就,也是系统超过4年孜孜以求的设计,开发和支持的结晶...我们创造了世界上最先进的服务器处理器,该处理器提供了高性能和高能效水平,使我们的客户能够显着降低成本。
除了对其产品毫无保留的自豪感外,公司代表毫不害羞地宣称自己的Centriq 2400处理器显着优于竞争产品,例如Intel Xeon Platinum8180。根据他们的计算,每花费1美元(处理器的成本为1995美元),用户将获得性能提升。 4次 而当以1瓦特的功率重新计算性能时,则可提高45%。 但是,大胆的声明是,对新产品感兴趣的各个公司的许多代表非常高兴听到他们的声音。
Qualcomm Centriq 2400技术规格
CPU架构- 最多48个64位内核,峰值频率为2.6 GHz;
- Armv8兼容性
- 仅AArch64;
- Armv8 FP / SIMD;
- 扩展CRC和Armv8加密;
CPU快取:- 指令(指令)L1的64 Kb高速缓存和单周期缓存L0的24 Kb;
- 32 Kb L1数据缓存;
- 每2个内核512 KB的总L2缓存;
- 60 MB共享三级缓存;
- 过滤处理器间请求L2;
- 服务质量
其中,L(L1,L2,L3,L0)是电平,即 L0为零电平。技术:内存带宽:- 6个通道用于连接DDR4内存模块;
- 每个连接最高2667 MT / s;
- 128 GB / s-最大总带宽;
- 内置带宽压缩
内存容量:内存类型:- 具有8位ECC的64位DDR4连接;
- RDIMM和LRDIMM;
支持的接口:- 通用输入输出
- I²C;
- SPI
- 8频段SATA Gen 3;
- 32个PCIe Gen3,能够连接多达6个PCIe控制器;
除了上述特性外,值得注意的是,该处理器每个芯片上还有180亿个晶体管。 并且其所有内核均通过双向环形总线连接。 在最大负载下,Centriq 2400仅消耗120瓦。
新处理器的主要重点仍然是云解决方案。 根据公司代表的说法,Centriq 2400将使您能够创建具有高性能,高效率和可扩展性的服务器系统。
这肯定会吸引许多公司,因为云技术几乎是其活动的基础。 出席的演讲者包括:阿里巴巴,LinkedIn,Cloudflare,American Megatrends Inc.,Arm,Cadence Design Systems,Canonical,Chelsio Communications,Excelero,Hewlett Packard Enterprise,Illumina,MariaDB,Mellanox,Microsoft Azure,MongoDB,Netronome,Packet,Red Hat, ScyllaDB,6WIND,三星,Solarflare,Smartcore,SUSE,Synopsys,Uber,Xilinx。 该列表令人印象深刻,这表明对该产品的关注度有所提高。
目前,Qualcomm Centriq 2400处理器的普及率和普及率都只有增长。 自然,这将导致QDT竞争对手出现一些新的,类似的或什至更具生产力的产品。
但是,并非所有人都盲目地相信新产品的酷感。 如果那些相信对多个处理器进行测试和比较分析的人可以看到比Centriq 2400启动器更多的指示性结果。
Cloudflare对以下三个平台进行了比较分析:Grantley(Intel),Purley(Intel)和Centriq(Qualcomm)。
下面将提供这种分析的图表以及其作者
弗拉德·克拉斯诺夫 (
Vlad Krasnov)的结论。 (
此分析的原始内容在Cloudflare的博客上 )
公钥密码术
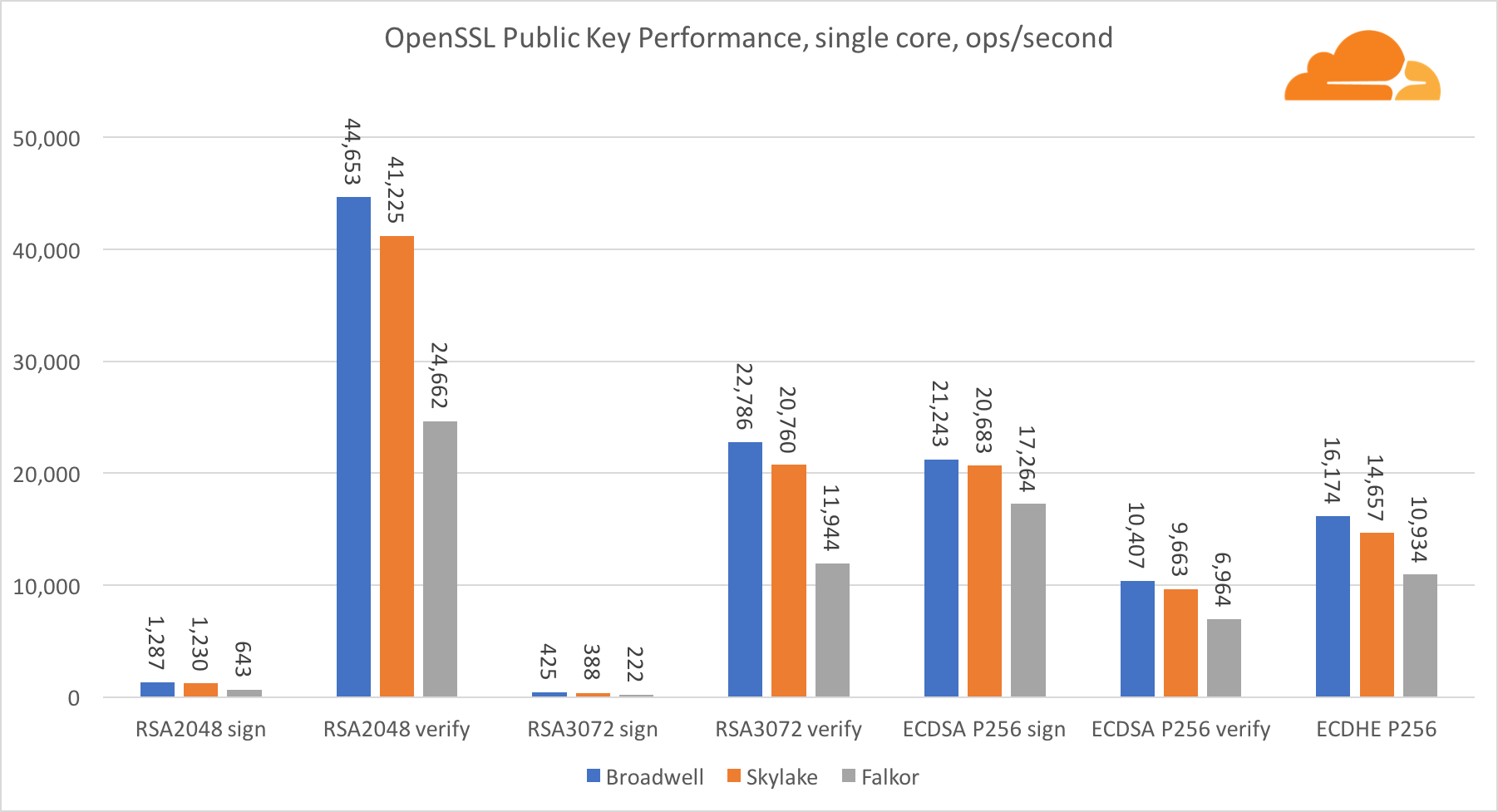
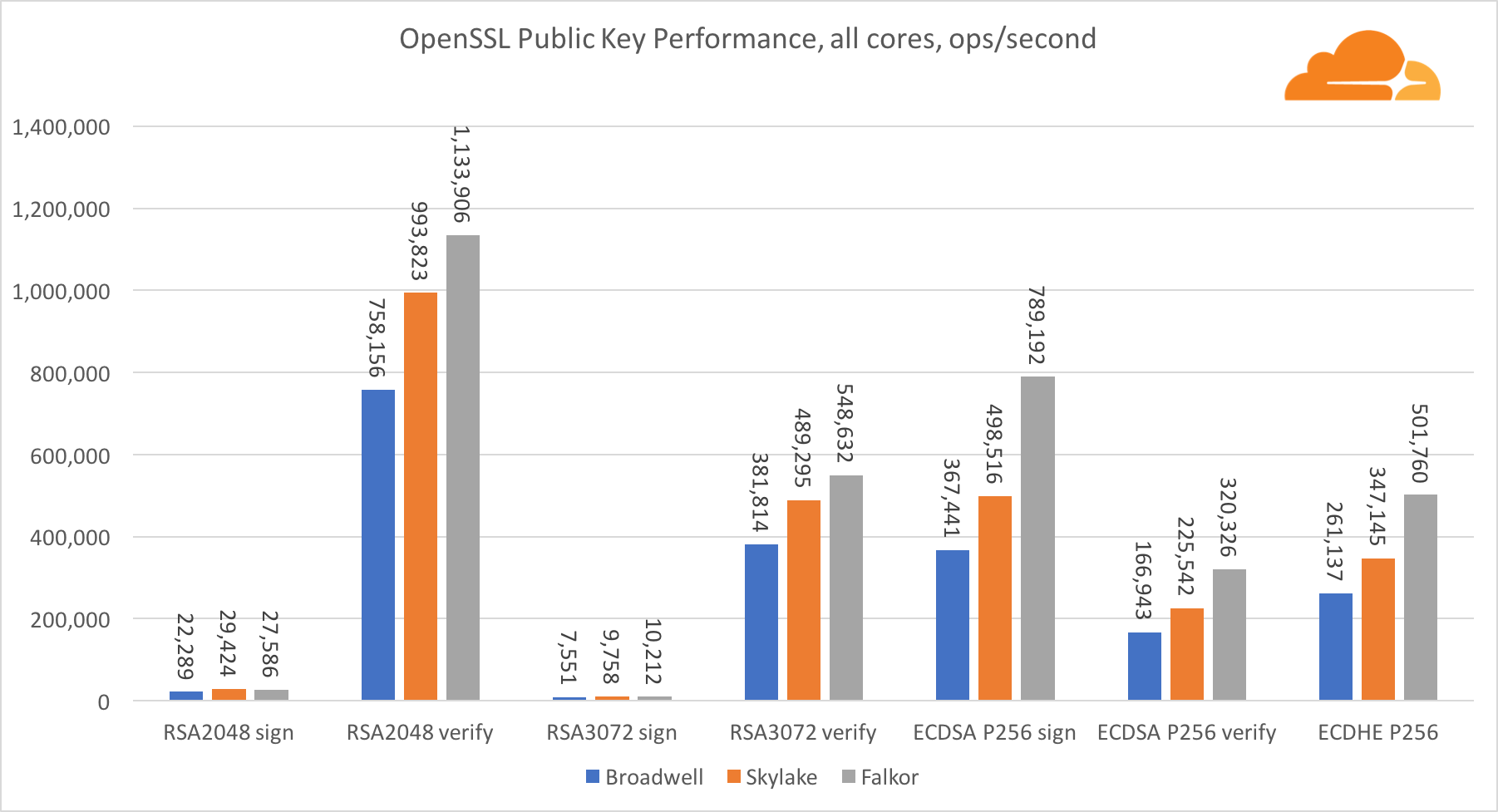
公钥加密是ALU(算术逻辑设备)的最纯粹的性能。 有趣但不奇怪的是,在一个基本基准中,Broadwell内核比Skylake快,而两者都比Falkor快。 这是因为Broadwell的工作频率更高,尽管就架构而言,它并不逊于Skylake。
福尔考在这项测试中不如其他人。 首先,turbo模式是在一项基本基准测试中开启的,这意味着Intel处理器的工作频率更高。 此外,英特尔在Broadwell推出了两个特殊指令以加速大批量处理:ADCX和ADOX。 它们每个周期执行两次独立的带进位加法运算,而ARM只能执行一次。 同样,ARMv8指令集没有用于执行64位乘法的单个命令;而是使用一对MUL和UMULH指令。
但是,在SoC级别,Falkor胜出。 就RSA2048而言,它比Skylake稍慢,这仅是因为RSA2048没有针对ARM的优化实现。 ECDSA的性能高得离谱。 单个Centriq芯片可以使用ECDSA满足世界上几乎所有公司的需求。
令人惊奇的是,尽管Skylake在测试中损失了一个内核,并且仅比Broadwell多出20%的内核,但它却超过了Broadwell 30%。 这可以通过更有效的Turbo模式和改进的超线程来解释。
对称密码学
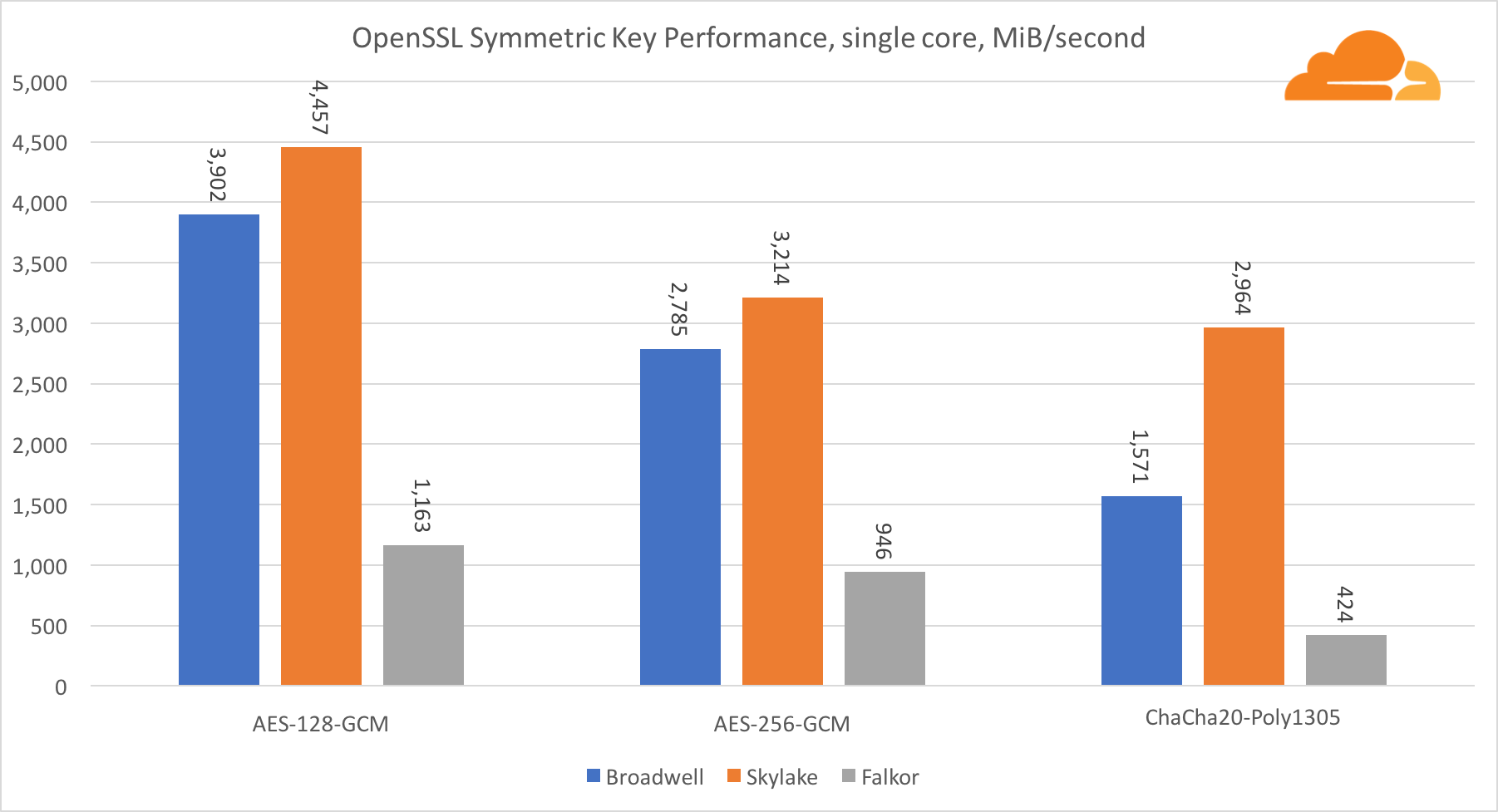
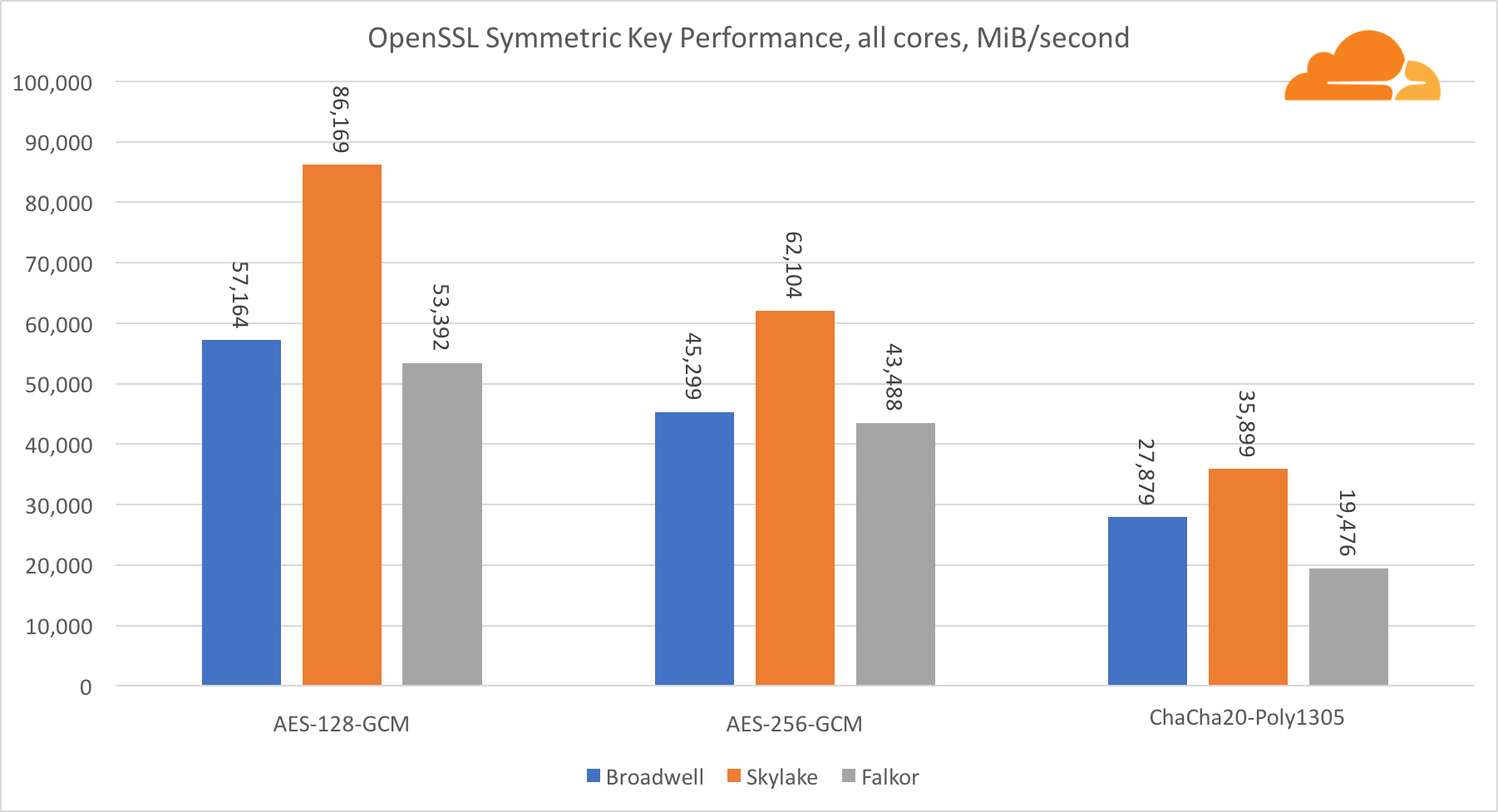
对称加密中英特尔内核的性能非常出色。
AES-GCM使用特殊硬件指令的组合来加速AES和CLMUL。 英特尔于2010年首次采用Westmere处理器引入了这些指令,并且每一代都提高了性能。 ARM最近推出了一组类似的指令,并将其64位指令集作为可选的补充。 幸运的是,我认识的每个设备供应商都已实施了它们。 高通很有可能在后代提高密码指令的性能。
ChaCha20-Poly1305是一种更通用的算法,其设计方式是为了更好地利用宽SIMD模块。 高通公司只有128位NEON SIMD,Broadwell有256位AVX2,而Skylake有512位AVX-512。 这就解释了为什么Skylake在以单个核心评估工作时仍然领先于如此优势。 同时,在所有内核的测试中,Skylake与其他内核的差距得以缩小,因为在执行AVX-512工作负载时,Skylake可以降低时钟频率。 在所有内核上运行AVX-512时,基本频率降低到1.4 GHz。 如果混合使用AVX-512和其他代码,请记住这一点。
关于对称密码学的结论是,即使Skylake处于领先地位,Broadwell和Falkor仍显示出非常好的结果,在实际情况下具有相当高的性能,因为事实是,RSA消耗的处理器时间比其他所有加密算法的总和还多。 。
压缩(压缩)
我想做的下一个测试是压缩。 有两个原因。 首先,这是一个重要的工作负载,因为压缩效果越好,功能差距越小,并且可以更快地将内容交付给客户端。 其次,这是一个非常苛刻的高频分支预测错误工作量。
显然,第一个测试将是流行的zlib库。 在Cloudflare,我们使用针对英特尔64位处理器进行了优化的库的改进版本,尽管该库主要是用C语言编写的,但它使用了某些特定于英特尔的内置功能。 将此优化版本与原始zlib进行比较将是不公平的。 但是不用担心,我花了些力气,我使用NEON和CRC32属性对库进行了修改,使其可以在ARMv8架构上运行。 而且,对于某些文件,其速度是原始速度的2倍。
第二项测试是使用C语言编写的新brotli库,该库允许在所有平台上使用相同的条件。
所有测试均在内存中的HTML blog.cloudflare.com上进行,类似于NGINX执行流压缩的方式。 除非HTML文件的特定版本为29329字节,否则这是一个很好的指示,因为它对应于我们压缩的大多数文件的大小。 并行压缩测试是同时对多个文件进行并行压缩,单次压缩是将一个文件压缩为多个流,类似于NGINX的工作方式。
gzip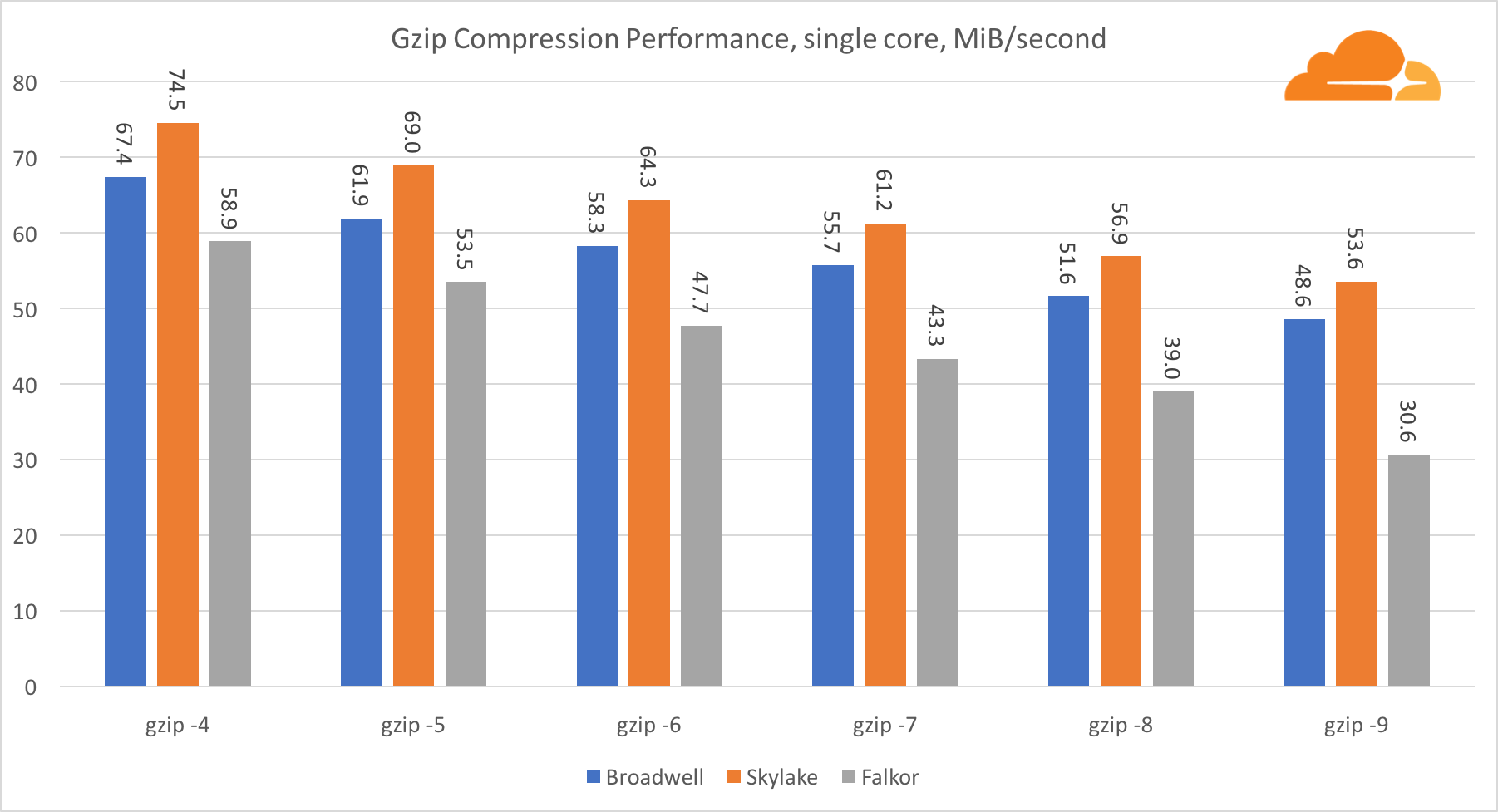
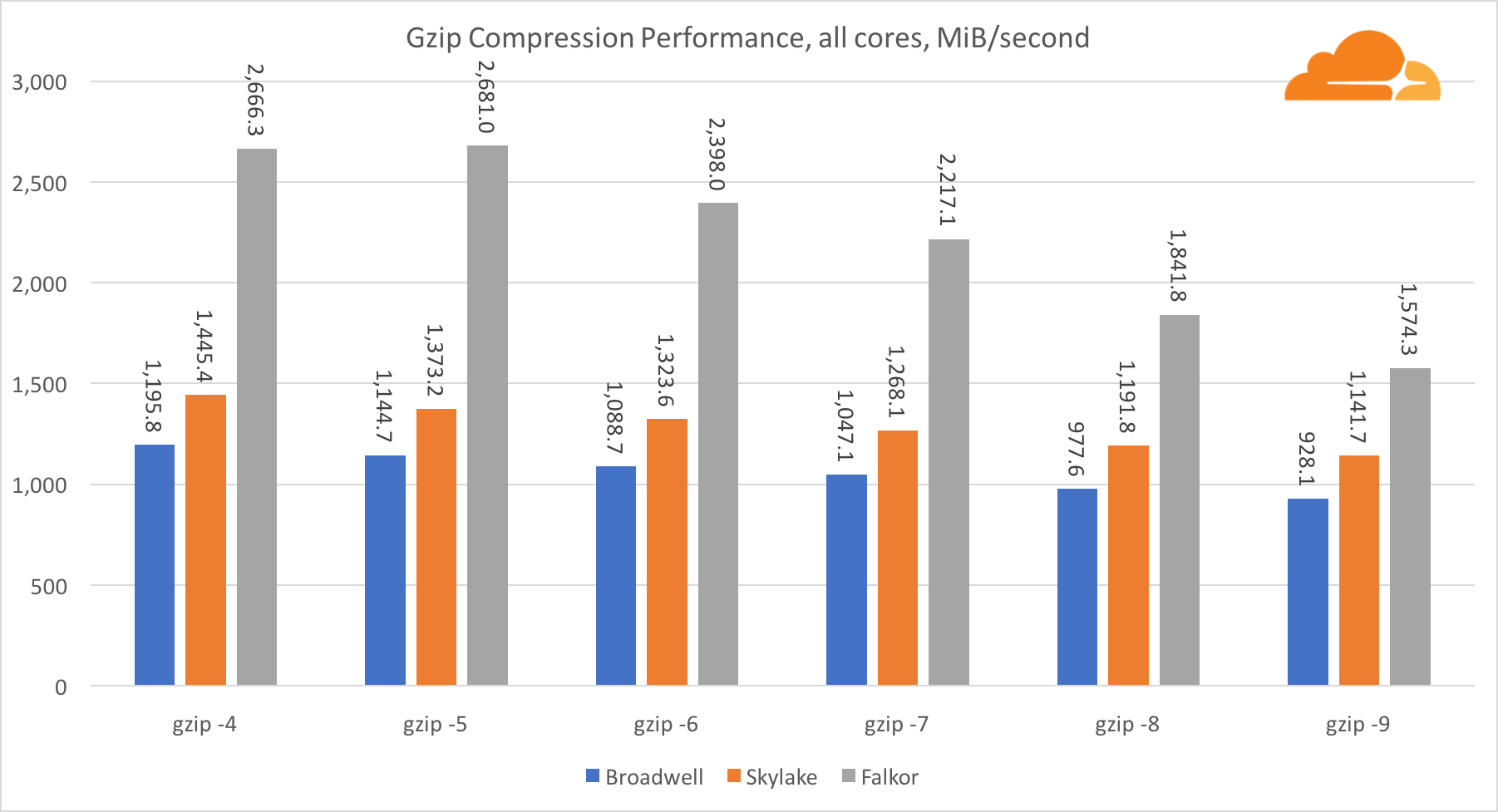
在单核级别使用gzip,Skylake无疑会获胜。 Skylake的频率比Broadwell的频率低,这得益于较低的分支预测错误风险。 Falkor核心并不落后。 在系统级别,Falkor在具有更多内核的情况下性能要好得多。 请注意,gzip如何在多个内核之间很好地扩展。
布罗特利将brotli放在一个核心上,情况与前一个类似。 Skylake是最快的,但Falkor紧随其后。 在标准9上,Falkor甚至更快。 Standard 4 Brotli与gzip 5级非常相似,而实际压缩仍然更好(8010B与8187B)。
在多个内核上进行压缩时,情况变得有些混乱。 对于第4、5和6级,brotli缩放很好。 在第7级和第8级,它开始在内核上有效地下降,在第9级下降到最低点,在这里,我们得到的所有内核的生产率是第一个内核的三倍。
我认为,这是由于在每个级别上,brotli开始消耗更多的内存并导致缓存崩溃。 指标已经开始在10和11级恢复。
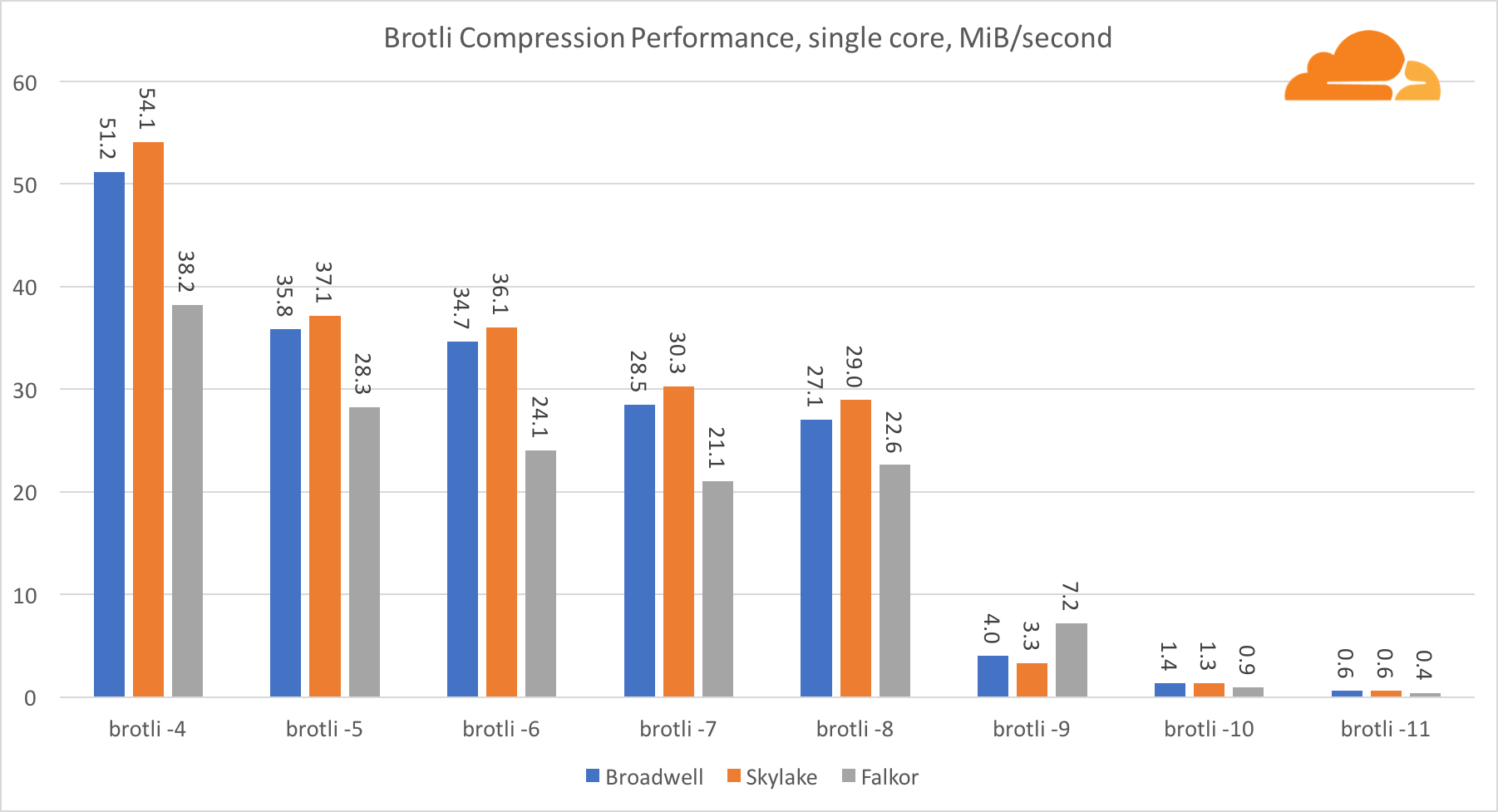
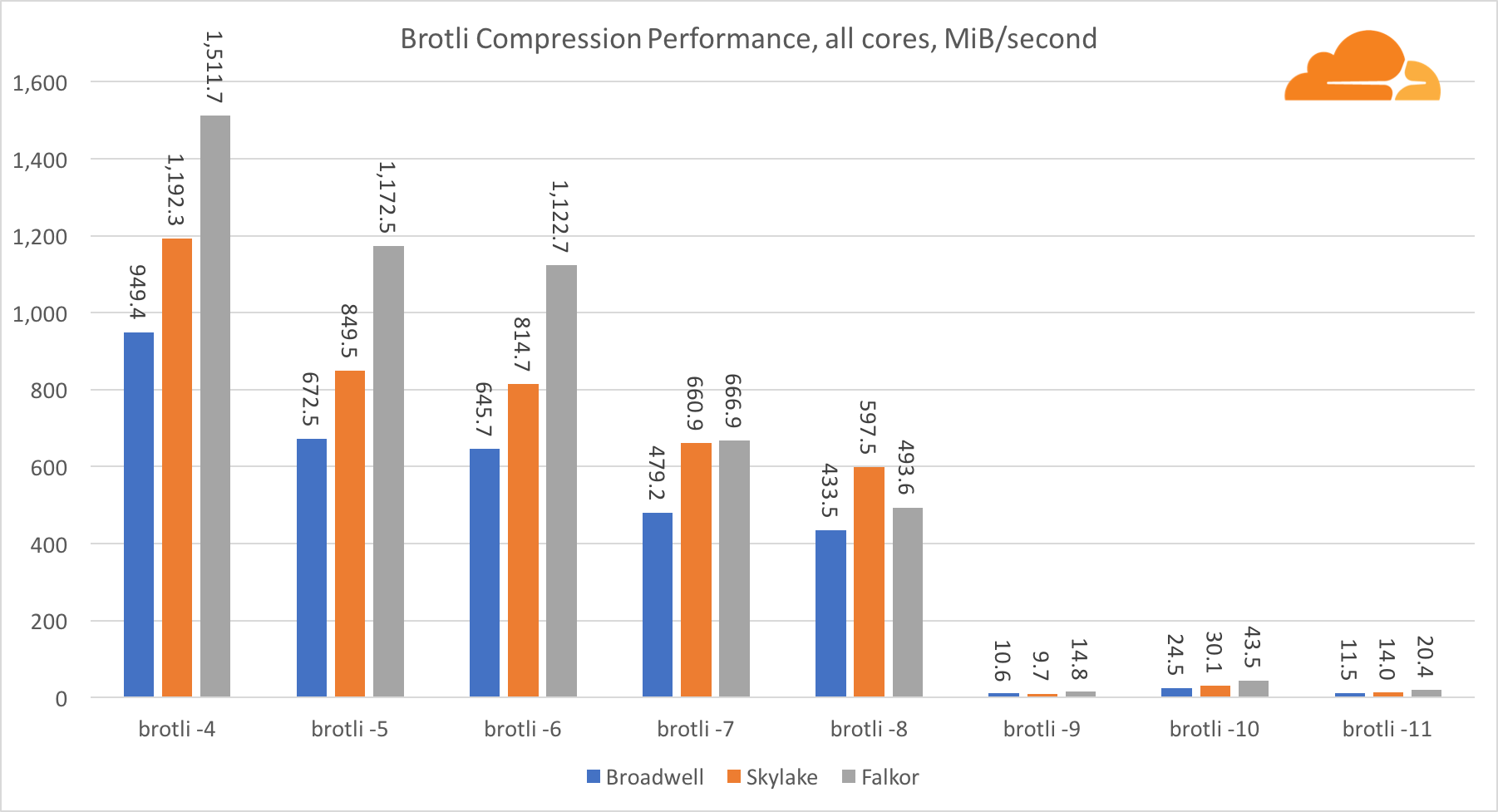
结论是,由于动态压缩不会超过7级,因此Falkor获胜。
高朗
Golang是Cloudflare的另一种非常重要的语言。 它也是最早支持ARMv8的语言之一,因此可以期待良好的性能。 我使用了一些内置测试,但针对多个goroutine对其进行了修改。
去加密我想从加密性能测试开始。 感谢OpenSSL,我们拥有出色的源数据,看到Go库的出色表现将非常有趣。
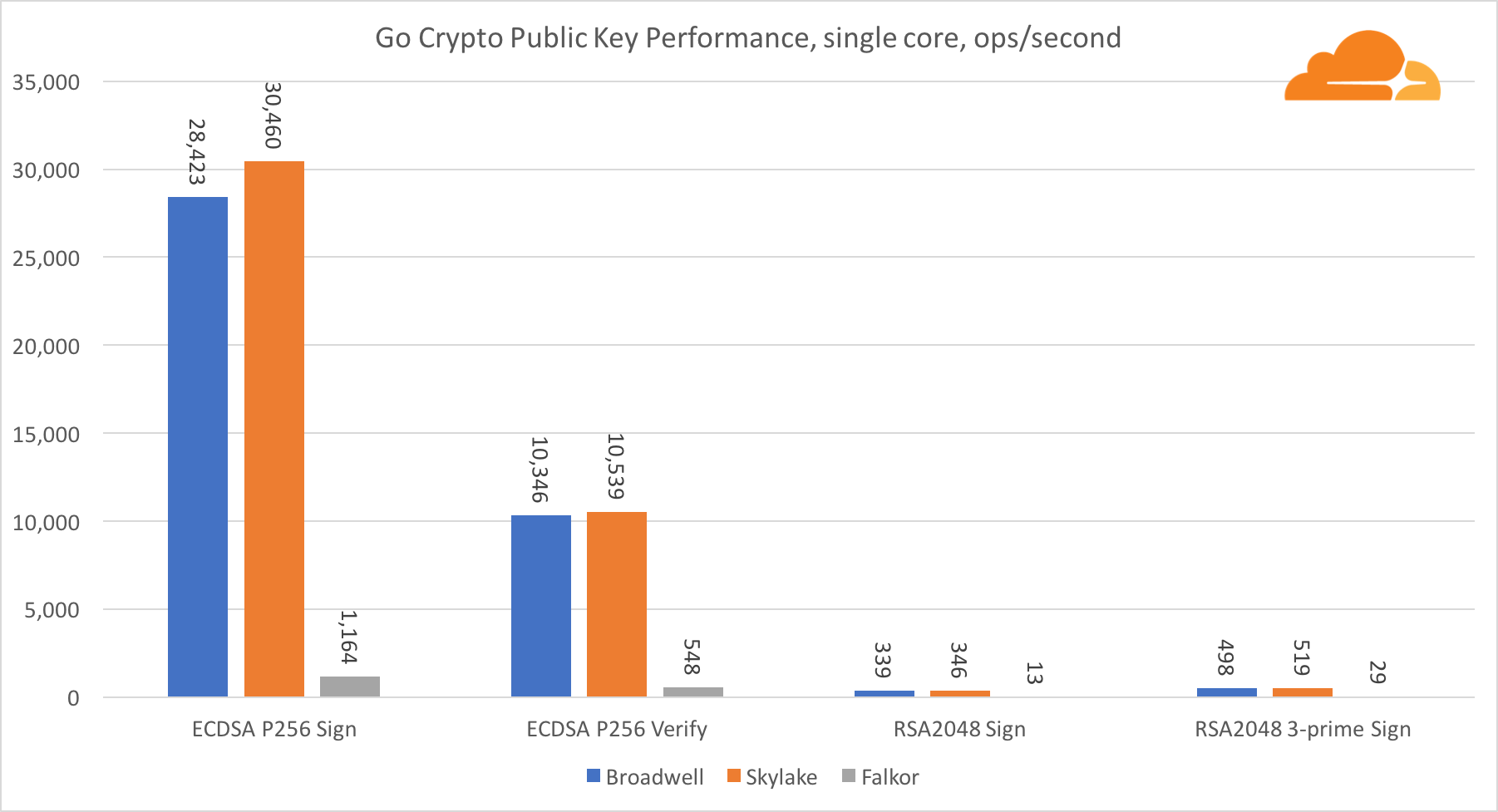
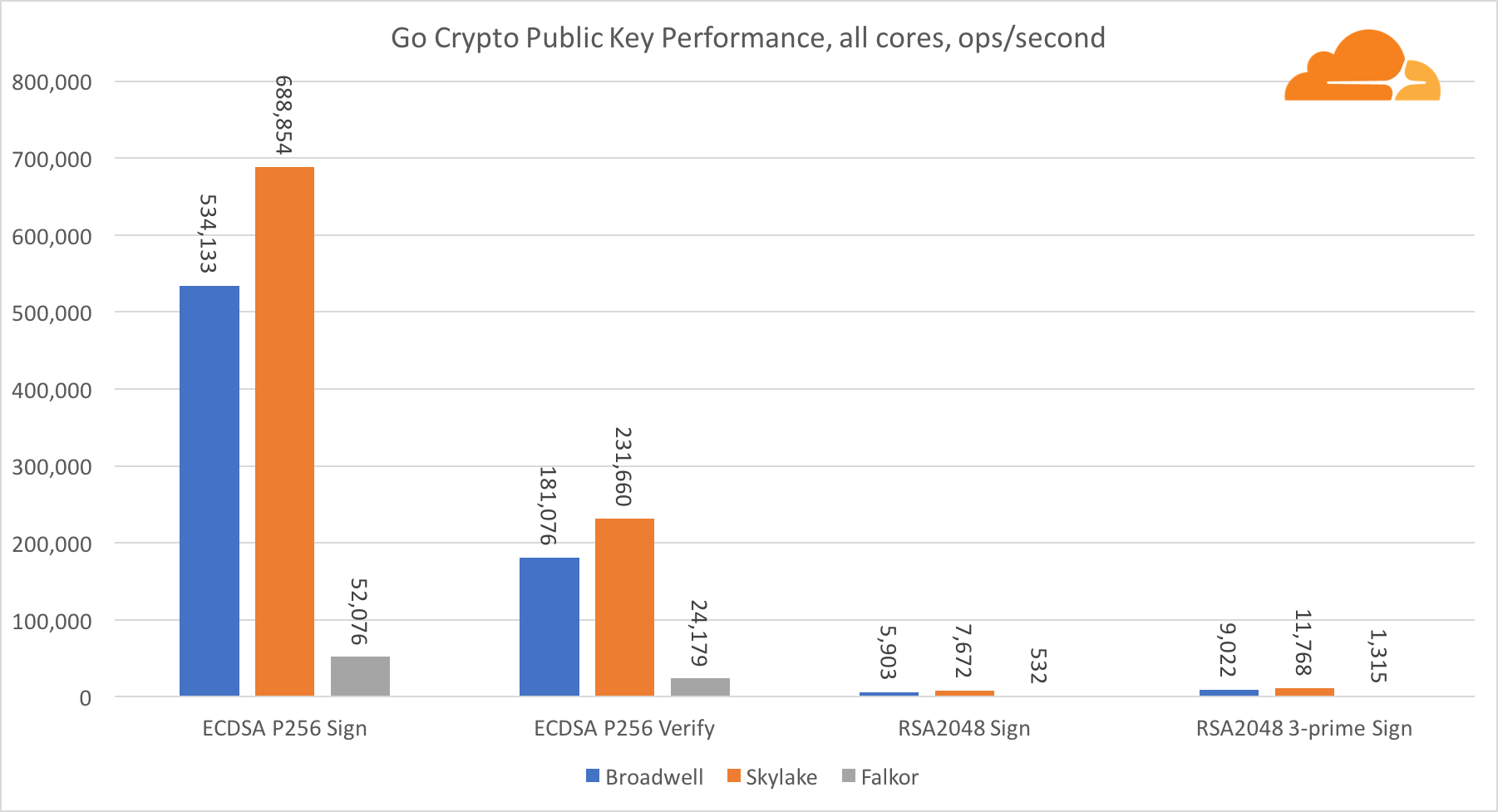
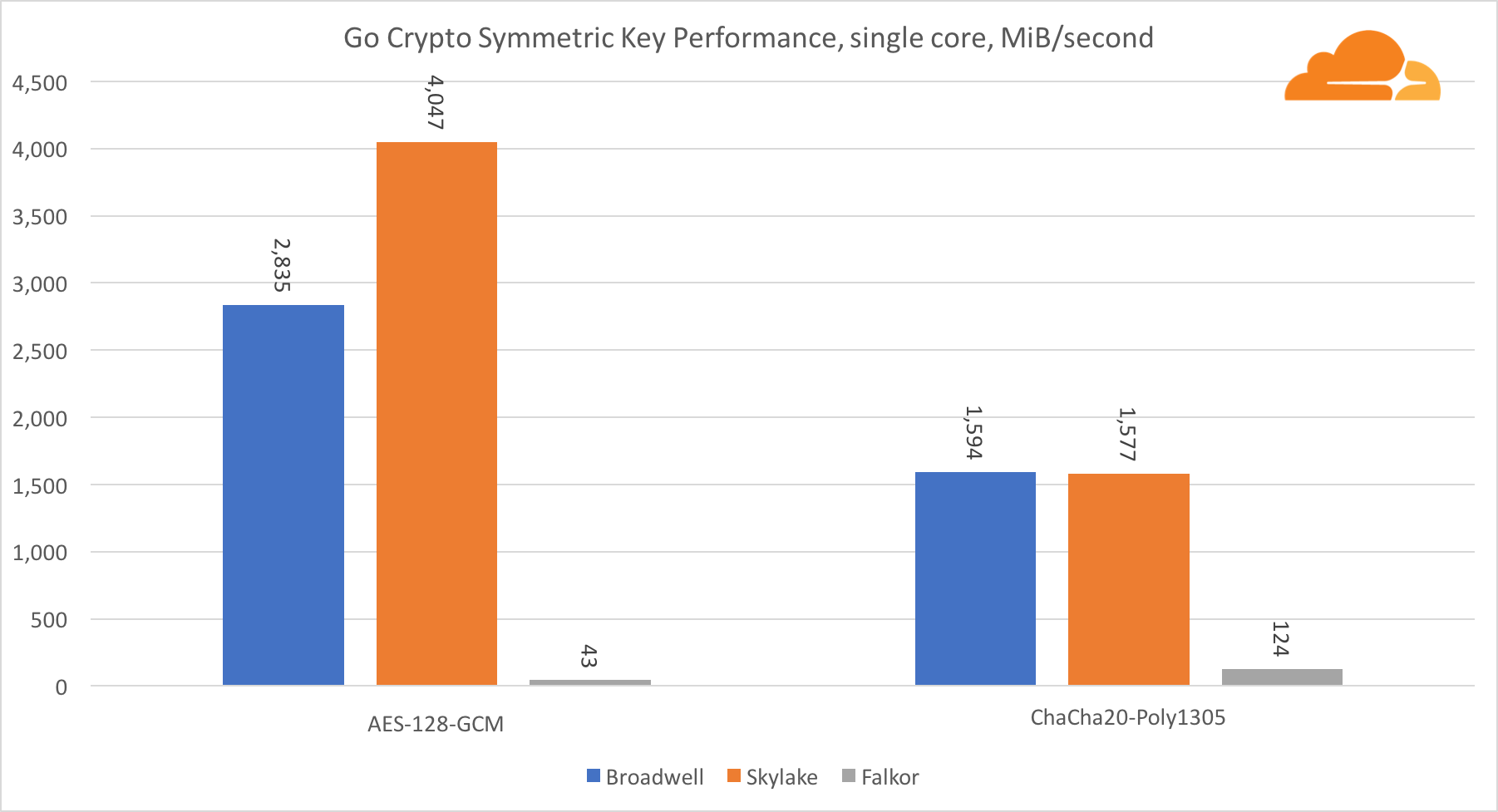
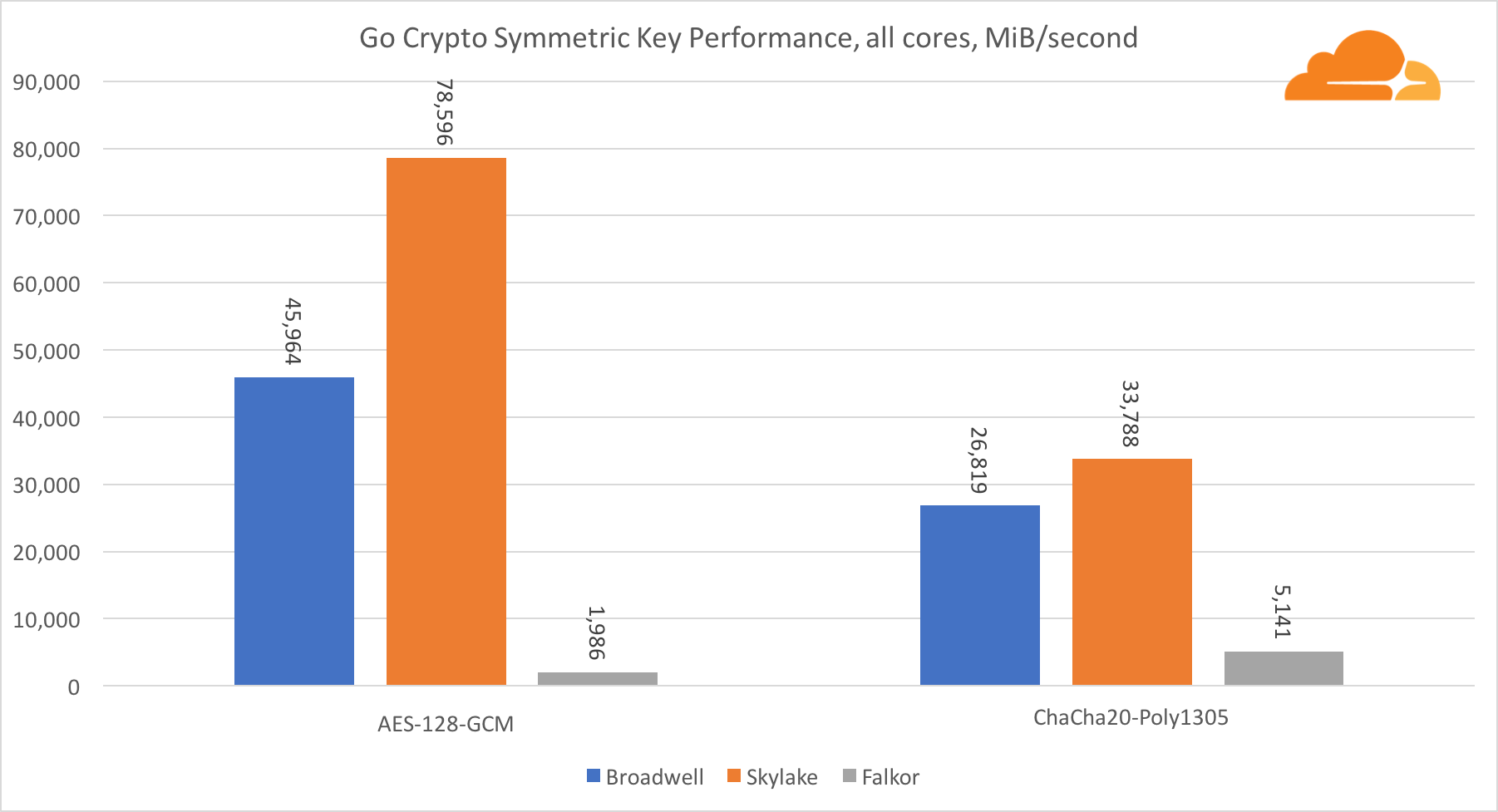
关于Go加密,ARM和Intel甚至不在同一重量级别。 Go在Intel上针对ECDSA,AES-GCM和Chacha20-Poly1305具有高度优化的汇编代码。 RSA计算中还使用了优化的数学函数。 ARMv8没有所有这些,这使其处于非常不利的位置。
不过,可以用相对较少的努力来缩小差距,并且我们知道,通过适当的优化,性能可以与OpenSSL媲美。 即使很小的更改(例如在程序集中实现addMulVVW功能),也会导致RSA性能提高十倍以上,使Falkor(得分为8009)高于Broadwell和Skylake。
值得一提的是,在Skylake上,使用AVX2的Go Chacha20-Poly1305代码的工作方式与OpenSSL AVX512代码大致相同。 同样,这是由于AVX2在更高的时钟频率下工作。
转到gzip现在,让我们看一下gzip的Go性能。 对于很好的优化代码,还有很好的指南,我们可以将其与Go进行比较。 对于gzip库,没有针对Intel的特定优化。
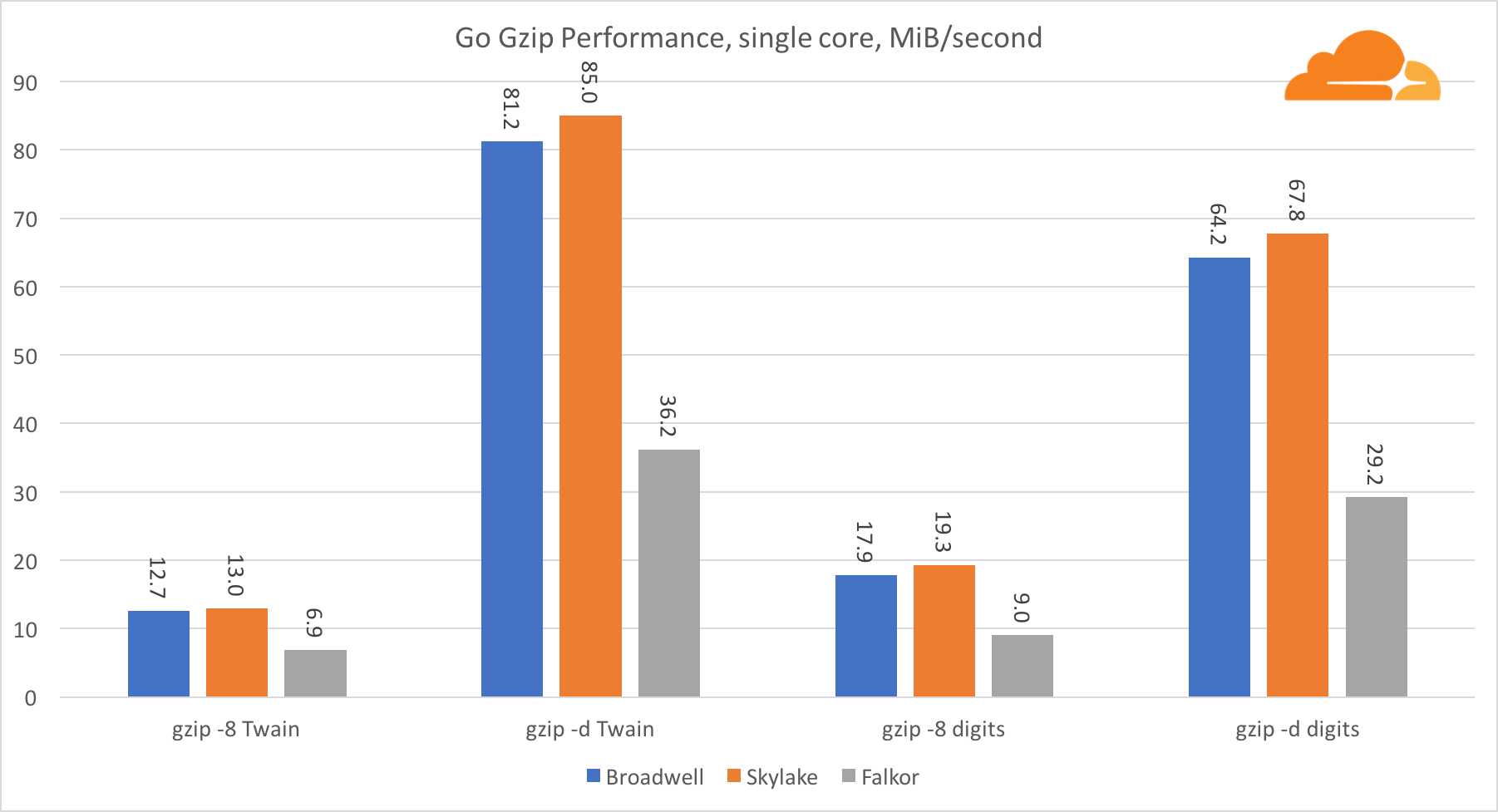

Gzip性能相当不错。 单核Falkor的性能大大落后于两个Intel处理器,但在系统级别,他设法击败了Broadwell并位于Skylake以下。 因为我们已经知道C运行时Falkor优于其他两个处理器,但这仅意味着一件事-与gcc相比,ARMv8的Go后端仍未完成。
去正则表达式正则表达式由于其性能也非常重要,因此广泛用于各种任务。 我对32 kb流进行了内置测试。
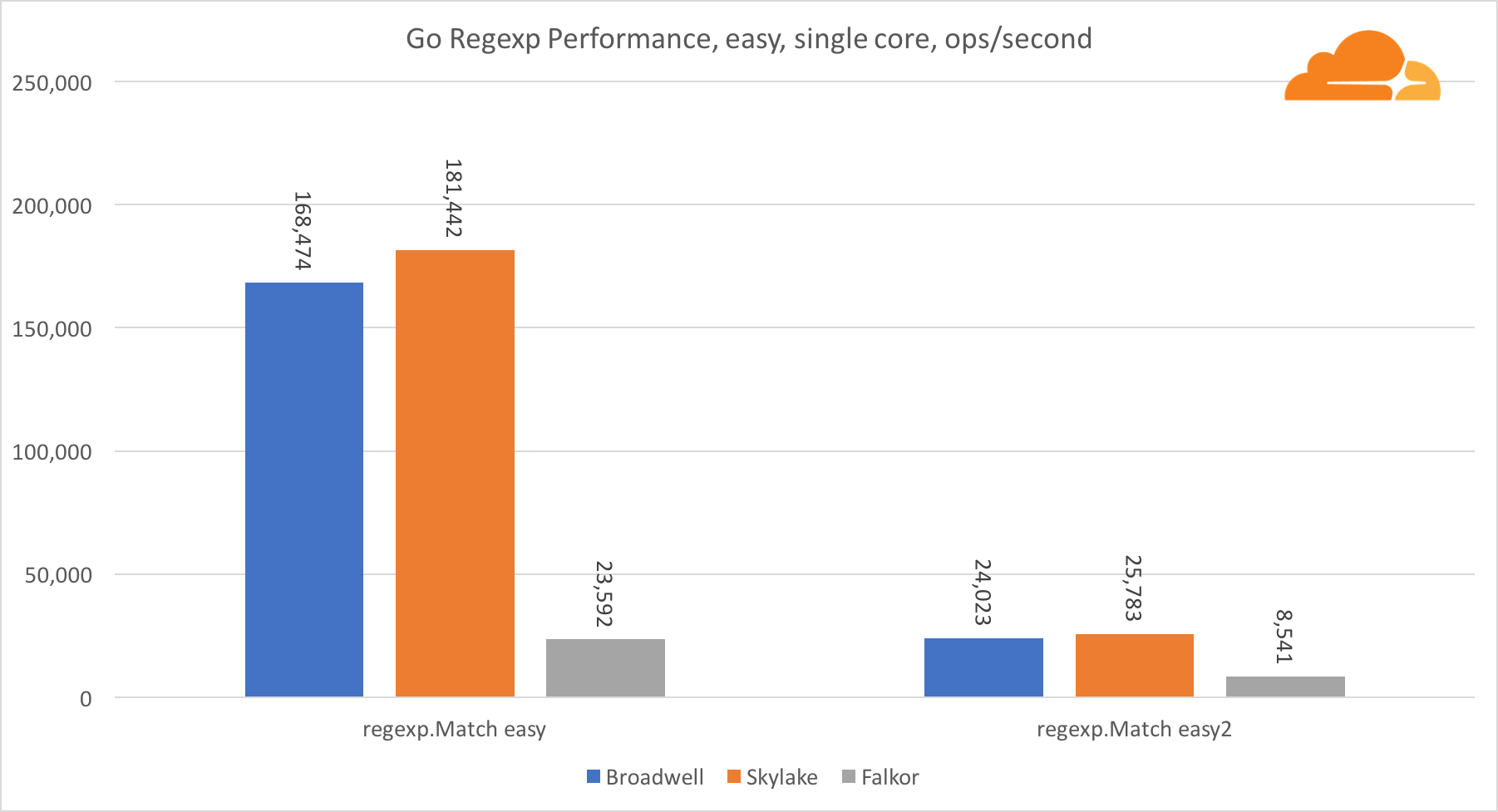
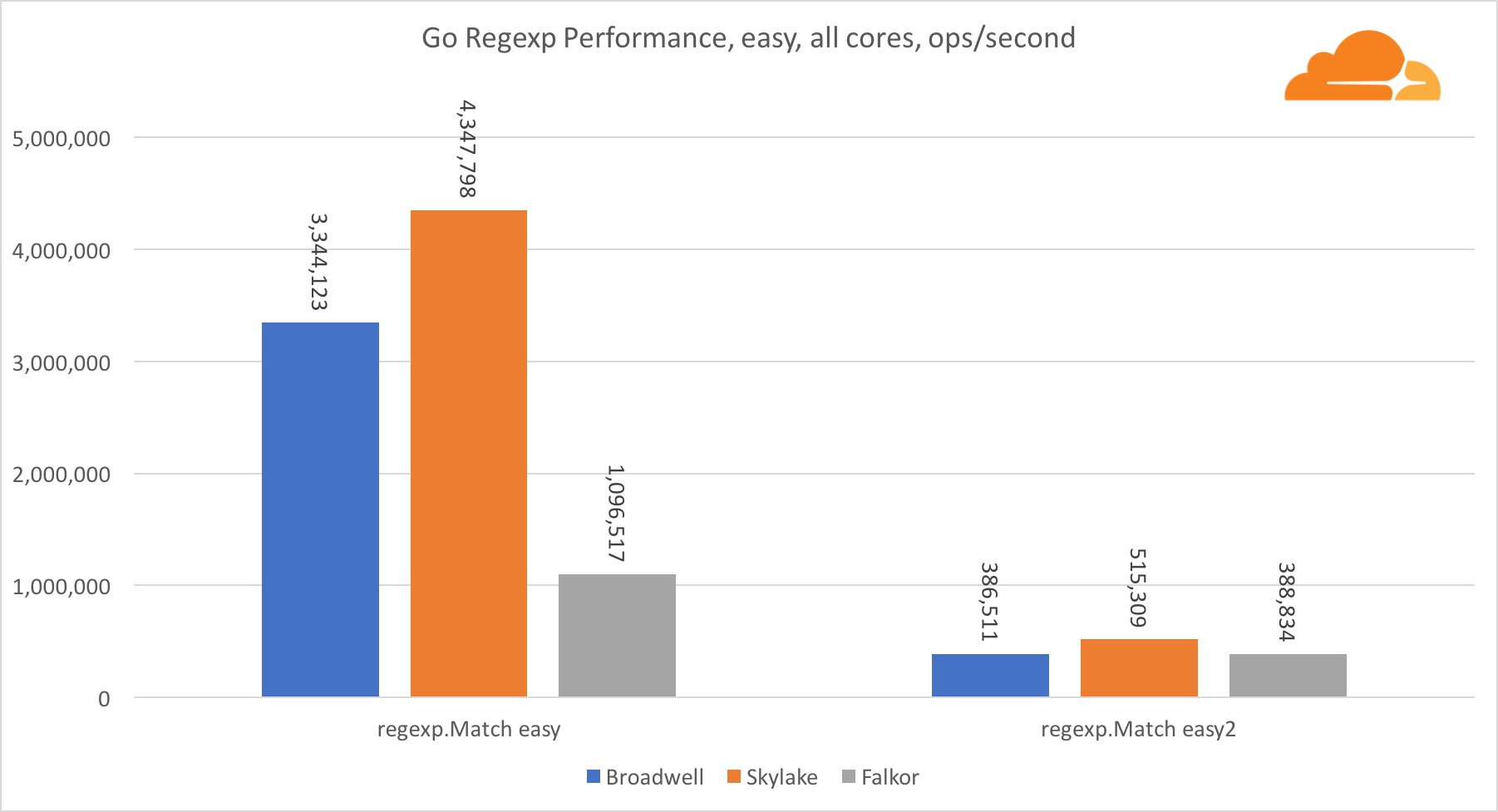
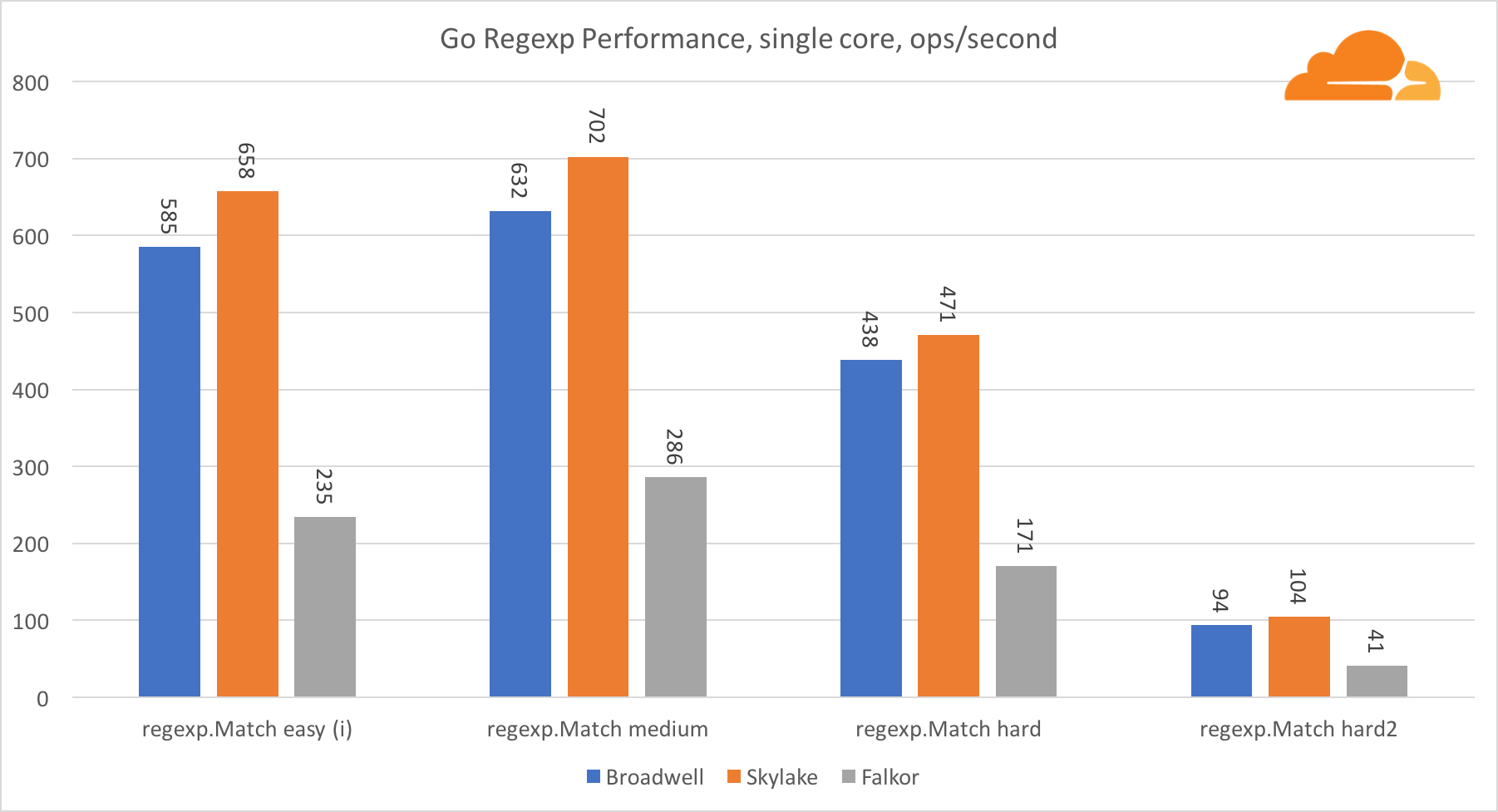
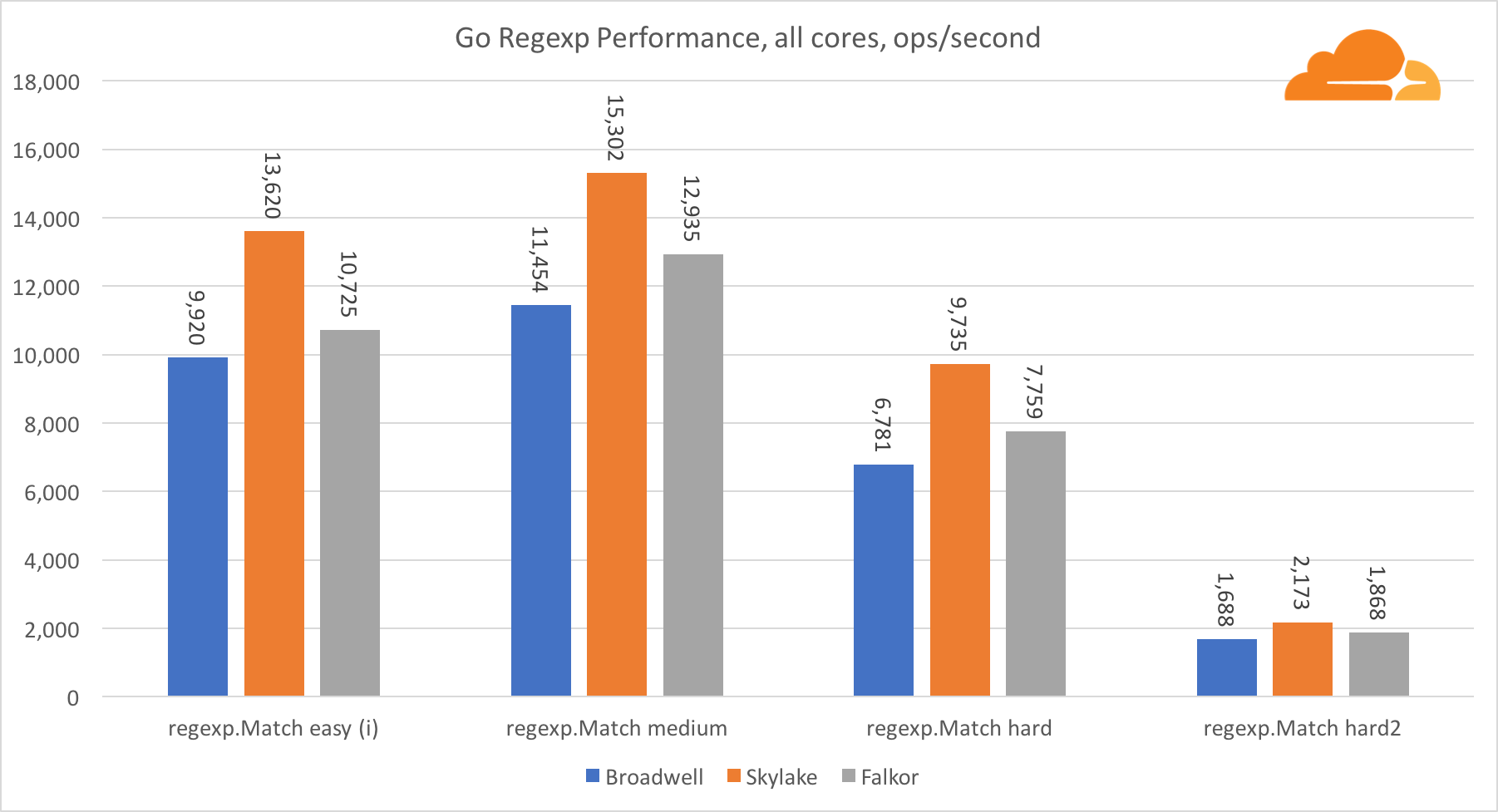
在Falkor上,Go regexp的性能不是很好。 由于拥有大量的内核,他在中等和复杂测试中排名第二,但是,Skylake的速度要快得多。
仔细查看该过程可以发现,bytes.IndexByte函数花费了大量时间。 该函数具有针对amd64(runtime.indexbytebody)的汇编程序实现,但主要实现针对Go。 在轻量级测试中,regexp在此功能上花费了更多时间,这解释了更大的差距。
去弦Web服务器的另一个重要库是Go字符串。 我只测试了主要的Replacer类。
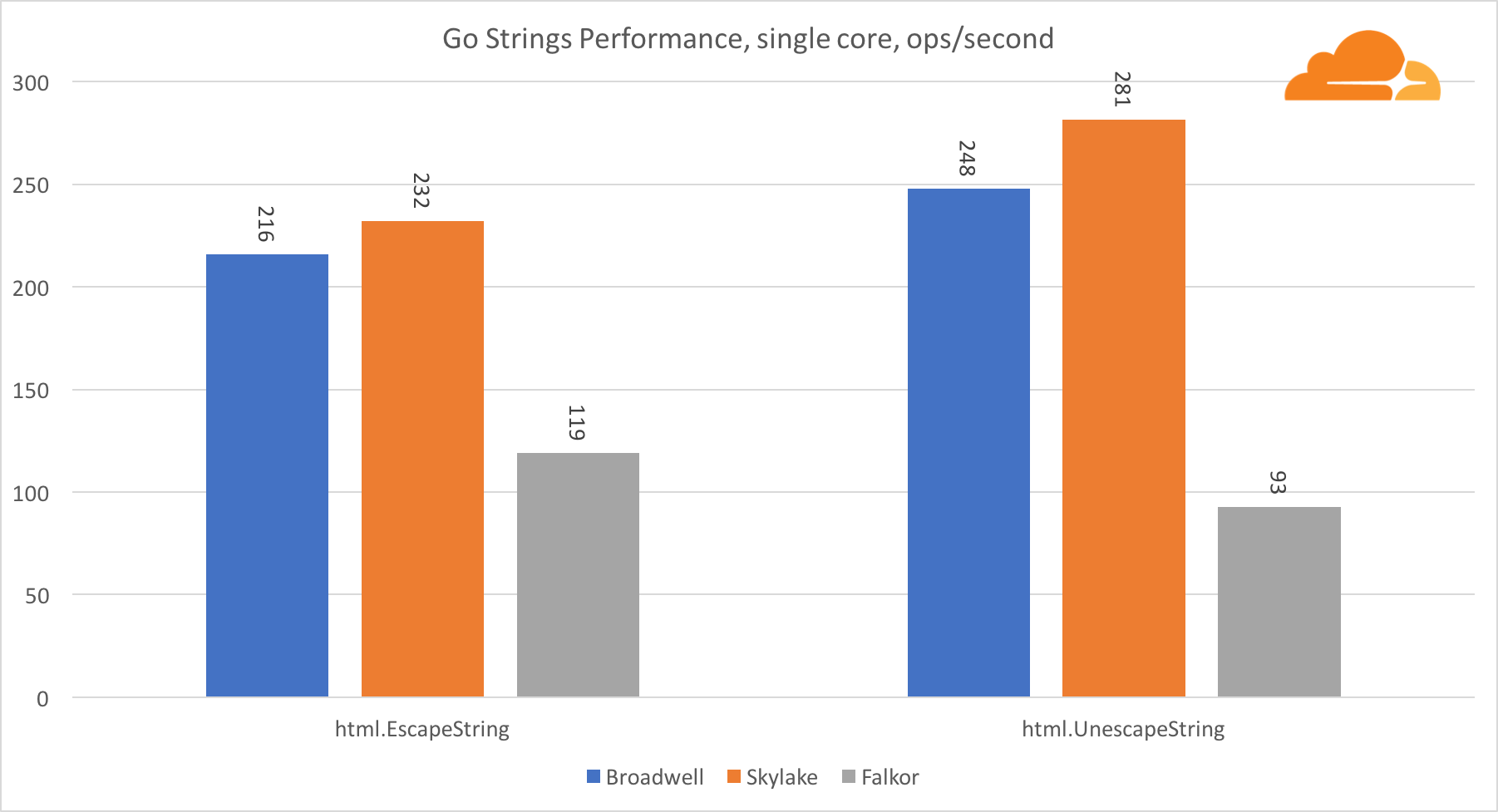
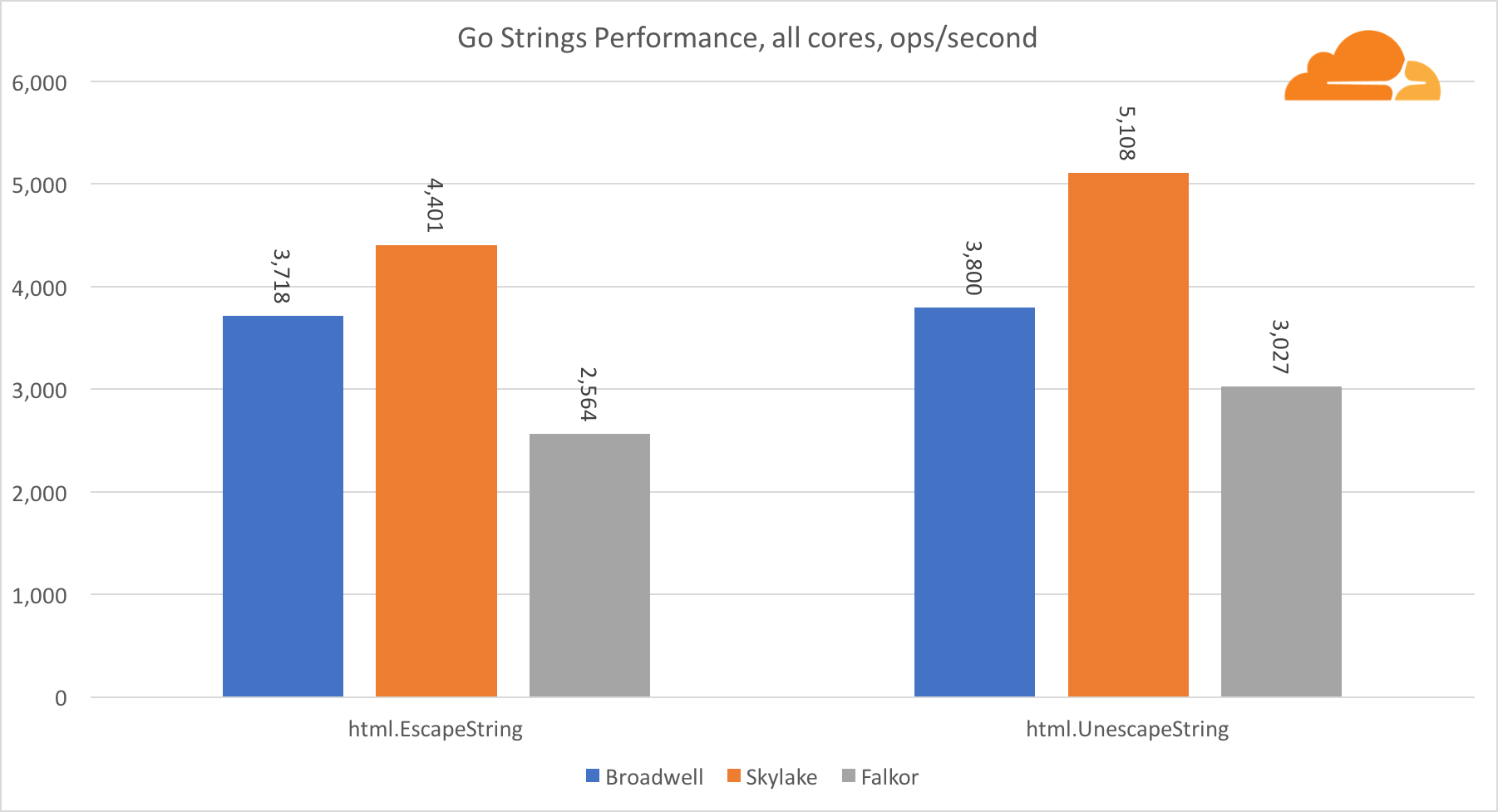
在这次测试中,福尔柯尔再次落后,甚至落后于Broadwell。 仔细观察可以发现在runtime.memmove函数中的停留时间很长。 你知道吗 对于使用AVX2的amd64,她有一个经过优化的汇编代码,但是只有一次复制8个字节的最简单的汇编器。 通过更改此代码中的3行并使用LDP / STP指令(成对加载/成对存储),您可以一次复制16个字节,从而将内存性能提高30%,从而将EscapeString和UnescapeString的速度提高20%。 这只是冰山一角。
得出结论对aarch64的Go支持非常令人失望。 我很高兴地宣布,所有内容都可以完美编译和工作,但是从性能方面来说可能会更好。 一种印象是,大多数工作都花在了编译器后端,而该库几乎未受影响。 有许多低级优化,例如我的addMulVVW修复花费了20分钟。 高通公司和其他ARMv8供应商打算花费大量技术资源来纠正这种情况,但实际上任何人都可以为Go做出贡献。 因此,如果您想在历史上留下印记,现在是时候了。
路易吉特
Lua是将Cloudflare粘合在一起的粘合剂。
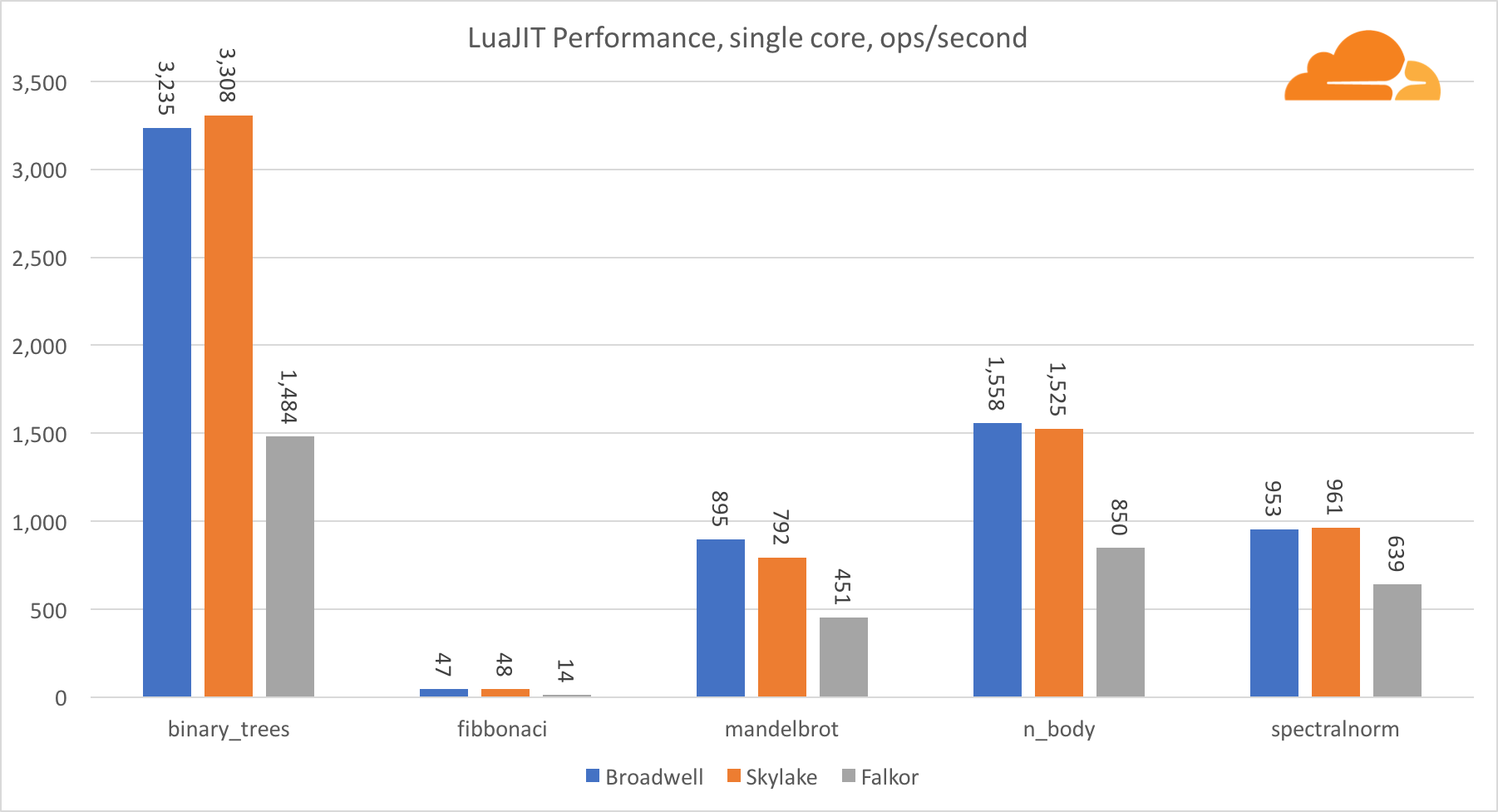
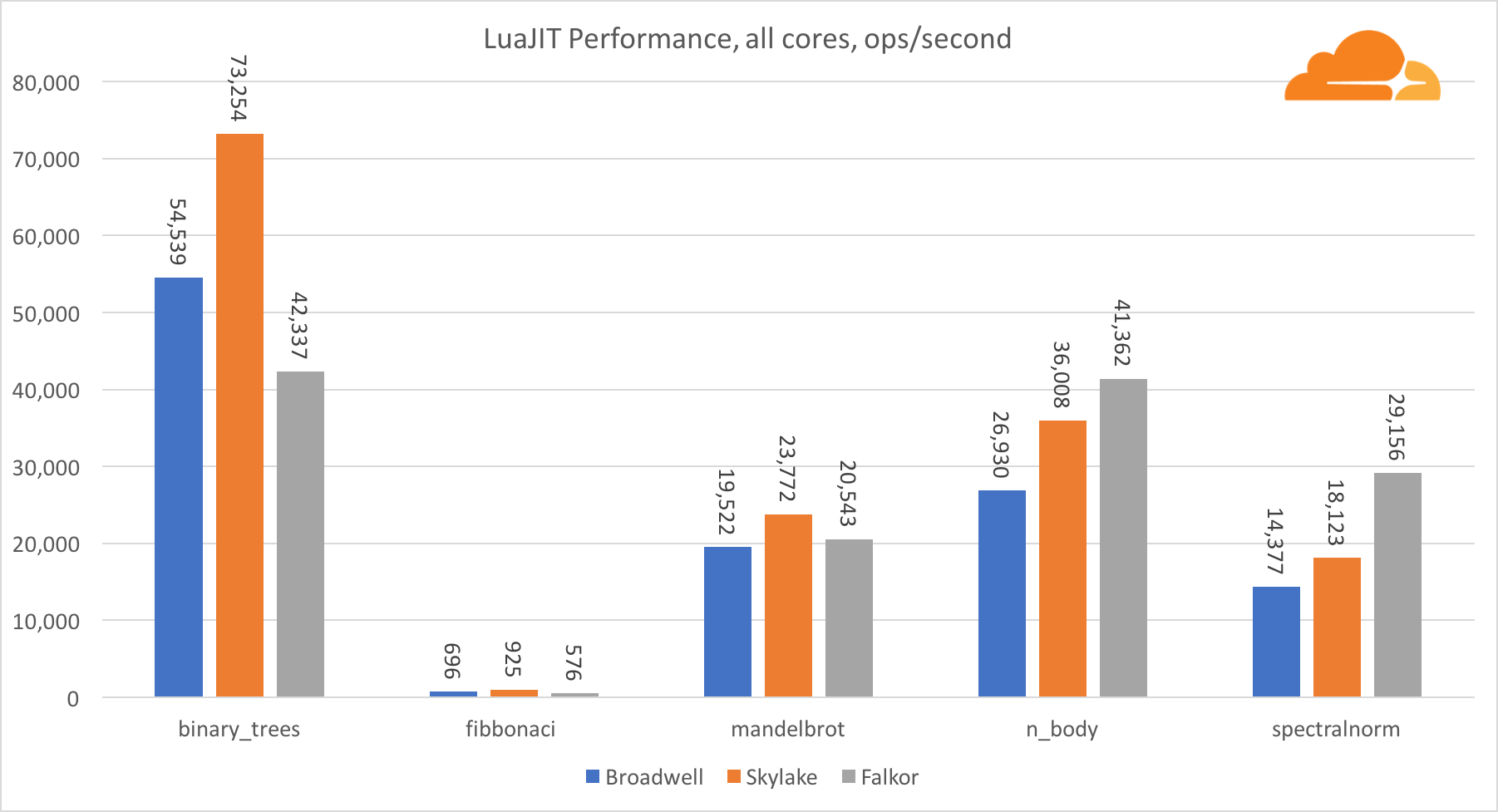
除了binary_trees测试之外,ARM上的LuaJIT性能非常有竞争力。 他赢得了两项测试,第三项与竞争对手并驾齐驱。
值得注意的是,binary_trees测试非常重要,因为它涉及许多内存分配和垃圾回收周期。 将来需要更细致的考虑。
Nginx的
作为NGINX的工作负载,我决定创建一个类似于实际服务器的工作负载。
我设置了一个服务器,该服务器使用ECDHE-ECDSA-AES128-GCM-SHA256密码套件在https之上提供gzip测试中使用的HTML文件。
添加时间戳时,它还使用LuaJIT重定向传入的请求,从HTML文件中删除所有换行符和多余的空格。 然后使用brotli 5压缩HTML。
每个服务器都配置为可与虚拟处理器一样多的用户使用。 Broadwell为40,Skylake为48,Falkor为46。
作为此测试的客户端,我使用了在3台Broadwell服务器上运行的hey程序。
在测试的同时,我们从每个服务器的相应BMC块中获取了功率读数。
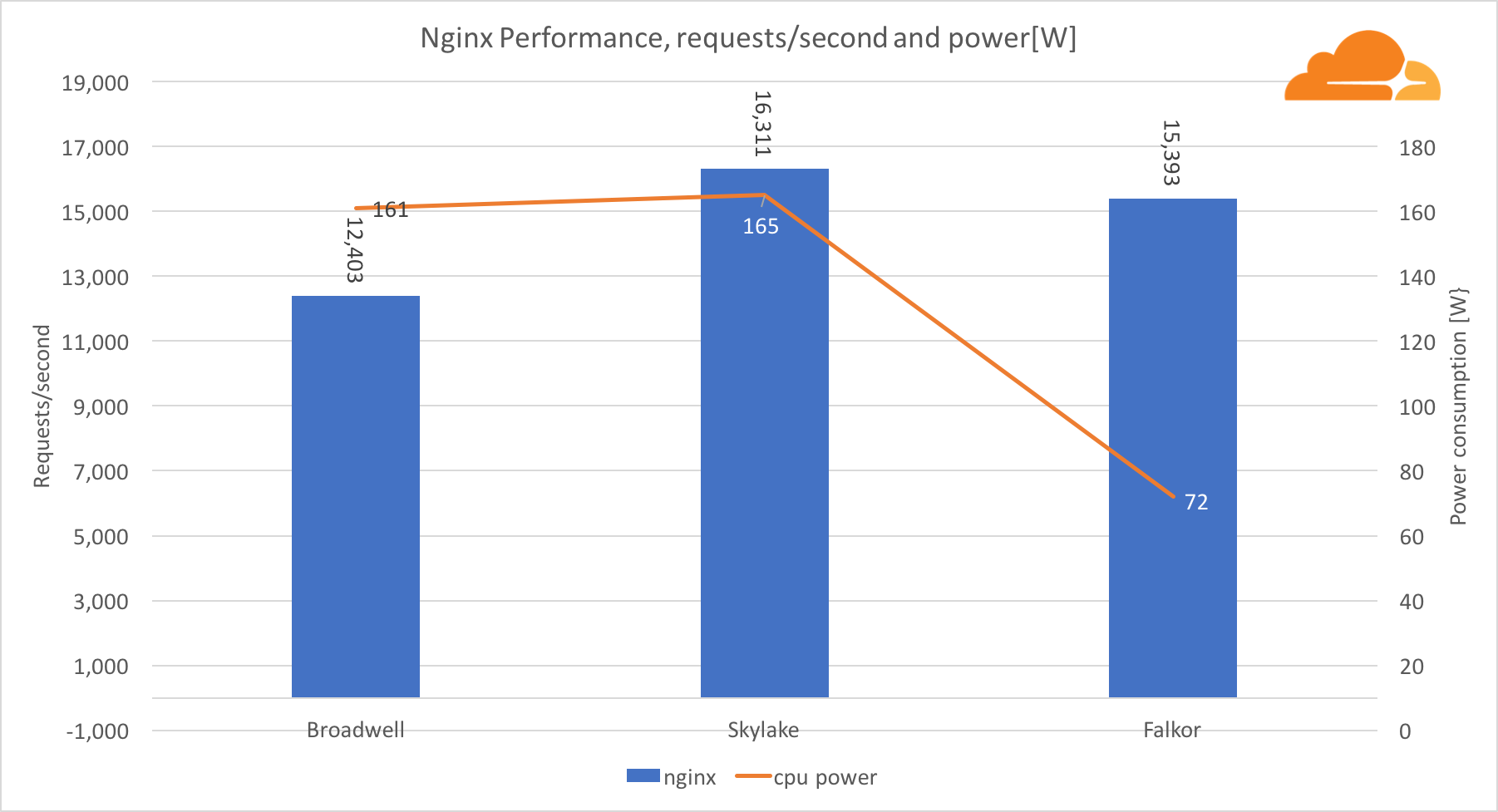
在工作量方面,NGINX Falkor处理的请求数量几乎与Skylake服务器相同,并且都大大超过了Broadwell。 从BMC读取的功率读数表明,这种情况是在功耗是其他处理器的一半时发生的。 这意味着Falkor设法获得214个请求/ W,Skylake-99个请求/ W和Broadwell-77个请求/ W。
令我惊讶的是,鉴于Skylake和Broadwell的生产方式相同,它们消耗的能量大致相同,而且Skylake的核心更多。
Falkor的低功耗不足为奇,因为高通处理器以其高能效而闻名,这使它们在移动设备处理器市场上占据了主导地位。
结论
我们得到的Falkor样本给我留下了深刻的印象。 与以前对基于ARM的服务器的尝试相比,这是一个巨大的改进。 当然,将核心与核心进行比较,英特尔Skylake要好得多,但是如果考虑系统级别,性能将变得非常诱人。
Centriq SoC的生产版本将包含48个Falkor内核,这些内核以最高2.6 GHz的频率运行,这可能使性能提高8%。
显然,我们测试的Skylake并非像铂金那样拥有28核的旗舰产品,但是这28核成本昂贵且消耗200W,而我们试图优化成本并提高1瓦性能。
目前,我最担心Go语言的糟糕性能,但是一旦基于ARM的服务器在市场上占据一席之地,这种情况就会改变。
Performance C和LuaJIT的竞争非常激烈,在许多情况下都优于Skylake。 在几乎所有测试中,Falkor被证明是Broadwell的值得替代品。
目前,Falkor的最大优点是功耗低。 尽管TDP为120W,但在我的测试中,这个数字从未超过89W(对于Go测试)。 相比之下,Skylake和Broadwell超过了160W,而其TDP为170W。
作为广告。 这些不仅仅是虚拟服务器! 这些是带有专用驱动器的VPS(KVM),这不会比专用服务器差,并且在大多数情况下-更好!
我们在荷兰和美国制造了带有专用驱动器的 VPS(KVM)(来自VPS(KVM)的配置-E5-2650v4(6核)/ 10GB DDR4 / 240GB SSD或4TB HDD / 1Gbps 10TB,价格低廉-从$ 29 /月,提供RAID1和RAID10的选件) ,不要错过订购新型虚拟服务器的机会,所有资源都属于您,就像专用的虚拟服务器一样,而生产率更高的硬件的价格要低得多!
如何建立建筑物的基础设施。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程? 戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) !