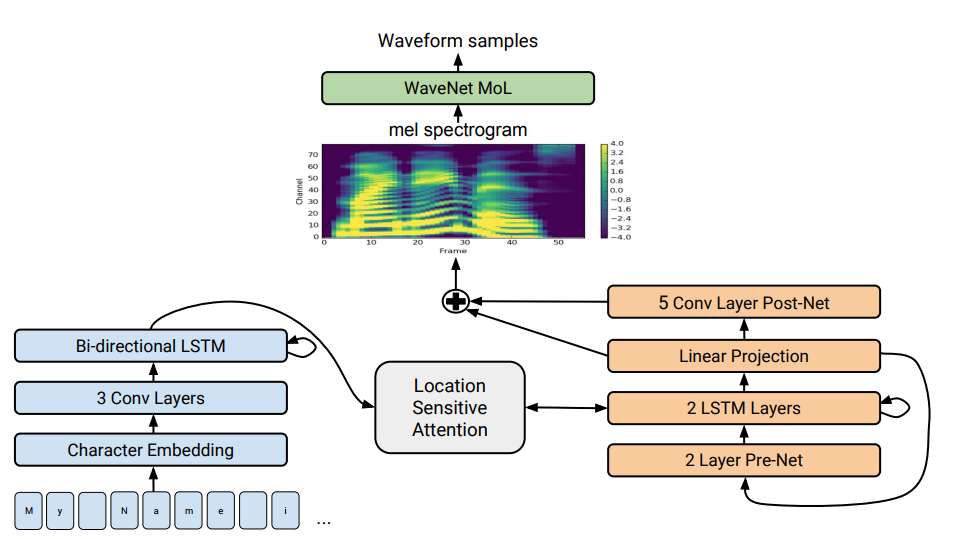
 Tacotron 2体系结构在图的底部,显示了“提供-提供”模型,该模型将字母序列转换为80维空间中的属性序列。 有关技术说明,请参阅科学文章。
Tacotron 2体系结构在图的底部,显示了“提供-提供”模型,该模型将字母序列转换为80维空间中的属性序列。 有关技术说明,请参阅科学文章。语音合成-从文本中人工还原人类语音-传统上被认为是人工智能的组成部分之一。 以前,此类系统只能在科幻电影中看到,但现在它们可以在几乎所有智能手机上使用:Siri,Alice等。 但是它们并不是很现实的话语:无生命的声音,单词彼此分开。
Google
开发了先进的下一代语音合成器。 它被称为Tacotron 2,是基于神经网络的。 为了展示其功能,该公司发布
了综合示例 。 在带有示例的页面底部,您可以进行测试,并尝试确定语音合成器在哪里传递文本以及该人在哪里。 确定差异几乎是不可能的。
尽管进行了数十年的研究,语音合成仍然是科学界的紧迫任务。 过去几年中,该领域盛行着各种技术:最近,级联合成和片段选择被认为是最先进的-将小的预先录制的声音片段组合在一起的过程以及统计参数语音合成,其中声码器合成了平滑的发音路径。 第二种方法解决了许多在片段之间边界存在伪影的级联合成问题。 但是,在两种情况下,与人类语音相比,合成声音听起来都是糊涂且不自然。
然后是WaveNet声音引擎(时域波形的生成模型),它首次能够显示出与人类相当的声音质量。 现在,它已在
Deep Voice 3语音合成系统中使用。
在2017年初,谷歌推出了
Tacotron的报价体系。 它从一系列字符生成幅度的频谱图。 Tacotron简化了传统的音频引擎传送带。 在这里,语言和声学特征是由仅对数据进行训练的单个神经网络生成的。 短语“句子到句子”是指神经网络在字母序列和用于编码声音的属性序列之间建立对应关系。 在具有12.5毫秒帧的80维音频频谱图中生成符号。
神经网络不仅学习单词的发音,而且学习特定的语音特征,例如音量,速度和语调。
然后,使用Griffin-Lim算法(用于相位估计)和逆短期傅立叶变换直接生成声波。 正如作者指出的那样,这是演示神经网络功能的临时解决方案。 实际上,WaveNet引擎等产生的声音比Griffin-Lim算法更好,并且没有伪影。
在改良的Tacotron 2系统中,来自Google的专家仍将WaveNet声码器连接到神经网络。 因此,神经网络创建了频谱图,然后WaveNet的修改版本生成了24 kHz的声音。
神经网络独立地(端对端)学习伴随着文本的人类声音。 训练有素的神经网络然后以这样的方式读取文本:几乎无法从人类语音中区分出来,正如在
实际示例中可以看到的那样。
研究人员指出,Deep Voice 3系统使用了类似的方法,但是其合成质量仍无法与人类语音相提并论。 但是Tacotron 2可以在表中看到平均意见分数(MOS)测试结果。
还有另一个语音合成器也可以在神经网络上工作-这是
Char2Wav ,但是它具有完全不同的架构。
科学家们说,一般来说,神经网络工作正常,但在发音某些复杂单词(如
礼节或
梅洛 )时仍存在困难。 有时它会随机产生奇怪的声音-现在正在澄清其原因。 另外,该系统不能实时工作,并且作者还不能控制引擎,即设置所需的语调,例如高兴或悲伤的声音。 他们写道,这些问题中的每一个本身都很有趣。
该科学文章于2017年12月16日发布在预印本网站arXiv.org(arXiv:1712.05884v1)上。