
在过去的十年中,深度神经网络(DNN)已成为许多AI任务(例如图像分类,语音识别甚至参与游戏)的出色工具。 当开发人员试图说明是什么导致DNN在图像分类领域取得成功时,并创建了可视化工具(例如Deep Dream,Filters)来帮助他们理解“什么”,确切地“研究”了DNN模型,因此出现了一个新的有趣的应用程序:从一幅图像中提取“样式”,然后应用于另一幅不同的内容。 这被称为“图像样式转换”。
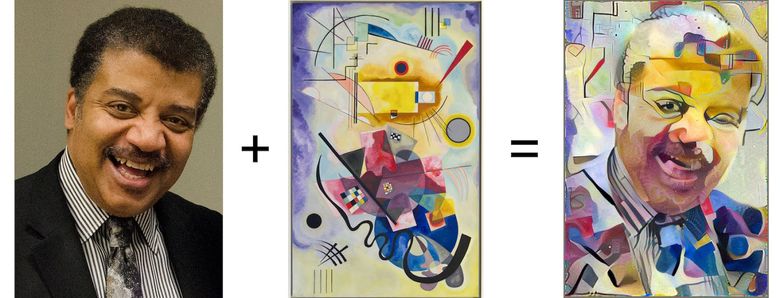
左:带有有用内容的图像,中间:带有样式的图像,右:内容+样式(来源: Google Research Blog )
这不仅激起了许多其他研究人员的兴趣(例如1和2 ),而且还导致了一些成功的移动应用程序的出现。 在过去的几年中,这些视觉样式转换方法已得到很大改进。

Adobe样式包装(来源: Engadget )

Prisma网站上的示例
此类算法的简短介绍:
但是,尽管在处理图像方面取得了进步,但是这些技术在其他领域(例如,用于处理音乐)的应用非常有限(请参见3和4 ),并且结果一点也不比图像方面的印象深刻。 这表明在音乐中传递风格要困难得多。 在本文中,我们将更详细地研究该问题并讨论一些可能的方法。
为什么在音乐中传递风格如此困难?
让我们首先回答一个问题: 音乐中的“样式转换”是什么? 答案不是那么明显。 在图像中,“内容”和“样式”的概念很直观。 “图像内容”描述了所表示的对象,例如狗,房屋,面部等,“图像样式”是指颜色,照明,画笔笔触和纹理。
但是,音乐本质上是语义抽象的和多维的。 “音乐内容”在不同的上下文中可能意味着不同的事物。 通常,音乐的内容与旋律相关联,而音乐的样式与编排或和声相关。 然而,内容可以是歌词,并且用于唱歌的不同旋律可以被解释为不同的风格。 在古典音乐中,内容可以看作是乐谱(包括和声),而风格是表演者对音符的解释,表演者可以表达自己的表情(改变自己的声音并添加一些声音)。 为了更好地理解音乐中风格转移的本质,请观看以下两个视频:
在第二个视频中,使用了各种机器学习技术 。
因此,按照定义,音乐中风格的转换很难形式化。 还有其他使任务复杂化的关键因素:
- BAD机器了解音乐 (目前为止 ):成功传递图像样式的原因在于DNN在与理解图像有关的任务(例如对象识别)方面的成功。 由于DNN可以学习跨对象变化的属性,因此可以使用反向传播技术来修改目标图像以匹配内容的属性。 尽管我们在创建能够理解音乐任务(例如,转录旋律,定义流派等)的基于DNN的模型方面取得了重大进展 ,但我们离图像处理的高度还差得很远。 这是音乐风格转移的严重障碍。 现有模型根本无法学习允许对音乐进行分类的“优秀”属性,这意味着在处理图像时使用样式转换算法的直接应用不会产生相同的结果。
- 音乐瞬息万变:它是表示动态系列的数据,即音乐片段随时间变化。 这使学习变得复杂。 尽管递归神经网络和LSTM (长期短期记忆)可让您从瞬态数据中学习更多,但我们仍然必须创建可靠的模型,以学习如何再现音乐的长期结构(注意:这是实际研究领域,Google小组的科学家洋红色在此方面取得了一些成功)。
- 音乐是离散的 (至少在符号级别):符号或纸上记录的音乐本质上是离散的。 在当今最流行的统一调律系统中,音质在连续频率范围内占据离散位置。 同时,音调的持续时间也位于离散的空间中(通常为四分之一音,全音等)。 因此,在符号音乐领域中很难适应像素反向传播方法(用于处理图像)。
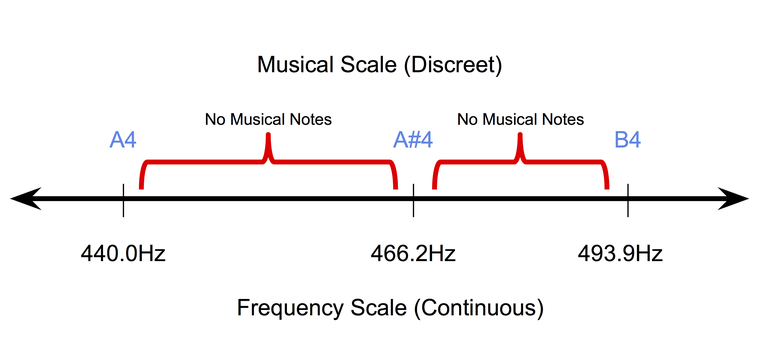
音符具有均匀的气质的离散特性。
因此,用于在图像中传递样式的技术不能直接应用于音乐。 为此,需要重点处理音乐概念和想法。
音乐中的风格转换是为了什么?
为什么需要解决这个问题? 与图像一样,音乐中样式转移的潜在用途也很有趣。 例如, 开发一种工具来帮助作曲家 。 例如,对于需要快速尝试不同想法的作曲家来说,能够使用不同流派的装置来改变旋律的自动乐器将非常有用。 DJ也将对此类乐器感兴趣。
这种研究的间接结果将是音乐信息学系统的重大改进。 如上所述,为了将样式转换为音乐作品,我们创建的模型必须学会更好地“理解”不同方面。
简化音乐中风格转移的任务
让我们从分析不同类型的单音旋律开始一个非常简单的任务。 单音旋律是音符序列,每个音符由音调和持续时间决定。 音高的变化在很大程度上取决于旋律的大小,而持续时间的变化则取决于节奏。 因此,首先,我们将“音高内容”和“节奏风格”明确区分为两个实体,您可以用它们重新定义传递风格的任务。 同样,当处理单音旋律时,我们现在将避免与编排和文本相关的任务。
在没有可以成功地区分单音旋律的音调和节奏的预训练模型的情况下,我们首先诉诸一种非常简单的方式来传递风格。 与其尝试将目标旋律学到的节奏内容更改为目标旋律学到的节奏风格,不如尝试分别教授不同流派的音调和持续时间的模式,然后尝试将它们组合在一起。 该方法的近似方案:
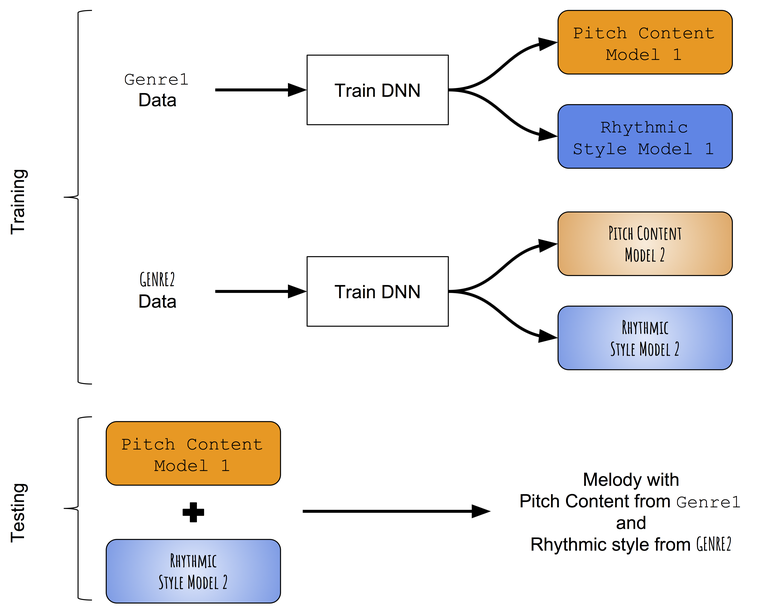
间体风格转移方法的方案。
我们分别教授音调和节奏的发展
资料呈现
我们将单声道旋律作为音符序列呈现,每个音符都有一个音调索引和一个序列。 为了使演示文稿键独立,我们将使用基于间隔的视图:下一个音符的音调将显示为与前一个音符的音调之间的偏差(±半音)。 让我们为音调和持续时间创建两个字典,其中为每个离散状态(对于音调:+ 1,-1,+ 2,-2等;对于持续时间:四分音符,完整音符,带点的四分音等)分配一个索引字典。
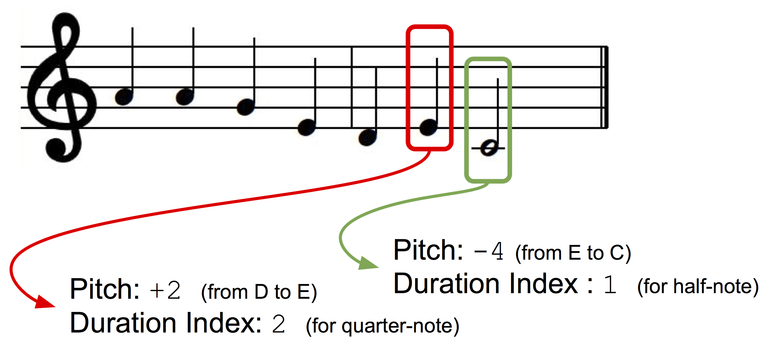
数据表示。
模型架构
我们将使用Colombo和同事使用的相同架构-他们同时将两个LSTM神经网络教给相同的音乐类型:a)音调网络学会了根据前一个音符和之前的持续时间来预测下一个音调,b)持续时间网络学会了根据下一个音符来预测下一个持续时间和以前的持续时间。 同样,在LSTM网络之前,我们将添加嵌入层以比较存储的嵌入空间中的输入音调索引和持续时间。 神经网络的架构如图所示:
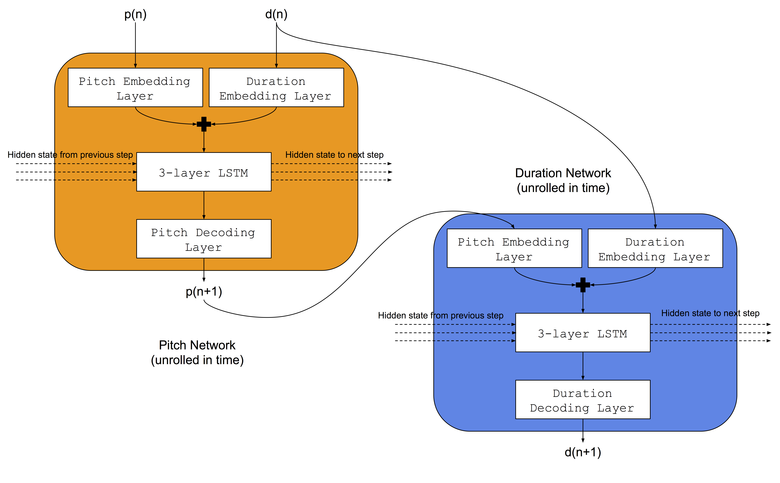
训练程序
对于每种类型,负责音调和持续时间的网络都应同时进行训练。 我们将使用两个数据集:a) Norbeck Folk Dataset ,涵盖大约2,000爱尔兰和瑞典民间旋律,b)一个爵士数据集(未公开),涵盖大约500爵士乐。
合并训练过的模型
在测试过程中,首先使用在第一类(例如,民间)中训练的音调网络和持续时间网络生成旋律。 然后,将来自生成的旋律的音调序列用于另一种流派(例如爵士乐)训练的序列网络的输入,结果是一个新的持续时间序列。 因此,使用两个神经网络的组合创建的旋律具有与第一流派(民谣)相对应的一系列音调和与第二流派(爵士乐)相对应的持续时间序列。
初步结果
某些结果曲调的简短摘录:
民谣音调和民谣持续时间

从音乐符号中提取。
民间音调和爵士乐时长

从音乐符号中提取。
爵士音调和爵士音序

从音乐符号中摘录 。
爵士乐和民谣序列

从音乐符号中提取。
结论
尽管当前的算法从一开始就不错,但它有许多严重的缺点:
- 不可能根据特定的目标旋律来“转移风格” 。 模型学习风格中的音调和持续时间的模式,这意味着所有变换都由该风格决定。 以特定目标歌曲或曲目的风格修改音乐是理想的。
- 无法控制样式更改的程度 。 获得控制该方面的“句柄”将非常有趣。
- 合并流派时, 不可能以变换后的旋律保留音乐结构 。 总体而言,长期结构对于音乐评估很重要,并且对于生成的旋律要具有音乐美感,必须保留该结构。
在以下文章中,我们将探讨规避这些缺点的方法。