AttnGAN操作示例。 第一行是神经网络生成的不同分辨率的几幅图像。 第二行和第三行显示了两个神经网络注意力模型对五个最合适的单词的处理,以绘制最相关的部分从自然语言的文字描述自动创建图像是许多应用程序(例如艺术创作和计算机设计)的基本问题。 这个问题还刺激了视觉和语言之间关系的多模式AI训练领域的进步。
研究人员在该领域的最新研究基于生成对抗网络(GAN)。 通用方法是将整个文本描述转换为全局句子向量。 这种方法显示出许多令人印象深刻的结果,但是它具有主要缺点:单词级别缺少清晰的细节,并且无法生成高分辨率图像。 来自Lichai大学,Rutgers大学,Duke大学(全美)和Microsoft的一组开发人员提出了他们
自己的解决方案:新的神经网络
Attentional Generative Adversarial Network(AttnGAN)代表了对传统方法的改进,并允许对生成的图像进行多阶段更改,从而可以更改文本中的单个单词说明。
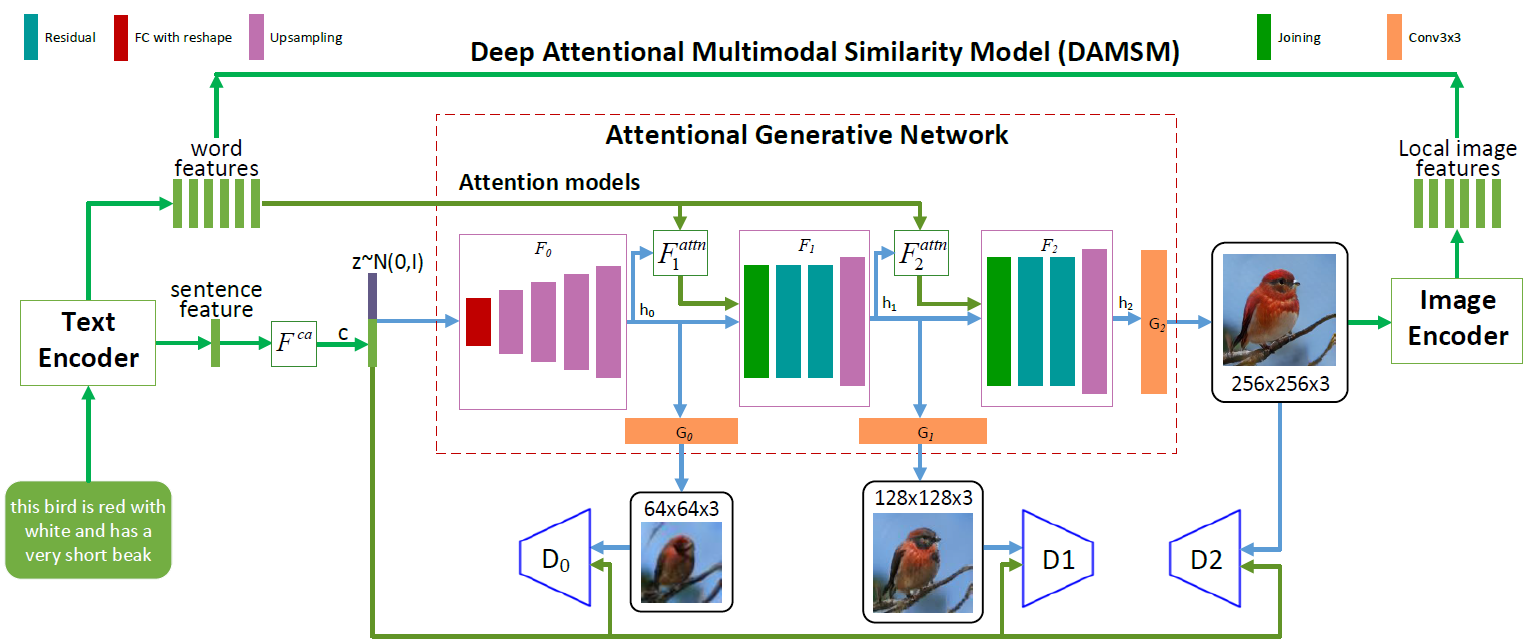 AttnGAN神经网络架构。 每个注意力模型自动接收用于生成图像的不同区域的条件(即,对应的词汇向量)。 DAMSM模块为生成网络中从图像到文本的转换中的一致性损失功能提供了额外的粒度
AttnGAN神经网络架构。 每个注意力模型自动接收用于生成图像的不同区域的条件(即,对应的词汇向量)。 DAMSM模块为生成网络中从图像到文本的转换中的一致性损失功能提供了额外的粒度如您在描绘神经网络架构的图示中所见,与传统方法相比,AttnGAN模型具有两项创新。
首先,它是一个对抗网络,将注意力作为学习因素(注意力生成对抗网络)。 也就是说,它实现了注意机制,该机制确定最适合生成图片的相应部分的单词。 换句话说,除了在句子的整体向量空间中编码整个文本描述之外,每个单独的词也被编码为文本向量。 在第一阶段,生成神经网络使用句子的全局向量空间来渲染低分辨率图像。 在以下步骤中,她使用每个区域中的图像向量来查询字典向量,并使用注意力层形成单词上下文向量。 然后,将区域图像向量与相应的词上下文向量组合以形成多峰上下文向量,基于该向量模型可以在各个区域中生成新的图像特征。 这使您可以有效地提高整个图像的分辨率,因为在每个阶段都有越来越多的细节。
微软的第二项神经网络创新是深度注意力多模式相似性模型(DAMSM)模块。 使用注意力机制,该模块使用来自句子向量空间级别和详细的字典向量级别的信息,计算生成的图像与文本句子之间的相似度。 因此,当训练生成器时,DAMSM为丢失从图像到文本的翻译时的拟合功能提供了额外的粒度。
开发人员写道,得益于这两项创新,AttnGAN神经网络显示的结果明显优于传统GAN系统的最佳结果。 尤其是,在CUB数据集上,现有神经网络的最大已知初始得分提高了14.14%(从3.82降低到4.36),提高了170.25%(从9.58降低到25.89)。在更复杂的COCO数据集上。
这一发展的重要性很难高估。 AttnGAN神经网络首次表明,多层生成-对抗网络将注意力作为学习因素,能够自动确定单词级条件以生成图像的各个部分。
该科学文章于2017年11月28日在预印本网站arXiv.org(arXiv:1711.10485v1)上发布。