Google Brain开发人员已经证明,“冲突”的图像可以同时容纳人和计算机。 而且可能的后果令人恐惧。
在上面的图片中-毫无疑问,在左边是一只猫。 但是您能确定地说这只猫在右边吗,还是只看似他的狗? 两者之间的区别在于,正确的算法是使用一种特殊的算法制作的,该算法没有给出称为“卷积神经网络”(CNN)的计算机模型,该算法明确地在图中得出结论。 在这种情况下,SNS认为这更像是狗而不是猫,但是最有趣的是-大多数人都以相同的方式思考。
这是所谓的“矛盾图片”(以下称为KARP)的示例:经过特殊修改,以欺骗SNA并防止正确识别内容。 Google Brain的研究人员想了解是否有可能以同样的方式使生物神经网络在我们的大脑中发生故障,因此产生了同样影响汽车和人的选择,使他们认为自己在看的东西不是。
什么是冲突图片?
为了在SNA中进行识别,几乎所有地方都使用了视觉分类算法。 通过“显示”该程序的大熊猫大量不同插图,您可以训练它识别大熊猫,因为它是通过比较学习的,目的是为整个熊猫挑选出一个共同的特征。 一旦SNA(也称为
“分类器” )在训练数据上收集到足够多的“熊猫标志”,它将能够在它将提供的任何新图片中识别出熊猫。
我们通过大熊猫的抽象特征来识别它们:小黑耳朵,大白头,黑眼睛,毛皮和所有爵士乐。 SNA会这样做,这并不奇怪,这是因为人们每分钟都会解读有关环境的信息量要大得多。 因此,考虑到模型的细节,可以通过与精心计算的数据混合来影响图像,使它们“不一致”,此后,一个人的结果看上去几乎像原始结果,但对于
分类器则完全不同,在尝试确定时,它会开始犯错误。内容。
这是一个熊猫的例子:
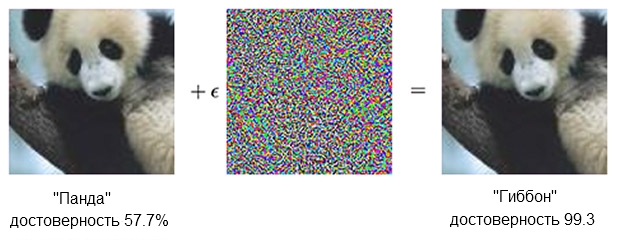 大熊猫的形象加上愤慨,可以使分类器确信它实际上是长臂猿。资料来源: OpenAI
大熊猫的形象加上愤慨,可以使分类器确信它实际上是长臂猿。资料来源: OpenAI基于SNA
的分类器可确保左侧的熊猫约为60%。 但是,如果您通过添加看起来像只是混沌噪声的东西来稍微补充(“引起愤慨”),则同一分类器将确保99.3%的信息将确保它正在查看长臂猿。 微小的变化甚至无法清楚地看出来,这会导致一次非常成功的攻击,但它只能在特定的计算机模型上起作用,而不会进行其他方面可以“学习”的变化。
为了创建引起大量不同的人工分析家错误反应的内容,应采取更加粗鲁的行动-微小的修改将不受影响。 用“小钱”做不到可靠的工作。 换句话说,如果您想让内容在各个角度和距离上都能正常工作,那么您必须进行更大幅度的干预,或者就像一个人说的那样,更加明显。
在眼前-一个男人
这是鲤鱼粗鲁的两个例子,一个人可以很容易地检测到干扰。
 资料来源:左侧为开放式AI ,右侧为Google Brain
资料来源:左侧为开放式AI ,右侧为Google BrainSNS定义为计算机的左侧猫的图片是使用“破碎的几何图形”制作的。 如果仔细观察(甚至不是太近),您会发现有一些类似于系统单元形状的角形和盒形结构。 从任何角度看,右边的香蕉图像(被认为是烤面包机)都稳定地产生了误报。 目前,人们会在这里找到一根香蕉,但是,旁边有一个奇怪的现象,有烤面包机的迹象-这简直就是技术的傻瓜。
当您制作出需要击败整个识别模型公司的有保证的合适“矛盾”图像时,通常会导致出现“人为因素”。 换句话说,混淆单个神经网络的问题根本不会被认为是一个问题,并且当您尝试获得绝对适合一次欺骗五到十次的rebus时,事实证明它在以下情况下起作用:人们是完全没用的。
结果,绝对没有必要强迫人们相信有角的猫是电脑机箱,香蕉和奇怪的橡皮擦的总和看起来像烤面包机。 创建专为您和我设计的CARP时,立即专注于使用能够像人们一样感知世界的模型会更好。
欺骗眼睛(和大脑)
具有深度训练和人眼视觉的SNA有点相似,但基本上,神经网络“以计算机方式”“看”事物。 例如,当给她喂食照片时,她会同时“看到”一个矩形像素的静态网格。 眼睛的工作原理有所不同,一个人在视线的每一侧大约五度的扇形区域内都能感知到较高的细节,但是在该区域之外,对细节的注意会线性降低。
因此,与机器不同,例如,模糊图像边缘不会对人起作用,并且只会被忽略。 研究人员能够通过添加“视网膜层”来模拟此功能,该层将SNA提供的数据更改为对眼睛的外观,目的是将神经网络限制在与正常视觉相同的帧。
应当指出的是,一个人通过注视不指向一个点而是不断移动来检查整个图像这一事实来应对自己的感知缺陷,但也有可能补偿实验条件,从而使SNA与人之间的差异变平。
从作品本身注意:
每个实验都以安装十字准线开始,该十字准线出现在屏幕中央500-1000毫秒,并指示每个对象将视线固定在十字准线上。使用“视网膜层”是对“人为特征”进行机器学习“精简”时必须采取的最后一步。 在生成样本的过程中,通过10种不同的模型来驱动它们,每个模型都应该明确地称呼它为猫,例如狗。 如果结果是“错误的十分之一”,则将该材料提交给人体进行测试。
这样行吗?
实验中涉及三组图片:“宠物”(猫和狗),“蔬菜”(西葫芦和西兰花)和“威胁”(蜘蛛和蛇),尽管作为蛇的主人,我建议使用其他术语进行评估。 对于每个组,如果测试人员选择了错误的事物(称为狗是猫,反之亦然),就算成功。 参与者坐在显示图像的监视器前面约60或70毫秒,他们必须按下两个按钮之一来指示对象。 由于图像的显示时间很短,因此可以消除人与神经网络感知世界之间的差异。 顺便说一句,标题中的插图显示了错误的持续性。
受试者显示的内容可能是未修改的图像(图像),“普通” CarP(adv),“倒置”(翻转)CarP(在应用之前将噪声颠倒了)或“假” CarP,其上有一层噪波被应用于不属于组中任何类型的图片(假)。 最后两个选项用于控制扰动的性质(噪声结构会以其他方式颠倒还是“吃不住”吗?),此外,它们还使我们能够理解干扰是完全欺骗了人还是只是稍微降低了准确性。
从作品本身注意:
错误:添加了条件以迫使对象犯错。 我们添加了它,因为如果初始更改降低了观察者的准确性,那可能是由于直接图像质量下降所致。 为了表明CARP实际上在每个班级都有效,我们引入了选项,其中没有选择是正确的,它们的准确度为0,并且在这种情况下,我们确切地看到了“正确”的答案。 我们演示了来自ImageNet的任意图像,这些图像受组中一个或另一个类别的影响,但不适合其中任何一个。 实验参与者必须确定自己面前的事物。 例如,我们可以显示通过施加“狗”噪声而变形的飞机的图片,尽管在实验过程中受试者应该只识别出猫或狗。这是一个示例,该示例显示了根据噪音的使用情况,能够清晰地将照片识别为狗的人数百分比。 让我提醒您,看一下并做出决定仅需要60-70毫秒。
 资料来源:Google Brain
资料来源:Google Brain
与狗的原始图片; 鲤鱼与狗,被男人和计算机都接受为猫; 控制图像,其中有一层噪音倒置。这是最终结果:
 资料来源:Google Brain
资料来源:Google Brain
研究结果表明,与失真图片相比,真实的人如何识别这些图片。图表显示了匹配的准确性。 如果您选择一只猫,但实际上它是一只猫,则准确性会提高。 如果您选择了一只猫,但实际上是一只狗,被噪音变成了一只猫,则准确性会降低。
如您所见,人们在选择未校正图像或具有反向噪声层时比在选择“不一致”图像时要正确得多。 这证明了攻击感知的原理可以从计算机转移给我们。
这些影响不仅无可否认地有效,而且比预期的要薄-没有盒子的猫或伪烤面包机,或类似的东西。 由于我们在处理之前和之后都看到了噪点和图像,因此我们需要弄清楚到底是什么使我们感到困惑。 尽管研究人员持谨慎态度,但指出“我们的示例是专门制作来愚弄人的,因此您应该谨慎地使用人作为实验来研究这种效果。”
将来,该小组将尝试针对某些类别的修改得出一些通用规则,包括“
破坏对象的边缘 ,尤其是受到垂直于边缘线的中等冲击的
破坏 ;通过在对纹理进行边框处理时提高对比度来
校正边界区域 ;
更改纹理 ;
使用深色部分” “即使有很小的干扰,对感知的影响仍然很高的
图像 。” 以下是在其中最好看到所描述方法的红色圆圈区域的示例。
 资料来源:Google Brain
资料来源:Google Brain
具有不同失真原理的图像示例结果如何?
最重要的是,这不仅仅是一个聪明的把戏。 Google Brain的人员证实,他们可以创建一种有效的欺骗技术,但考虑到抽象级别,他们并没有完全理解欺骗的原因,而且这有可能是现实的基本级别:
我们的项目提出了有关CARP如何工作,神经网络和大脑如何工作的基本问题。 您是否设法将攻击从SNA转移到大脑,因为其中的信息的语义表示相似? 还是因为这两种表示都对应于自然存在于周围世界中的某个通用语义模型?
总之,如果您确实想有点偏执,那么研究人员很乐意为您提供帮助,并指出“物体的视觉识别...很难给出客观的评估。 “图1”在客观上是真的是狗吗,还是可以让人们认为它是狗的客观猫?” 换句话说,图片真的变成了物体,还是只是让您有所不同?
令人毛骨悚然的是(我认真地说“令人毛骨悚然”),最后您可以找到影响任何事实的方法,因为操作SNA和操作人员之间的距离显然不会太大。 因此,机器学习技术可能会以正确的方式用于扭曲图像或视频,这将取代我们的感知(以及相应的反应),我们甚至不了解发生了什么。 从报告中:
例如,可以对人们对某些类型的人,特征,表情的置信度进行评估,从而对经过深入培训的一系列模型进行训练。 可能会产生“矛盾的”愤慨,而这种愤慨会增加或减少“可信度”的感觉,并且这种“经过调整的”材料可以用于新闻剪辑或政治广告中。
将来,理论上的风险包括可能产生以多种方式并以非常高的效率闯入大脑的感觉刺激。 如您所知,许多动物被认为容易受到阈值以上的刺激。 可以说杜鹃可以同时装作无助并发出轻率的叫声,这共同导致其他品种的鸟在自己的后代之前喂养杜鹃雏鸡。 可以将“冲突”样本视为神经网络的这种超阈值刺激的特殊形式。 可以使用机器创建过度刺激,从理论上讲,不仅仅是使他们在狗的照片上悬挂标签“猫”,而且更可能影响人的事实引起了广泛的关注,这一事实可以通过机器制造出来,然后转移给人们。
当然,这样的方法可以“有益”地使用,并且已经提出了许多选择,例如“例如在控制空气状况或分析X射线图像时,为了增强浓度水平而增强图像的特征”,因为这项工作是单调的,其后果是单调的。粗心大意可能是可怕的。” 另外,“用户界面设计人员可以使用扰动来开发更直观的界面。” 嗯 当然,这很棒,但是我更担心地动脑筋并建立对人的信任程度,这是您知道的吗?
提出的一些问题将成为未来研究的主题-可能会发现到底是什么使特定图片更适合于向人传达错误,这可能为理解大脑原理提供新的线索。 反过来,这将有助于创建更高级的神经网络,从而使学习速度更快,更好。 但是我们应该小心并记住,就像计算机一样,有时候欺骗我们并不是那么困难。
可以从
arXiv下载项目
“ Gamaleldin F. Elsayed,Shreya Shankar,Brian Cheung,Nicolas Papernot,Alex Kurakin,Ian Goodfellow和Jascha Sohl-Dickstein的Gamaleldin F. Elsayed,Google大脑的项目” 。 而且,如果您需要更多有争议的图片来处理与人有关的事情,那么
这里提供支持材料。