
Instagram拥有世界上最大的Apache Cassandra数据库之一。 该项目于2012年开始使用Cassandra取代Redis,并支持欺诈识别系统Tape和Direct等应用程序功能的实现。 最初,Cassandra集群在AWS中工作,但后来工程师将其与所有其他Instagram系统一起迁移到了Facebook基础架构中。 Cassandra在可靠性和容错性方面表现非常出色。 同时,读取数据时的等待时间指标可以明显改善。
去年,卡桑德拉(Cassandra)的Instagram支持团队开始致力于一个旨在显着减少卡桑德拉(Cassandra)中读取数据延迟的项目,该工程师称为Rocksandra。 在本文中,作者讲述了促使团队实施该项目的原因,必须克服的困难以及工程师在内部和外部云环境中使用的性能指标。
过渡理由
Instagram积极广泛地将Apache Cassandra用作键值存储服务。 大多数Instagram请求都是在线发生的,因此,为了为数亿个Instagram用户提供可靠和愉快的用户体验,SLA对系统的性能要求很高。
Instagram坚持五至九的可靠性等级。 这意味着在任何给定时间的故障数量不能超过0.001%。 为了提高性能,工程师积极监控各种Cassandra群集的吞吐量和延迟,并确保所有请求中的99%都符合某个指标(延迟P99)。
下图显示了一个Cassandra战斗集群的客户端延迟为1。 蓝色表示平均读取速度(5毫秒),橙色表示99%的读取速度,范围为25-60毫秒。 其更改高度依赖于客户端流量。
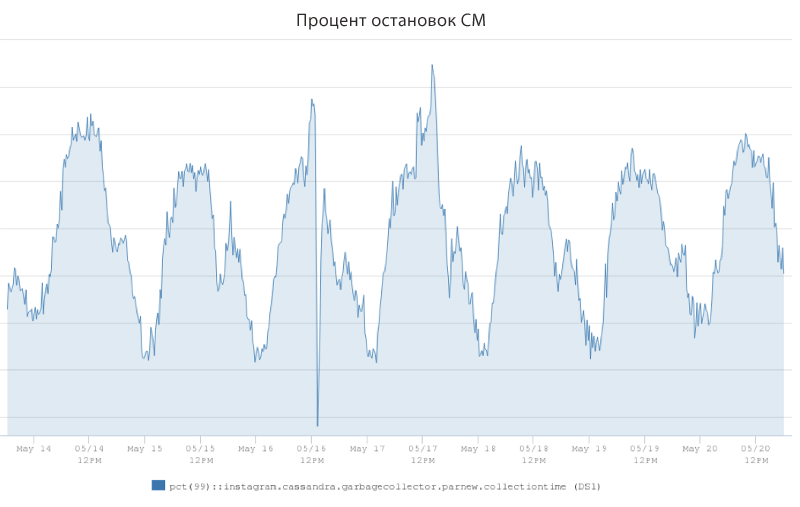

研究发现,急剧的延迟爆发主要是由于JVM垃圾收集器的工作所致。 工程师引入了一种称为“ SM停止百分比”的度量标准,以衡量Cassandra服务器在“停止世界”上花费的时间百分比,并伴随拒绝客户请求的服务。 这是上面的图表,其中以一台Cassandra战斗服务器为例,显示了前往SM站的时间(以百分比为单位)。 该指标的范围从最小流量时的1.25%到峰值负载时的2.5%。
该图显示,此Cassandra服务器实例可能花费其2.5%的时间来收集垃圾而不是服务于客户端请求。 收集器的预防性操作显然对P99延迟有重大影响,因此很明显,如果我们能够降低CM停止率,则工程师可以显着降低P99延迟率。
解决方案
Apache Cassandra是基于Java的分布式数据库,具有基于LSM树的自己的数据存储引擎。 工程师发现引擎组件,例如内存表,压缩工具,读/写路径以及其他一些组件,在Java动态内存中创建了许多对象,这意味着JVM必须执行许多额外的开销操作。 为了减少存储机制对垃圾收集器工作的影响,支持团队考虑了各种方法,并最终决定开发一种C ++引擎并用它替换现有的引擎。
工程师们不想从头开始做所有事情,因此决定以RocksDB为基础。
RocksDB是用于键值存储的高性能,开源嵌入式数据库。 它使用C ++编写,其API具有针对C ++,C和Java的官方语言绑定。 RocksDB针对高性能进行了优化,尤其是在SSD等快速驱动器上。 它在业界广泛用作MySQL,mongoDB和其他流行数据库的存储引擎。
难点
在RocksDB上实现新存储引擎的过程中,工程师面临着三项艰巨的任务并将其解决。
第一个困难是,Cassandra仍然缺乏允许连接第三方数据处理器的体系结构。 这意味着现有引擎的工作与其他数据库组件紧密联系在一起。 为了在大规模重构和快速迭代之间找到平衡,工程师定义了新引擎的API,包括最常见的读取,写入和流接口。 因此,支持团队能够为API实现新的数据处理机制,并将其插入到Cassandra内部的相应代码执行路径中。
第二个困难是Cassandra支持结构化数据类型和表模式,而RocksDB仅提供键值接口。 工程师精心定义了编码和解码算法,以在RocksDB数据结构中支持Cassandra数据模型,并确保两个数据库之间相似查询的语义的连续性。
第三个困难与任何分布式数据库组件的重要组件(如处理数据流)相关。 每当在Cassandra群集中添加或删除节点时,都需要在不同节点之间正确分配数据以平衡群集中的负载。 这些机制的现有实现基于从现有数据库引擎获取详细数据的基础上。 因此,工程师必须将它们彼此分开,创建一个抽象层,并使用RocksDB API来实现用于处理流的新选项。 为了获得高吞吐量的流,支持团队现在首先将数据分发到临时的sst文件,然后使用特殊的RocksDB API“吞下”文件,从而允许将它们同时加载到RocksDB实例中。
绩效指标
经过将近一年的开发和测试,工程师完成了该实现的第一个版本,并成功地在多个Instagram Instagram Cassandra集群上“推出”了该实现。 在其中一个战斗机群中,P99延迟从60毫秒降至20毫秒。 观察还显示,该集群中的SM止损从2.5%下降到0.3%,即几乎10倍!
工程师们还想检查Rocksandra在公共云环境中能否表现良好。 支持团队使用三个i3.8 xlarge EC2实例在AWS中建立了一个Cassandra群集,每个实例均具有32核处理器,244 GB RAM和零RAID的四个NVMe闪存驱动器。
为了进行比较测试,我们使用了
NDBench和框架的默认表架构。
TABLE emp ( emp_uname text PRIMARY KEY, emp_dept text, emp_first text, emp_last text )
工程师预先加载了2.5亿行6行,每行6 KB(每个服务器上存储了大约500 GB的数据)。 接下来,在NDBench中设置128个读写器。
支持团队测试了各种负载,并测量了平均/ P99 / P999读写延迟。 下图显示了Rocksandra的读写延迟显着降低并且更加稳定。


工程师还检查了读取模式下未写入的负载,发现在相同的P99读取延迟(2毫秒)下,Rocksandra能够将信息读取速度提高10倍以上(Rocksandra的速度为300 K / s,C的速度为30 K / s) * 3.0)。


未来计划
Instagram支持团队已打开
Rocksandra代码和
框架来评估性能 。 您可以从Github下载它们,然后在自己的环境中尝试。 一定要告诉我们这是怎么回事!
下一步,该团队正在积极努力,为C *功能添加更广泛的支持,例如二级索引,修补程序等。 此外,工程师正在
用C *开发
插件数据库引擎的
体系结构,以进一步将这些开发成果转移到Apache Cassandra社区。
