哈Ha! 最后,我们等待
大数据专家和
深度学习计划的毕业生Cyril Danilyuk的系列材料的另一部分,即使用Mask R-CNN(当前流行的神经网络)作为图像分类系统的一部分,即使用来自传感器的数据集评估准备好的菜肴的质量。
在检查了
上一篇文章中由路标图像组成的玩具数据集之后,我们现在可以解决我在现实生活中遇到的问题:
“是否可以实施深度学习算法,该算法可以一次将高品质的菜品与不良的菜品区分开照片吗? 。 简而言之,企业希望这样做:
企业在考虑机器学习时代表什么:这是一个错误提出的问题的示例:在这种情况下,无法确定解决方案是否存在,解决方案是否唯一且稳定。 而且,问题本身的陈述非常模糊,更不用说解决方案的实施了。 当然,本文并非专门讨论沟通或项目管理的有效性,但需要注意的是:
切勿从事未定义最终结果并记录在工作说明中的项目。 解决此类不确定性的最可靠方法之一是首先构建原型,然后使用新知识来构造其余任务。 那就是我们所做的。
问题陈述
在我的原型中,我专注于菜单上的一个菜-煎蛋卷-并建立了可伸缩的管道,该管道确定了煎蛋卷在输出处的“质量”。 可以更详细地描述如下:
- 问题类型:具有6个离散质量类别的多类分类: 好 (好), 碎蛋黄(带有散开的蛋黄), 烤制 (过度煮熟 ),两个鸡蛋(两个鸡蛋),四个鸡蛋(四个鸡蛋), 放错位置的碎片(散落在盘子上) 。
- 数据集: 351个手动收集的各种煎蛋卷的照片。 培训/验证/测试样本:139/32/180张混合照片。
- 分类标签:每张照片对应一个分类标签,该标签对应于对煎蛋卷质量的主观评估。
- 指标:分类交叉熵。
- 最少的领域知识: “优质”煎蛋卷应该看起来像这样:它由三个鸡蛋,少量的培根,中心的欧芹叶组成,没有散布的蛋黄和煮熟的蛋块。 同样,整体成分应“看起来不错”,也就是说,碎片不应散布在整个板上。
- 完成标准:原型开发两周后,在所有可能的测试样品中,交叉熵的最佳值。
- 最终可视化的方法:在较小维度的数据空间上使用t-SNE。
 输入图像
输入图像管道的主要目标是学习组合几种类型的信号(例如,来自不同角度的图像,热图等),已接收到每种信号的预压缩表示并将这些特征通过神经网络分类器进行最终预测。 因此,我们可以实现我们的原型并将其实际应用于进一步的工作。 以下是原型中使用的一些信号:
- 关键成分的口罩(面罩R-CNN): 1号信号 。
- 框架上关键成分的数量。 信号编号2 。
- 板材RGB庄稼用煎蛋卷没有背景。 为简单起见,尽管它们是最明显的信号,我还是决定不将它们添加到模型中:将来,您可以使用一些适当的三重态损失函数训练卷积神经网络进行分类,计算图像嵌入并从当前模型中切除L2距离图像完美。 不幸的是,我没有机会检验这个假设,因为测试样本仅包含139个对象。
管道总览
我注意到,我将不得不跳过几个重要步骤,例如,针对Mask R-CNN的管道,例如探索性数据分析,构建基本分类器和主动标记(我的提议术语,这是指对象的半自动注释,受
Polygon-RNN演示视频启发)。在下一篇文章中)。
总体看一下整个管道:
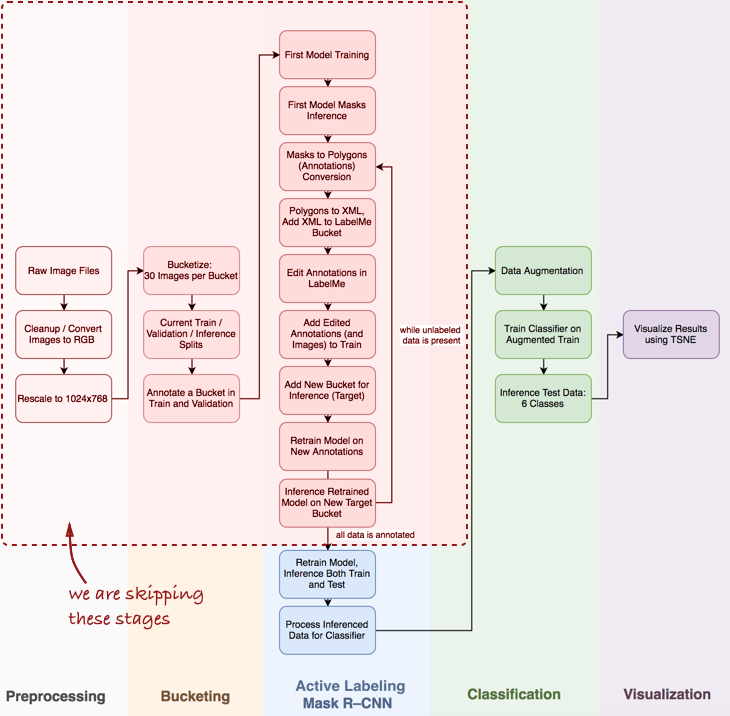 在本文中,我们对Mask R-CNN的阶段以及管道中的分类感兴趣。
在本文中,我们对Mask R-CNN的阶段以及管道中的分类感兴趣。接下来,我们将考虑三个阶段:1)使用Mask R-CNN构建蛋卷成分的面具; 2)基于Keras的ConvNet分类器; 3)使用t-SNE可视化结果。
阶段1:遮罩R-CNN和建筑遮罩
遮罩R-CNN(MRCNN)最近已经达到顶峰。 Mask R-CNN从最初的
Facebook文章开始,到Kaggle的
Data Science Bowl 2018结束,已将自身确立为强大的实例分割架构(即,不仅逐像素图像分割,而且还分离了属于同一类的多个对象) 此外,很高兴与
Keras的Matterport一起
实施MRCNN 。 该代码结构合理,具有良好的文档说明,并且开箱即用,尽管比预期的要慢。
在实践中,尤其是在开发原型时,拥有预训练的卷积神经网络至关重要。 在大多数情况下,数据科学家的标记数据集非常有限或根本没有,而ConvNet需要大量标记数据才能实现收敛(例如,ImageNet数据集包含120万个标记图像)。 在这里,
转移学习可助您一臂之力:我们可以固定卷积层的权重并仅对分类器进行重新训练。 固定卷积层对于小型数据集很重要,因为此技术可防止重新训练。
这是我进入再培训的第一个时代后得到的:
 对象分割结果:识别所有关键成分
对象分割结果:识别所有关键成分在流水线的下一阶段(
分类器的处理推断数据 ),您需要切出包含该板的图像部分,并为该板上的每种成分提取二维二进制掩码:
 与关键成份的播种的图象以二进制面具的形式。
与关键成份的播种的图象以二进制面具的形式。然后将这些二进制掩码组合成一个8通道图像(因为我为MRCNN定义了8个掩码类),所以我们得到
信号1 :
 1号信号 :由二进制掩码组成的8通道图像。 颜色更好地可视化。
1号信号 :由二进制掩码组成的8通道图像。 颜色更好地可视化。为了得到
2号信号 ,我计算了在平板作物上发现每种成分的次数,并得到了一组特征向量,每个特征向量都对应于其作物。
阶段2:Keras中的ConvNet分类器
CNN分类器是使用Keras从零开始实现的。 我想组合几个信号(
信号1和
信号2 ,以及将来可能添加的数据),然后让神经网络使用它们来对菜肴的质量做出预测。 下面介绍的体系结构是试用版,远远不够理想:

关于分类器架构的几句话:
- 多尺度卷积模块 :我最初为卷积层选择了5x5滤镜,但这只能带来令人满意的结果。 通过将AveragePooling2D应用于具有不同滤镜的多层:3x3、5x5、7x7、11x11,可以实现改进。 在每个层的前面添加了一个额外的1x1卷积层以减小尺寸。 这个组件有点像一个Inception模块 ,尽管我并不打算建立一个太深的网络。
- 较大的滤镜 :我使用了较大的滤镜,因为它们有助于从输入图像中轻松提取较大的信号(其本质上是具有8个滤镜的激活层-每种成分的掩模都可以视为单独的滤镜)。
- 组合信号 :在我的幼稚实现中,仅使用一层连接两组属性:已处理的二进制掩码( 信号1 )和计数成分( 信号2 )。 然而,尽管其简单性,但增加了2号信号仍使将交叉熵度量从0.8降低到[0.7,0.72]成为可能 。
- Logits :就TensorFlow而言,logit是一层应用tf.nn.softmax_cross_entropy_with_logits来计算批次损失的层 。
阶段3:使用t-SNE可视化结果
为了可视化测试数据分类器的结果,我使用了t-SNE-一种算法,该算法可让您将源数据传输到较低维度的空间(要了解算法的原理,我建议阅读
原始文章 ,该
文章非常有用且写得很好)。
在可视化之前,我拍摄了测试图像,提取了分类器的logite层,并将t-SNE算法应用于该数据集。 尽管我没有尝试过不同的perplexity参数值,但结果仍然看起来不错:
 基于分类器预测的测试数据上t-SNE的结果
基于分类器预测的测试数据上t-SNE的结果当然,这种方法并不完美,但是可以起作用。 可能会有很多改进:
- 更多数据。 卷积网络需要大量数据,而我只有139张图像用于训练。 诸如数据增强之类的技术可以很好地工作(我使用了D4或对称二面体增强 ,可以生成2000多个图像),但是拥有更多真实数据仍然非常重要。
- 更合适的损失函数。 为简单起见,我使用了分类交叉熵,这很好,因为它可以直接使用。 最好的选择是使用损失函数,该函数考虑了类之间的差异,例如,三元组损失函数(请参阅FaceNet文章 )。
- 改进分类器架构。 当前的分类器本质上是一个原型,其唯一目的是构建二进制掩码并组合多组特征以形成单个管道。
- 改进的图像布局。 手动标记图像时我很马虎:分类器在十几张测试图像上比我做得更好。
结论 最终必须承认,企业既没有数据,也没有解释,甚至没有需要解决的更明确的任务。 这很好(否则,他们为什么需要您?),因为您的工作是使用各种工具,多核处理器,预先训练的模型以及技术和业务专长的结合来为公司创造更多价值。
从小处开始:可以从几个玩具代码块中创建一个有效的原型,这将大大提高与公司管理层进行进一步对话的效率。 这是数据科学家的工作-为业务提供新的方法和想法。
2018年9月20日,
“大数据专家9.0”启动,您将在其中学习如何可视化数据并理解该任务或任务背后的业务逻辑,这将有助于更有效地向同事和管理层展示您的工作成果。