
今天,CERN已成为全球最大的Kubernetes用户之一。 根据最近的统计,在大型强子对撞机(LHC)和许多其他著名的研究项目之后,该欧洲组织已经发射了210个欧洲K8机群,同时完成数十万个任务。 这个成功的故事是关于他们的。
CERN容器:开始
对于那些至少初步了解CERN活动的人来说,在这个组织中对相关信息技术给予了很多关注已不是什么秘密:记住,这是万维网的发源地,在最近的优点中,您还可以回想起网格系统(包括
LHC)计算网格 ),专用
集成电路 ,
科学Linux发行版,甚至
拥有自己的开放式硬件
许可证 。 通常,这些项目,无论是软件还是硬件,都与CERN的主要创意-LHC有关。 这也适用于CERN IT基础架构,该基础架构在很大程度上满足了其自身的需求。
 在日内瓦CERN数据中心
在日内瓦CERN数据中心有关组织基础架构中容器实际使用的最早公开信息可追溯到2016年4月。 作为
CERN Clouds中Containers and Orchestration的“内部”报告的一部分,CERN员工讨论了如何使用OpenStack Magnum
(用于与容器编排引擎一起工作的OpenStack组件)为云中的容器(CERN Cloud)及其编排提供支持。 那时,工程师已经提到Kubernetes,其目标是独立于所选的编排工具,并支持其他选项:Docker Swarm和Mesos。
注意 :OpenStack云本身是在几年前(2013年)引入CERN生产基础架构的。 截至2017年2月,该云中可使用18.8万个内核,440 TB RAM,创建了400万虚拟机(其中22,000个处于活动状态)。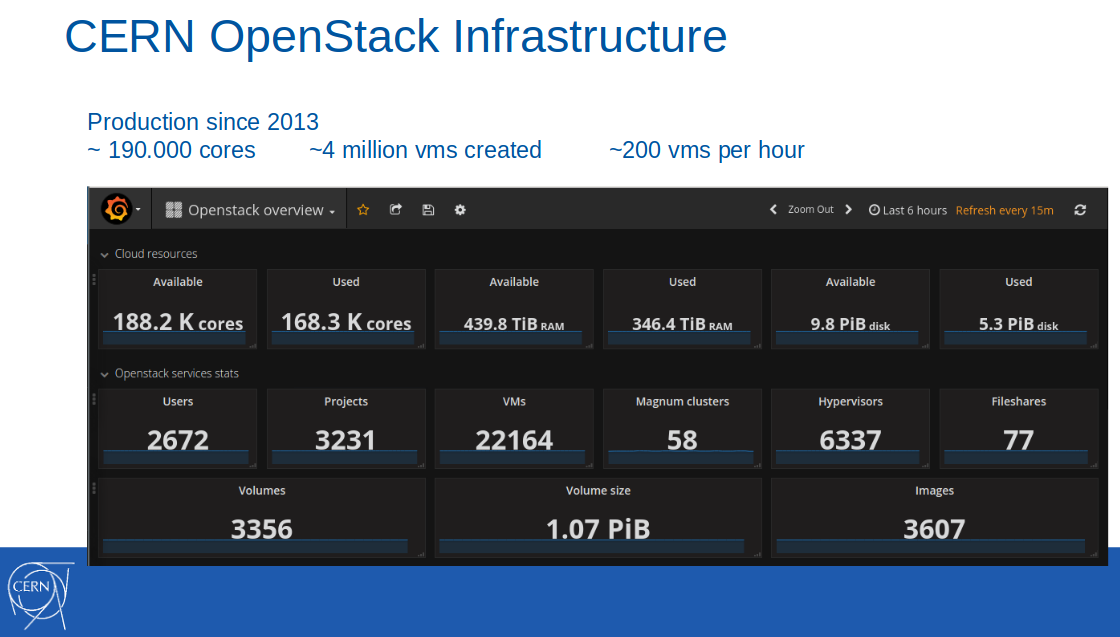
那时,以容器即服务的格式提供的容器支持被定位为一项试点服务,并被该组织的10个IT项目所使用。 在应用程序场景中,需要与GitLab CI进行持续集成以在Docker容器中构建和推出应用程序。
 从演讲到2016年4月8日的CERN报告
从演讲到2016年4月8日的CERN报告预计该服务将于2016年第三季度投入生产。
注意 :值得注意的是,CERN员工总是将其最佳实践始终用于所使用的开源项目的上游,包括 以及众多OpenStack组件,在这种情况下为Magnum,puppet-magnum,Rally等。Kubernetes每秒数百万个请求
截至同一年(2016年)的六月,CERN的服务仍处于生产前状态:
“我们正在逐步走向成熟的生产模式,将容器即服务纳入CERN提供的标准IT服务集中。”
然后,受Kubernetes博客上有关在K8s中的服务更新期间每秒处理100万个HTTP请求而无需停机的请求的启发,科学组织的工程师决定在OpenStack Magnum,Kubernetes 1.2和800个CPU内核的硬件基础上重复这一成功。
此外,他们决定不局限于重复进行一次简单的实验,而是成功地将请求数量增加到每秒200万次,同时为同一个OpenStack Magnum准备了几个补丁程序,并对集群中不同数量的节点(300、500和1000)进行了测试。
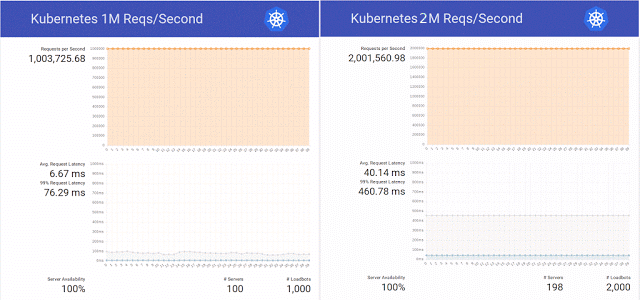
总结测试结果,工程师再次指出:“还有Swarm和Mesos,我们计划很快对其进行测试。” 事情是否已经通过这些测试,Internet尚不为人所知,但是到那年底,对Kubernetes的试验仍在
继续 -每秒有1000万个请求。 结果是非常积极的,但由于与OpenStack不相关的网络问题,成功的成绩仅超过700万。
专门研究OpenStack Heat和Magnum的工程师还测量了23分钟的时间,将集群从1个节点扩展到1000个节点,并将其评估为一个很好的结果
(另请参见2016年巴塞罗那OpenStack峰会上的OpenStack上的10,000个容器 ) 。
欧洲核子研究组织的集装箱:过渡到生产
在下一年(2017年)的二月,CERN的容器已被广泛用于解决各个领域的问题:批处理,机器学习,基础架构管理,持续部署……这
在CERN的OpenStack Magnum报告中宣布
。 在FOSDEM 2017上将
容器集群扩展到数千个节点 ”(
视频 ):

它还报告说,CERN在2016年10月开始使用Magnum进入生产阶段,并再次强调了对三种编排工具的支持:Kubernetes,Docker Swarm和Mesos。 CERN IT部门的里卡多·罗查(Ricardo Rocha)在其演讲之一(2017年5月在波士顿举行的OpenStack峰会)上
解释了为什么它如此重要:
“ Magnum还允许我们选择一个容器引擎,这对我们来说非常有价值。 鼓吹Kubernetes的人们在组织中工作,但也有一些人已经使用过Mesos,甚至有些人使用普通的Docker,希望继续依赖Docker API,而Swarm在这里具有巨大的潜力。 我们希望实现易用性,而不是要求人们了解复杂的模式来配置集群。”
当时,CERN在Kubernetes上使用了大约40个集群,在Docker Swarm中使用了20个集群,在Mesosphere DC / OS中使用了5个集群。
一年后的2018年5月,情况发生了很大变化。 里卡多和他的同事(Clenimar Filemon)在KubeCon Europe 2018上的
CERN多云联合Kubernetes体验演讲 (
视频 )中,有关使用Kubernetes的新细节变得众所周知。 现在,它不仅是科学组织用户可以使用的容器编排工具之一,而且还是整个基础架构重要的技术,这要归功于联邦,通过将第三方资源(GKE,AKS,Amazon,Oracle ...)添加到自己的能力中,可以显着扩展计算云。
注意 :Kubernetes中的联合身份验证是一种特殊的机制,它通过同步位于多个集群中的资源并自动检测所有集群中的服务来简化多个集群的管理。 其应用程序的实际案例是与分布在不同提供商(其数据中心,第三方云服务)上的各种Kubernetes集群一起使用。从这张幻灯片中可以看到,该幻灯片展示了日内瓦CERN数据中心的一些定量特征...

……该组织的内部基础架构已得到极大发展。 例如,一年中可用内核的数量几乎增加了一倍-已达到32万。 工程师走得更远,合并了几个数据中心,在CERN云中实现了70万个内核的可用性,这些内核并行执行了40万个任务(用于事件重建,检测器校准,模拟,数据分析等)...
但是,在本文的背景下,人们已经对存在210个Kubernetes集群(其大小变化很大(从10到1000个节点))这一事实感到关注。
与Kubernetes联合
但是,欧洲核子研究中心的内部能力并不总是足够的,例如在急剧的负荷爆发时期:在大型国际物理学会议之前以及在进行大型实验重建活动的情况下。 一个需要大量资源的引人注目的用例是CERN批处理服务,该服务约占组织计算资源的80%。
该系统的核心是开放源代码框架
HTCondor ,旨在解决HTC类别的问题(高吞吐量计算)。 StartD守护程序负责其中的计算,该守护程序在每个节点上启动,并负责启动其上的工作负载。 他是在CERN进行集装箱运输的,目的是在Kubernetes上启动并进一步实现联合。
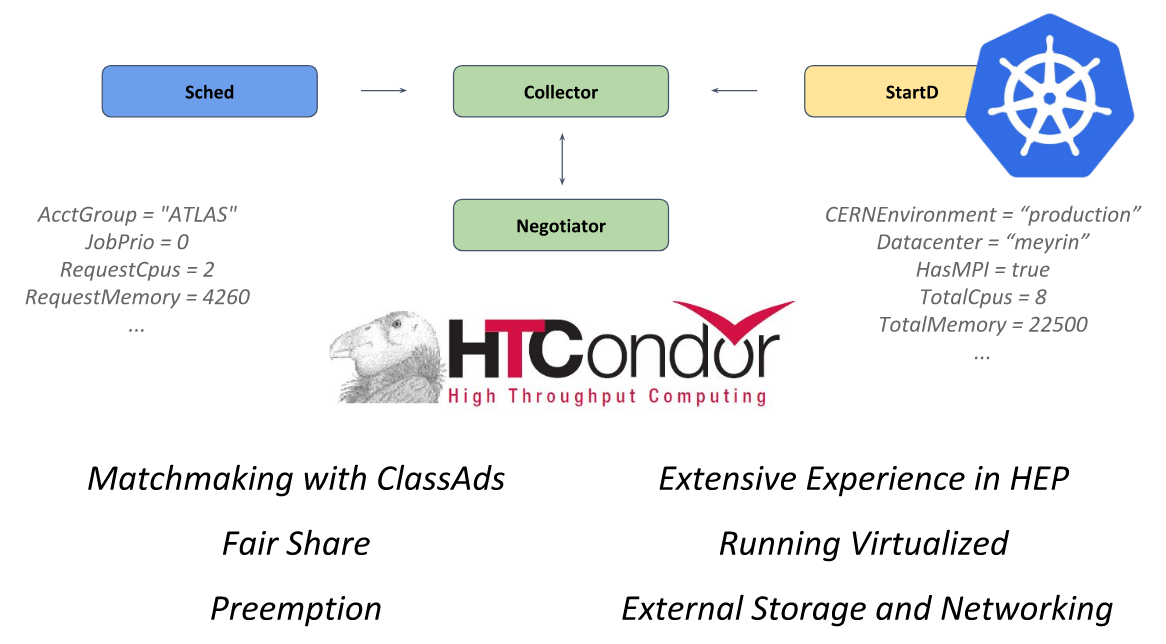 欧洲核子研究组织在KubeCon Europe 2018上的演讲中的HTCondor
欧洲核子研究组织在KubeCon Europe 2018上的演讲中的HTCondor按照这种方式,CERN工程师能够描述单个资源(带有从HTCondor启动
DaemonSet的容器的DaemonSet)并将其部署在所有联合Kubernetes集群的节点上:首先作为其数据中心的一部分,然后连接外部提供商(公共云)来自T-Systems和其他公司):
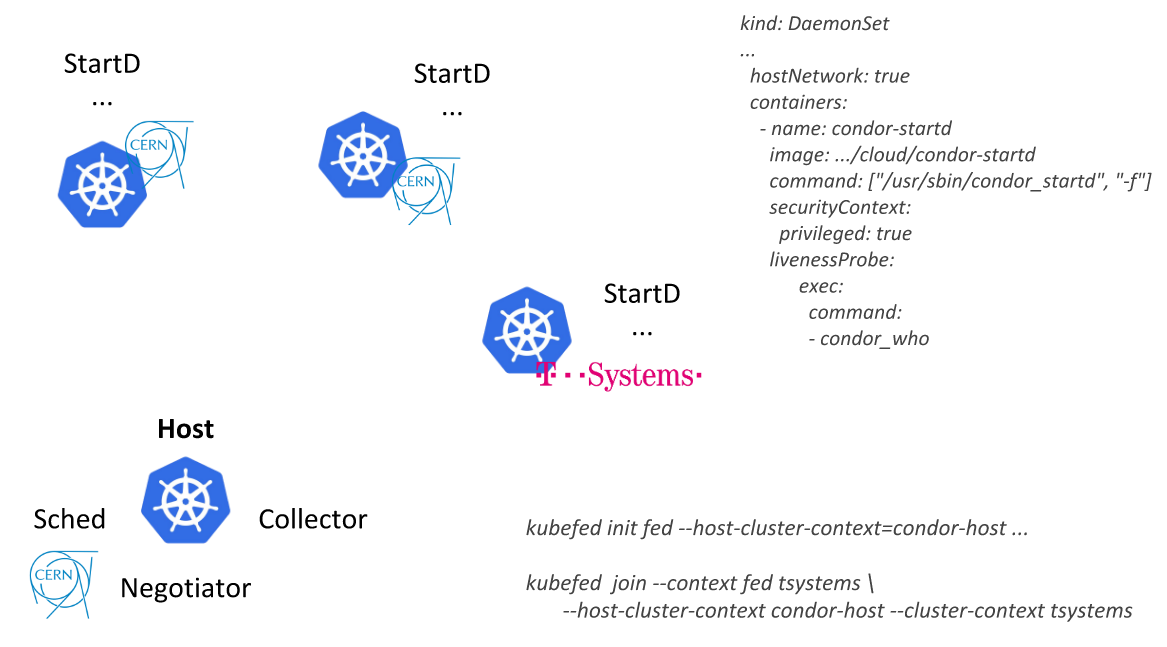
另一个应用程序是基于
REANA ,
RECAST和
Yadage的分析平台。 与CERN Batch Service(该组织中的“已建立”软件)不同,这是一项新的开发,它立即将应用程序的详细信息与Kubernetes一起考虑在内。 该系统中的工作流以将每个步骤转换为
Job for Kubernetes的方式实现。
如果最初所有这些任务都在单个集群上运行,那么随着时间的流逝,请求将增加,并且“今天是我们在Kubernetes中最好的用例联合”。 在里卡多·罗查(Ricardo Rocha)演讲的
片段中 ,观看一段简短的视频,演示他的演示。
聚苯乙烯
有关CERN当前IT使用范围的其他信息,请
访问该组织的网站 。
周期中的其他文章