在我们的Habré博客上,我们出版了The Financial Hacker博客的改编材料翻译,专门讨论有关创建交易所交易策略的问题。 之前,我们讨论了
寻找市场效率低下的问题 ,创建
交易策略模型以及
其编程原理的问题 。 今天,我们
将专注于使用机器学习方法来提高交易系统的效率。
赢得世界象棋冠军的第一台计算机是Deep Blue。 那是在1996年,又过了二十年,另一个程序Alpha Go击败了Go中最好的球员。 Deep Blue是具有嵌入式国际象棋规则的面向模型的系统。 AplhaGo是一个数据挖掘系统,是一个深度神经网络,使用Go中的数千种游戏进行了培训。 就是说,为了在国际象棋冠军上取得胜利,并在Go比赛中占据主导地位,要取得进步,必须改进的不是铁杆,而是软件领域的突破。
在当前的文章中,我们将考虑将数据挖掘方法应用于创建交易策略。 这种方法没有考虑市场机制;它只是扫描价格曲线和其他数据源以搜索预测模式。 并非总是需要机器学习或“人工智能”。 相反,在大多数情况下,最流行和最有利可图的数据挖掘方法可以毫不费力地以神经网络或支持矢量方法的形式工作。
机器学习原理
训练有素的算法会收到通常以某种方式从历史交易价格中提取的数据样本。 每个样本都包含n个变量x1 ... xn,通常称为预测变量,函数,信号或更简单地称为输入数据。 这些预测变量可以是价格图表上最后n条柱的价格或一组经典指标的值,或者价格曲线的任何其他函数(甚至在某些情况下,价格图表的各个像素都被用作神经网络的预测变量!) 每个样本通常还包含某个目标变量y,例如,分析样本后的下一次交易结果或下一次价格变动。
在文献中,y通常被称为标签或物镜。 在学习过程中,算法学习基于预测变量x1 ... xn预测目标y。 系统在过程中“记住”的内容存储在称为模型的数据结构中,该数据结构特定于特定算法(重要的是不要将此概念与财务模型或面向模型的策略相混淆)。 机器学习模型可以是具有使用由学习过程生成的C代码编写的预测规则的函数。 或者它可能是一组与神经网络相关的权重:
训练:x1 ... xn,y =>模型
预测:x1 ... xn,模型=> y
预测变量,函数或任何您想要调用的变量,都应包含足以以一定精度生成有关目标y值的预测的信息。 他们还必须满足两个正式标准。 首先,所有预测值必须在相同范围内,例如-1 ... +1(对于R上的大多数算法)或-100 ... + 100(对于脚本语言Zorro或TSSB的算法)。 因此,在将数据发送到系统之前,您需要对其进行规范化。 其次,样本必须是平衡的,即均匀分布在目标变量的值上。 也就是说,您应该具有相同数量的样本,这些样本会导致阳性结果,并且会丢失结果。 如果不遵循这两个要求,那么好的结果将不会成功。
回归算法会生成有关数值的预测,例如数值或下一次价格走势的迹象。 分类算法可预测样本的定量类别,例如,样本是否在资金损益之前。 某些算法(例如神经网络,决策树或支持向量法)可以在两种模式下运行。
还有一些算法可以学习从类样本中提取,而无需目标y。 与监督学习相反,这称为无监督学习。 这两种方法之间的某个地方位于“强化学习”中,在该系统中,系统通过运行具有指定功能的模拟进行训练并将结果用作目标。 AlphaGo的追随者,一个名为AlphaZero的系统,使用了强化学习功能,自己玩了100万个Go游戏。 在金融领域,很少使用无监督学习的系统或产品。 99%的系统使用监督学习。
无论我们将哪些信号用作财务预测指标,在大多数情况下,它们都将包含很多噪音和很少的信息,此外,它们还会不稳定。 因此,财务预测是机器学习最困难的任务之一。 这里更复杂的算法可获得更好的结果。 预测变量的选择对于成功至关重要。 不一定应该有很多,因为这会导致重新培训和故障。 因此,数据挖掘策略通常使用预选算法,该算法将从较宽的池中提取少量预测变量。 这样的初步选择可以基于预测变量之间的相关性,预测变量的重要性,信息丰富度,或者仅基于使用测试套件的成功/失败。 例如,可以在
Robot Wealth博客上找到有关选择目标的实际实验。
以下是在金融领域中使用的最受欢迎的数据挖掘方法的列表。
1.指标汤
大多数交易系统都不基于财务模型。 通常,交易者仅需要由某些技术指标生成的交易信号,这些信号就会被其他指标与其他技术指标结合过滤。 当问一个交易者这种指标的混杂如何带来某种利润时,他通常会回答:“相信我,我进行交易,一切都会起作用。”
这是真的。 至少有时。 尽管这些系统中的大多数都无法通过
WFA测试 (有些仅通过历史数据进行测试),但出乎意料的是,大量此类系统最终都可以工作并从中获利。 博客Financial Hacker的作者从事定制交易系统的开发,并讲述了一个客户的故事,该客户系统地尝试了技术指标,直到找到适合某些类型资产的组合。 这种反复试验的方法是一种经典的数据挖掘方法,要获得成功,您只需要它,运气和大量金钱来进行测试。 结果,有时您可以指望获得有利可图的系统。
2.烛台图案
不要与已有数百年历史的烛台图案混淆。 这种方法的现代等同物是基于价格变动的贸易。 您还可以分析图表中每个蜡烛的开盘价,最高价,最低价和收盘价。 但是现在您正在使用数据挖掘来分析价格曲线的蜡烛,以突出显示可用于生成有关未来价格走势的预测的模式。
有用于此目的的完整软件包。 他们寻找根据用户定义的标准可获利的模式,并使用它们来构建模式检测功能。 所有这些可能看起来像这样:
int detect(double* sig) { if(sig[1]<sig[2] && sig[4]<sig[0] && sig[0]<sig[5] && sig[5]<sig[3] && sig[10]<sig[11] && sig[11]<sig[7] && sig[7]<sig[8] && sig[8]<sig[9] && sig[9]<sig[6]) return 1; if(sig[4]<sig[1] && sig[1]<sig[2] && sig[2]<sig[5] && sig[5]<sig[3] && sig[3]<sig[0] && sig[7]<sig[8] && sig[10]<sig[6] && sig[6]<sig[11] && sig[11]<sig[9]) return 1; if(sig[1]<sig[4] && eqF(sig[4]-sig[5]) && sig[5]<sig[2] && sig[2]<sig[3] && sig[3]<sig[0] && sig[10]<sig[7] && sig[8]<sig[6] && sig[6]<sig[11] && sig[11]<sig[9]) return 1; if(sig[1]<sig[4] && sig[4]<sig[5] && sig[5]<sig[2] && sig[2]<sig[0] && sig[0]<sig[3] && sig[7]<sig[8] && sig[10]<sig[11] && sig[11]<sig[9] && sig[9]<sig[6]) return 1; if(sig[1]<sig[2] && sig[4]<sig[5] && sig[5]<sig[3] && sig[3]<sig[0] && sig[10]<sig[7] && sig[7]<sig[8] && sig[8]<sig[6] && sig[6]<sig[11] && sig[11]<sig[9]) return 1; .... return 0; }
当信号与模式之一匹配时,此C函数返回1,否则返回0。长代码似乎暗示这不是搜索模式的最快方法。 最好使用一种方法,其中不需要导出检测功能,但是可以根据信号的重要性对其进行排序并对其进行排序。 可以
在链接中找到此类系统的示例。
可以按价格交易吗? 与以前的情况一样,此方法也不基于任何理性的财务模型。 同时,每个人都知道,市场中某些特定事件确实会影响其参与者,因此会出现短期预测模式。 但是,如果仅研究图表上几个连续蜡烛的序列,则此类模式的数量就不会很大。 然后,您需要将结果与蜡烛的数据进行比较,蜡烛的数据不在附近,相反,蜡烛是在更长的时间内随机选择的。 在这种情况下,您将获得几乎无限数量的模式-并成功脱离了现实和理性的概念。 很难想象如何根据上周的某些价格来预测未来价格。 尽管如此,许多交易者还是朝着这个方向努力。
3.线性回归
许多复杂的机器学习算法的简单基础:使用预测变量x1 ... xn的线性组合来预测目标变量y。

赔率-这是模型。 根据以下公式计算它们,以最小化真实y值,训练值和预测y之间的二次偏差之和:

对于正态分布的样本,可以使用矩阵运算来最小化,因此不需要迭代。 在n = 1-仅具有一个预测变量x的情况下,回归公式简化为:
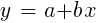
-也就是说,在进行简单线性回归之前,并且当n> 1时,线性回归将是多变量的。 在大多数交易平台上都可以使用简单的线性回归,例如TA-Lib中的
LinReg指标。 当y =价格而x =时间时,它可以用作移动平均线的替代方法。 在R平台中,这种回归是通过标准传递函数lm(..)实现的。 也可以用多项式回归表示。 与最简单的情况一样,这里我们使用一个预测变量x,还使用其平方和后续度数,因此xn == xn:
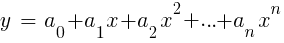
如果n = 2或n = 3,则通常使用多项式回归从最后一个柱的平滑价格中预测下一个平均价格。 对于多项式回归,可以使用MatLab,R,Zorro和许多其他平台的polyfit函数。
4.感知器
通常将其称为只有一个神经元的神经网络。 实际上,感知器是如上所述的回归函数,但是具有二进制结果,因此将其称为
逻辑回归 。 尽管通常这不是回归,而是分类算法。 例如,Zorro框架的advis函数(PERCEPTRON,...)生成C代码,该代码根据预测结果是否为阈值返回100或-100:
int predict(double* sig) { if(-27.99*sig[0] + 1.24*sig[1] - 3.54*sig[2] > -21.50) return 100; else return -100; }
如您所见,sig数组等效于回归公式中的函数xn,系数an是数字因子。
5.神经网络
线性或逻辑回归只能解决线性问题。 同时,交易任务通常不属于此类别。 一个著名的例子是对简单XOR函数输出的预测。 这也包括对交易利润的预测。 人工神经网络(ANN)可以解决非线性问题。 这是一组感知器,它们连接到不同级别的阵列中。 每个感知器都是一个网络神经元。 它的输出成为以下级别的其他神经元的输入:
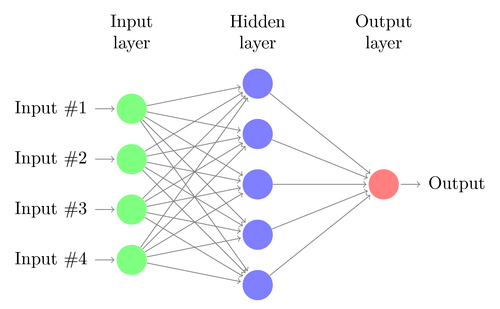
像感知器一样,通过确定最小化预测值和样本中目标之间误差的系数来训练神经网络。 这需要一个近似过程,通常是误差从输出到输入的反向传播,并且沿途优化了权重。 此过程有两个限制。 首先,神经元的输出应该是连续可微的功能,而不是感知器的简单阈值。 其次,网络不应太深-输入和输出数据之间存在大量隐藏级别的神经元只会对人造成伤害。 第二个限制限制了标准神经网络可以解决的问题的复杂性。
当使用神经网络预测交易时,您将拥有很多可操纵的参数,如果参数做得不正确,则会导致选择偏见的出现:
- 隐藏层数;
- 每个隐藏层中的神经元数量;
- 反向传播周期数-历元;
- 培训程度,时代步伐;
- 动量,权重的惯性因子;
- 激活功能。
激活功能模拟感知器阈值。 对于反向传播,您需要一个不断微分的函数,该函数可为某个x值生成一个软步。 通常,使用S型,tanh或softmax函数。 有时会使用线性函数来返回所有输入数据的加权和。 在这种情况下,该网络可用于回归,数值预测而不是二进制输出。
神经网络包含在R的标准程序包中(例如,nnet是具有一个隐藏级别的网络),以及许多其他程序包(例如RSNNS和FCNN4R)中。
6.深度学习
深度学习方法使用具有许多隐藏级别和数千个神经元的神经网络,这些神经元无法通过简单的反向传播进行有效训练。 近年来,用于训练这样的大型网络的几种方法变得流行。 它们通常涉及对神经元隐藏水平的预训练,以提高基础学习的有效性。
受限玻尔兹曼机(RBM)是一种具有特殊网络结构的不受控制的分类算法,其中隐藏神经元之间没有连接。 稀疏自动编码器(SAE)使用通常的网络结构,但以特定的方式预训练隐藏层,以尽可能少的活动连接在输出级别上再现输入信号。 这些方法使您可以实施非常复杂的网络来解决非常复杂的学习问题。 例如,击败玩Go的最佳人选的任务。
深度学习网络包含在R的deepnet和darch软件包中。Deepnet包含自动编码器,而darch包含Boltzmann机器。 下面是一个示例代码,该代码使用具有三个隐藏级别的Deepnet通过Zorro框架的neor()函数处理交易信号:
library('deepnet', quietly = T) library('caret', quietly = T) # called by Zorro for training neural.train = function(model,XY) { XY <- as.matrix(XY) X <- XY[,-ncol(XY)] # predictors Y <- XY[,ncol(XY)] # target Y <- ifelse(Y > 0,1,0) # convert -1..1 to 0..1 Models[[model]] <<- sae.dnn.train(X,Y, hidden = c(50,100,50), activationfun = "tanh", learningrate = 0.5, momentum = 0.5, learningrate_scale = 1.0, output = "sigm", sae_output = "linear", numepochs = 100, batchsize = 100, hidden_dropout = 0, visible_dropout = 0) } # called by Zorro for prediction neural.predict = function(model,X) { if(is.vector(X)) X <- t(X) # transpose horizontal vector return(nn.predict(Models[[model]],X)) } # called by Zorro for saving the models neural.save = function(name) { save(Models,file=name) # save trained models } # called by Zorro for initialization neural.init = function() { set.seed(365) Models <<- vector("list") } # quick OOS test for experimenting with the settings Test = function() { neural.init() XY <<- read.csv('C:/Project/Zorro/Data/signals0.csv',header = F) splits <- nrow(XY)*0.8 XY.tr <<- head(XY,splits) # training set XY.ts <<- tail(XY,-splits) # test set neural.train(1,XY.tr) X <<- XY.ts[,-ncol(XY.ts)] Y <<- XY.ts[,ncol(XY.ts)] Y.ob <<- ifelse(Y > 0,1,0) Y <<- neural.predict(1,X) Y.pr <<- ifelse(Y > 0.5,1,0) confusionMatrix(Y.pr,Y.ob) # display prediction accuracy }
7.支持向量
与神经网络一样,支持向量法是线性回归的另一种扩展。 如果再次查看回归公式:
然后,可以将函数xn解释为n维空间的坐标。 将目标变量y设置为固定值将确定该空间中的平面-称为超平面,因为实际上它的大小为两个(甚至为n-1)。 超平面将y> 0的样本与y <0的样本分开。可以将系数a计算为将平面与最近的样本(其支持向量)分开的路径。 因此,我们获得了具有最佳样本的最佳分类的二元分类器。
问题:通常无法将这些样本线性划分-将它们随机分组在函数空间中。 在获胜和失败选项之间绘制一个平滑的平面是不可能的;如果可以做到,则可以使用更简单的方法(例如线性判别分析)进行计算。 但是在一般情况下,您可以使用技巧:在空间中增加更多大小。 在这种情况下,支持向量算法将能够通过结合任意两个预测变量的核函数来生成更多参数-与从简单回归到多项式的转换类似。 添加的大小越多,就越容易用超平面分割样本。 然后可以将其转换回原始的n维空间。
像神经网络一样,参考向量不仅可以用于分类,而且可以用于回归。 他们还提供了许多优化和可能的再培训选项:
- 内核函数-通常使用RBF内核(径向基函数,对称内核),但可以选择其他内核,例如S形,多项式和线性。
- 伽玛-RBF铁心宽度。
- 成本参数C,“罚款”,用于错误分类训练样本。
经常使用libsvm库,该库在R的e1071软件包中可用。
8. k最近邻算法
与繁重的ANN和SVM相比,这是一种简单而令人愉悦的算法,具有独特的属性:不需要训练。 样品将成为模型。 该算法可用于通过添加新样本不断进行培训的交易系统。 该算法计算从当前值到k个最近样本的函数空间中的距离。 两组(x1 ... xn)和(y1 ... yn)在n维空间中的距离由以下公式计算:
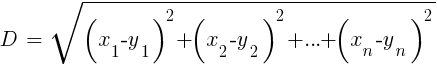
该算法仅根据最近样本的k个目标变量的平均值来预测目标,并以它们的返回距离加权。 它可以用于分类和回归。 要预测最近的邻居,可以为此目的在R中调用knn函数或自己编写C代码。
9. K-均值
这是用于不受控制的分类的近似算法。 它有点类似于先前的算法。 为了对样本进行分类,该算法首先将k个随机点放置在函数空间中。 然后,他将距离最短的所有样本分配给这些点之一。 然后,点移动到这些最近值的中间。 这将生成新的示例绑定,因为其中一些绑定现在将更接近其他点。 重复该过程,直到由于点移动而导致的重新参考停止为止,也就是说,直到每个点均是最近样本的平均值为止。 现在我们有k个样本类,每个样本类都位于k点旁边。
这个简单的算法可以产生令人惊讶的良好结果。 在R中,使用kmeans函数来实现它;可以
在link上找到该算法的示例。
10.朴素贝叶斯
该算法使用贝叶斯定理对非数字函数(事件)的样本进行分类,例如上述蜡烛图案。 假设事件X(例如,当前条的Open参数下方的上一个条的Open参数)出现在80%的获胜样本中。 那么在事件X存在的情况下赢得样本的概率是多少? 您可能会认为这不是0.8。 此概率由以下公式计算:
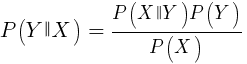
P(Y | X)是所有包含X事件的样本中Y事件(利润)发生的概率(在我们的示例中,Open(1)<Open(0))。 根据公式,它等于所有获胜样本中事件X发生的概率(在我们的示例中为0.8),乘以所有样本中事件Y的概率(如果遵循平衡样本的技巧,则为约0.5),再除以X在事件中出现的概率所有样本。
如果我们很幼稚并假设X的所有事件彼此独立,那么我们可以通过简单地将每个事件X的概率P(X |获胜)相乘来计算样本获胜的总概率。然后我们得出以下公式:
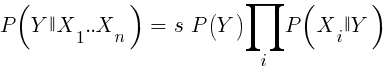
带有比例因子s。 为了使公式起作用,必须以尽可能独立的方式选择函数。 这将成为使用朴素贝叶斯进行交易的障碍。 例如,关闭(1)<关闭(0)和打开(1)<打开(0)这两个事件很可能彼此不独立。 通过将数字划分为不同的范围,可以将数字预测变量转换为事件。 Naive Bayes可用于R的软件包e1071中。
11.决策树和回归树
这样的树根据决策链中的是/否格式在树枝结构中预测数值的结果。 每个决策代表事件的存在与否(在非数字值的情况下)或具有固定阈值的值的比较。 例如,由Zorro框架生成的典型树函数如下所示:
int tree(double* sig) { if(sig[1] <= 12.938) { if(sig[0] <= 0.953) return -70; else { if(sig[2] <= 43) return 25; else { if(sig[3] <= 0.962) return -67; else return 15; } } } else { if(sig[3] <= 0.732) return -71; else { if(sig[1] > 30.61) return 27; else { if(sig[2] > 46) return 80; else return -62; } } } }
如何从一组样本中获得这棵树? 为此,可以有几种方法,包括
香农的信息熵 。
决策树可以被广泛使用。 例如,它们适合于生成比使用神经网络或参考矢量可以实现的预测更准确的预测。 但是,这不是通用解决方案。 这种类型的最著名算法是C5.0,可在C50软件包中找到R。
为了进一步提高预测质量,您可以使用树集-它们被称为随机森林。 R包中提供了该算法,这些包称为randomForest,ranger和Rborist。
结论
数据挖掘和机器学习有很多方法。 这里的关键问题是:哪种更好的,基于模型的或机器学习的策略? 毫无疑问,机器学习具有许多优势。 例如,您无需关心市场的微观结构,经济状况,也无需考虑市场参与者的哲学或其他类似事物。 您可以专注于纯数学。 机器学习是创建交易系统的一种更为优雅和有吸引力的方式。 在他的方面,除了一个优点以外,所有优点都具有优势-除了交易者论坛上的故事外,这种方法在真实交易中的成功很难追踪。
几乎每个星期,都会发布有关使用机器学习进行交易的新文章。 此类材料应引起相当多的怀疑。 一些作者声称出色的胜率达到70%,80%甚至85%。 但是,很少有人说,即使预测成功了,您也可能会亏钱。 85%的准确性通常会转化为高于5的获利能力指标-如果一切都如此简单,那么该系统的创建者就已经成为亿万富翁。 但是,由于某些原因,仅通过重复文章中描述的方法来重现相同的结果将失败。
与基于模型的系统相比,很少有真正成功的机器学习系统。 例如,成功的对冲基金很少使用它们。 也许在将来,当计算能力变得更加可访问时,某些事情将会改变,但是到目前为止,对于交易所迷来说,深度学习算法仍然是更有趣的业余爱好,而不是交易所中真正的赚钱工具。