
坐在Odnoklassniki的机器学习和数据分析之间有什么区别,以及如何开始您的机器学习之旅-我们在第十二期面向程序员的脱口秀中谈到了这一点。
在Technostream频道上的视频该计划的主持人是媒体项目技术总监Pavel Shcherbinin,来宾是Odnoklassniki的分析师Dmitry Bugaychenko。
00:56 Dmitry Bugaychenko:从外包到确定和科学活动
02:42为什么将大学和大公司的工作结合起来
02:57在哪里可以应用机器学习
03:49机器学习和数据分析-有什么区别?
05:08截屏视频“我们借助数据分析来分析受众群体”
22:34同学们约会吗?
24:07从哪里开始学习机器学习?
25:33我应该参加机器学习锦标赛吗?
26:53如何在OK中练习
28:18机器学习手册
30:28机器学习活动
32:48数据管道的排列
方式如何(在板上显示)
43:42闪电战民意调查
谈谈自己。我们可以假设我的职业道路始于1999年,当时我进入数学专业。 五年来,他积极研究数学,编程和各种相关学科。 然后,他在一家外包公司工作了相当长的时间。 外包是非常有趣的经历。 从编写冰箱驱动程序到创建分布式企业系统,我设法参与了许多项目。
所有这些时间,除了主要工作,我还在大学任教,以保持与学术界的联系,这是非常困难的。 当我在2011年应邀去Odnoklassniki从事推荐系统时,这是一个很好的机会,我对此加以利用。 在这里,可以将大学的数学准备与编程的实际经验结合起来。 但是,我继续在大学任教。
教学需要很多时间吗?每周上大学1.5天,但这是值得的,因为我们已经有三位以前的学生在工作。 也就是说,大学是人才的伪造。
在工作中,与您离开1.5天这一事实有关系吗?辞职 每个人都知道从中获利,所以我没有遇到任何反对。
告诉我Odnoklassniki在哪里使用机器学习。我们有很多应用。 从历史上看,第一个机器学习系统是音乐推荐。 这一切都始于2011年。 然后就是爆炸性的增长:社区的推荐,朋友的推荐,“也许彼此了解”,试图对用户的供稿中的内容进行排名。 现在正在开发许多项目。 无论您拨动Odnoklassniki的哪一部分,都有与机器学习或数据分析相关的组件。
帮助我们的读者区分这两个概念:机器学习和数据分析。一个人对数据进行分析,以找到一些模式,联系,检验一些假设。 为此,使用了各种数学统计方法。 机器学习是一种使用模式的更高级方法,该方法通常使用基于具有大量参数的某种大型,复杂模型的技术。
我们正在尝试选择该模型的参数,以便它很好地描述我们需要的现象。 有许多不同的算法,枚举参数的方法,但是所有这些都是为了发现某些规律性而进行的。 例如,根据社交网络上某个帖子的数据,评估特定人员对该帖子发表“课程”的可能性。 也就是说,机器学习是用于数据分析的工具。
您和我能否揭穿关于Odnoklassniki的神话之一,根据这个神话,这个观众的年龄非常老?没问题 这是一张实时反映每个特定用户登录信息的地图。 也就是说,每个点都是登录并在Odnoklassniki中做某事的人。
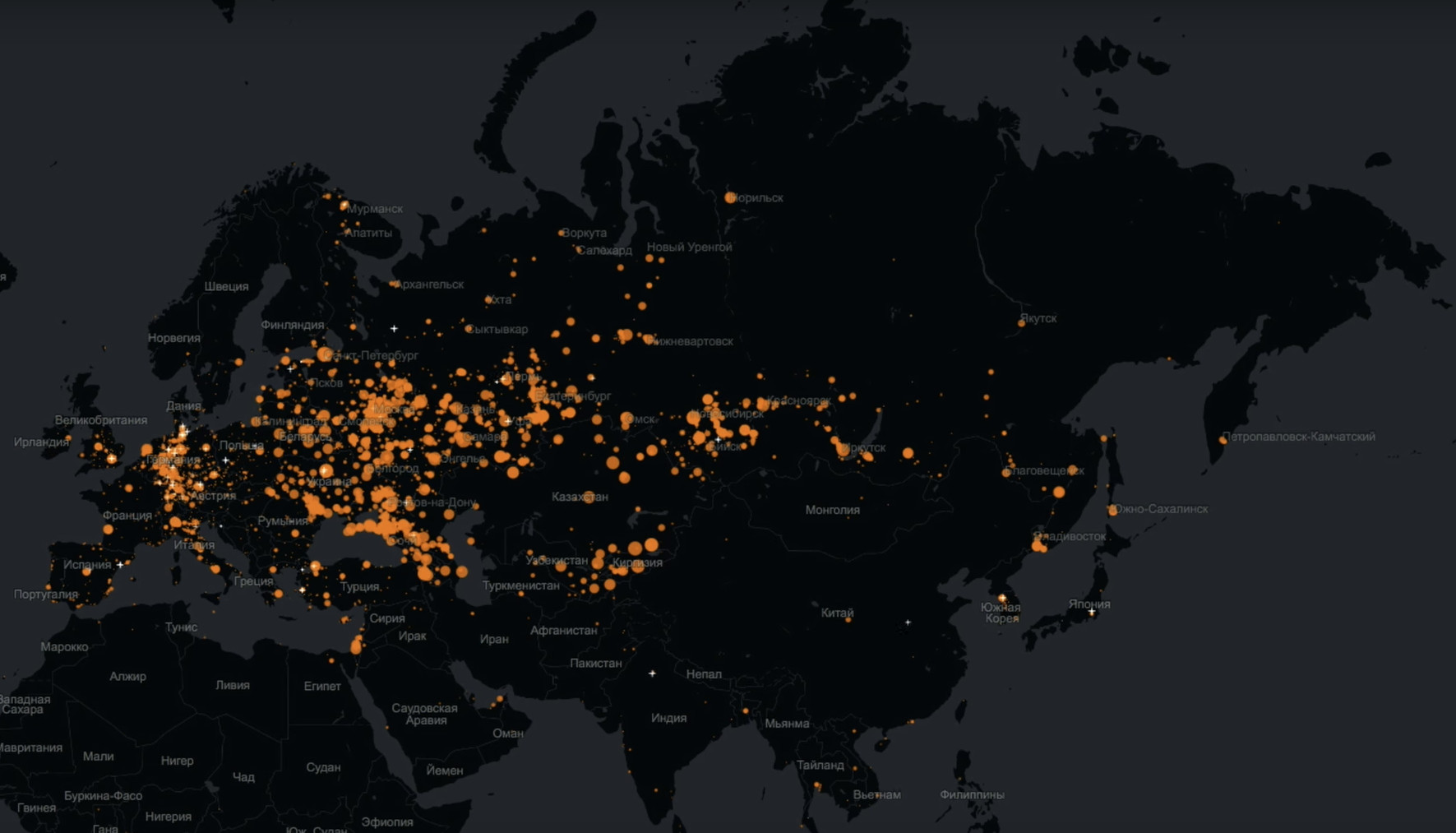
大红色圆圈是许多用户来到我们的城市。 在这里非常清楚地看到,Odnoklassniki不仅活着,而且几乎覆盖了整个欧亚大陆。
让我们计算昨天有多少用户在Odnoklassniki中放置了“班级”,并查看了年龄分布。
编码从哪里开始? 当然,可以从导入各种有用的数据以供将来进行汇总计算。 我们的主要工具是
Spark ,使用
Zeppelin Web Front可以访问。 基本上,数据通过
Apache Kafka打包并打包成不同的块。 在这种情况下,我们对描述昨天用户活动(特别是课程)的块感兴趣。 有一个存储用户人口统计信息的字段,包括生日。

输出是前十个记录的出生年份。 现在,让我们尝试从中构建一些汇总。 我们要计算唯一身份用户的数量。 我们需要ID和出生年份,并按年份分组并计算唯一身份用户的数量。 让我们玩一下:肯定会有未标明出生年份的人,因此我们将其过滤掉,以免他们在图表上产生噪音。
为了进行计算,系统需要铲除大约1 TB的数据。 我们得到结果并以图形方式呈现:

年龄高峰出现在1983年-35岁。 那对他们来说是相当老的用户。
为了更好地表示情况,没有来自一个来源的足够信息。 如果我们谈论的是用户人口统计数据,那么最有趣的比较来源是俄罗斯人口统计数据。 我从
Rosstat网站下载了2016年收集的俄罗斯人出生年份的数据。
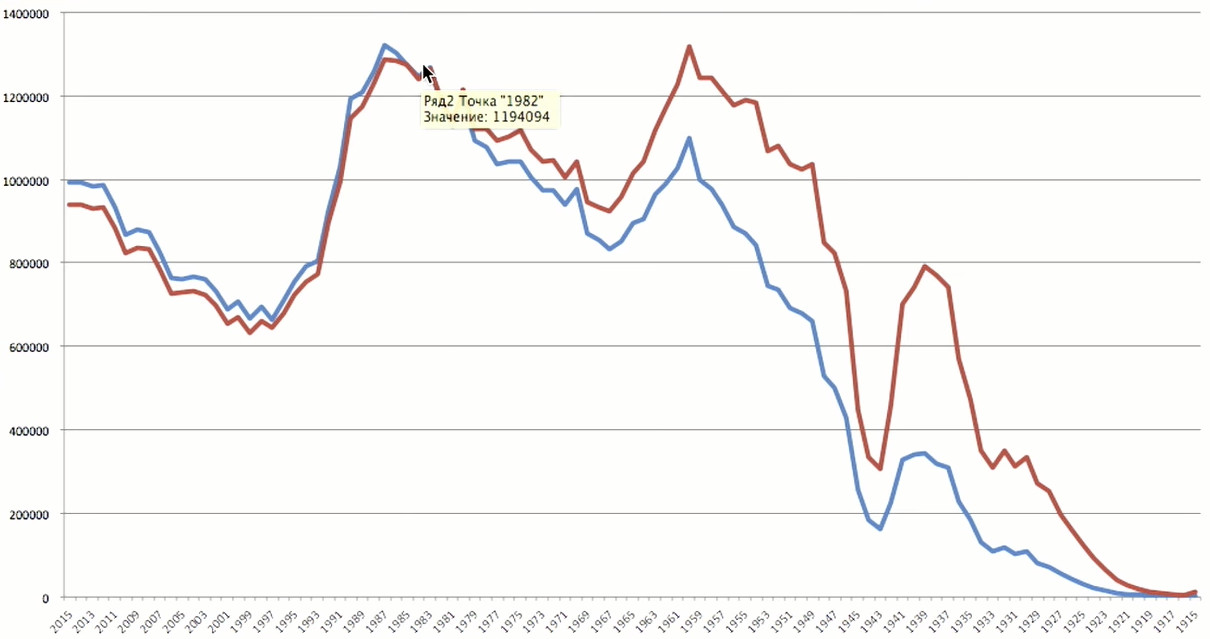
根据Odnoklassniki的说法,统计数据的峰值非常接近峰值-我们的用户分别出生于1983年和Rosstat-1987年。 让我震惊的是两次重大失败。 1940年代初期的大战是伟大的卫国战争。 战争不仅使我们丧生超过2000万,而且使数百万未出生的人丧生。 这是仍在感觉的人口统计问题。 第二个坑-1990年代。 我们还没有从这场危机中完全康复。 我们在Odnoklassniki的数据中看到了相同的图片:1990年之后,下降幅度很大。 我们仍然无法在2015年出生,因为注册的最低年龄为5岁。
将性别属性添加到我们的样本并不仅按年份,而且按性别分组。
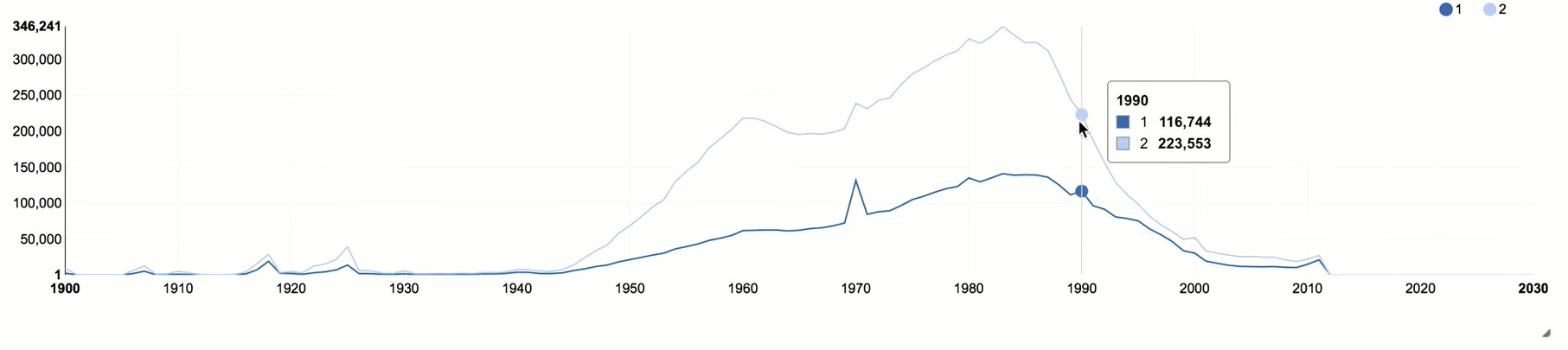
1990年之后,急剧下降,这与俄罗斯的总体年龄状况有关。 妇女对“阶级”的投入更为积极,几乎是男子的两倍。 对于社交网络,这是相当典型的情况,因为女性比男性更活跃于社交活动。
您还可以注意与“整年”相关的几个高峰。 根据这些高峰,可以评估机器人或故意扭曲年龄的人的影响,因为在这种情况下,它们通常表示某种日期。
我们也对用户的地理分布感兴趣。 我们需要一个用户ID来计算唯一身份访问者,并在配置文件中指出居住地址。 按城市分组并计算单位。 按用户数降序排序,仅保留前200个城市。 运行聚合:

就设置同学的人数而言,这是排名最高的城市。 自然,莫斯科处于领先地位。 俄罗斯的南部要比西北部好得多。 我们在美国,加拿大,德国很多,以色列很多都有用户。 有趣的事实:来自南萨哈林斯克的3.6万人每天都喜欢。 根据维基百科,总共有18万人居住在城市中。 南萨哈林斯克人口的20%去了Odnoklassniki,并被定为“阶级”。

放大并查看在莫斯科和莫斯科地区会发生什么。

在Odnoklassniki中,乌克兰的中亚共和国,摩尔多瓦的代表非常丰富。

您可以立即看到他们试图阻止访问我们的社交网络的位置,而没有阻止。
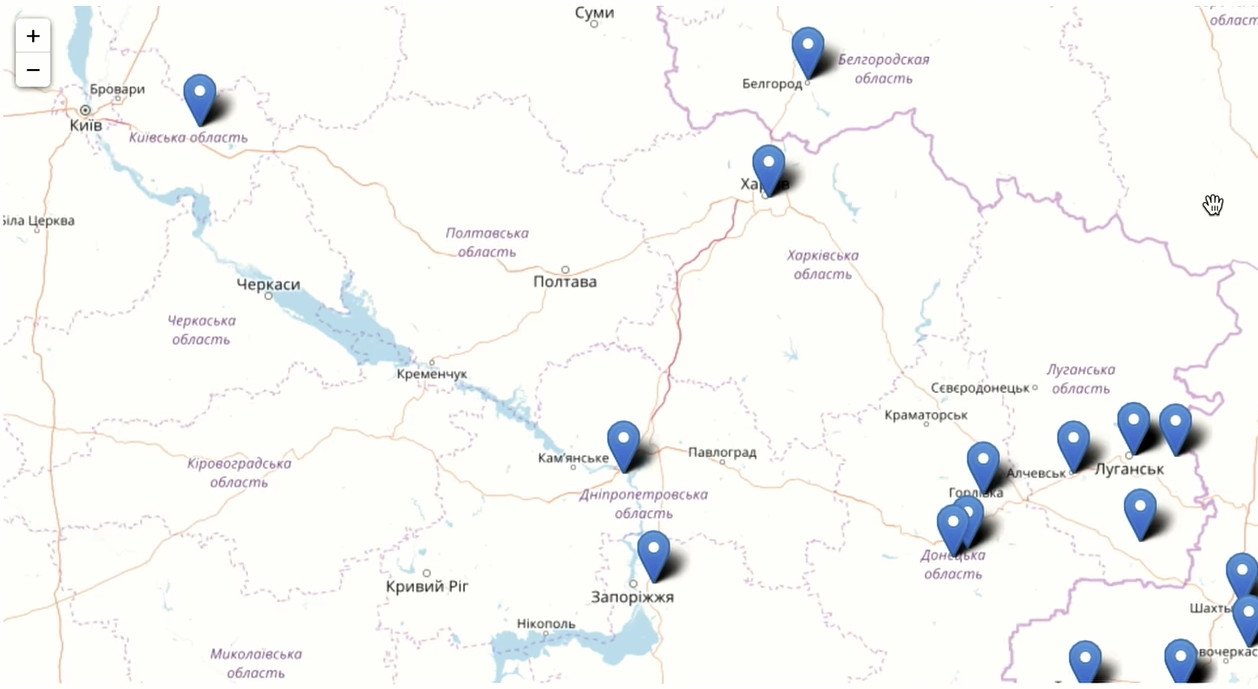
如您所见,Odnoklassniki是一种活泼,充满活力的产品,在全世界的年轻人和老年人中都有使用,有时甚至是您所不希望的地方。 在所有年龄段中,我们年龄最大的是30岁。
社交网络围绕社区构建。 通常,如果一个社区进入了某个社交网络,那么它对其他社交网络的了解就很少。 因此,例如,新闻工作者的专业团体可能会幻想Odnoklassniki主要是老年人。 实际上,这是某些社区的主观意见。 我们的用户年龄在50至60岁之间,有小学生,有20岁的青年,有成熟的30-35岁的人。
Odnoklassniki覆盖俄罗斯,邻国,乌克兰,白俄罗斯,中亚的所有地区。 我们有很好的代表性侨民,例如,俄罗斯侨民的德国侨民,美国侨民和以色列人。 他们与留在俄罗斯和前苏联共和国的亲戚进行了非常积极的沟通。 从这个角度来看,Odnoklassniki很好地促进了社交网络的基本功能的实现-维持彼此居住的人们之间的联系。
有一种观点认为,Odnoklassniki对许多人如此有吸引力,因为它是结识朋友和亲朋好友的一种简便方法。 也就是说,Odnoklassniki被提供为约会服务。 这种约会方式和Odnoklassniki意识形态的一部分是多少?满足包括异性在内的其他人的需求是人类的基本需求。 自然地,它在任何社交网络中表达。 但是在Odnoklassniki中,它的表达不亚于其他社交网络。 我们不重视约会服务。 我们的社交网络发展的思想基于人与人之间交流的共同价值。 对于我们来说,是不是已经分散到不同城市的同学,还是正在寻找伴侣的人,对我们来说并不重要。 两种选择都非常适合我们。 我们很高兴人们找到彼此并进行交流。 但仅此而已
您要做很多机器学习。 现在,这个话题激发了许多人。 从哪里开始,如何进入这个行业?首先,您需要了解一些知识。 这样做没有问题,
Coursera ,
Stepik和某些大学课程中都有精美的课程,它们提供了很好的机器学习基础知识。 要真正加入这个领域,您需要一个目标并了解可以在哪里应用它。 因为仅听抽象课程远不能像您真正解决一个问题一样有效。
对于学生而言,理想的选择是学期论文,学位论文。 即使在这种情况下,我也尽量不要放任自流,而是要帮助学生提出想法,他们会更有动力。
也就是说,设定目标之后,听在线课程,然后尝试应用知识。 一切都会结果。
在我看来,今天有足够的任务。 来自Sberbank,Tinkoff和许多其他公司的大量比赛都在吃喝玩乐中进行。当然可以 但是,它们首先将重点放在已经紧密从事机器学习的人员上。 而且,在这样的比赛中,人们经常观察到的不是机器学习,而是仇恨。 在吃喝玩乐上训练的那些模型将无助于解决实际问题,因为它们驱动了太多参数。 结果,这些模型专门针对撞柱游戏的特定比赛,只有在其中才能获得任何结果。 如果将这些模型转移到现实世界中,它们将无法工作。
最佳实践是实践。 如何与您的团队一起练习?有很多方法。 如果我们谈论研究团队,那么我们有一个名为“ OK数据科学实验室”的项目,我们在其中向想要发展与机器学习和数据分析有关的想法的人们提供计算资源,数据,我们的知识和经验。 并不一定是社交网络。 例如,我们进行了一项研究,作者试图了解现代学童最感兴趣的事物。
如果您是专家并且正在寻找工作,我们总是有许多与机器学习相关的空缺。 请访问我们进行采访。
有书籍,机器学习的读者吗?这是一个瞬息万变的领域,以至于写一本机器学习书籍或阅读器都过于雄心勃勃。 我可以推荐经典著作“
统计学习要素 ”。 这是起源于统计学的关于机器学习的最基本方法。
Sergey Nikolenko出版了一本有关深度机器学习的书。我认为,深度学习不是从哪里开始。 如果您已经拥有经典的机器学习,那么这是一个不错的选择。 但是,如果您还不了解经典技术,那么立即开始深度学习是错误的,因为它经常使研究人员摆脱问题,这是一个非常强大的工具。 在应用它之前,您需要以更简单的方式“手动”分析问题。 然后只有在了解了主题领域的基础上,才能进行深度学习。 否则,您的模型将学习,但您不会。 当您变得比模型更笨时,说得一点一点就是无效。 您无法进一步开发模型,这是一个死胡同。 因此,最好先掌握经典ML。 这并不意味着您需要花费数年,很可能在合理的时间内掌握。
您有机器学习活动吗?我们有一系列的
SNA Hackathon hackathon。 到目前为止,已经过去了两次。 黑客马拉松第一次专门用于分析文本并试图预测特定帖子将获得多少“班级”。 第二次黑客马拉松于一年前举行,专门用于图形分析。 有很多有趣的事件。 我们提供了一些用户“友谊”的信息,这似乎是一小块大约1 GB的数据。 但是,当想要发送预测的参与者尝试与他合作时,几乎没有人成功,即使在具有16 GB和32 GB内存的机器上,所有内容都掉了,飞快地掉了下来,不想工作。 我们甚至不得不匆忙解释如何处理数据以及如何不使用数据。
事实证明,即使是相当高级的机器学习专家,也早已扎根,并开始忘记编程的基本原理。 忘记装箱是什么,哈希表的结构如何,如果使用哈希表,则可能有多少内存开销。 如果您不考虑所有这些,而是直接使用Python,Java或Scala进行操作,则将描述所描述的问题。 我们用Python进行了演示,其他语言也一样。 可以容纳200 MB内存的4000万个链接的图形在20 GB时急剧爆炸,仅仅是因为您忘记了基本数据结构的工作原理。 当时非常令人印象深刻。 即使您是机器学习专家,也不应忘记编程的基础知识。
您的数据处理工作流程如何安排?用户与我们产品的整个生态系统进行交互。 我们可以有条件地区分两个级别:前端应用程序(移动应用程序,门户,移动版本,各种其他应用程序)和业务逻辑。 前端通常与用户进行交互并且可以访问数量非常有限的服务器,因此业务逻辑中有一些特殊的方法允许前端记录数据。
该数据落入Apache Kafka单数据总线。 这已成为一种用于收集原始数据的行业标准。 自然,在Kafka中分析原始数据很困难,因此它们会定期传输到大型Hadoop。 有人可能会说Hadoop是上个世纪,现在是Spark规则。 但是Hadoop是一个平台,您可以在该平台上运行许多工具。 我们在Hadoop之上有多种分析工具。 我经常采用这种分类:
- 数据输入方式 。
- 批处理。 您需要以某种方式处理一些数据。
- 流处理。 您可以使用直接来自流(在本例中为我们的Kafka)的实时数据。
如果在批处理期间可能存在非常严重的延迟-我们在白天收集了统计信息,而您在夜间进行了模型训练,那么在流处理的情况下,延迟是以接收数据和处理数据之间的秒数为单位进行度量的。
- 运营分析 。 这是过程控制和监视。 服务生产,它应该自己工作,无需人工干预。
- 交互式分析 。 一个人做什么。 反应的速度在这里很重要:他们做了一些事情,得到了结果。
在这些细分市场中,我们都有自己的产品生态系统。 例如,批处理操作分析主要使用经典的MapReduce,Apache Tez和一些Spark。 如果我们正在谈论交互式批处理分析,则这些是Spark SQL以及脚本语言Pig和Hive。
当然,没有明确的界线,因为一些交互式语言通常用于批量操作分析。
对于运营流分析,我们使用Apache Samza。这是基于LinkedIn平台的有趣开发。我们在2014年推出了它。对于流的交互式分析,在这里我们使用Spark Streaming,并将其与Web界面集成。必须以某种方式在生产中提供分析结果,否则它们不会带来好处。通常,为此,我们使用相同的Kafka,但它有缺点。 Kafka是一个队列,它允许您快速编写大量内容,但不允许按键读取。为了提取按地址写给Kafka的特定密钥的数据,我们开发了一个特殊的Streaming Index应用程序。它从Kafka读取数据,并将其分解为两个基础:内置的Casandra和基于共享内存SMC的大型内置缓存。也就是说,几乎所有操作都主要由缓存执行,我们的命中率非常高,约为99%。并且业务逻辑服务已经与流索引进行通信,从中获取数据并使用它来调整其工作。尤其是,他们下载有关帖子的点击次数和印象数,一个用户将“班级”放给另一个用户的更早数量的信息,等等。也就是说,所有用于选择最相关,有趣的内容的信息。最后,请回答一些闪电问题。您喜欢哪种操作系统?Mac电脑IDE吗?想法。您会选择什么:初创公司或大型公司?创业公司怎么了动力学,新技术。您认为10年后新的IT趋势是什么?我认为这将是一个神经接口,并直接与人脑交互。你缺钱是为了什么?我早就了解了事实:主要是欲望与您的能力相吻合。也许我拥有生活中想要的一切。你有比特币吗?谢天谢地我对比特币持怀疑态度。实际上,一个成熟的核反应堆只能使人们开采比特币。考虑到我们所有的环境问题和能源危机,这显然不是人类所需要的。这是我所听到的最令人信服的答案。您的朋友最常问您关于Odnoklassniki的哪些信息?和记者一样:在Odnoklassniki还剩下多少人。您想成为哪个超级英雄?可能是托尼·史塔克(Tony Stark)。钢铁侠?是的
怎么了技术。