向尊敬的社区致以问候!
重复是学习的源泉,理解解析对于任何程序员来说都是非常有用的技能,因此我想再次提出这个主题,并在本次讨论递归下降(LL)分析时不要做太多形式化(您以后可以随时使用它们)回来)。
正如伟大的D. Strogov所写,“理解就是简化”。 因此,为了了解使用递归下降方法(又名LL解析)进行解析的概念,我们尽可能简化了任务,并手动编写了与JSON类似但格式更简单的解析器(如果您愿意,可以将其扩展为完整的JSON解析器,如果想运动)。 让我们以
剪切字符串的想法为基础来编写它。
在经典书籍和编译器设计课程中,它们通常开始解释解析和解释的主题,并突出几个阶段:
- 词法分析:将源文本分成子字符串数组(令牌或令牌)
- 解析:根据令牌数组构建解析树
- 解释(或编译):以必要的顺序(正向或反向)遍历结果树,并在此遍历的某些步骤执行一些解释或代码生成操作
并非如此因为在解析过程中我们已经获得了一系列步骤,这是对树节点的访问序列,所以以显式形式存在的树本身可能根本不存在,但是我们还不深入。 对于那些想更深入的人,结尾处有链接。
现在,我想对这个相同的概念(LL解析)使用稍微不同的方法,并展示如何基于剪切字符串的思想来构建LL分析器:在解析期间从原始字符串中剪切片段,片段变小然后解析暴露了其余部分。 结果,我们得出了递归下降的相同概念,但是所用的方式与通常的方式略有不同。 也许这条路径将更方便理解该思想的本质。 如果不是这样,那么仍然有机会从另一个角度看待递归下降。
让我们从一个简单的任务开始:一行包含定界符,我想为其值编写一个迭代。 类似于:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
怎么办呢? 标准方法是使用String.split(在Java中)或names.split(“,”)(在javascript中)将定界的字符串转换为数组或列表,并已经在数组中进行迭代。 但是,让我们想象一下,我们不希望或者不能使用到数组的转换(例如,如果我们使用AVAJ ++编程语言进行编程,那会突然出现,因为其中没有“数组”数据结构)。 您仍然可以扫描字符串并跟踪定界符,但是我也不会使用此方法,因为它会使迭代循环代码变得繁琐,而且最重要的是,它与我想展示的概念背道而驰。 因此,我们将以与函数编程中的列表相同的方式涉及一个定界字符串。 并且它们总是在其中定义函数的头(获取列表的第一个元素)和尾部(获取列表的其余部分)。 从Lisp的第一种方言开始,这些函数被绝对可怕且非直观地称为:car和cdr(car =地址寄存器的内容,cdr =递减寄存器的内容。old的传说很深,是的,eheheh。)
我们的线是定界线。 用紫色突出显示分隔线:
并以黄色突出显示列表项:

我们假设我们的行是可变的(可以更改)并编写一个函数:
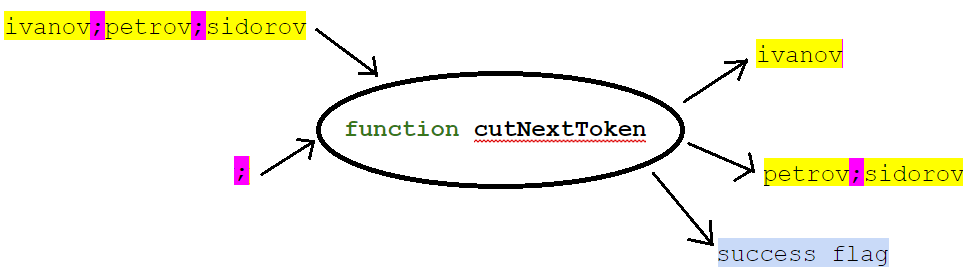
例如,她的签名可能是:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
在函数的输入处,我们给出一个列表(带分隔符的字符串形式),实际上是分隔符的值。 在输出处,该函数返回列表的第一个元素(线段到第一个分隔符),列表的其余部分以及是否返回第一个元素的符号。 在这种情况下,列表的其余部分与原始列表位于相同的变量中。
结果,我们有机会这样写:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
预期输出:
伊万诺夫
彼得罗夫
西多罗夫
我们没有转换为ArrayList,但是破坏了names变量,现在它具有空字符串。 看起来好像还没有什么用,好像他们将锥子换成了肥皂。 但是,让我们走的更远。 在那里,我们将看到为什么有必要,以及它将导致我们何去何从。
现在,让我们解析一些更有趣的东西:键值对列表。 这也是非常常见的任务。
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
结论:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
也预期。 而且,使用String.split可以实现相同的目的,而无需插队。
但是,让我们说,现在我们想使我们的格式复杂化,并从平面键值转换为让人想起JSON的可嵌套格式。 现在,我们想阅读如下内容:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
拆分什么分隔符? 如果是逗号,那么在其中一个标记中,我们将
'birthdate':{'year':'1984'
显然不是我们所需要的。 因此,我们必须注意要解析的行的结构。
它以大括号开头,以大括号结尾(与之配对,这很重要)。 在这些括号内是“键”对“值”对的列表,每对与下对之间用逗号隔开。 键和值之间用冒号分隔。 密钥是用撇号括起来的字母字符串。 该值可以是用单引号引起来的字符串,也可以是相同的结构,以成对的花括号开头和结尾。 我们将这种结构称为“对象”一词,这在JSON中是很常见的。
我们只是非正式地描述了类似JSON格式的语法。 通常,语法以相反的形式进行正式描述,并且使用BNF表示法或其变体来编写语法。 但是现在我可以不用它了,我们将看看您如何“剪切”该行,以便可以根据此语法规则对其进行解析。
实际上,我们的“对象”以打开的花括号开头,以将其关闭的对结尾。 函数解析这种格式可以做什么? 最有可能的是以下内容:
- 验证传递的字符串以大括号开头
- 验证传递的字符串以一对右大括号结尾
- 如果两个条件都成立,则切掉左括号和右括号,然后剩下的内容传递给解析“ key”对:“ value”对的列表的函数。
请注意:出现了“函数解析此格式”和“函数解析对'键':'值'的列表”的字样。 我们有两个功能! 这些功能在递归下降算法的经典描述中被称为“非终结符的解析函数”,并且说“对于每个非终结符,都会创建自己的解析函数”。 实际上,它可以解析它。 我们可以将它们命名为parseJsonObject和parseJsonPairList。
现在,我们还需要注意的是,除了“分隔符”的概念外,我们还具有“成对括号”的概念。 如果要切入下一个分隔符(键和值之间的冒号,“键:值”对之间的逗号),那么cutNextToken函数就足够了,因为我们不仅可以使用字符串,还可以使用对象,功能“切到下一对括号”。 像这样:

如果有括号,此功能可将片段从开括号的那条线切到关闭它的线对。 当然,您不能只限于方括号,而可以使用类似的功能来切断可嵌套的各种块结构:运算符块开始于..end,if..endif,for..endfor以及类似的结构。
让我们以图形方式绘制字符串会发生什么。 绿松石色-这意味着我们将线向前扫描到以绿松石突出显示的符号,以确定下一步应该做什么。 紫罗兰色是“要切除的东西,这是当我们从线条中切除紫色突出显示的片段,并继续解析其剩余内容时。

为了进行比较,分析此行的程序输出(程序文本在附录中给出):
演示解析类似JSON的结构
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
在任何时候,我们都知道我们期望在输入行中找到什么。 如果我们输入了parseJsonObject函数,那么我们希望该对象已传递给我们,我们可以通过在开头和结尾处使用左括号和右括号来进行检查。 如果我们输入parseJsonPairList函数,那么我们期望在那里有一个“键:值”对的列表,并且在我们“咬掉”键之后(在“:”分隔符之前),我们期望下一个“咬掉”的东西是价值。 我们可以查看该值的第一个字符,并得出有关其类型的结论(如果使用撇号,则该值的类型为“字符串”,如果左花括号为该值的类型则为“对象”类型)。
因此,从字符串中切除片段,我们可以通过自顶向下分析(递归下降)的方法对其进行解析。 当我们可以解析时,我们可以解析所需的格式。 或提出您自己的格式以方便我们进行分解。 或者为我们的特定领域想出一种领域特定语言(DSL),并为其设计一个解释器。 并正确地构建它,而不会在正则表达式或自制状态机上出现曲折的解决方案,而那些试图解决某些需要解析但并不完全拥有材料的程序员会遇到这种情况。
在这里 恭喜大家即将到来的夏天,并祝您一切顺利,爱心和功能丰富的解析器:)
进一步阅读:
意识形态:史蒂夫·耶格(Steve Yeegge)的一些漫长但值得阅读的文章:
丰富的程序员食物那里有两句话:
您要么学习编译器并开始编写自己的DSL,要么获得更好的语言
编译管道的第一个重要阶段是解析
皮诺奇问题从那里引用:
类型转换,缩小和扩展转换,友好函数可以绕过标准的类保护,将迷你语言填充到字符串中并手动解析出来 ,有许多方法可以绕过Java和C ++中的类型系统,并且程序员一直在使用它们,因为(他们几乎不知道)他们实际上是在尝试构建软件,而不是硬件。
技术:两篇有关解析LL和LR方法之间差异的文章:
LL和LR解析神秘上下文中的LL和LR:为什么解析工具很难甚至更深入的主题:如何用C ++编写Lisp解释器
90行C ++中的Lisp解释器应用程序。 实现本文中描述的分析器的示例代码(java): package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {