 由DataArt Java社区负责人高级开发人员Igor Masternaya发布
由DataArt Java社区负责人高级开发人员Igor Masternaya发布5月18日至19日,JEEonf在基辅举行,这是整个东欧Java社区最受期待的活动之一。 DataArt与会议合作。 来自世界各地的发言人分四个阶段发言:Volker Simonis,
JCP和OpenJDK贡献者的SAP代表,JürgenHöller,重要的Spring Framework的父亲,Pivotal首席工程师,Apache Camel的创建者Klaus Ibsen,以及Lightbend的传播者Hugh McKee。
日程安排非常繁忙:两天里有超过50场演出,每场45分钟。 休息10分钟-并生成新报告。 当所有视频出现在网络上时,将需要很长时间来观看它们。 因此,我将简要介绍我发现最有趣的和我亲自访问过的报告。
春天的15年
会议由尤尔根·霍勒(JürgenHöller)主持开幕。 他谈到了Spring框架的15年(!)历史,从0.9版中的“收藏夹” XML配置到响应式Spring WebFlux,后者是受
Reactive Manifesto影响的研究项目而产生的。 Jürgen在Spring WEB中谈到了Spring MVC和Spring WebFlux的共存,并解释了为什么他们决定不将它们集成为一个。 关键是,Spring MVC的主要抽象是Servlet API 3.0和阻塞IO,而Spring WebFlux使用了反应性流和非阻塞IO的抽象。 您可以在任何支持无阻塞IO的服务器上的SpringWebFlux上运行服务:Netty,Tomcat的新版本(> 8.5),Jetty。 创建反应式WebFlux控制器与使用Spring MVC创建它们并没有太大不同,但是仍然存在差异。 在处理用户请求时,反应式控制器通常不会处理它,而是创建一个管道来处理请求。 分派器调用controller方法,该方法创建管道并立即将其作为发布者流提供。 Reactive Spring中的发布者流以两种抽象形式表示:Flux / Mono。 Flux返回对象流,而Mono始终返回单个对象。
于尔根还提到在使用Spring 5.0时使用Java 8样式的便利性,并承诺于2018年7月发布候选版本Spring 5.1,并于9月发布发行版本,该版本将支持Java 11并进行新的Spring 5.0功能的微调。
Python / Java集成
有很多报告,很难在下一个广告位中选择最有趣的报告。 这些描述同样有趣,因此我相信自己的直觉,并决定听取来自匈牙利黑石集团副总裁Tamas Rozman的讲话。 但是,如果我再次收听Event Sourcing和CQRS,那就更好了。 从描述来看,该公司从事数据科学领域的大型投资基金。 该报告的目的是说明他们如何创建一个可扩展的,稳定的系统,这对于使用Python的数据分析人员和主系统的Java开发人员同样方便。 但是,在我看来,构建的系统真的很方便令人怀疑。 为了与Python和Java成为朋友,贝莱德(BlackRock)的工程师提出了从Python应用程序中启动Python解释器的过程的想法。 他们之所以这样做有以下几个原因:
- 由于过时的代码库2.7和CPython 3.6,Jython(JVM上的Python)不适合使用。
- 他们认为用Java重写数据科学逻辑的选择过程太长了。
- Apache Spark决定不采用它,因为正如发言者所述,您无法混合使用Java和Python编写的工作负载。 尽管尚不清楚为什么UDF和UDFA不适合[ 2 ]。 而且,Spark不适合,因为他们已经有了某种工作框架,并且他们实际上并不想引入一个新的框架。 而且,事实证明,它们也没有大数据,所有处理都归结为有关可悲的100 MB文件的统计信息。
使用内存映射文件(一个文件用作输入数据文件)和命令(第二个文件是Python进程的输出)来组织Java与Python进程的通信。 因此,交流的形式为:
Java:calcExr | 1 + javaFunc(sqrt(36))
Python:1 + javaFunct | 6
Java:1 +成功| 64
Python:成功| 65岁
这种集成的主要问题,Tamas称输入/输出参数的序列化和反序列化期间的开销。

Java 10应用CD
在介绍了运行Python的复杂性之后,我真的很想听听Java界的一些深奥技术。 因此,我看了Volker Simonis的报告,他在报告中谈到了
Java 10+的Application类数据共享功能。 在基于Docker中微服务构建的现代世界中,共享Java Codecache和Metaspace的能力加快了应用程序的启动并节省了内存。 该图显示了使用Tomcat类的共享/共享档案启动dockerized西红柿的结果。 如您所见,对于第二个进程,内存中的某些页面已被标记为shared_clean-这意味着当前进程和至少一个进程(第二个正在运行的tomcat)引用了它们。

有关在OpenJDK 10中如何使用CDS的详细信息,请参见:
App CDS 。 除了在进程之间划分应用程序类别外,将来计划在
JEP-250中共享实习字符串。
AppCDS的主要限制:
不适用于1.5级以下的类。
- 您不能使用从文件(仅.jar存档)加载的类。
- 由类加载器修改的类不能使用。
- 由多个类加载器加载的类只能重用一次。
- 字节码重写不起作用,这可能导致性能下降多达2%。 JDK-8074345

使用Apache Spark的自然语言处理管道
有关NLP和Apache Spark的报告由Grammarly的工程师Vitaliy Kotlyarenko提出。 Vitaliy演示了语法语法如何在Apache Zeppelin上原型NLP-Jobs。 一个示例是基于
通用爬网 Internet存档的
LDA算法构建用于主题建模的简单管道。 主题建模的结果被用来过滤内容不当的网站,作为父母控制功能的一个例子。 为了创建管道,我们使用了Terraform脚本和
AWS EMR Spark集群,这使您可以在Amazon中使用YARN部署Spark集群。 从原理上讲,管道如下所示:
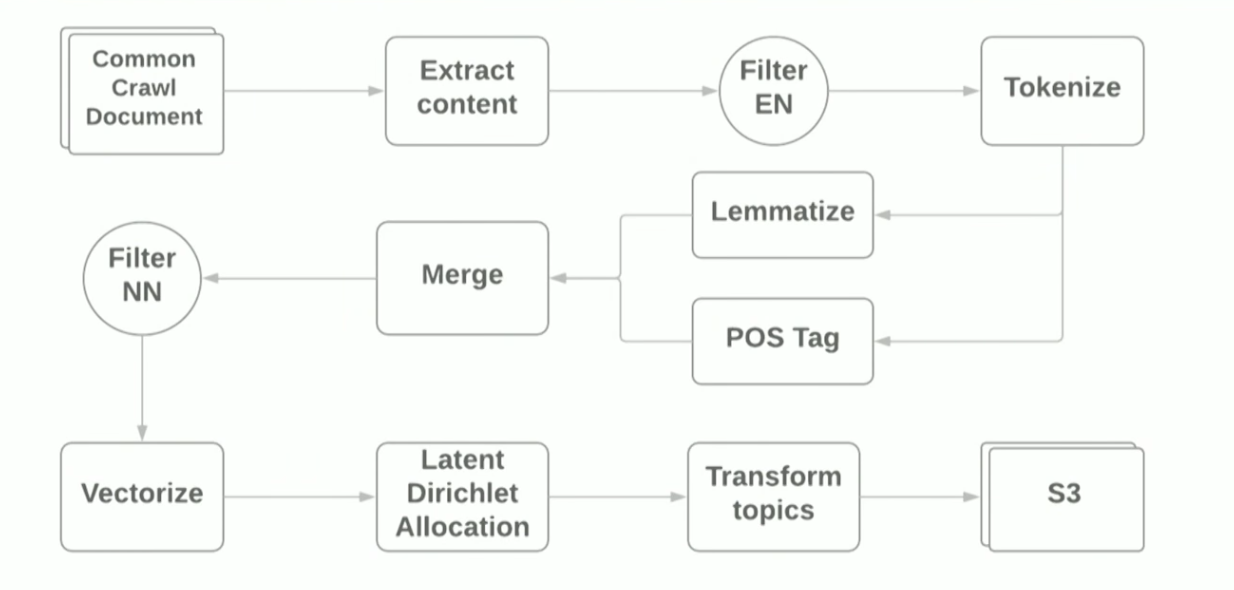
该报告的目的是说明使用现代框架为ML任务制作原型非常简单,但是,使用标准库仍然会遇到困难。 例如:
在演示期间,我们使用标准的Spark UI和监视子系统
Ganglia监视了作业的执行,该子系统在部署到AWS EMR时将自动可用。 作者专注于热图“服务器负载分布”,该图显示了集群中节点之间的负载分布,并就优化Spark Job的工作提供了一般建议:增加分区数,优化数据序列化,分析GC日志。 您可以
在此处阅读有关优化Spark Jobs的更多信息。 演示的源文件可以在报告作者的
github中找到。
Graal,Truffle,SubstrateVM和其他特权:这些是什么,为什么您需要它们
对我来说,最令人期待的是JUG.ru的Oleg Chirukhin的报告。 他讲述了如何使用Grail优化完成的代码。 什么是圣杯? Grail是
Oracle Labs的一个品牌,结合了JIT(即时)编译器,用于编写DSL语言的框架Truffle和特殊的JVM(
SubstrateVM ),通用的
封闭世界虚拟机可以用JavaScript编写, Ruby,Python,Java,Scala。 该报告侧重于JIT编译器及其在生产中的测试。
首先,回顾一下Java机器执行代码的过程,并注意Java已经有两个编译器:C1(客户端编译器)和C2(服务器编译器)。 Grail可用作C2编译器。
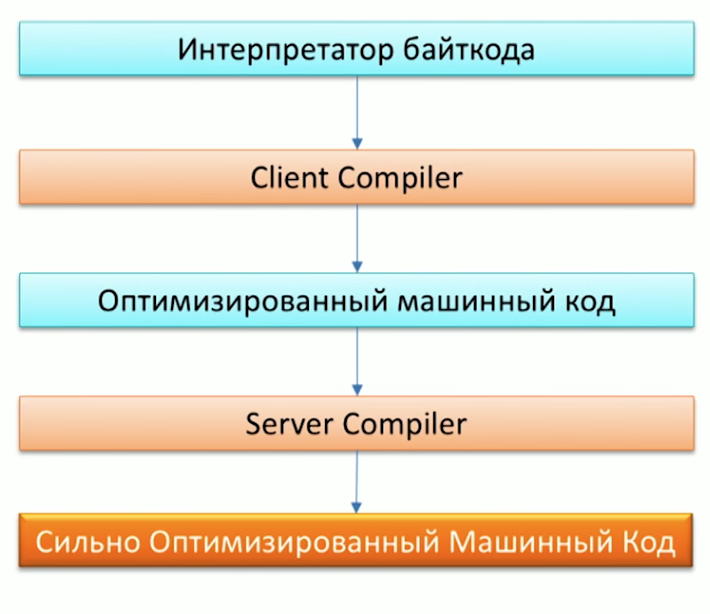
当被问及为什么需要另一个编译器时,Oracle Labs的一名员工Chris Seaton博士在“
了解Graal的工作原理 ”一文中回答得很好。 简而言之,Graal项目和
Metropolis项目的最初想法是用Java重写用C ++编写的JVM代码的一部分。 这将使将来有可能方便地补充代码。 例如,优化之一(P
artial Escape Analysis )已在Grail中,但不在Hotspot中,
因为扩展Grail代码比C2代码容易得多 。
听起来不错,但是您会问,这在我的项目中将如何实践? 圣杯适用于项目:
- 里面乱扔了很多东西,创造了很多小物件。
- 以Java 8风格编写,带有一堆流和lambda。
- 使用不同的语言:Ruby,Java,R。
Grail是首批投入生产的产品之一,开始在Twitter上使用。 您可以在发布于Habré的Christian Talinger
访谈中 (
访谈 _1和
访谈 _2)了解有关此内容的更多信息。 他在那里解释说,通过用Graal替换C2,Twitter开始节省了大约8%的CPU利用率,考虑到组织的规模,这是相当不错的。
在会议上,我们还可以通过启动Scala基准测试之一
Scala DaCapo来验证Graal的速度。 结果,在Graal上,基准测试通过了大约7000毫秒,在常规JVM上通过了大约14000毫秒! 为什么会这样,您可以通过查看gclog测试来了解。 使用Graal时分配失败的次数明显少于Hotspot。 但是,您仍然不能说Grail将成为Java应用程序性能问题的解决方案。 Oleg在他的报告中还展示了一个失败的故事,比较了Grail下的
Apache Ignite的工作和没有它的情况-性能没有明显变化。

设计容错微服务
AppsFlyer的Orkhan Gasimov阅读了另一篇有关故障安全微服务架构的报告。 他介绍了用于构建分布式应用程序的流行设计模式。 我们可能很了解其中的许多人,但是四处走动并回想起它们并不会造成任何伤害。
报告中描述的模式所针对的服务的容错性的主要问题是:网络,峰值负载,服务之间的通信的RPC机制。
为了解决网络问题,当其中一项服务不再可用时,我们需要能够用另一项服务快速替换它的功能。 实际上,这可以通过同一服务的多个实例以及这些实例的替代路径的描述(一种
服务发现模式)来实现。 参与
心跳服务并注册新服务将是一个单独的实例-服务注册表。 通常使用著名的
Zookeeper或
Consul作为服务注册表。 反过来,它们也具有分布式特性并支持容错。
解决了网络问题之后,我们转向峰值负载的问题,即某些服务处于负载状态并且处理请求比常规模式慢得多。 要解决此问题,可以使用
自动缩放模式。 他不仅将承担自动扩展高负载服务的任务,还将在高峰负载期过后停止实例。
作者报告的最后一章描述了内部RPC服务间通信的可能问题。 Urahan特别注意了“用户不应长时间等待错误消息”这一论点。 如果他的请求由服务链处理并且问题在链的末端,则可能会出现这种情况:因此,用户可以等待链中每个服务处理该请求,并且仅在最后阶段才收到错误。 最糟糕的是,如果最终服务过载,并且经过漫长的等待,客户端将收到毫无意义的HTTP错误:500。
为了应对这种情况,可以使用
Timeout ,但是仍然可以正确处理的请求可能会属于超时。 为此,超时逻辑可能很复杂,并且可以为每个时间间隔的服务错误数添加一个特殊的阈值。 当错误数量超过阈值时,我们了解到该服务正在负载中,并认为该服务不可用,从而为该服务提供了处理当前任务的必要时间。 此方法描述了
断路器模式。 您还可以将CircuitBreaker.html“> Circuit Beaker用作监视的附加指标,使您可以快速响应可能的问题并清楚地确定哪些服务链正在遇到这些问题,为此,每个服务调用必须包装在Circuit Breaker中。
在报告中,作者还回顾了
N-Modular冗余模式,该模式旨在“在可能的情况下更快地处理请求”,并提供了一个美丽的示例,用于验证客户地址。 他们在系统中通过地址缓存发出的请求立即发送给了多个地理地图提供者,从而赢得了最快的响应。
除了描述的模式外,还提到了以下内容:
- 快速路径模式 ,例如,在缓存查询结果时可以应用。 然后缓存访问是快速路径。
- 错误内核模式 -来自Akka世界的一种模式,涉及将任务划分为子任务,并将子任务委托给下游参与者。 这样,实现了处理子任务执行错误的灵活性。
- Instance Healer ,假设存在特殊服务-管理其他服务并对状态变化做出响应的主管。 例如,万一服务出现错误,主管可以重启有问题的服务。

使用Akka和Java的集群式事件源和CQRS
我想提请您注意的最后一份报告是由Lightbend福音传教士和建筑师Hugh McKee阅读的。 Lightbend(以前称为Typesafe)类似于Oracle,但适用于Scala语言。 该公司还积极开发
Akka.io框架。 休在一份报告中谈到了在Akka框架上流行的
CQRS (命令查询责任命令/ SEGREGATION)方法的实现。 从原理上讲,CQRS系统的体系结构如下所示:
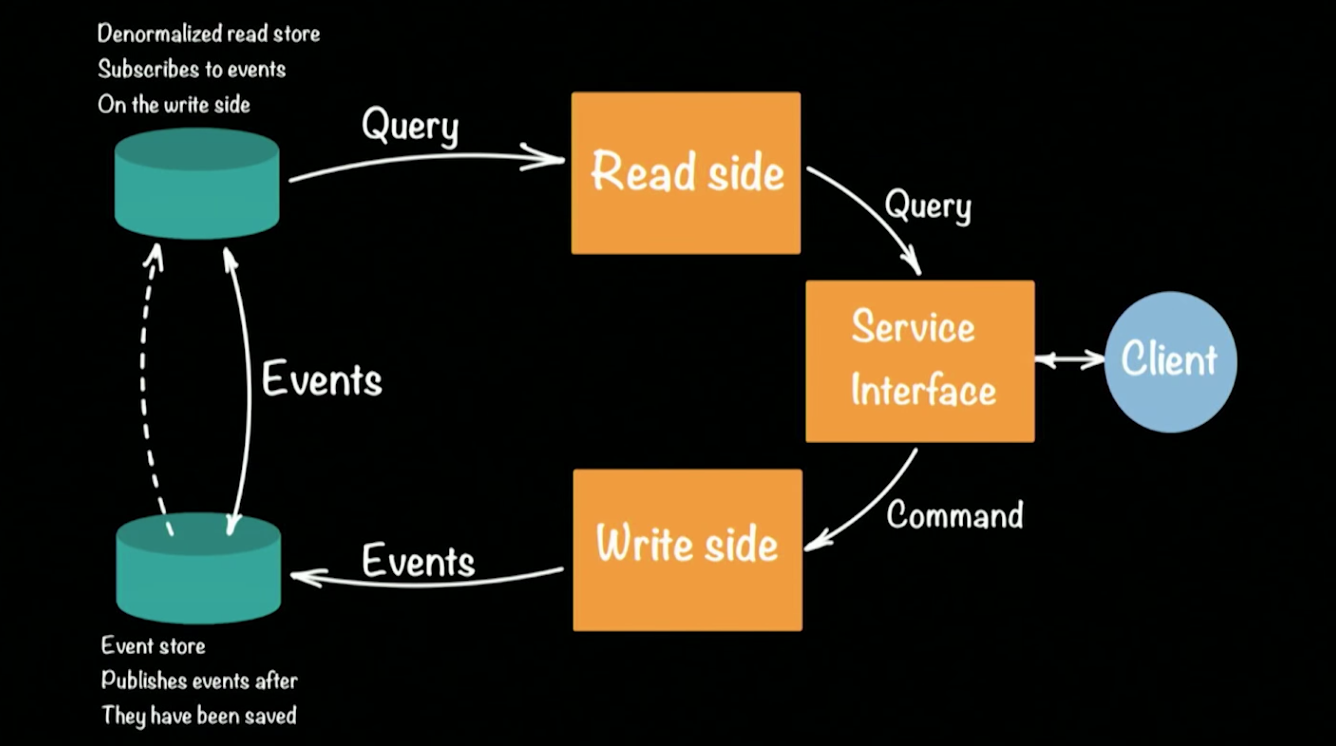
休以银行的原型作为工作系统的示例。 CQRS体系结构中的客户端执行两项操作:查询,命令。 每个团队(例如,从一个帐户向另一个帐户转移资金的银行交易)都会生成一个事件(既成事实),该事件将记录在EventStore中(例如:Cassandra)。 事件的链式汇总(将资金存入帐户,从一个帐户转至另一个帐户,在ATM上取款)构成了客户的当前状态,即帐户中的资金余额。 对于当前状态的请求将转到单独的存储库,即事件存储库的快照,因为保留银行帐户的完整历史记录是没有意义的。 定期更新每个用户的状态就足够了。
这种方法可以在发生错误时自动恢复:为此,我们需要获取用户状态的最后一个转换,并将在错误发生之前发生的所有事件应用于该状态。 由于存在两个存储,CQRS体系结构很好地承受了出现的峰值负载(峰值)。 大量事件将加载事件存储,但不会影响读取存储,并且用户仍将能够完成对数据库的查询。
让我们回到在Akka和CQRS上建立银行系统的原型。 系统中银行/帐户/可能的团队的每个客户都将由一个(!)
Actor代表。 大型银行可以支持成千上万个帐户,这对Akka来说不是问题。 开箱即用的框架支持集群,并且可以在数百个JVM上运行。 如果群集中的一台计算机发生故障,Akka提供了特殊的机制来自动响应这种情况:在我们的情况下,可以在群集中的任何可用计算机上重新创建客户端的actor,并且其状态将从存储库中重新读取。
没有为参与者创建单独的线程-这样就可以在单个JVM中支持成千上万的参与者。 同时,执行者保证将按照接收请求的顺序分别处理每个请求(!)。 这样可以保证在处理请求时自动消除可能的竞争条件。 您可以通过使用GitHub中的链接打开系统代码来更详细地了解系统原型。 每个子项目都展示了构建原型的最复杂阶段的实现:
黄蜂。
所有报告的记录将在几周内在线显示。 希望本文能帮助您确定观看顺序,特别是因为我认为值得观看表演。