计算机视觉越来越融入我们的生活。 同时,我们甚至没有注意到对我们的所有观察。 今天,我们将讨论一种系统,该系统可以帮助分析会议,教育过程,电影院等中的访客情绪。 顺便说一下,我们将显示代码并讨论实际案例。 看猫下!
 我请作者发言。
我请作者发言。您是否总是想亲自了解大厅,教室,办公室中的观众并进行管理? 这个问题绝不是闲着。 这是关于离线受众的。 为了提高业务绩效,掌握有关客户行为,其反应和愿望的信息是至关重要的。 如何收集这些统计数据?
有了在线观众,一切都会变得更加容易。 如果企业位于Internet上,那么营销将大大简化,并且可以根据客户的个人资料收集数据,然后无限期地“赶上”它-非常简单。 很多工具-使用和使用,成本在上升。
在离线模式下,与50年前一样,采用了相同的方法:问卷,问卷,带有笔记本的外部观察员等。 这些方法的质量很差。 可靠性令人怀疑。 关于便利,您通常可以保持沉默。
在本文中,我们想谈谈CVizi的新解决方案,该解决方案收集有趣且独特的统计信息,并有助于使用计算机视觉分析有关您的客户/访客的信息。
视频分析和电影院
最初,该产品被开发为一种工具,用于对电影院观众进行计数,并将其人数与购买的门票进行比较,以对服务人员进行纪律控制并防止违规行为。 但是正如他们所说,食欲与进食有关。
先进的技术可以扩展解决方案的功能。 确定电影观众的年龄和性别特征,以及确定会议期间每个人的情感背景成为可能。
信息会及时更新,用户只需要进入您的个人帐户并查看感兴趣的会话的统计数据或受众的分析报告即可。
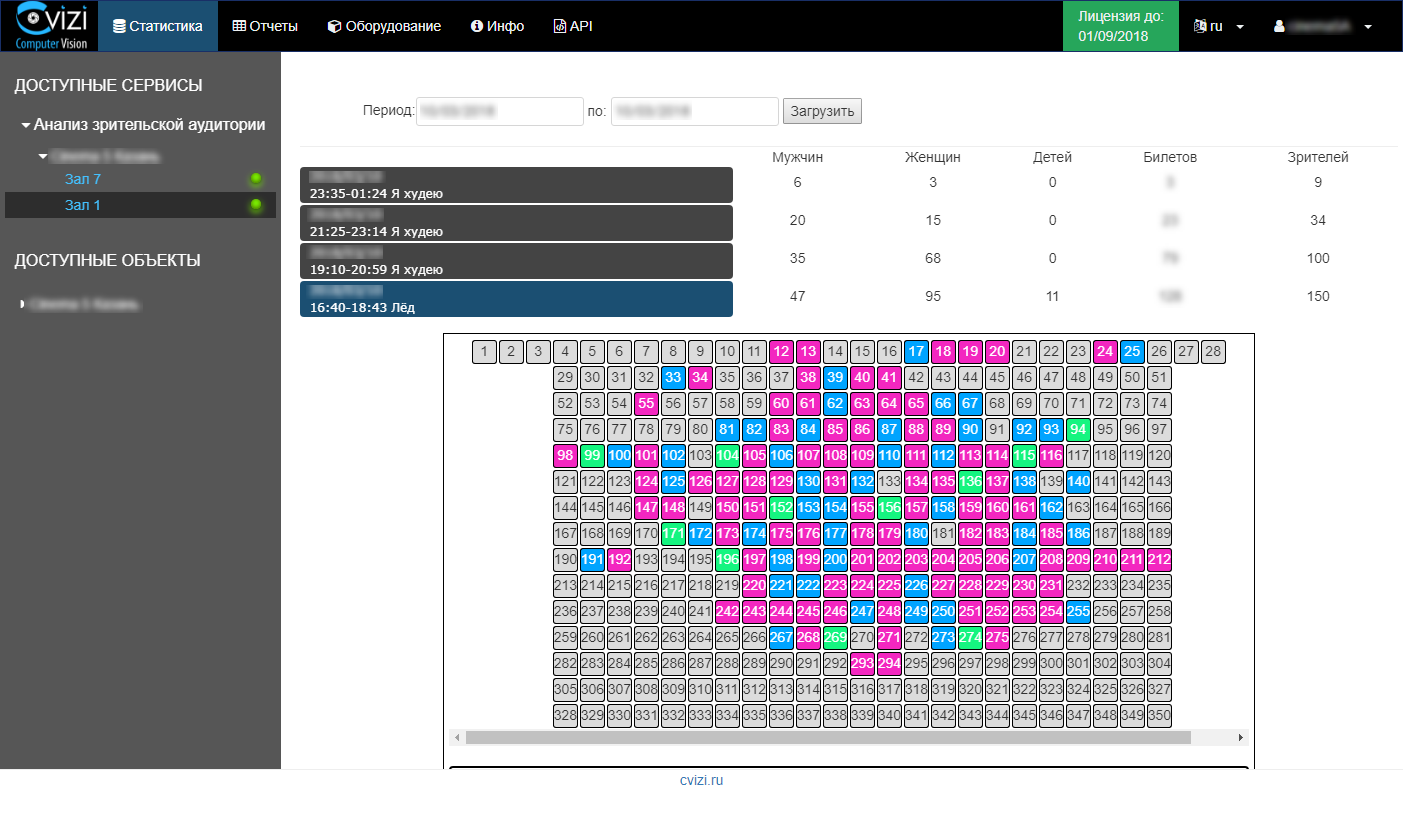
例如,我们与电影“冰”一起开场,在大厅的实像上我们看到了女性观众的明显统治地位(原则上是可以预见的)。 然后我们看一下人们经历过的那些情绪(每个人都能看到)。
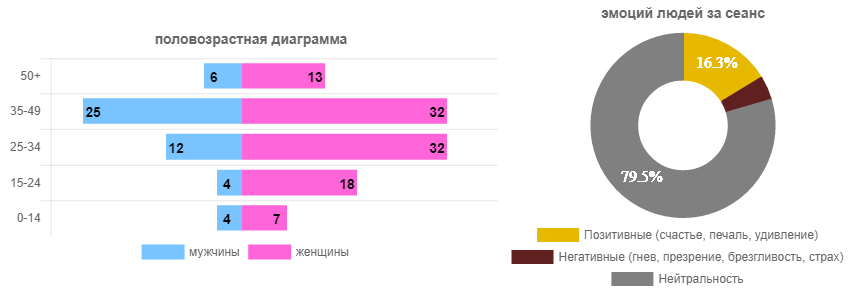
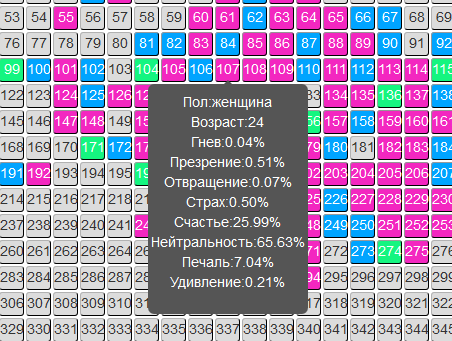
这是一个特定会话的数据。 现在,让我们来看一下电影整个租借期间(在一个电影院中)的相同数据,并获得更相关的图片。
在观众方面,年龄在25-34岁之间的女性观众占绝对优势。 男性少2.5-3倍。 即 在广告单元中的新SUV中投放广告并不像在新睫毛膏中投放广告那样聪明。 虽然这是有争议的。 但是无论如何,只要租借几天,您就可以安全地向广告客户保证目标受众,甚至可以量化。
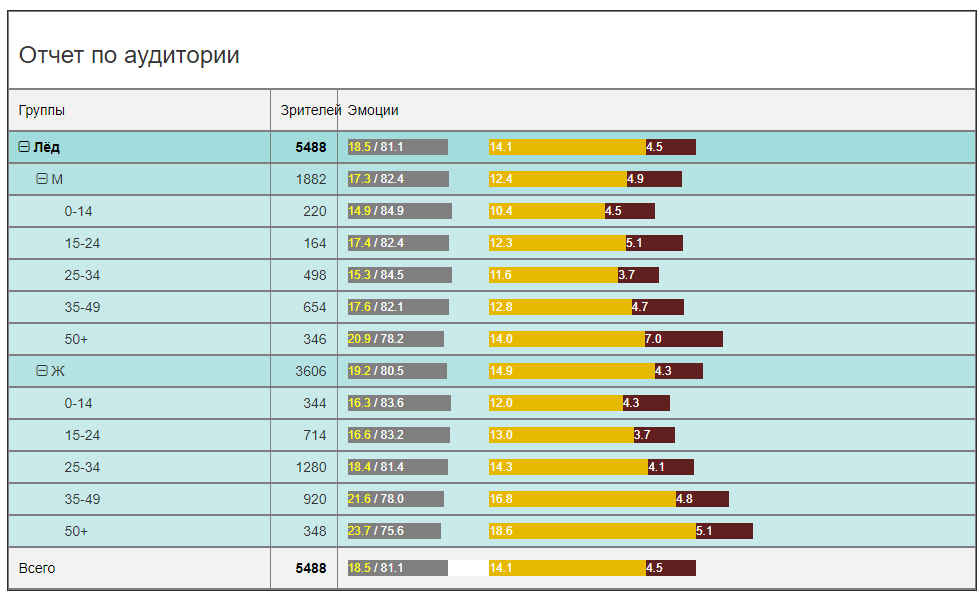
从情感背景的角度来看,主要是经销商和分销商感兴趣的图片。 电影给谁取悦,谁讨厌? 我应该拍续集吗? 相信机器人的评论或获得可靠的统计信息? 在这种情况下(电影“冰”),该电影在情感上相当明亮。 正面与负面情绪的总和是100鹦鹉中的18.5,其余是中性的。 这是一个很好的指标。 为了进行比较,其他电影中的情感背景可能并不那么乐观(所有年龄段和性别的医院平均而言)。
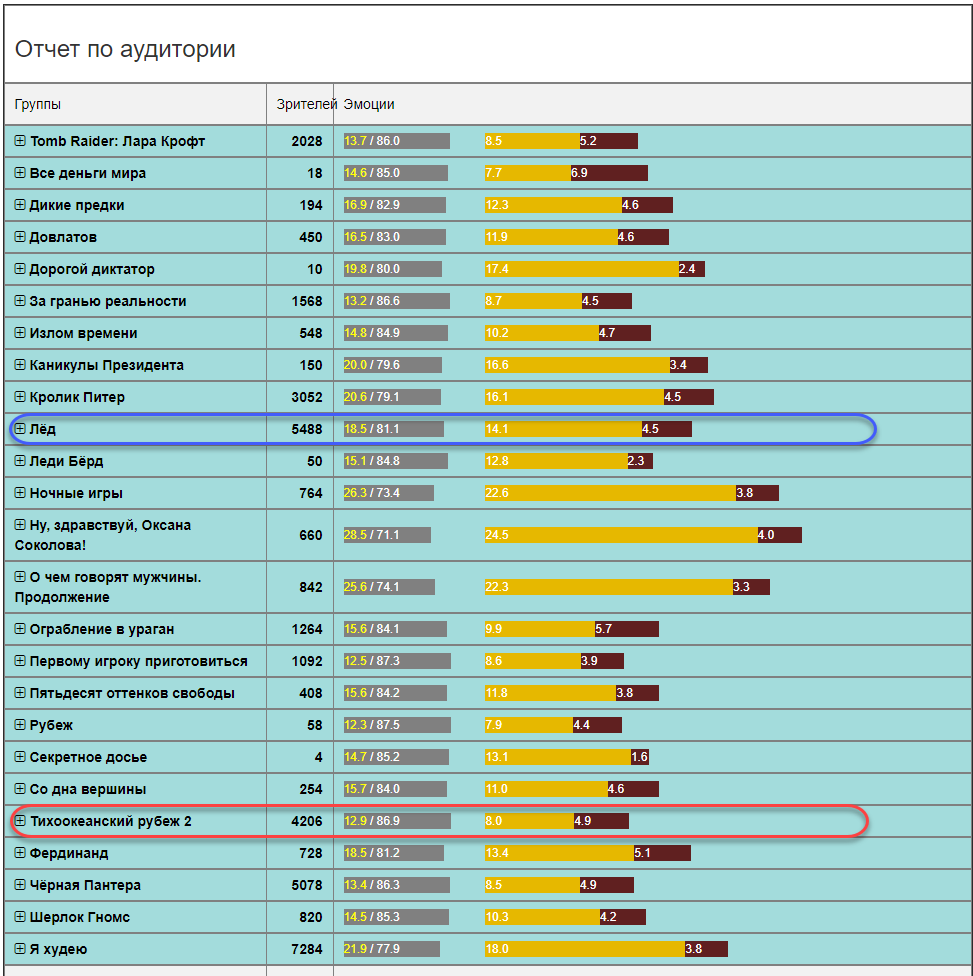
例如,同一时期观众人数相当的太平洋边境地区的积极情绪要少2倍。 电影“你好,Oksana Sokolova”就是对“ 50+”女性的发现。

所有这些都是可以在电影网络中使用的一些分析示例。 他们只是根本没有这些信息,很少有人知道它完全可以获取,甚至更多可以自己使用。
对于电影网络而言,根据观众的组成及其对各地电影的反应,可以为深入分析大厅中正在发生的事情提供巨大的机会。
您可以立即突出显示以下内容 :
- 测试任何营销假设的能力是接收实时反馈并客观评估受众变化和营销活动的效果。
- 能够为广告客户提供有关观看广告的受众的准确信息。 甚至不止如此,广告商有可能保证某些受众群体观看广告。
- 能够为特定年龄和性别的访客在市场上创建独特的营销优惠(折扣),而不会破坏现有的工作计划,也不会降低当前的财务指标。
由于这一决定而产生的这些以及许多其他机会,能够改变电影院网络市场,增加收入并提高单个电影院和整个网络的效率。
考虑到该解决方案是“简单”的(没有服务器,也没有流向Internet的流),积极使用Microsoft Azure云,并且以可承受的价格向市场推出(定期订阅该服务),因此俄罗斯和国外的电影院网络都在积极地实施它。
而且,所创造的技术在并行领域的其他解决方案中得到了体现。
视频分析和事件
活动,事件,论坛,峰会,会议,专题讨论会...组织者对新观众了解什么? X个人注册了,Y来了,Z填写了调查表,几乎就是这些。
询问是另外一个痛苦:“所以,我很了解这个同志,尽管报告很无聊,我还是给他5分。” 我们导致调查表的可靠性低的事实。
要了解会议的有效性,仅需要参与者向组织者和赞助者的反馈即可。
用于分析电影院观众的服务可以完美地转移到会议场所。 CVizi还通过进行两个实验测试了这个案例:在一次会议上在斯科尔科沃的Matrex厅以及在2018年Imagine Cup学生技术项目竞赛俄罗斯决赛中的Digital October厅。
实验1.斯科尔科沃的Matrex Hall
在Matrex中,照相机不是像电影院那样安装在屏幕上方,而是安装在扬声器后面的伸缩支架上。 因此,该解决方案证明是可移动的。 仅需要几个小时即可开始安装摄像头,设置大厅平面图并输入发言人时间表。 然后,系统自行完成所有操作。

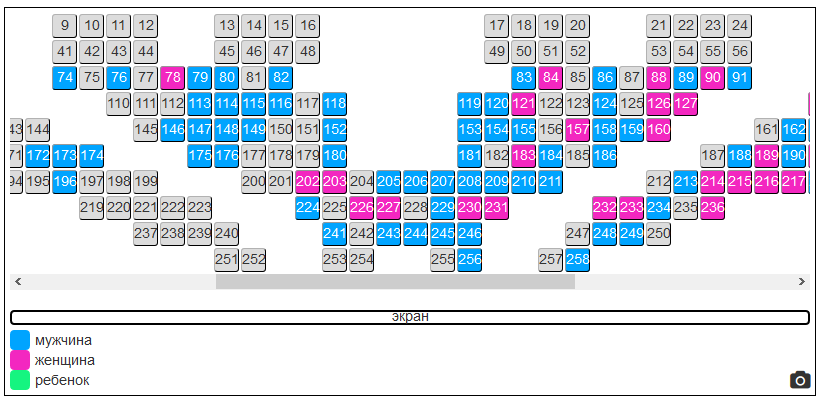
现在,组织者可以通过会议厅参与者的人数及其每次会议/报告的情绪收集有关报告质量的数据。 下次您可以根据客观事实来计划活动。 有报道说,与会者随后简单地离开了房间,下一位发言者与那些留下或没有时间离开的人一起工作。 这是错误的,并且这样的预测可以通过重新排列报告来极大地改变效果。
实验2.俄罗斯决赛想象杯
这里的目标有所不同,但是方法是相同的。 比赛的提名之一是观众奖。 坐在大厅里的是那些观众,而不是在线观众。 首次在“想象杯”上,观众的选择奖被授予了由人工智能选择的团队。 团队获胜,当他们在舞台上时观众对他们的表现最满意。 为此,已经使用了两个摄像头,每个摄像头连续地控制着自己的大厅区域,并收集了每个观众的情感特征。
在这种情况下,可以将摄像机悬挂在舞台上方的照明桅杆上,以确保其稳定性和固定性。 同时,我们再次确信4G互联网足以使服务正常工作。 事实证明该系统是尽可能自治的。 组织者只需要220 V,这非常重要,因为 在如此大规模的事件中,通信通道始终是瓶颈,服务质量直接取决于Internet通道的稳定性。
结果,观众的奖品被授予在表演中获得最大积极情绪的团队-NNSU im的“ Last Day Development”。 洛巴切夫斯基。

视频分析和学习
就其流程的自动化而言,教育领域仍然远远落后于其他行业。 例如,在许多大学中,出勤控制仍以带有日记的外部控制者的形式进行:一个人进来,在讲座中对学生进行计数,在日记中输入一些数字(什么问题?),然后继续。
通过计算机视觉方法对观众进行分析的技术非常适合教育领域,为实验和分析开辟了广阔的领域。 可能要解决的任务:
- 班级出勤监控
- 学生证
- 教学质量评估
- 识别学生的负面情绪并采取预防措施。
- 评估一个或多个学生在学校中的参与程度。
正确的教育过程计划,包括时间表,讲师的选择-这是教育成功的基础。 但是实际上,如果我们转移到经济领域,这就是每个学生所接受的教育成本。
其他行业的视频分析
CVizi技术不仅限于所提供的解决方案,还有零售和生产解决方案。
例如,一个有趣的解决方案是获取有关商店的外部和内部转换的信息。 这两个指标使您可以构建离线销售渠道:
- 您的商店附近有多少人走?
- 有多少人参加了?
- 有多少人去收银机。
这是位于莫斯科购物中心的一家典型商店的外部转换示例:
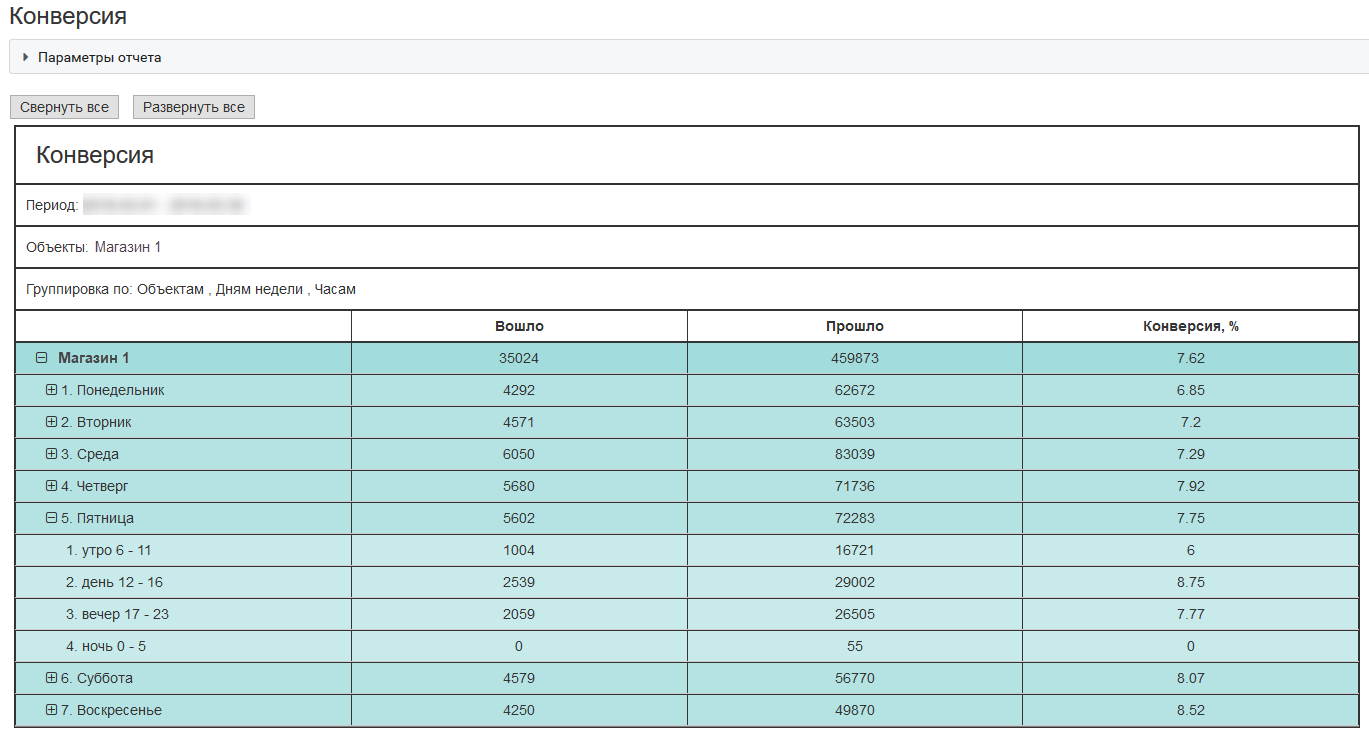
有了这些指标,企业可以更有效地在吸引客户,测试营销假设以及服务质量上花钱。
如何运作?
现在我想谈谈技术。 为什么我们说解决方案“简单”? 一切都与建筑有关。 购买昂贵的解决方案始终是任何客户的负担,此外,还要购买各种服务器,注册服务商和其他形式的设备。 然后进行全部设置,彼此配对并陪伴。 如果向客户提供了微型手机形式的盒子,其大小相当于手机的大小,那么至少对该技术有一定了解的任何人都可以将其安装在其本地网络上,并悬挂IP摄像机。 在家中与Wi-Fi路由器的类比暗示了自己的问题-我将其插入电源插座,连接了Internet,进行了最简单的设置。 仅此而已。 无需售后服务。 一切都非常容易独立完成。
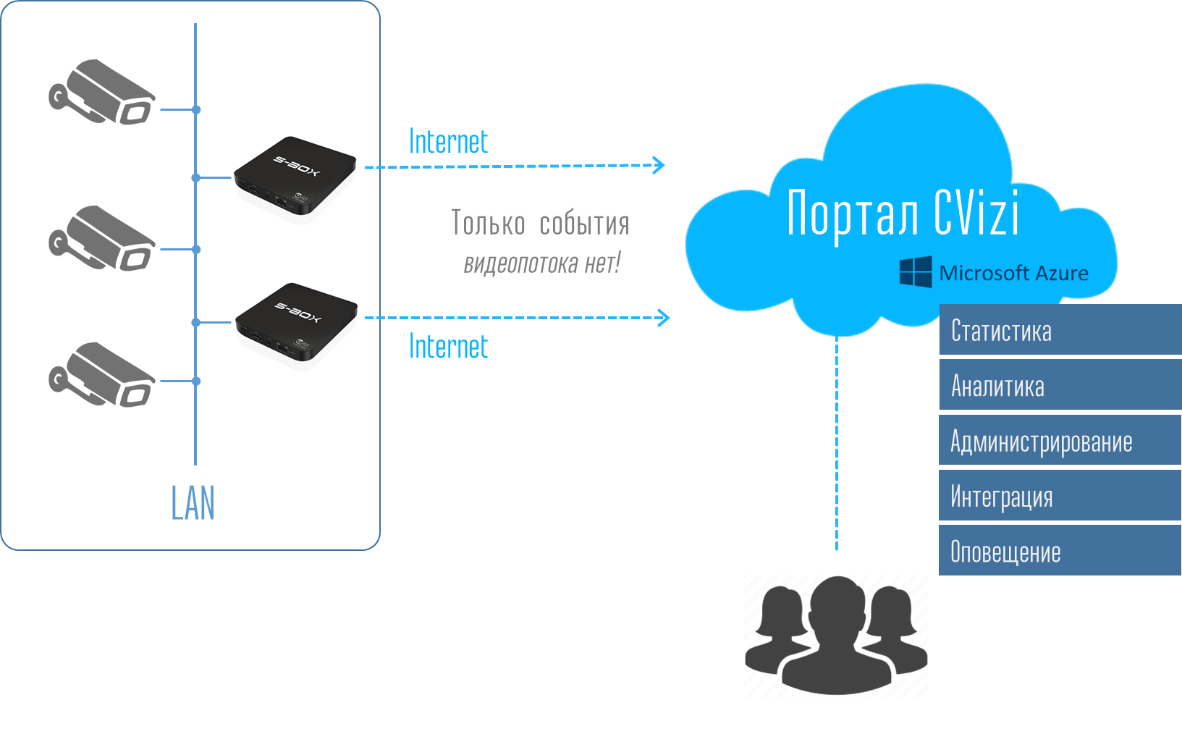
然后,在用户帐户中,用户可以看到整个系统,并可以以报告和统计日志的形式接收数据,并使用API将这些数据带入公司的IT系统中。
因此,用户无需思考和关心基础架构。 连接S-Box计算设备非常容易。 将解决方案复制到其他地方也很容易-挂起相机,连接所需数量的S-Box,然后立即在帐户中查看门户中的对象。
在门户和个人帐户下是部署在Azure云中的整个分析,数据库存储,设备监视和通知系统。 该系统非常灵活,并且所有必要的计算资源都会自动分配给用户。 因此,消除了用户对设备及其支持的全部困扰。 他只购买视频分析服务。 很舒服
哪些摄像机可以用于观众的视频分析?
鉴于最终您需要使观看者的面部质量达到可接受的水平,因此,摄像机首先应具有良好的光学和变焦功能,其次应控制PTZ。
我们测试了十几个来自不同品牌的相机。 我们不会命名特定的相机型号,但可以表达其特征。
对于最多容纳150-200人的大厅,配备2MP矩阵的20倍摄像机就足够了。 对于200人以上的大厅,最好使用25倍及以上的摄像机。 它们当然更贵,但这是正确的方法。 虽然当然也可以使用矩阵的大小,但是您必须了解,在红外光谱中,矩阵会产生噪声,光学变焦始终优于数字。
识别精度
我们越靠近脸部,脸部就会越清晰。 一切似乎都清楚了,孩子明白了。 但是,如果一切都很好,并且具有性别识别能力,那么无论相机距离多近,确定年龄的准确性都可以轻松达到±5岁甚至更高。 而且这里的重点不是算法和神经网络的质量,而是每个成年人都试图在外观上投入尽可能多的事实。
因此,相机会给出一个人看起来或试图看起来的年龄。 即 根据照片的生物学年龄和年龄-这可能是两个很大的差异。 毕竟,我们每个人都可以回忆起他误以对话者的年龄分级的情况。 同时,人脑是一个非常强大且训练有素的神经网络。
Azure及其服务
所有这些的核心是Microsoft Face API认知服务。 这是一项非常方便的服务,几乎可以从任何常见的开发环境中访问该API。 我们使用Python使用大多数服务-这是在云端。
一般顺序如下所示:1)S-Box将图片传输到云端
2)云服务会对其进行累积,排序并将其提供给人脸检测认知服务。 要将收集的图像上传到云,请使用Python:
def upload_file(file_path, upload_file_type):
""" Uploading file """
...
if authData == '' or authData == 'undefined':
...
try:
r = requests.post(param_web_service_url_auth, headers={'authentication': base64string})
if r.status_code == 200:
authData = json.loads(r.text)['token']
result = upload_file(file_path, upload_file_type)
return result
logging.error("Upload_file(%s) - UNEXPECTED AUTH RESULT CODE %d", file_path, r.status_code)
except Exception as e:
logging.error('Upload_file(%s) error', file_path)
logging.exception('Upload exception ' + str(e))
return False
try:
base_name = os.path.basename(file_path)
txt_part, file_extension = os.path.splitext(base_name)
files = {'file': open(file_path, 'rb')}
...
if upload_file_type == 1: # for upload full view
...
payload = {'camid': cam_id, 'dt': dt, 'mac': mac}
z = requests.post(uploaddatalinkhall, headers={'authentication': authData}, files=files, data=payload)
if z.status_code == 200:
return True
logging.debug('post result -> %d', int(repr(z.status_code)))
if upload_file_type == 0:
...
payload = {'camid': cam_id, 'dt': dt, 'json_str': json_str, 'mac': mac}
...
z = requests.post(param_web_service_url, headers={'authentication': authData}, files=files, data=payload)
myfile.close()
if z.status_code == 200:
...
if len(debug_path) > 0:
# move
fnn = debug_path + os.sep + json_file
shutil.move(upload_folder + os.sep + json_file, fnn)
else:
# delete
os.remove(upload_folder + os.sep + json_file)
return True
result = "UNEXPECTED STATUS CODE " + repr(z.status_code)
logging.error('upload_file(%s) - ERROR. Res=%s, text: %s',
json_file, result, z.text)
...
except Exception, e:
...
logging.exception('Upload exception: ' + str(e))
return False
3) Python
CF.face.detect , , MS Face detection Cognitive Service API, :
def faceapi_face_detect(url):
…
# API call
image_url = url
need_face_id = False
need_landmarks = False
attributes = 'age,gender,smile,facialHair,headPose,glasses,emotion,hair,makeup,accessory,occlusion,blur,exposure,noise'
watcher = elapser_mod.Elapser()
try:
api_res = CF.face.detect(image_url, need_face_id, need_landmarks, attributes)
# callback(url, need_face_id, need_landmarks, attributes, e.elapsed(), api_res)
text = 'CF.face.detect image_url {}, need_face_id {}, need_landmarks {}, attributes {}, completed in {} s.'. \
format(image_url, need_face_id, need_landmarks, attributes, watcher.elapsed())
printlog(text)
text2 = 'Detected {} faces.'.format(len(api_res))
printlog(text2)
text3 = '{}'.format(api_res)
printlog(text3)
except CF.CognitiveFaceException as exp:
text = '[Error] CF.face.detect image_url {}, need_face_id {}, need_landmarks {}, attributes {}, failed in {} s.'. \
format(image_url, need_face_id, need_landmarks, attributes, watcher.elapsed())
printlog(text)
text2 = 'Code: {}, Message: {}'.format(exp.code, exp.msg)
printlog(text2)
message = exp.msg
…
return api_res, message
. () . . , . . – .
? ! . API. – , , . , () .., «» . . .
.

— CVizi. : 'aosipov @ cvizi.com'.
FB .