列式DBMS在零年代积极发展,目前他们已经找到了自己的定位,并且实际上无法与传统的小写系统竞争。 通过削减,作者了解了通用解决方案是否可行以及其实用性。
“一切都有进步。...不要害怕他们会叫你到办公室说:”我们在这里进行了咨询,明天你将根据自己的意愿被困在营地或被烧死。“这将是一个艰难的选择。 我认为他会让我们很多人感到困惑。”
Yaroslav Hasek。 勇敢的士兵施维克的历险记。
背景知识
存在多少个数据库,这种意识形态的冲突就这么多。 出于好奇,作者于1975年在垃圾桶中找到了IBM [1]的J. Martin所著的一本书,并立即偶然发现了这样的词(第183页):“二进制关系用于作品,即 只有两个域的关系。 众所周知,二进制关系为基础提供了最大的灵活性。 但是,在商业任务中,各种程度的关系都很方便。” 关系在这里被理解为关系关系。 所提到的作品的日期为1967年至1970年。
Sybase IQ是第一个在工业上使用的专栏DBMS,但是至少在思想层面,一切都比它早25年了。
当前,以下列或某种程度地支持DBMS(主要
在此使用 ):
商业广告
免费和开源
差异性
关系关系是元组的集合,本质上是一个二维表。 因此,有两个存储选项-行或列。 分离有点人为的,合乎逻辑的。 数据库开发人员早已停止计划
鼓和跟踪记录。 DBMS管理员的任务是将DBMS数据最佳地分解为一个文件系统,但是文件系统开发人员主要了解文件系统如何在物理磁盘上安排数据。
让DBMS决定存储数据的顺序是合乎逻辑的。 在这里,我们讨论的是一些假设的DBMS,它既支持组织数据存储的两个选项,又可以向其中的任何一个分配表。 我们不认为支持两个数据库是一个非常流行的选择-一个用于工作,第二个用于分析/报告。 以及Microsoft SQL Server的列索引。 不是因为它很糟糕,而是要检验是否存在更优雅的方法这一假设。
不幸的是,没有任何假设的DBMS可以选择最佳的存储数据方式。 因为 不了解我们将如何使用这些数据。 没有这个,就很难做出选择,尽管它很重要。
DBMS最有价值的品质是快速处理数据的能力(当然还有
ACID要求)。 DBMS的速度主要取决于磁盘操作的数量。 由此产生两种极端情况:
- 数据快速更改/添加,您需要时间来写。 显而易见的解决方案-如果可能,将一行(元组)放在一页上,因此无法更快地完成。
- 数据变化极少或根本没有变化,我们多次读取数据,一次只涉及少量的列。 在这种情况下,使用存储的逐列变体是合乎逻辑的,然后在读取时将增加最少的页面数。
但是这些都是极端的情况,在生活中并不是那么明显。
- 如果要读取整个表,那么从页数的角度来看,数据逐行或逐列都不重要。 即,当然有一些区别,在逐列版本中,我们有能力更好地压缩信息,但是目前这并不重要。
- 但是在性能方面,存在差异,因为 在逐行记录的情况下,从磁盘读取的内容将更加线性。 较少的硬盘驱动器磁头可明显加快读取速度。 在逐行记录期间更可预测的文件读取使操作系统(OS)可以更有效地使用磁盘缓存。 即使对于SSD驱动器,这也很重要,因为按假设加载(预读 )通常会成功。
- 更新并不总是会更改整个记录。 假设一个常见的情况是在两列中进行了更改。 如果这些列的数据在一页上,那将是很好的,因为每条记录只需要一个页面锁,而不是两个。 另一方面,如果数据分布在页面之间,则可以使不同的事务更改一行中的数据而不会发生冲突。
这是仔细看看。 一种可能的选择是使表变为小写或柱状,这是DBMS在创建表时必须做出的。 但是要做出此选择,最好知道例如我们将如何更改此表。 也许你应该扔硬币?
- 假设我们使用树结构(例如:聚集索引)进行存储。 在这种情况下,添加数据甚至更改数据都可能导致树或其部分重新平衡。 在行存储中,存在(至少一个)写锁,这可能会影响表的大部分。 在柱状版本中,此类故事发生的频率更高,但造成的损失则更少,因为 只关注特定的列。
- 考虑按索引过滤。 假设样本足够稀疏。 优先选择逐行记录,因为在这种情况下,为公司读取的有用信息的比例更好。
- 如果过滤得到更稠密的流量而只需要一小部分色谱柱,则逐级色谱柱将变得更便宜。 这些情况之间的鸿沟在哪里,如何确定?
换句话说,在任何情况下,我们假设的DBMS都不承担在行存储选项和列存储选项之间进行选择的责任,这应该由数据库设计者来完成。
但是,鉴于以上所述,数据库设计人员也将处于非常困难的选择中。 他会让我们很多人感到困惑。
如果呢
从本质上讲,按列和按行的变体(一种想法的极端情况)都将表切成“丝带”,并在每个磁带中逐行存储数据。 在一种情况下,磁带是一根,而在另一种情况下,磁带退化为一列。
因此,为什么不允许中间选项-如果某些列的数据在一起/读取,即使它们在同一磁带上也是如此。 如果磁带中没有数据(NULL),则无需存储任何内容。 同时,消除了最大行大小的问题-当该行可能不适合一页时,您可以拆分表。
这个想法不是那么原始,作者有机会看到它并亲自应用。 新颖性元素是使数据库设计人员能够确定如何将其表分成几部分,以及将数据以何种形式存储到磁盘。
我们为自己做了如下:
- 创建表时,有关我们的首选项的信息会使用编译指示传递给SQL处理器
- 最初,在创建表时,假定整行将位于B树的一页上
- 但是,您可以使用--#pragma page_break
为了告诉SQL处理器以下列将位于另一页上(在另一棵树中) - 用法--#pragma column_based
允许我们简洁地说,更远的列分别位于其自己的树上 - --#pragma row_based
取消基于列的操作 - 因此,该表由一个或多个B树组成,其第一个关键元素是隐藏的IDENTITY字段。 可以相信,创建记录的顺序(可能与读取记录的顺序很好地相关)也很重要,不应忽略。 主键是一棵单独的树,但是,这不适用于该主题。
在实践中如何看待?
例如,像这样:
CREATE TABLE twomass_psc ( ra double precision, decl double precision, …
例如,获取了地图集
2MASS的主表,
此处和
此处 都有图例。
J ,
H ,
K-红外子带,将数据一起存储在它们上是有意义的,因为在研究中它们是一起处理的。
例如 ,
在这里:
遇到的第一张照片。
或者
在这里 ,更加美丽:
是时候确认这在实际中是有意义的了。
结果
呈现如下:
- 在创建两个版本的表时将页(逻辑号)写入磁盘的过程的阶段图(已记录页面的X编号,较早记录的最后一个Y编号)
- 在列中,其指定为by_1
- 对于切成16列的表,将其指定为by_16
- 总列181

让我们仔细看看它是如何工作的:
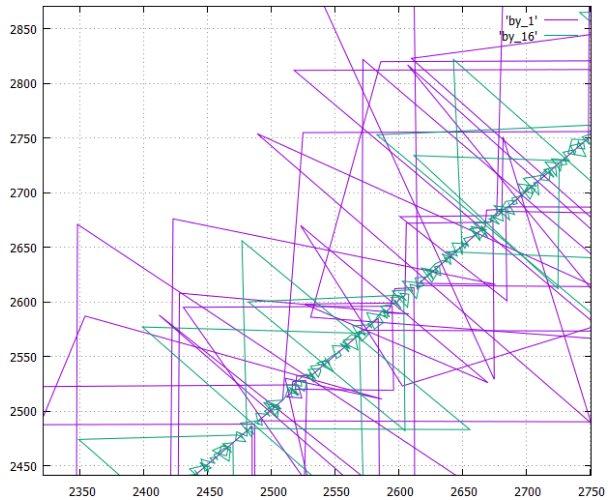
- by_16选项明显更紧凑,这是合乎逻辑的最终选择-line选项将仅给出一条直线(带有异常值)。
- 三角离群值-记录B树的中间页面。
- 显示了数据记录,显然,读数看起来像这样。
- 上面说过,所有选项都记录相同数量的信息,需要减去的流大约相同(±压缩效率)。
但是这里非常清楚地表明,在列式版本中,由于数据的特殊性,树木以不同的速度生长(在一列中它们经常重复并很好地压缩,在另一列中-从压缩器的角度来看是噪声)。 结果,有些树先行,有些则迟了;读取时,我们客观地得到了一种“撕裂”的读取模式,这对于文件系统来说是非常不愉快的。 - 因此,by_16比按列阅读更可取,在舒适度上与按行阅读几乎相等。
- 但是同时,在需要少量列的情况下,by_16变体的主要优点是逐列变体。 特别是如果您在分析联合使用的可能性后没有将机械表拆分为16张,而是有意义地进行拆分的话。
资料来源
[1] J. Martin。 计算系统中数据库的组织。 1978年世界
[2]
列索引,使用功能[3] Daniel J. Abadi,Samuel Madden,Nabil Hachem。
列存储与 RowStores:它们的真正区别是什么? ,ACM SIGMOD国际数据管理国际会议论文集,加拿大不列颠哥伦比亚省温哥华,2008年6月
[4]迈克尔·斯通布雷克(Michael Stonebraker),乌格·Çetintemel。
“一种尺码适合所有人”:一个时机已逝的想法 ,2005年