 蒙特祖玛的复仇Atari游戏等级
蒙特祖玛的复仇Atari游戏等级DeepMind
演示了学习AI(弱形式)以在Atari上传递游戏的过程。 通过演示YouTube视频游戏传递系统来完成培训。 许多由于某种原因而无法通过某种游戏的人类玩家都使用这种方法。
通常,为了解决这个问题,必须使用所谓的
强化学习方法。 该技术非常流行,因为它允许您训练机器人执行各种特定任务。 系统一旦获得任何结果,便会获得少量奖励。
开发人员创建的算法和模型可以评估游戏环境,包括完成游戏可能获得的奖励(积分,奖金等)。 这样的系统会逐步学习游戏,并逐步进入决赛。
DeepMind中开发的新方法不同于其他方法。 该公司的专家能够训练AI在Atari领导下玩游戏,例如Montezuma的Revenge,Pitfall和Private Eye。 同时,并未强调分数和奖品-培训在YouTube的教程中进行。 这使我们在AI方面取得了非同寻常的结果。
事实是,像“蒙特祖玛的复仇”这样的游戏很难被机器“理解”。 没有明确的任务,也不清楚去哪里,将来要收集哪些物品以及如何处理它们。 机器只是丢失了,因为在升级过程中它没有得到奖励,并且使用增强工具进行的培训在这里变得无用或几乎无用。
在上述游戏中,您需要控制一个名为Panama Joe的角色。 最后,他必须在旧庙里去库房。 相传这些珍宝属于蒙特祖玛。 首先,您需要找到传递游戏的第一个关键项目-金钥匙。 要检测到它,您需要执行大约100个步骤。 但这是如果您知道该怎么办。 如果没有,那么
18个初始动作中有100个的可能性很大。 对于人类创造的任何AI来说,这都是太多了。 好吧,您将不会在这里获得奖励,一切都非常非常具体。
让计算机知道该怎么做的一种方法是演示这段场景。 实际上,不仅汽车,人们还通过示例学习执行各种任务。 跳舞,艺术家的动作和焊接-所有这些最好只看一次,而不是听一百遍。
DeepMind得出的结论是,这是向计算机展示如何完成具有隐式结果的任务的最佳方法。 专家创造的技术确实有所帮助。 该示例使用了两种方法:TDC(时间距离分类)和CDC(跨模式时间距离分类)。
在第一种情况下,训练AI以确定游戏环境中的距离,以注意两个不同框架之间的差异。 AI还“了解”从一个地方移到另一个地方需要做什么。 为了在YouTube上进行培训,视频被随机分配了成对的帧。
在第二种情况下,还添加了声音伴奏的“理解”。 几乎所有游戏中的声音都与某些动作的执行相对应。 例如,跳跃,拿东西等等。 因此,训练计算机以将声音感知为重要的游戏元素。 视频和声音使计算机在传递游戏过程中表现出色。
这是经过训练的AI在蒙特祖玛的复仇中的动作。 开头提到的另外两场比赛的通过就
在这里 。
没错,不可能完全放弃奖励的作用-直到现在,人工智能都依赖于相同的观点。 但是,较早使用的通常的系统教学方法不允许至少获得金钥匙,为此,他给出了第一百分。 因此,AI就像瞎小猫一样,四面八方地戳着,不知道该怎么做。 的确,“加固”系统也已修改。
在传递AI游戏通过记录的每第16个视频帧的过程中,将其与人通过游戏的视频帧进行比较。 如果比较结果显示出高度相似性,则AI会获得奖励。 随着时间的流逝,AI开始执行与人相同的动作序列,以获得相似的帧。
而且,在许多情况下,AI都比人类玩家或其他通过算法(包括Rainbow,ApeX和DQfD)显示出更好的结果。
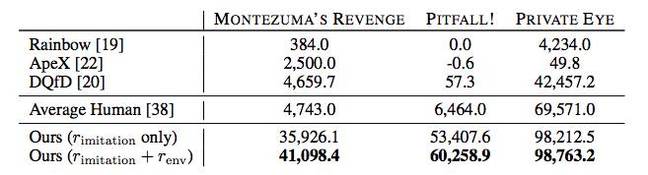
原则上,所有这些都是令人印象深刻的,但是到目前为止,DeepMind的成就的实际好处尚不清楚。 除了通过旧游戏以外,是否可以在其他任何地方使用公司提出的AI教学方法? 但是,知道了DeepMind在AI领域取得的成就后,毫无疑问,所有这一切都可以用于实际目的-专家们不太可能为了“乐趣”而开始研究该问题。