序言
当前,我正在开发Javascript模式编辑器,在此工作过程中,我遇到了本文将要解决的问题,即复杂数据对象的序列化和反序列化。
在不涉及项目细节的情况下,我注意到根据我的想法,方案是从基类继承的元素(顶点)的数组。 因此,每个子类都实现其自己的逻辑。 此外,顶点包含彼此的链接(箭头),这些链接也需要保留。 从理论上讲,顶点可以直接引用自己,也可以通过其他顶点引用。 标准JSON.stringify无法序列化这样的数组,因此我决定创建自己的序列化程序来解决上述两个问题:
- 能够在序列化期间保存类信息,并在反序列化期间恢复它。
- 保存和还原对象链接的能力,包括 循环的。
阅读更多有关该问题的陈述及其解决方案的信息。
Github序列化器项目
链接到github项目: link 。
复杂的示例也位于test-src文件夹中。
递归序列化器: link 。
平面序列化器: link 。
问题陈述
正如我已经指出的,最初的任务是为编辑器序列化任意电路。 为了不浪费时间描述编辑器,我们将任务设置得更容易。 假设我们要使用ES6 Javascript类对简单算法方案进行正式描述,然后对该方案进行序列化和反序列化。
在互联网上,我找到了确定两个值中最大值的最简单算法的合适图片:
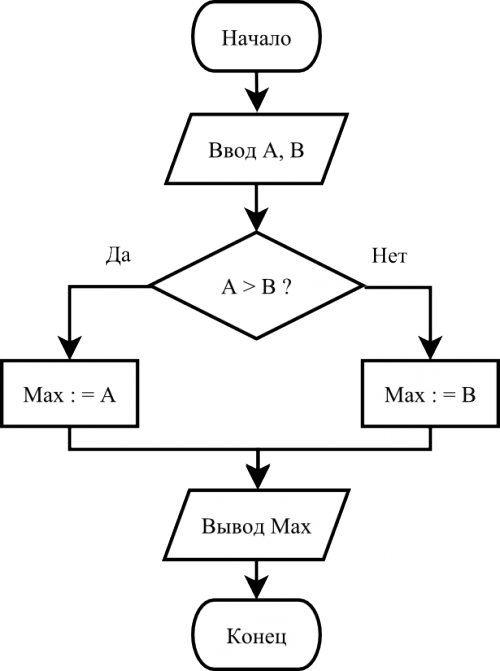
在这里我必须说我不是Java语言开发人员,而我的“本机”语言是C#,因此解决问题的方法取决于C#中面向对象开发的经验。 查看此图,我看到以下类型的顶点(条件名称和特殊角色不起作用):
- 开始顶点(开始)
- 最终高峰(完成)
- 队长(指挥官)
- 赋值顶点(让)
- 验证验证顶部(如果有)
这些顶点在数据集或语义上有一些区别,但是它们都是从基本顶点(节点)继承的。 在相同的地方,在Node类中,描述了links字段,其中包含到其他顶点的链接,并且addLink方法允许添加这些链接。 所有类的完整代码都可以在这里找到。
让我们编写从图片中收集电路的代码,然后尝试序列化结果。
如果我们使用JSON.stringify序列化此模式,我们将得到可怕的结果。 我将给出结果的前几行,并在其中添加我的评论:
JSON.stringify结果 [ { "id": "d9c8ab69-e4fa-4433-80bb-1cc7173024d6", "name": "Start", "links": { "2e3d482b-187f-4c96-95cd-b3cde9e55a43": { "id": "2e3d482b-187f-4c96-95cd-b3cde9e55a43", "target": { "id": "f87a3913-84b0-4b70-8927-6111c6628a1f", "name": "Command", "links": { "4f623116-1b70-42bf-8a47-da1e9be5e4b2": { "id": "4f623116-1b70-42bf-8a47-da1e9be5e4b2", "target": { "id": "94a47403-13ab-4c83-98fe-3b201744c8f2", "name": "If", "links": { ...
因为 第一个顶点包含到第二个顶点的链接,也包含到第二个顶点的链接,然后由于其序列化,整个电路被序列化。 然后,第二个峰被序列化,所有与之相关的序列,依此类推。 您可以仅通过标识符从此哈希还原原始链接,但是如果任何一个顶点直接或通过其他顶点引用自身,则它们将无济于事。 在这种情况下,序列化程序将引发Uncaught TypeError:将循环结构转换为JSON错误。 如果不清楚,下面是生成此错误的最简单示例: https : //jsfiddle.net/L4guo86w/ 。
此外,JSON不包含有关源类的任何信息,因此无法了解序列化之前每个顶点的类型。
意识到这些问题后,我上网了,开始寻找现成的解决方案。 有很多,但大多数都非常笨重,或者需要对可序列化类进行特殊描述,因此决定自己制造一辆自行车。 是的,我喜欢自行车。
序列化器概念
本部分适用于那些想与我一起创建序列化算法的人,尽管实际上是这样。
Javascript的问题之一是缺少可在C#或Java(属性和反射)等语言中实现奇迹的元数据。 另一方面,我不需要具有定义可序列化字段,验证和其他芯片列表的功能的超复杂序列化。 因此,主要思想是向对象添加有关其类型的信息,并使用普通的JSON.stringify对其进行序列化。
在寻找解决方案时,我遇到了一篇有趣的文章,其标题翻译为“ 6种在JSON中添加类型信息的错误方法” 。 实际上,这些方法非常好,我选择了第5种方法。如果您懒于阅读本文,但是我强烈建议您这样做,那么我将简要描述该方法:序列化一个对象时,我们将其包装在另一个对象中名称格式为"@<type>"的字段,该值是对象的数据。 反序列化期间,我们提取类型名称,从构造函数中重新创建对象,然后读取其字段的数据。
如果我们从上面的示例中删除链接,则标准JSON.stringify会像这样对数据进行序列化:
JSON.stringify [ { "id": "d04d6a58-7215-4102-aed0-32122e331cf4", "name": "Start", "links": {} }, { "id": "5c58c3fc-8ce1-45a5-9e44-90d5cebe11d3", "name": "Command", "links": {}, "command": " A, B" }, ... }
我们的序列化器将像这样包装它:
序列化结果 [ { "@Schema.Start": { "id": "d04d6a58-7215-4102-aed0-32122e331cf4", "name": "Start", "links": {} } }, { "@Schema.Command": { "id": "5c58c3fc-8ce1-45a5-9e44-90d5cebe11d3", "name": "Command", "links": {}, "command": " A, B" } }, ... }
当然,有一个缺点:序列化程序必须知道其可以序列化的类型,并且对象本身不应包含名称以狗开头的字段。 但是,第二个问题是通过与开发人员达成协议或用其他符号替换狗符号来解决的,而第一个问题是用一行代码解决的(下面将作为示例)。 我们确切知道将要序列化的内容,对吗?
解决链接问题
就算法而言,它仍然更简单,但是更难以实现。
当序列化在序列化器中注册的类的实例时,我们会将它们存储在缓存中并为其分配一个序列号。 如果将来再次遇到该实例,那么在第一个定义中,我们将添加此数字(字段名称将采用"@<type>|<index>" ),并在序列化的位置以对象的形式插入链接
{ "@<type>": <index> }
因此,在反序列化期间,我们将查看该字段的确切值。 如果这是一个数字,那么我们将根据该数字从缓存中提取对象。 否则,这是他的第一个定义。
让我们将链接从方案的第一顶部返回到第二顶部,并查看结果:
序列化结果 [ { "@Schema.Start": { "id": "a26a3a29-9462-4c92-8d24-6a93dd5c819a", "name": "Start", "links": { "25fa2c44-0446-4471-a013-8b24ffb33bac": { "@Schema.Link": { "id": "25fa2c44-0446-4471-a013-8b24ffb33bac", "target": { "@Schema.Command|1": { "id": "4f4f5521-a2ee-4576-8aec-f61a08ed38dc", "name": "Command", "links": {}, "command": " A, B" } } } } } } }, { "@Schema.Command": 1 }, ... }
乍一看似乎不太清楚,因为 首先在Link通信对象的第一个顶点内定义第二个顶点,但是这种方法起作用很重要。 此外,我创建了序列化器的第二个版本,该版本绕过树的深度不是宽度,而是宽度,从而避免了这种“梯子”。
创建序列化器
本部分适用于有兴趣实施上述思想的人员。
序列化器空白
像其他任何方法一样,我们的序列化器将有两种主要方法-序列化和反序列化。 另外,我们将需要一种方法来告诉序列化程序应该序列化的类(注册)和不应该序列化的类(忽略)。 为了不对DOM元素,JQuery对象或任何其他无法序列化或不需要序列化的数据类型进行序列化,后者是必需的。 例如,在我的编辑器中,我存储了对应于顶点或链接的可视元素。 它是在初始化期间创建的,并且当然不应该落入数据库中。
序列化程序外壳程序代码 export default class Serializer { constructor() { this._nameToCtor = [];
说明
要注册一个类,您必须通过以下两种方式之一将其构造函数传递给register方法:
- 注册(MyClass)
- 注册('MyNamespace.MyClass',MyClass)
在第一种情况下,类名称将从构造函数的名称中提取(IE中不支持),在第二种情况下,您自己指定名称。 第二种方法是可取的,因为 允许您使用名称空间,第一种是设计使然,可以使用重新定义的序列化逻辑来注册内置Javascript类型。
对于我们的示例,序列化器的初始化如下:
import Schema from './schema'; ...
Schema对象包含所有顶点类的描述,因此类注册代码仅占一行。
序列化和反序列化的上下文
您可能已经注意到了神秘的SerializationContext和DeserializationContext类。 是由他们来完成所有工作,并且主要是为了将数据与不同的序列化/反序列化过程分离开来,因为 对于每个呼叫,他们都需要存储中间信息-序列化对象的缓存和链接的序列号。
序列化上下文
我将仅详细分析递归序列化器,因为 它们的“扁平”对象在某种程度上更加复杂,并且仅在处理对象树的方法上有所不同。
让我们从构造函数开始:
constructor(ser) { this.__proto__.__proto__ = ser; this.cache = [];
我this.__proto__.__proto__ = ser;解释这条神秘线: this.__proto__.__proto__ = ser;
在构造函数的输入处,我们接受序列化程序本身的对象,并且此行从其继承我们的类。 这允许通过this访问序列化器数据。
例如, this._ignore引用序列化程序本身的被忽略类的列表(“黑名单”),这非常有用。 否则,我们将不得不编写类似this._serializer._ignore 。
主要序列化方法:
serialize(val) { if (Array.isArray(val)) {
应该注意的是,我们处理的数据有三种基本类型:数组,对象和简单值。 如果对象的构造函数在“黑名单”中,则该对象不会序列化。
阵列序列化:
serializeArray(val) { let res = []; for (let item of val) { let e = this.serialize(item); if (typeof e !== 'undefined') res.push(e); } return res; }
您可以通过map编写较短的文字,但这并不重要。 只有一件事很重要-检查未定义的值。 如果数组中存在不可序列化的类,那么如果不进行此检查,它将以未定义的形式落入数组中,这不是很好。 同样在我的实现中,数组被序列化而没有键。 从理论上讲,您可以优化用于序列化关联数组的算法,但是出于这些目的,我更喜欢使用对象。 另外,JSON.stringify也不喜欢关联数组。
对象序列化:
代号 serializeObject(val) { let name = this._ctorToName[val.constructor]; if (name) {
显然,这是串行器最困难的部分,它的核心。 让我们拆开。
首先,我们检查类构造函数是否已在序列化程序中注册。 如果不是,则这是一个简单的对象,将为其调用serializeObjectInner实用程序方法。
否则,我们检查对象是否被分配了唯一标识符__uuid 。 这是所有序列化程序都通用的简单计数器变量,用于在缓存中保留对类实例的引用。 您可以不使用它,而将实例本身本身不带密钥存储在高速缓存中,但是要检查对象是否存储在高速缓存中,则必须遍历整个高速缓存,这里足以检查密钥。 我认为就浏览器中对象的内部实现而言,这更快。 另外,我故意不序列化以两个下划线开头的字段,因此__uuid字段不会像其他私有类字段那样落入生成的json中。 如果这对于您的任务不可接受,则可以更改此逻辑。
接下来,通过__uuid的值,我们找到一个对象,该对象描述了高速缓存( cached )中类的实例。
如果存在这样的对象,则该值已在前面进行了序列化。 在这种情况下,如果之前没有这样做,我们将为该对象分配一个序列号:
if (!cached.index) {
该代码看起来很混乱,可以通过为我们序列化的所有类分配一个数字来简化代码。 但是对于调试和感知结果,最好将数字仅分配给将来有链接的那些类。
分配编号后,我们根据算法返回链接:
如果对象是第一次序列化的,我们将创建其缓存的实例:
let res; let cached = { ref: { [`@${name}`]: {} } }; this.cache[val.__uuid] = cached;
然后序列化它:
if (typeof val.serialize === 'function') {
该类将检查序列化接口的实现(将在后面讨论),以及Object.keys(cached.ref)[0]的构造。 事实是,cached.ref存储了指向包装对象{ "@<type>[|<index>]": <> } ,但是对象字段的名称对我们来说是未知的,因为 在此阶段,我们尚不知道名称是否包含对象编号(索引)。 该构造仅提取对象的第一个也是唯一的字段。
最后,序列化对象内部的实用方法:
serializeObjectInner(val) { let res = {}; for (let key of Object.getOwnPropertyNames(val)) { if (!(isString(key) && key.startsWith('__'))) {
我们创建一个新对象,并将字段从旧对象复制到其中。
反序列化上下文
反序列化过程以相反的顺序进行,不需要特殊注释。
代号 /** * */ class DeserializationContext { /** * * @param {Serializer} ser */ constructor(ser) { this.__proto__.__proto__ = ser; this.cache = []; // } /** * json * @param {any} val json * @returns {any} */ deserialize(val) { if (Array.isArray(val)) { // return this.deserializeArray(val); } else if (isObject(val)) { // return this.deserializeObject(val); } else { // return val; } } /** * * @param {Object} val * @returns {Object} */ deserializeArray(val) { return val.map(item => this.deserialize(item)); } /** * * @param {Array} val * @returns {Array} */ deserializeObject(val) { let res = {}; for (let key of Object.getOwnPropertyNames(val)) { let data = val[key]; if (isString(key) && key.startsWith('@')) { // if (isInteger(data)) { // res = this.cache[data]; if (res) { return res; } else { console.error(` ${data}`); return data; } } else { // let [name, id] = key.substr(1).split('|'); let ctor = this._nameToCtor[name]; if (ctor) { // res = new ctor(); // , if (id) this.cache[id] = res; if (typeof res.deserialize === 'function') { // res.deserialize(data); } else { // for (let key of Object.getOwnPropertyNames(data)) { res[key] = this.deserialize(data[key]); } } return res; } else { // console.error(` "${name}" .`); return val[key]; } } } else { // res[key] = this.deserialize(val[key]); } } return res; } }
附加功能
序列化介面
Javascript中没有接口支持,但是我们可以同意,如果该类实现了序列化和反序列化方法,则这些方法将分别用于序列化/反序列化。
另外,Javascript允许您为内置类型实现这些方法,例如,对于Date:
将日期序列化为ISO格式 Date.prototype.serialize = function () { return this.toISOString(); }; Date.prototype.deserialize = function (val) { let date = new Date(val); this.setDate(date.getDate()); this.setTime(date.getTime()); };
最主要的是要记住注册日期类型: serializer.register(Date); 。
结果:
{ "@Date": "2018-06-02T20:41:06.861Z" }
唯一的限制:序列化的结果不应为整数,因为 在这种情况下,它将被解释为对该对象的引用。
同样,您可以将简单的类序列化为字符串。 将描述颜色的Color类序列化为#rrggbb行的示例在github上 。
平面序列化器
亲爱的读者,尤其是对您来说,我写了序列化器的第二个版本 ,它没有深度地递归遍历对象树,而是使用队列遍历对象的宽度。
为了进行比较,我将给出在两种情况下我们方案的前两个顶点的序列化示例。
递归序列化器(深度序列化) [ { "@Schema.Start": { "id": "5ec74f26-9515-4789-b852-12feeb258949", "name": "Start", "links": { "102c3dca-8e08-4389-bc7f-68862f2061ef": { "@Schema.Link": { "id": "102c3dca-8e08-4389-bc7f-68862f2061ef", "target": { "@Schema.Command|1": { "id": "447f6299-4bd4-48e4-b271-016a0d47fc0e", "name": "Command", "links": {}, "command": " A, B" } } } } } } }, { "@Schema.Command": 1 } ]
平面串行器(串行化范围) [ { "@Schema.Start": { "id": "1412603f-24c2-4513-836e-f2b0c0392483", "name": "Start", "links": { "b94ac7e5-d75f-44c1-960f-a02f52c994da": { "@Schema.Link": { "id": "b94ac7e5-d75f-44c1-960f-a02f52c994da", "target": { "@Schema.Command": 1 } } } } } }, { "@Schema.Command|1": { "id": "a93e452e-4276-4d6a-86a1-0681226d79f0", "name": "Command", "links": {}, "command": " A, B" } } ]
就个人而言,我甚至比第一个更喜欢第二个选项,但应记住选择一个选项不能使用另一个选项。 都是关于链接的。 请注意,在平面串行器中,指向第二个顶点的链接位于其描述之前。
序列化程序的优缺点
优点:
- 序列化器代码非常简单和紧凑(大约300行,其中一半是注释)。
- 序列化器易于使用,不需要第三方库。
- 内置了对序列化接口的支持,以实现对类的任意序列化。
- 结果令人愉悦,令人赏心悦目(IMHO)。
- 用其他语言开发类似的序列化器/反序列化器不是问题。 如果序列化的结果在背面处理,则可能需要这样做。
缺点:
- 序列化程序需要注册可以序列化的类。
- 对对象的字段名有一些限制。
- 序列化器是用Java语言编写的noob,因此可能包含错误和错误。
- 大量数据的性能可能会受到影响。
另外要注意的是,代码是用ES6编写的。 当然,可以转换为Javascript的早期版本,但是我没有检查结果代码与不同浏览器的兼容性。
我的其他出版物
- 使用功能解释器在.NET上对项目进行本地化
- 用基于模型的数据填充文本模板。 .NET使用动态字节码(IL)函数的实现