补充:关于黑客新闻的很好的讨论GitHub上的David Yu开发了一个
有趣的性能测试,用于通过各种外部接口(外部功能接口,
FFI )进行的函数调用。
他用一个简单的C函数创建了一个共享库(
.so )文件,然后他编写了代码,以通过每个带有时间维度的FFI重复调用此函数。
对于C“ FFI”,他使用标准的动态链接,而不是
dlopen() 。 这种差异非常重要,因为它确实会影响测试结果。 您可以争辩说,这种比较与实际的FFI有多诚实,但是衡量仍然很有趣。
最令人惊讶的基准结果是
LuaJIT的 FFI
明显快于C。 它比共享对象函数的本机C调用快25%。 在基准测试C中,弱动态类型的脚本语言将如何超越? 结果准确吗?
实际上,这是很合逻辑的。 该测试在Linux上运行,因此延迟来自过程链接表(PLT)。 我准备了一个非常简单的实验来演示在普通的旧C语言中的效果:
https://github.com/skeeto/dynamic-function-benchmark以下是Intel i7-6700(Skylake)上的结果:
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/call有三种不同类型的函数调用:
- 通过PLT。
- 间接函数调用(通过
dlsym(3) ) - 直接函数调用(通过JIT编译函数)
如您所见,后者是最快的。 它通常不用于C程序中,但是在存在JIT编译器(包括LuaJIT)的情况下,它是自然的选择。
在我的基准测试中,
empty()函数称为:
void empty(void) { }
编译为共享对象:
$ cc -shared -fPIC -Os -o empty.so empty.c
与之前的
PRNG比较中一样 ,基准在警报响起之前会尽可能多地调用此函数。
程序布局表
当程序或库在另一个共享库中调用函数时,编译器无法知道此函数在内存中的位置。 仅当程序及其依赖项加载到内存中时,才在运行时找到信息。 通常,例如,根据地址空间的随机化(地址空间布局随机化,ASLR),功能位于随机位置。
如何解决这样的问题? 好吧,有几种选择。
其中之一是在二进制元数据中标记每个调用。 然后,动态运行时构建器
将在每个调用中
插入正确的地址。 具体机制取决于编译期间使用的
代码模型 。
这种方法的缺点是它减慢了加载速度,增加了二进制文件的大小,并减少了不同进程之间
的代码页交换 。 下载速度变慢,因为在启动程序之前,所有动态拨号对等方都需要使用正确的地址进行修补。 二进制文件过大,因为每个条目都需要在表中放置一个位置。 缺乏共享与代码页的更改有关。
另一方面,可以消除调用动态功能的开销,从而获得类似于JIT的性能,如基准测试所示。
第二种选择是通过表路由所有动态调用。 原始的拨号对等点引用此表中的存根,然后从那里到实际的动态功能。 使用这种方法,不需要对代码进行修补,从而导致进程之间的
琐碎交换 。 对于每个动态功能,您只需要修补表中的一条记录。 此外,可以在函数的第一次调用时
延迟进行这些校正,从而进一步加快了加载速度。
在ELF二进制系统上,此表称为过程链接表(PLT)。 PLT本身并未真正得到纠正-对于其余代码,它显示为只读。 而是,更正了全局偏移表(GOT)。 PLT存根从GOT检索动态功能的地址,并
间接跳转到该地址。 为了延迟加载功能地址,这些GOT条目会用找到目标字符的功能地址进行初始化,并用该地址更新GOT,然后继续执行功能。 后续呼叫使用延迟检测到的地址。
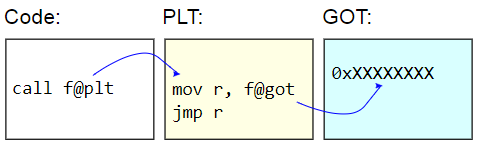
PLT的缺点是调用动态函数的额外开销,这是基准测试中出现的情况。 由于基准测试
仅测量函数调用,因此差异似乎相当大,但实际上,差异通常接近于零。
这是基准:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
由于
empty()位于共享对象中,因此调用将通过PLT。
间接动态通话
动态调用函数的另一种方法是遍历PLT并在程序中获取目标函数的地址,例如,通过
dlsym(3) 。
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
如果接收到函数地址,则开销小于通过PLT调用的函数。 存根和访问GOT没有中间功能。 (警告:如果程序具有此功能的PLT记录,则
dlsym(3)实际上可以返回存根地址)。
但这仍然是
间接的挑战。 在常规体系结构上,
直接函数调用接收其直接相对地址。 也就是说,调用的目的是相对于调用点的一些硬编码偏移。 CPU可以弄清楚调用将在何处进行。
间接调用的开销更大。 首先,该地址需要存储在某个地方。 即使只是寄存器,使用它也会增加寄存器不足。 其次,间接调用会在CPU中引起分支预测器,从而给处理器带来额外的负担。 在最坏的情况下,调用甚至可能导致管道停止。
这是基准:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
传递给该基准的函数是使用
dlsym(3)提取的,因此编译器无法
做一些棘手的事情 ,例如将间接调用转换为直接调用。
如果循环体足够复杂,从而导致寄存器不足,从而给堆栈提供地址,那么该基准也不能与PLT基准进行诚实地比较。
直接函数调用
动态函数调用的前两种类型简单易用。
直接调用动态函数更难以组织,因为它们在执行过程中需要更改代码。 在我的基准测试中,我组合了一个
小的JIT编译器来生成直接调用。
诀窍是在x86-64上,由于32位带符号操作数(带符号立即数),显式转换限制在2 GB范围内。 这意味着JIT代码应几乎放置在目标函数(
empty()旁边。 如果JIT代码必须调用两个不同的动态函数(除以2 GB以上),则不可能进行两次直接调用。
为了简化这种情况,我的基准测试并不担心JIT代码地址的准确或非常仔细的选择。 接收到目标函数的地址后,它只需减去4 MB,将其四舍五入到最近的页面,分配一点内存并向其中写入代码。 如果一切都按计划进行,那么要找到一个位置,您需要检查自己的程序在内存中的表示形式,而这不能以干净,可移植的方式完成。 Linux
需要在/ proc下解析虚拟文件 。
这就是我的JIT内存分配的样子。 它假定
强制转换uintptr_t的行为 :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
这里有两页引人注意:一页用于编写,而另一页则具有不可写的代码。 就像在我
的闭包库中一样 ,此页面的底部是可写的,并且包含一个
running变量,该变量重置为Alarm。 该页面应该在JIT代码旁边,以便提供有关RIP的有效访问,这是其他两个基准测试中的功能。 首页包含此汇编代码:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty是唯一动态生成的指令,必须正确填写相对地址(相对于指令
末尾指示负5):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
如果
empty()函数不在通用对象中,而是在同一二进制文件中,则本质上这是编译器将为
plt_benchmark()生成的直接调用,假定由于某种原因它没有内置
empty() 。
具有讽刺意味的是,调用JIT编译的代码需要间接调用(例如,通过函数指针),而这没有办法。 我在这里能做什么,JIT编译另一个函数以直接调用? 幸运的是,这并不重要,因为在循环中仅测量直接调用。
没有秘密
鉴于这些结果,很明显,为什么LuaJIT生成比PLT更有效的动态函数调用,
即使它们仍然是间接调用 。 在我的基准测试中,没有PLT的间接呼叫比使用PLT的速度快28%,没有PLT的直接呼叫比使用PLT的速度快43%。 由于绝对拒绝进程之间的代码交换,因此实现了JIT程序相对于简单的旧本机程序的小优势。