Anti-Plagiarism系统是一个专门的搜索引擎。 与搜索引擎一样,具有自己的引擎和搜索索引。 当然,就来源数量而言,我们最大的索引是俄语。 相当久以前,我们决定将所有文字(不是图片,音乐或视频),俄语文字,大小大于1 kb的内容(而不是“几乎重复的”内容)放入索引中已经在索引中。
这种方法的好处在于不需要复杂的预处理,并且最大程度地降低了“用水泼婴儿”的风险-跳过可能会借用文本的文档。 另一方面,结果是,我们几乎不知道最终将哪些文档包含在索引中。
随着Internet索引的增长-现在,仅一秒钟它已经超过3亿个
俄语文档-出现了一个完全自然的问题:此转储中是否有很多真正有用的文档?
既然我们(
yury_chekhovich和
Andrey_Khazov )接受了这种反思,那么为什么我们不同时回答另外几个问题。 索引了多少科学文献,以及多少不科学的文献? 科学论文在文凭,论文,摘要中所占的份额是多少? 按主题分布的文件是什么?

由于我们讨论的是数亿个文档,因此有必要使用自动数据分析的手段,尤其是机器学习技术。 当然,在大多数情况下,专家评估的质量优于机器方法,但要吸引人力资源来解决如此繁重的任务将太昂贵。
因此,我们需要解决两个问题:
- 创建一个“科学”过滤器,一方面,该过滤器使您可以自动丢弃结构和内容之外的文档,另一方面,可以确定科学文档的类型。 立即做出保留,即在“科学性”下绝不表示结果的科学意义或可靠性。 筛选器的任务是分离具有科学文章,学位论文,文凭等形式的文档。 来自其他类型的文本,即小说,新闻文章,新闻文章等;
- 实施用于对科学文献进行分类的工具,该工具将文件与科学专业之一(例如, 物理和数学 , 经济学 , 建筑 , 文化研究等)相关联。
同时,我们需要通过专门处理文档的文本支持来解决这些问题,而不是使用它们的元数据,有关文档中文本块和图像位置的信息。
让我们举例说明。 即使是粗略的浏览也足以区分
科学文章
例如来自
儿童的童话故事 。

但是,如果只有文本层(对于相同的示例),则必须阅读内容。
科学过滤和按类型排序
我们按顺序解决任务:
- 在第一阶段,我们过滤掉非科学文献;
- 在第二阶段,所有被确定为科学的文档都按类型进行分类:文章,候选人论文,博士学位摘要,文凭等。
看起来像这样:
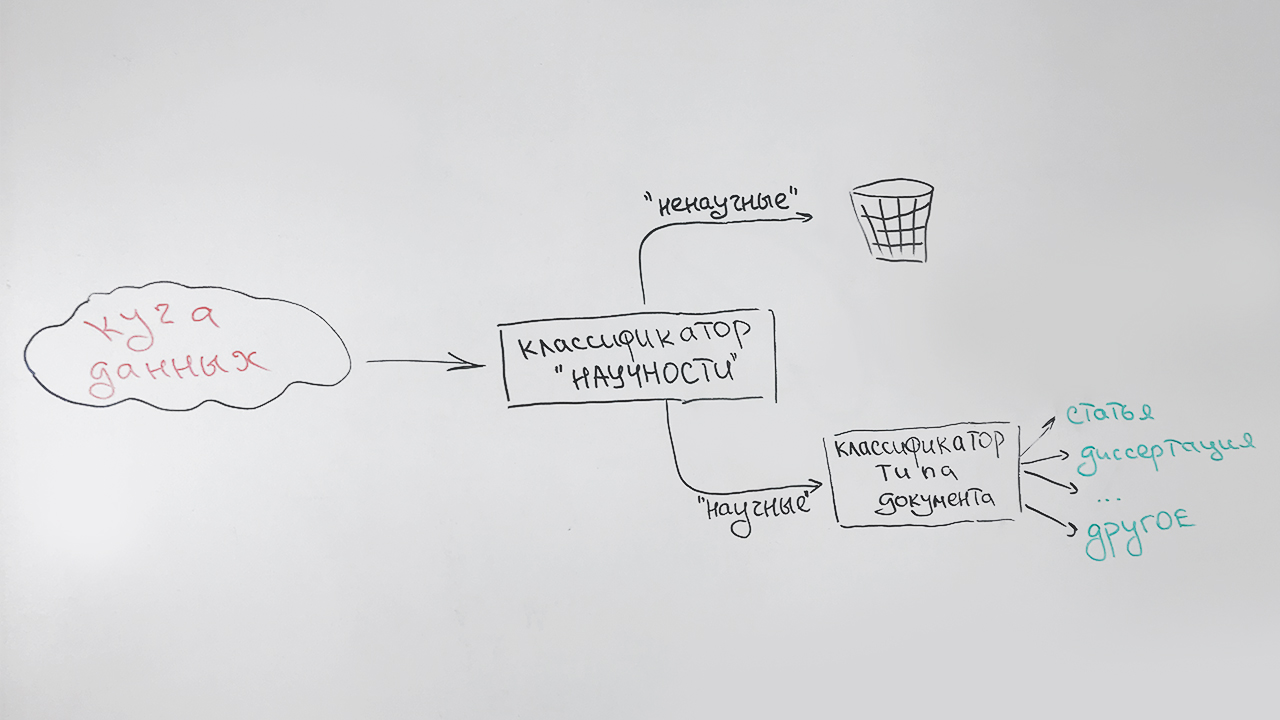
特殊类型(未定义)被分配给不能可靠地归于任何一种类型的文档(这些主要是简短的文档-科学站点的页面,摘要摘要)。 例如,此出版物将归因于这种类型,这种类型具有一定的科学性,但与上述任何一种都不相似。
必须考虑另一种情况。 这是算法的高速和低资源需求-尽管如此,我们的任务是辅助的。 因此,我们使用非常小的文档说明性描述:
- 文本中句子的平均长度;
- 停用词相对于文本中所有词的份额;
- 可读性指标 ;
- 标点符号相对于文本所有字符的百分比;
- 文本开头部分中列表中单词的数量(“摘要”,“学位论文”,“文凭”,“证书”,“专业”,“专着”等)(属性负责标题页);
- 文本最后部分中列表中单词的数量(“列表”,“文学”,“书目”等)(该属性负责文献列表);
- 文字在文字中的比例;
- 平均字长
- 文字中唯一字的数量。
所有这些符号都很好,因为它们可以快速计算出来。 作为分类器,我们使用随机森林算法(
Random forest ),这是机器学习中一种流行的分类方法。
在没有专家标记的样本的情况下进行质量评估很困难,因此我们将分类器放入科学电子图书馆
Elibrary.ru的文章收集中。 我们假设所有文章都将被视为科学文章。
结果是100%? 没什么-只有70%。 也许我们创建了错误的算法? 我们浏览筛选的文章。 事实证明,许多不科学的文本都发表在科学期刊上:社论,对周年的祝贺,ob告,食谱甚至星座运势。 选择性查看分类器被认为是科学的文章不会显示错误,因此,我们认为分类器是合适的。
现在我们承担第二项任务。 在这里,您不能缺少高质量的培训材料。 我们要求评估者准备样品。 我们得到了超过3.5千个文档,分布如下:
| 文件类型 | 样本中的文件数 |
|---|
| 文章 | 679 |
| 博士学位论文 | 250 |
| 博士学位论文摘要 | 714 |
| 科学会议集锦 | 75 |
| 博士论文 | 159 |
| 博士论文摘要 | 189 |
| 专着 | 107 |
| 学习指南 | 403 |
| 论文 | 664 |
| 未定义类型 | 514 |
为了解决多类分类问题,我们使用相同的随机森林和相同的特征,以免计算出一些特殊的东西。
我们得到以下分类质量:
下图显示了将训练有素的算法应用于索引数据的结果。 图1显示,馆藏中一半以上是科学文献,而其中一半以上是文章。
 图 1.以“科学”方式分发文件
图 1.以“科学”方式分发文件图2显示了科学文献按类型的分布,“文章”类型除外。 可以看出,第二流行的科学文献类型是教科书,而最稀有的是博士学位论文。
 图 2.按类型分列的其他科学文献
图 2.按类型分列的其他科学文献总的来说,结果符合预期。 通过快速的“粗糙”分类器,我们不再需要。
文件主题的定义
碰巧的是,尚未创建统一的,公认的科学作品分类器。 今天最受欢迎的是
VAK ,
GRNTI ,
UDC的标题。 为了以防万一,我们决定将这些主题按主题分类。
为了建立主题分类器,我们使用基于
主题建模的方法,这是一种统计方法,用于为文本文档的集合构建模型,其中针对每个文档确定其属于某些主题的概率。 作为构建主题模型的工具,我们使用
BigARTM开放库。 我们之前已经使用过该库,并且我们知道它对于大量文本文档的主题建模非常有用。
但是,有一个困难。 在主题建模中,确定主题的组成和结构是解决与特定文档集合有关的优化问题的结果。 我们不能直接影响他们。 自然,调整到我们的集合所产生的主题将与任何目标分类器都不对应。
因此,为了获得特定请求文档的注释者的最终未知值,我们需要执行一次其他转换。 为此,在BigARTM主题空间中,使用最近邻居算法(
k-NN ),查找与最熟悉的带摩擦符的查询最相似的几个文档,并在此基础上为查询文档分配最相关的类。
该算法以简化形式显示在图中:

为了训练该模型,我们使用来自开放源的文档以及Elibrary.ru提供的数据以及UDC SRSTI高级认证委员会的知名专业知识。 我们从收集器中删除了与磨擦者的非常普遍的职位相关的文档,例如,
自然科学和精确科学的一般和复杂问题 ,因为此类文档会极大地干扰最终的分类。
最终收集的内容包括每个主题的约28万份培训文档和6000份测试文档。
就我们的目的而言,对于我们来说,预测第一级标题的值就足够了。 例如,对于GRNTI值为
27.27.24:谐波函数及其泛化的文本,第
27节
:数学 的预测是正确的。
为了提高开发算法的质量,我们在原有的
朴素贝叶斯分类器的基础上增加了两种方法。 作为符号,它使用具有特定HAC标题值的每个文档最具特征的单词出现频率。
为什么这么辛苦? 结果,我们将两种算法的预测结果进行加权,并对每个请求产生平均预测结果。 机器学习中的这项技术称为
集成 。 这种方法使我们的质量明显提高。 例如,对于SRSTI规范,原始算法的准确性为73%,朴素的贝叶斯分类器的准确性为65%,它们的关联为77%。
结果,我们得到了这样的分类器方案:
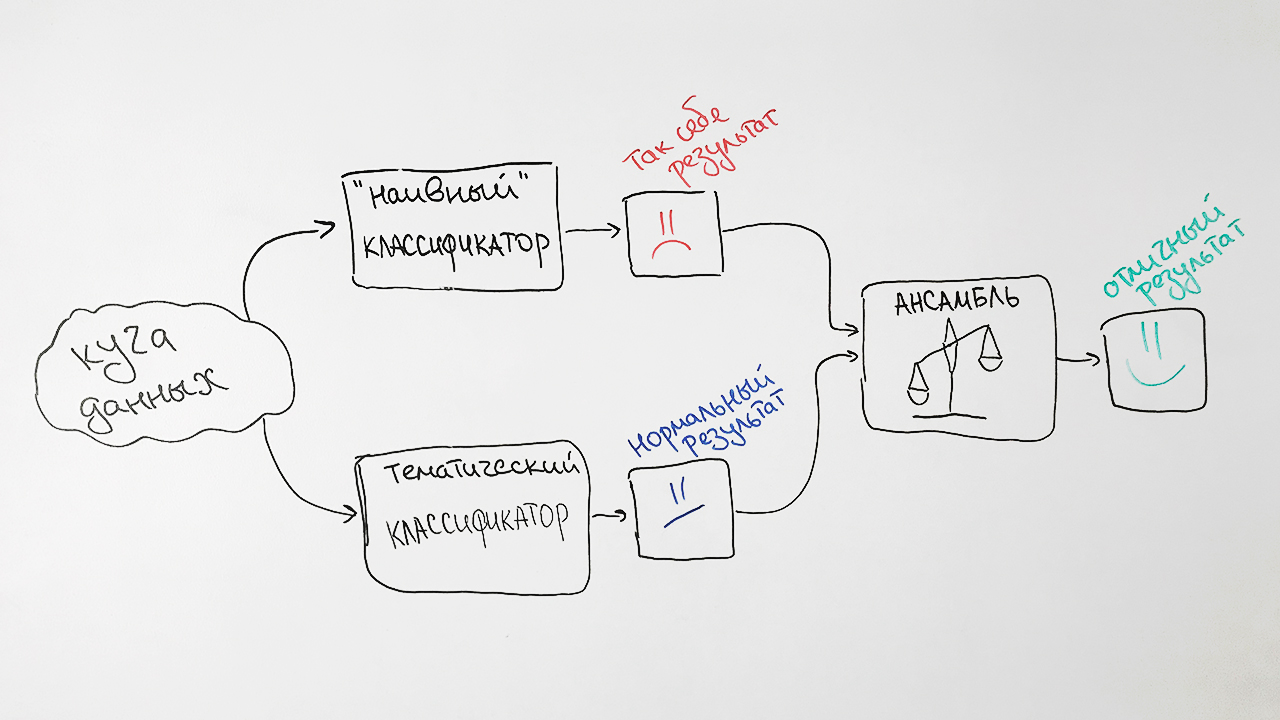
我们注意到影响分类器结果的两个因素。 首先,可以一次为任何文档分配一个以上的摩擦值。 例如,高级认证委员会的标题值为25.00.24和08.00.14(
经济 ,
社会和政治地理以及
世界经济 )。 那不会是一个错误。
其次,在实践中,专栏的值是专业地,主观地放置的。 一个明显的例子是
机械工程和
农业与林业等看似相似的主题。 我们的算法将标题
为“森林砍伐机器”和
“针对西北地区条件开发标准尺寸系列拖拉机的前提条件 ”的文章分类为机械工程,并根据原始布局将它们精确地指代农业。
因此,我们决定显示每个类别的前3个最有可能的值。 例如,对于
“专业教师宽容(以多民族学校的俄语教师的活动为例)”一文,高级认证委员会负责人的价值观
的可能性如下:
| 造价者的价值 | 机率 |
|---|
| 教育科学 | 47% |
| 心理科学 | 33% |
| 文化研究 | 20% |
结果算法的准确性为:
| 专栏 | 前三名的准确性 |
|---|
| 科学技术研究院 | 93% |
| 瓦克 | 92% |
| UDC | 94% |
这些图显示了对所有(图3)和仅科学(图4)文档在俄语语言Internet索引中文档主题分布的研究结果。 可以看出,大多数文献都与人文有关:最常见的规范是经济学,法律和教育学。 而且,仅在科学文献中,它们所占的份额甚至更大。
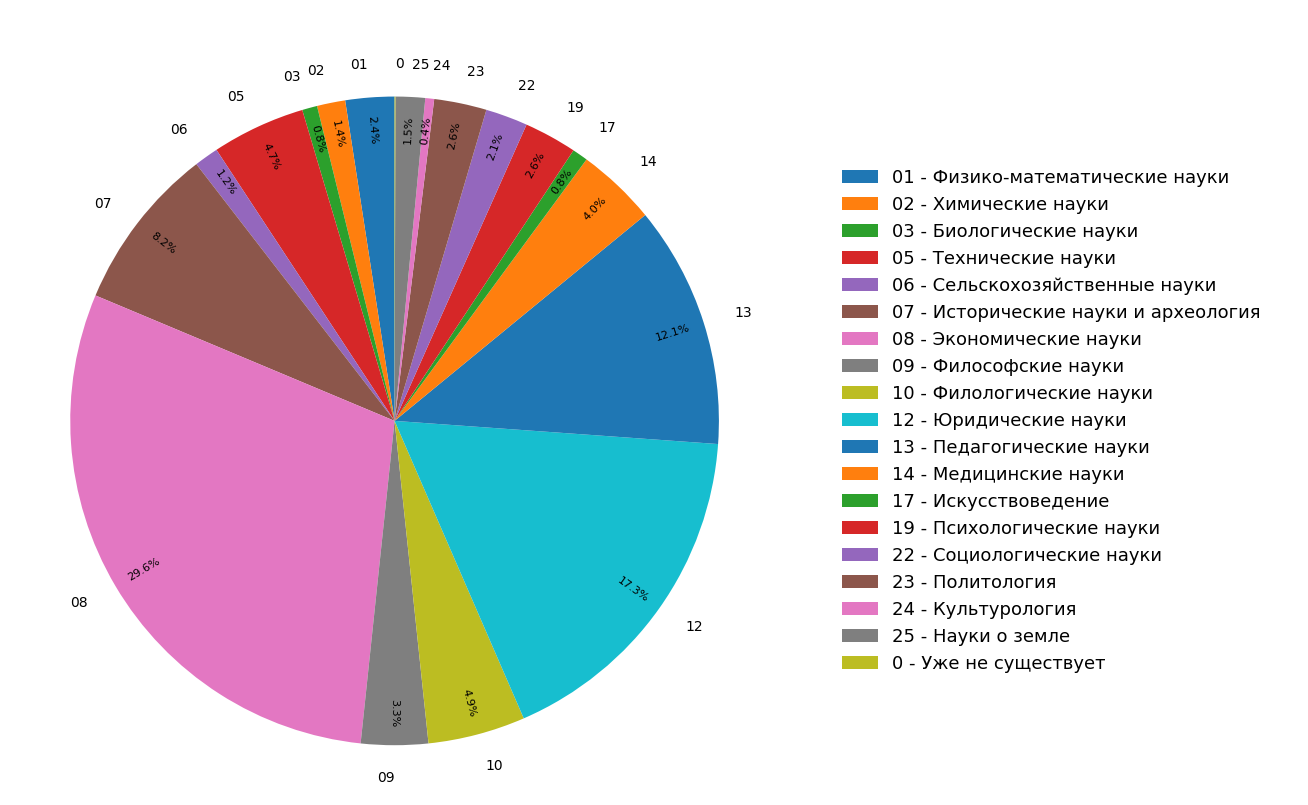 图 3.在整个搜索模块中分配主题
图 3.在整个搜索模块中分配主题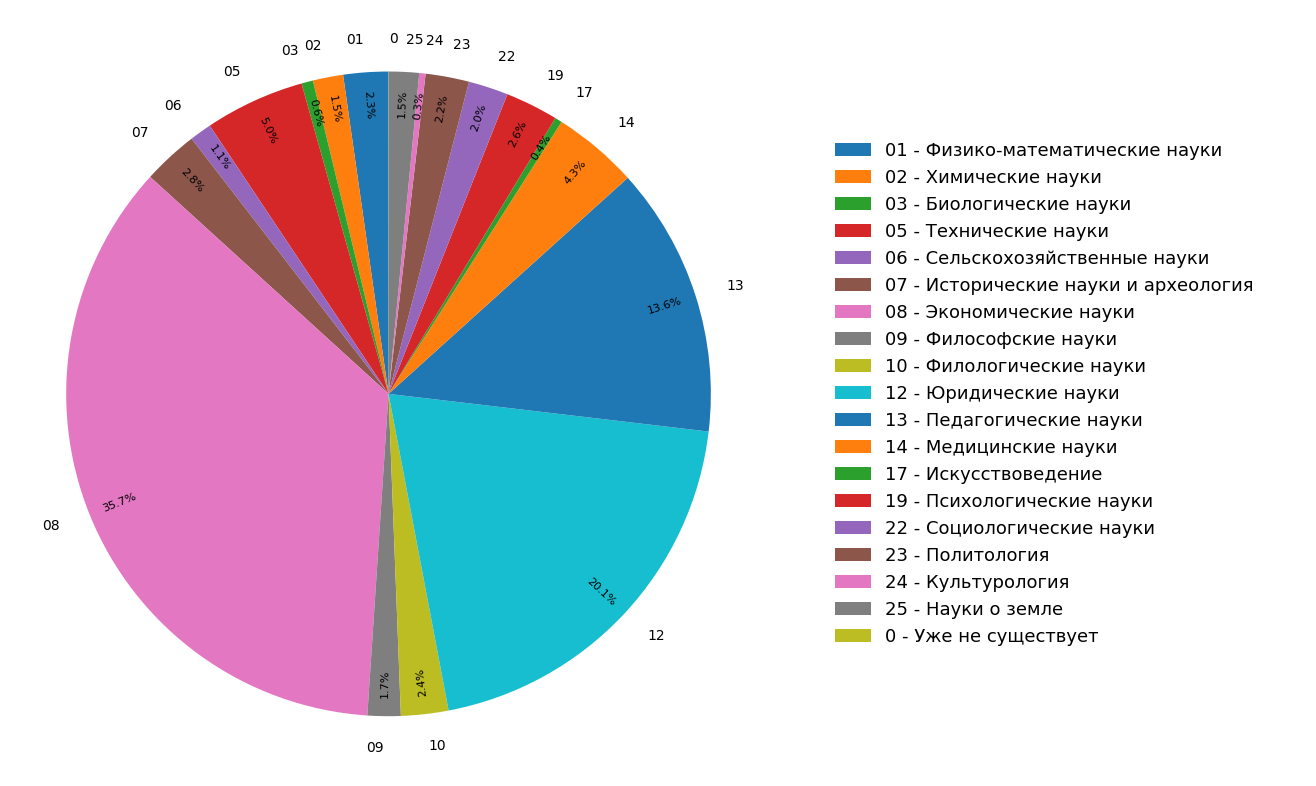 图 4.分发科学文献的主题。
图 4.分发科学文献的主题。结果,从字面上看,我们不仅从中学到了索引互联网的主题结构,而且还提供了附加功能,您可以利用这些功能将文章或其他科学文献立即“分类”为三个主题类别。

上面描述的功能现在正在Anti-Plagiarism系统中积极实施,并将很快对用户可用。