NoSQL的趋势已经有近10年的历史了,您可以放心地得出任何结论和概括。 我们将做这件事,并讨论NoSQL的发展。
回想一下NoSQL是如何诞生的。 让我们看看其中有什么好事和坏事,以及经受住时间考验的是什么。 让我们分析一下SQL中已经存在的功能,这些功能现在出现在NoSQL DBMS中。 我们着重介绍NoSQL的独特价值,并展望未来市场上将发生的事情。
Tarantool DBMS的开发人员和架构师Konstantin Osipov(
@kostja )在RIT ++ 2017的报告中谈到了NewSQL趋势,将为我们提供帮助,因为架构师应该了解数据库世界中正在发生的事情,至少重新发明轮子。
关于发言人 :现在,康斯坦丁·奥西波夫(Konstantin Osipov)正在从事Tarantool的开发工作,但之前曾参与MySQL的开发,当康斯坦丁(Konstantin)开始研究新数据库时,他非常困惑为什么应该这样做,为什么需要下一个数据库。 特别是,对于“ SQL下”,对NoSQL的态度非常怀疑。
但是,发展仍在继续,一些原始原则消失了,与此同时,NoSQL数据库取代了传统SQL的功能。 根据这几年快速转型的结果,很有可能得出中间结果,并让自己对未来做出一些预测。
计划
NoSQL原则
现在,许多人都在尝试使用NoSQL术语,但是当
#nosql标签出现时,它在2009年被广泛采用。 Last.FM的开发人员为分布式数据库mitap发明了此标签。
此后,该标签开始在Twitter上流行起来,NoSQL成为人们沮丧的排水槽或漏斗,正如我所说的那样-沮丧已经在使用传统数据库的许多年中积累了下来。
NoSQL是解决问题的出路,每个没有足够SQL功能的人都可以使用此标签。
需要以某种方式构造这种挫败感,并确定大多数人在传统DBMS中不喜欢它。 对于创建NoSQL的解决方案,我们可以区分3个大任务块:
让我们看看这些块是什么。 以键值数据库为例。 键值数据模型的主要思想是数据库很简单,但是具有可伸缩性。 大量的问题落在开发人员的肩膀上,但是他有严格的保证,他的数据库将是
无限可扩展的 。 但是,无限的可扩展性不是魔术。 由于
所支持操作的
语义非常简单,因此可以确保可伸缩性:在键值数据库中,任何操作都只会影响一个群集节点。
最初,社区很难将数据模型与规模模型分开。 如果您使用相同的Cassandra,则在早期版本中,其数据模型称为宽列存储-宽列数据库。 如果DBMS的键值中有一个索引(按键),那么在宽列存储中总是自动创建两个索引:按键和按列族。
此外,按键索引是可分割的,按列族索引对于特定数据节点是本地的。 因此,我们实现了水平缩放,但同时获得了对列族执行本地查询的机会。 老人们记得,Oracle在维护关系模型的同时实现了类似的功能,称为联接表。 通过此功能,可以在连接表中为两个表指定物理布局。 Cassandra中的宽列存储-实现在整个集群中自动分布的联接表。
数据模型和规模模型的合并正是使用关系模型解决的问题。 欢迎来到70年代。
除了新的数据模型,NoSQL还实现了新的一致性模型。 是的,是的,再次是这个著名的
CAP定理 。 一直在谈论CAP定理,这让我很开心-谁需要它? 由于没有第二种新鲜度的st鱼,因此关于数据一致性的问题没有其他答案,只有一个:
数据库必须保证这种一致性 。 因此,在我看来,新的一致性模型也正在逐渐消失。
今天的NoSQL
我首先要表达的观点是整个NoSQL运动幸存下来的观点:
- 水平缩放;
新的数据模型文档和图形数据模型;新的一致性模型。
在有关新数据模型的论文中,几乎有一半幸免于难,关于一致性模型的论点完全死了。
死亡上限
为什么某些一致性模型无法生存?
●
最终一致性:长期通胀谁使用具有工作向量时钟的数据库,而应用程序的业务逻辑适合于此? -没有人 谁使用的数据库具有CRDT(无冲突的复制数据类型)? 谁在使用Riak? -没有人 人们使用什么? PostgreSQL较多,其他基础较少,例如MongoDB。
●
MongoDB:原子被替换为隔离,事务在3.xx中添加该数据库具有异步复制。 这是一件很容易理解的事情,尽管实际上,
异步复制有4种类型 。 在本地提交事务后,可以进行事务数据的复制。 在本地提交事务之前。
即,也可以以不同的方式使对主数据库的提交点与对副本的提交点相关。
已经在本地日志中输入了一个条目,但尚未输入副本。 假设您要等待她至少飞走到副本。 飞走-并不意味着飞。 到达-这并不意味着它已被写入副本上的本地日志。
最初,MongoDB有一种模式:请求到达服务器,数据库回答OK-它甚至还没有到达磁盘,也没有到达日志-它什么都没走。 因此,一切工作都非常迅速,但是后来他们开始为此批评MongoDB,并且默认情况下,在更高版本的3+中,毕竟它首先开始将事务写入日志,然后才向客户端发送确认。
也就是说,即使异步复制也是语义模型的深渊。 因此,
一致性模型过于复杂,以至于广大开发人员都无法理解,并且事务和同步复制正在取代各种奇特的模型 。
在一致性模型失效的背景下,实际上更严格的一致性的发展仍存在有趣的趋势。 Redis中有事务,尽管我不会将它们称为事务,但是以实际事务为代价,没有事务就存在争议。
让我们看看NoSQL中的事务历史。 最初,MongoDB实现了文档级原子性。 然后添加了隔离的执行模式,以允许开发人员(如果他们确实想要)原子地更新几个文档。
●
Redis交易在NoSQL诞生之初,开发人员被要求将整个业务案例放在一个篮子文档中。 出现了称为域驱动设计的整个流程,该流程将这种转变提升到设计模式的等级。 实际上,如果将所有内容都存储在一个文档中,那么原子性就可以轻松实现:您完成了一项交易,一个业务流程,并且在一个文档中进行了一次原子更改。
但是事实证明这是行不通的。 需要对数据进行标准化以避免存储冗余。 对于分析查询,需要对其进行标准化。 最后,数据模型正在发展-昨天可以保存今天的业务场景所需的所有信息的文档需要扩展和补充。
原子性问题说明了吗? 数据模型与一致性模型有多紧密的联系-事务和同步复制的出现使得NoSQL中的大多数模型都是不必要的。
资料模型
现在让我们谈论下一个故事-数据模型的故事。
SQL之后发明的数据模型组:
- 关键值
- 纪录片
- 宽列存储;
- 数据结构服务器(用于Redis);
- 图形数据库。
好酷! 我们有这么多的数据模型! 它们的伸缩性如何?
这是一个理论,主要与所谓的超融合有关,当时所有现代项目都使用便宜的单服务器服务器,而企业则停止购买垂直可扩展的机器。
超融合已经深入我们的生活,以至于如今即使在垂直扩展的计算机中(如果有),也已经存在水平可扩展的软件-查看PureStorage的工作方式,或者,如果记得,还可以在夜间查看Nutanix。 当然,他们将柜子卖给人们,但是这些柜子像托管服务提供商的普通机架一样布置在内部。
也就是说,水平缩放是一种趋势,向所有人(包括新数据模型的发明者)施加压力。 那么哪些数据模型适合水平缩放,哪些不好?
水平缩放是好是坏? 答案实际上是有争议的,我们稍后会再讨论。
雷迪斯
当Redis添加Redis集群时,事实证明并非所有数据模型操作都可以正常水平扩展。

这是从文档中引用的一句话,他们在其中写道,某些功能适用于特定的分片,而某些功能实际上适用于实际的集群。
这种方法的基本问题与MySQL中的相同,我们进行了握手。 也就是说,开发人员具有两个数据模型:
- 在其中之一中,他在关系代数的框架内进行思考。
- 然后,当他考虑独立分片时,便会考虑分片相关代数的数据模型。
一个好的数据模型应该是通用的 。 关系代数的优点-投影的结果是一个关系,任何算子的结果都是一个关系。 而且,一旦我们手动开始将MySQL分片到集群上,我们就失去了它。
但是,Redis添加Redis集群是因为
每个人都希望水平缩放 。
图形数据库
图数据库是一个很好的示例,可帮助
分离计算和存储的水平缩放概念 。 信息总是可以除以任意数量的节点。 但是,如果数据库本质上是为处理其存储的数据而设计的,并且这些计算未进行水平缩放,则将出现有效的水平存储问题,从而使计算无法正常工作。
让我们看一下缩放图DBMS的问题-SQL DBMS面临着非常相似的缩放障碍。
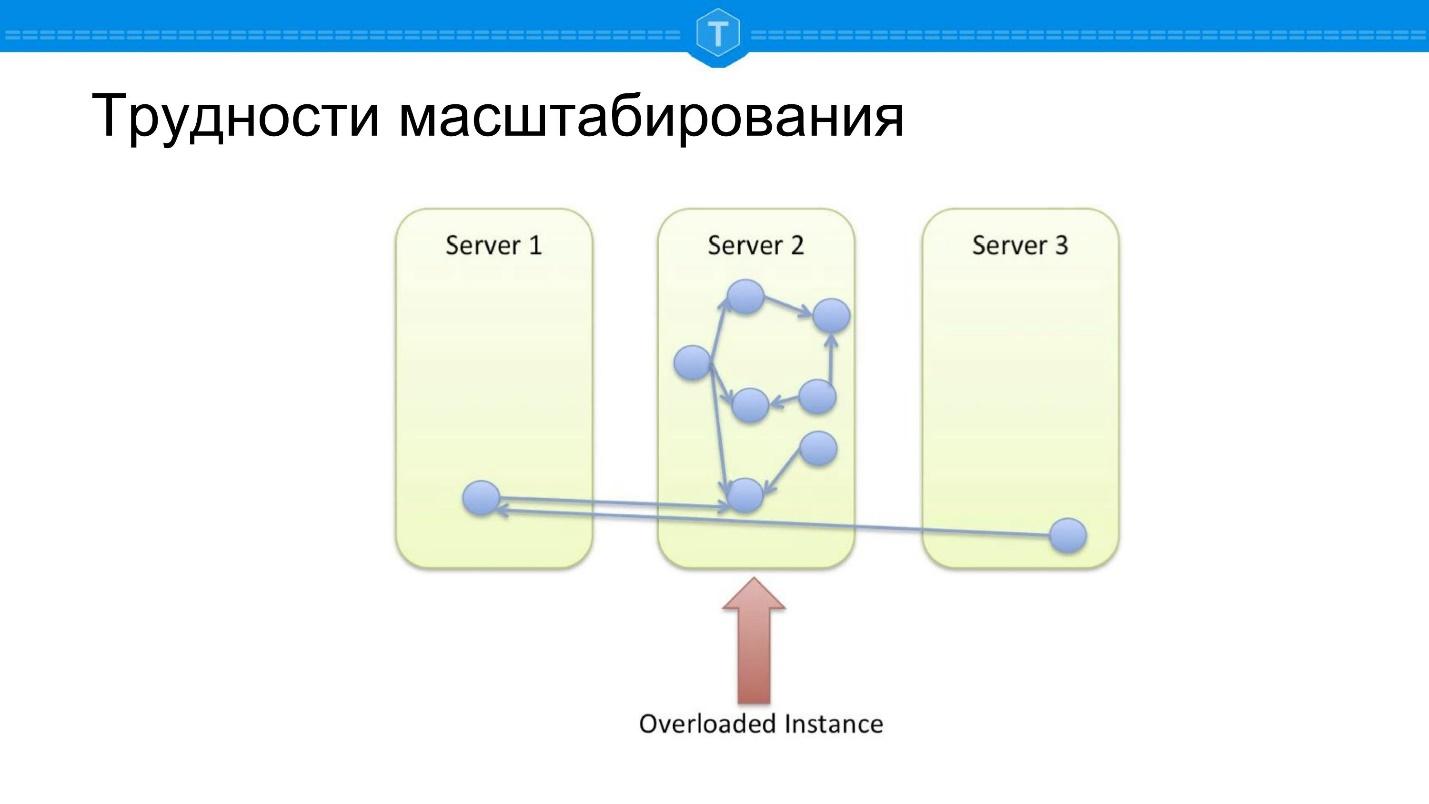
以存储图形的本地数据库为例。 早晚填充一个节点,然后我们开始使用其他节点。 一旦使用多个节点,中心节点就会过载,因为请求的位置会丢失。 图上的某些查询被迫遍历几个物理节点,即出现网络延迟。
假设我们做了一些不同的事情-他们采用了良好的分片功能将所有东西收起并弄碎了。 我们计算出某个哈希值,相当随机地随机分布集群中的所有数据,这又带来了另一个问题。

如果在以前的方案中至少有一些查询可以正常工作,那么
这里的查询100%是愚蠢的 ,因为大多数数据库查询都与图
遍历有关 。 从节点绕行的任何地方都必须走到某个地方,通常,为了计算请求,您需要去另一个节点。

如上图所示,这个想法大概是分片的:找到集群并将其放置在节点上:紧密连接的子集放置在一起,弱连接的子集隔开。
这是一些理想的选择,但是
理想的选择仅在理论上存在 。 实时数据不适合进行静态分区。 要实现这种方法,我们必须自动检测动态变化集上的集群,并根据出现和消失的键不断移动节点。
因此,Neo4j基本上可以像传统的SQL数据库一样进行扩展。 他们已经进行了很长时间的分片工作,试图解决所描述的问题。
我提出的论点是,
水平缩放对每个人都施加了
压力 ,所有数据模型迟早都会被强制实施。 但是有些模型会保留在我们身上,而有些则不会。
因此,例如,如果我们以纯格式考虑键值数据库和文档数据库,那么我的陈述是它们不会。 如果您查看图数据库,它们已经占据了很大一部分,但是处于水平缩放的压力之下。
图形数据库会消失吗?
像文档一样 ,
列很可能
会包含在所有产品中 。 这种趋势称为多模型数据库,稍后在报告中,我将举一个示例说明如何在实践中使用它。 但是现在,作为多模型数据库趋势的另一个例证,让我们看一下JSON。
杰森
下面是一个示例,说明如何将趋势变为无所不包。
我认为,任何甚至能够以任何方式支持JSON的数据库都将支持JSON。
也许某些用于矩阵计算的数据库将不支持JSON。 但最有可能的是它将派上用场。 其余的肯定会。
| 的MySQL
| PostgreSQL的
| 雷迪斯
| Couchbase
| 卡桑德拉
| Neo4j
|
JSON存储
| 是的
| 是的
| 是的
| 是的
| 是的
| 是的
|
JSON字段操作
| 是的
| 是的
| 是的
| 是的
| 没有啦
| 没有啦
|
Json查询
| 是的
| 是的
| 没有啦
| 是的
| 是的
| 没有啦
|
JSON二级索引
| 是的
| 是的
| 没有啦
| 是的
| 没有啦
| 没有啦
|
该表使您可以直观地查看数据模型的情况。 关系数据库在支持JSON方面甚至领先于同一Cassandra的非关系数据库。 它没有JSON字段的辅助键。 甚至图形数据库也开始包含JSON,因为
每个人都需要JSON 。
因此,NoSQL将长期认真地对待多模型数据库,尤其是在几乎所有产品中都可以找到的JSON作为数据类型。
但是,如果所有数据库都支持JSON,那么为什么根本需要NoSQL数据库?只剩下一个故事-水平缩放。 我们想水平扩展,这就是为什么我们使用MySQL或PostgreSQL以外的东西的原因。

这是Oracle MySQL工程副总裁Thomas Ulin的主题演讲,他谈到了MySQL的未来。 在Postgres社区和其他关系产品中也会发生同样的事情。 由于向超融合和云计算过渡,水平扩展的压力影响了100%的产品。
Thomas说他们的愿景是开箱即用的具有高可用性和可伸缩性的产品。 我们主要在谈论高可用性InnoDB集群,这是组复制+ InnoDB。 这样的数据库即使被重击也不会消失。
然后,托马斯(Thomas)编写了“
嵌入了缩放功能 ”-“我们烘焙了所有这些功能”。 关键是,通过x版本(我认为x = 2、3),他们将收到纯格式的MySQL群集,它将支持群集上的SQL和群集中的JSON存储。
今天,
MySQL已经具有与MongoDB非常相似的X协议,该协议旨在与JSON一起使用。
NoSQL中的SQL
现在让我们从另一侧看一下运动。 为了说明死亡,您不仅需要研究SQL如何采用NoSQL的原理,反之亦然。
| Mongodb
| Couchbase
| 卡桑德拉
| 雷迪斯
|
数据模式
| 是的*
| 没有啦
| 是的
| 没有啦
|
空值/缺少值
| 是的*
| 是的
| 是的
| 没有啦
|
加入
| 是的
| 是的
| 没有啦
| 没有啦
|
辅助键
| 是的*
| 是的
| 是的,但是...
| 没有啦
|
分组依据
| 是的*
| 是的
| 没有啦
| 没有啦
|
JDBC / ODBC
| 没有啦
| 是的
| 没有啦
| 没有啦
|
实际上,这里也有有趣的见解。 我认为我是领导人。 我同意并不是所有内容都在这里,例如,Elastic也是NoSQL的领导者。 但是Elastic仍然主要是全文搜索的解决方案,因此我没有在表中包括它。
Times Series Databases作为一种趋势我不会触及。 在一系列时间序列运动中,有一个论点是这是一个独立的利基市场,类似于图数据库,但是如果您深入研究,Postgres将会处于幕后。
Couchbase
我认为,Couchbase具有SQL世界中最广泛的可能性。 每个人都知道
Couchbase是Memcached的 。 Memcached的开发商之一Dormando(
Alan Kasindorf )拥有完全不同的产品愿景,该愿景不涉及水平扩展。 因此,Memcache分叉以便水平扩展。 它进展顺利,开始围绕它开展业务,然后与CouchDB合并,依此类推。
Couchbase最初对自己说这是一个
无模式数据库 。 Memcache最初是一个非常简单的键值。 现在,让我们看看这种自我识别如何随时间变化。
例如,Couchbase具有次要密钥,而
次要密钥实际上是方案的开始 。 如果您说您具有用于构建索引的某些字段,那么您已经在谈论要存储的数据文档的方案。
此外,随着Couchbase逐渐从今天的文档中删除有关Memcache的整个故事,他们也将在明天删除有关最终一致性的故事,尽管今天仍然有很多关于缺乏读取一致性的故事-二级密钥最终是一致的。
但是要注意的是,Couchbase具有JDBC / ODBC。
从理论上讲,由于CQL语法与SQL不兼容,因此从理论上讲,可以使用这些驱动程序连接Tableau或ClickView。但是这些驱动程序本身就是SQL标准的一部分。展望未来,让我们看一下语法。 他们搞砸了语法,因为出于某种原因,他们决定由于拥有文档而没有模式,因此他们需要一些特殊的运算符-并发明了SQL中已经存在的完全类似物。例如,它们的IS MISSING(标准缺失)-如果标准的标准为IS NULL,为什么这是必需的?
他们搞砸了语法,因为出于某种原因,他们决定由于拥有文档而没有模式,因此他们需要一些特殊的运算符-并发明了SQL中已经存在的完全类似物。例如,它们的IS MISSING(标准缺失)-如果标准的标准为IS NULL,为什么这是必需的?JDBC, ODBC SQL ? 30-40 , SQL- SQL , , : look-in, , ..
, .
, , ., Couchbase JDBC/ODBC — . , — .
Secondary keys
, NoSQL — , — , . OrientDB, , , .
SQL- , ( , ), NoSQL, .
NoSQL- secondary keys. secondary keys?
( — ):
- , , . , range-, SQL . range- map/reduce .
- . index notes, . range- .., .
, , , , , . , .
. , NoSQL- SQL, , , .
: CockroachDB? :
, . , MySQL — legacy. , , ..
, NoSQL- legacy 10 . , , . SQL- , PostgreSQL, , MySQL Couchbase , True NewSQL.
, secondary keys. MongoDB SQL, . , JOINs, , .
Redis No, . Redis , — . , , , .
, Redis — , - . , Redis-, SQL. , Redis SQLite, — storage — Redis', in memory.
NoSQL , , ?
, NoSQL . , , , SQL . SQL .
schemaless , , , waterfall : agile, - . , , CREATE TABLE, .
, online alter table. Oracle , .
SQL , .
MongoDB — , .
MongoDB , schemaless. . , , strict. validation level validation action. Validation level , .
, , - . , , . validation action reject, warn: warning, validation action.
. , MongoDB ( Tarantool), .
Cassandra JSON, . — , . , , NoSQL, .
-, NoSQL SQL .

eventually consistent , , ,
. , — . .
?
, , . BigQuery , , Vertica, .
NoSQL . , SELECT LTP, LTP - Key-value.
, NoSQL- .
SELECT JOIN , , ,
— ..
NoSQL:
,
, , .
domain-specific languages .
NoSQL DSL. —
RethinkDB ReQL . , — domen specific language. Python, JavaScript .. — . SQL , .
ReQL, . ReQL , , — . RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
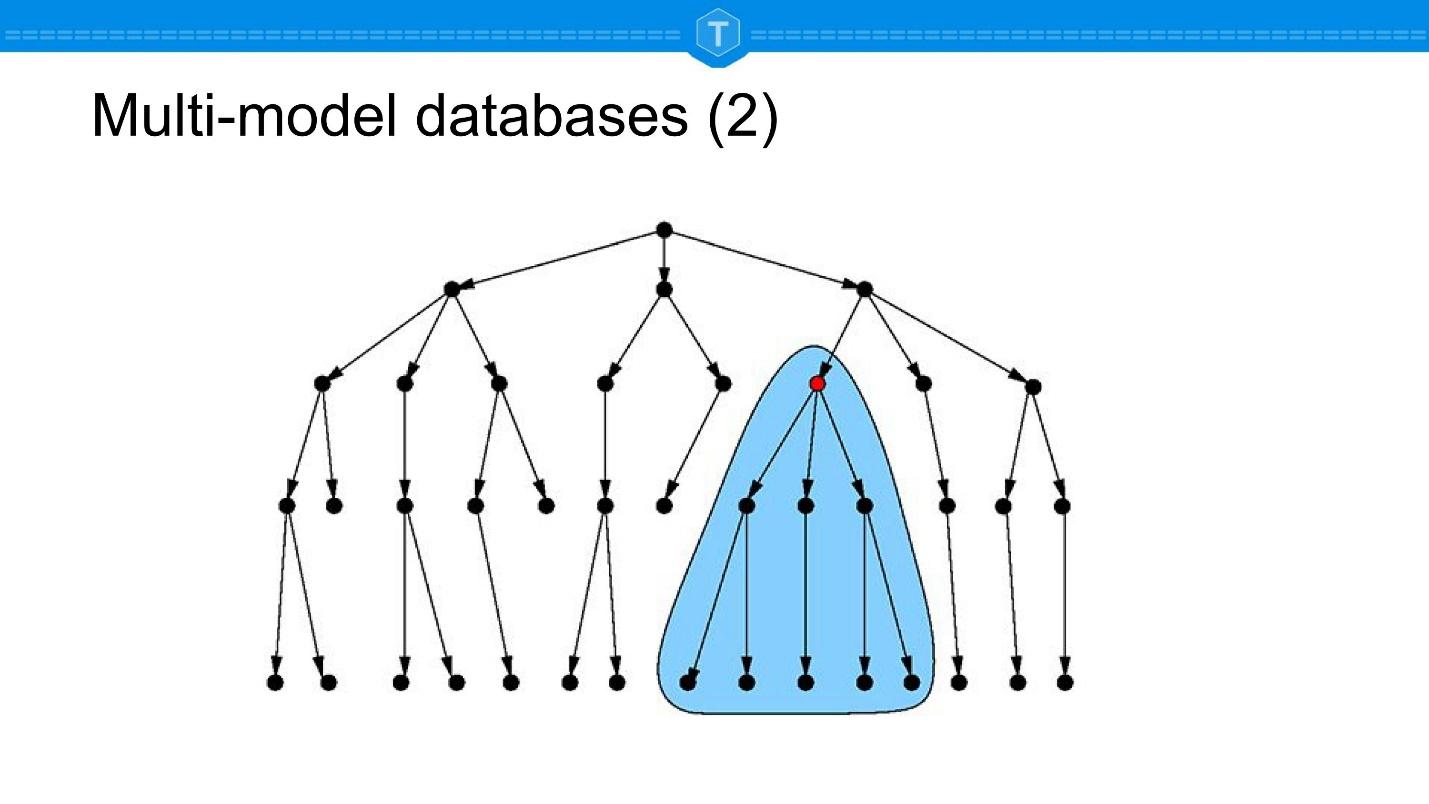 同时,通常有图形查询,如上图所示。假设零件发生故障,但仅在装配中发生变化,因此您需要找到需要购买和更换的模块。这是一个典型的图形查询。需要为开发人员提供不同的方式来处理相同的数据。在同一个数据库中,图形和集合以及关系都应同时存在。相对而言,可以在关系中包含对集合中存在的对象的引用,可以将关系中的数据用于图形等。
同时,通常有图形查询,如上图所示。假设零件发生故障,但仅在装配中发生变化,因此您需要找到需要购买和更换的模块。这是一个典型的图形查询。需要为开发人员提供不同的方式来处理相同的数据。在同一个数据库中,图形和集合以及关系都应同时存在。相对而言,可以在关系中包含对集合中存在的对象的引用,可以将关系中的数据用于图形等。UPSERT:为什么
这不完全与NoSQL有关,但是对我来说,这是一个非常重要的趋势-这是
写优化存储 -我认为它将长期认真地存在于我们中。
SQL和NoSQL都没有仅是自然编写的语句。 在许多情况下,甚至MonsDB中的absert也读取数据。 插入也是一种读操作,因为如果在文档中已经定义了一个ID,那么您需要检查是否没有这样的ID。
您说-如果有索引,那么我们必须阅读。 但是,
即使有索引,也不一定总是需要读取 。 想法是这样的-在任何情况下您都不想阅读,您不需要这样做,您也不在乎阅读的结果。 您想要将数据添加到数据库中(如果该数据库尚不存在)。 如果它们存在,则假设您用新版本替换了它们的旧版本或运行了某种合并命令。 也就是说,您必须发明
新的语义才能不读。
在我看来,现在没有一个数据库可以提供这种功能,但是写优化算法的吸引力是如此之大,以至于我真的很希望这种可能性。 因为有了写优化的存储,所以LSM树(RocksDB,LevelDB等)在
不读取的情况下的写入性能要比在读取时的写入性能高2个数量级 。 一个节点上可能有一百万个请求,而不是每秒一万个请求。
这就是为什么时间序列数据库之所以会获胜的原因,是因为它们缺乏语义上的差距。 它们中到达的数据流明确定义为时间序列,尤其是非常快速且紧凑地写入数据库中。 因为您不需要验证唯一性。 这快一个数量级,仅是因为在传统数据库中没有仅写的语义操作。
我认为它将出现。

接下来所有这些都去了哪里? 如果您看上去很遥远,那么创新不仅会停留在NoSQL和NewSQL上。 我们对信息的了解在不断发展。
我认为,未来最重要的趋势之一就是我们将越来越少地删除信息。
为此,诞生了一系列产品,这些产品称为时间数据库。
NewSQL之后:临时数据库
以下是Microsoft SQL Server的屏幕截图。 这是一个数据库,允许您在某个时间点提问:当前状态为SELECT,但仍可以对过去的某个日期进行SELECT。

这产生了许多新的数据库应用程序。 首先,您可以跟踪对象的历史记录。 其次,您可以按期间自动计算组和报告。 您无需为此创建单独的表-您在一个表中具有自然的表示形式:一个实体-一个表。
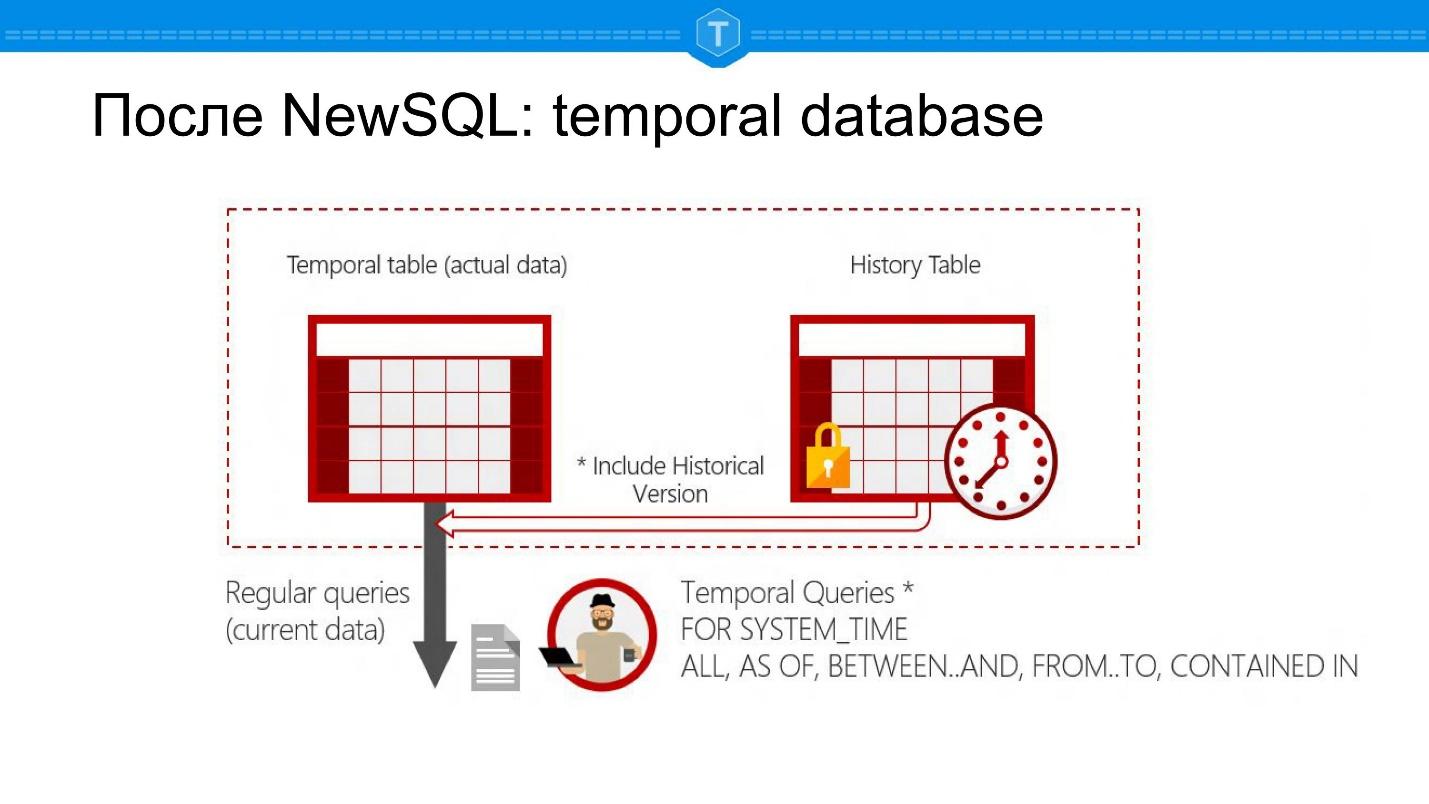
从内部结构的角度来看,这实际上是主表和具有历史记录的表。 每行都与系统已知的两次关联。 这些不仅仅是您添加的两列,而是系统自动支持的数据:
- 记录添加到数据库的时间,
- 活动时间。
无论多么有趣,现在都是不同的时代。
假设Ivan Ivanovich于11月17日去世,并且该记录于11月20日输入数据库-这两个时间均存储在此类数据库中。
我认为,这也是基本趋势之一。 我为什么这么认为? 如果我们返回到辅助键和最终一致性,那么绝对存储所有内容只会使您优雅地解决此问题。
如果我们根本不需要从数据库中删除任何内容,那么我们的数据库将始终保持一致-如此有趣的故事!
有用的链接
常见问题-在创建不适用于MySQL,PostgreSQL,MongoDB等的新数据库方面有什么进展吗?
一个好方法是,问题是:会有新的数据库,初创公司吗? 我认为它们会越来越少出现。 风暴已经消退,现在我们将比到达更早看到离开,CockroachDB是最后一个到达的地方。
让我们说清楚。 我在大学的教授说DBMS是永恒的绿色区域。 因此,我们将始终看到某种运动。 但是我认为,在不久的将来,根本不会出现不同的产品,而是会出现融合,而不是繁荣。
-不是问题,而是一个补充:SQL经常尝试覆盖索引,以使SQL查询的结果与存储级别无关,而是立即从索引中获取。 索引本身实际上是图的一种特殊情况。 那么,趋势可能是整个数据库逐渐流入陡峭的图形索引?
这是一个很棒的故事,图数据库的所有代表都喜欢告诉他们的客户-这是行不通的! 因为有许多更新索引的方法,并且有许多索引选项,但并不是每个人都有一张图! 让我们冷静一下-正如并非所有事物都是相关的,所以并非每个人都是图。
-在您看来,Elastic之类的东西会去哪里? 我说的是他开始解决非常奇怪的问题的事实-他正试图假装时间序列和处理日志的分析基础。 似乎没有人使用它进行文本搜索。
Elastic不需要移动到任何地方,因为Elastic感觉很棒。 它解决了一个特定的业务问题-这是一个有效的搜索以及与此生态系统相关的所有内容。
我认为一切主要来自于Elastic试图成为一切的事实。 但是这里的问题来自任务,Elastic任务与时间序列任务非常相似,因此是合理的。 Elastic适用于搜索大量相同日志等的数组。
情况比较狭窄-只是全文搜索,但您不会做很多事情。 首先,需要做更多工作才能与竞争对手区分开。 因此,这一切都在发生。
但我认为Elastic明天不会进行银行交易。 例如,一切都将达到Couchbase的地步-如果不是银行交易,那么事情会如此之快。
最新消息
很快, 6月21日, Tarantool会议 将在莫斯科举行,或者简称为T + Conf-一次会议,不仅涉及Tarantool本身,而且还涉及内存中计算的使用。
- 康斯坦丁·奥西波夫(Konstantin Osipov)计划提交一份报告,在报告中,他将尽可能一致且详细地研究Vinyl架构,其功能以及最重要的是针对该引擎的调整和性能监视机制。
- Vladimir Perepelitsa以教程格式表示,希望证明 Tarantool是一个数据库,它有很大的潜力可以用作应用程序服务器。
- 弗拉迪斯拉夫·扎伊采夫(Vladislav Zaitsev)将从他的角度(从物联网的角度)着手解决这个话题,尤其要讲解为什么要使用物联网控制系统。