我们每个人都做家务。 每个人都编写样板代码。 怎么了 自动化此过程并仅执行有趣的任务不是更好吗? 如果您希望计算机为您完成此类工作,请阅读本文。
 本文基于Uber移动应用程序开发人员Zack Sweers在2017年MBLT DEV会议上发表的报告的笔录 。
本文基于Uber移动应用程序开发人员Zack Sweers在2017年MBLT DEV会议上发表的报告的笔录 。
Uber拥有大约300个移动应用程序开发人员。 我在一个称为“移动平台”的团队中工作。 我团队的工作是尽可能简化和改善开发移动应用程序的过程。 我们主要研究内部框架,库,体系结构等。 由于人员众多,我们必须执行工程师将来需要的大型项目。 可能是明天,或者下个月甚至是一年。
自动化代码生成
我想证明代码生成过程的价值,并考虑一些实际示例。 该过程本身看起来像这样:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
这是使用Kotlin Poet的示例。 Kotlin Poet是一个具有良好API的库,可以生成Kotlin代码。 那么我们在这里看到什么?
- FileSpec.builder创建一个名为“ Presentation ”的文件。
- .addComment() -在生成的代码中添加注释。
- .addAnnotation() -添加类型为Author的注释。
- .addMember() -在参数中添加一个变量“ name ”,在我们的例子中是“ Zac Sweers ”。 %S-参数类型。
- .useSiteTarget() -安装SiteTarget。
- .build() -完成将要生成的代码的描述。
代码生成后,将获得以下内容:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
代码生成的结果是一个包含名称,注释,注释和作者姓名的文件。 问题立即浮出水面:“如果可以通过几个简单的步骤完成代码,为什么我需要生成此代码?” 是的,您是对的,但是如果我需要一千个具有不同配置选项的文件怎么办? 如果我们开始更改此代码中的值会怎样? 如果我们有很多演讲,该怎么办? 如果我们有很多会议怎么办?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
结果,我们得出的结论是,根本不可能手动维护这么多文件,而必须实现自动化。 因此,代码生成的第一个优点是摆脱了常规工作。
无错误代码生成
自动化的第二个重要优点是无错误操作。 所有人都会犯错。 当我们做同样的事情时,这种情况尤其经常发生。 相反,计算机可以完美地完成这项工作。
考虑一个简单的例子。 有一个Person类:
class Person(val firstName: String, val lastName: String)
假设我们要在JSON中为其添加序列化。 我们将使用
Moshi库来执行此操作,因为它非常简单并且非常适合演示。 创建一个PersonJsonAdapter并从Person类型的参数继承自JsonAdapter:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
接下来,我们实现fromJson方法。 它为读者提供了阅读信息的方法,这些信息最终将返回给Person。 然后,我们用名字和姓氏填写字段,并获得新值Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
接下来,我们查看JSON格式的数据,对其进行检查并将其输入必要的字段中:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
这样行吗? 是的,但是有一个细微差别:我们读取的对象必须包含在JSON中。 为了过滤掉可能来自服务器的多余数据,请添加另一行代码:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
至此,我们成功绕过了常规代码领域。 在此示例中,只有两个值字段。 但是,此代码有很多不同的部分,您可能会在其中突然崩溃。 突然我们在代码中出错了?
考虑另一个示例:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
如果每10个型号左右至少有一个问题,那么这意味着您肯定会在这方面遇到困难。 在这种情况下,代码生成确实可以为您提供帮助。 如果课程很多,那么没有自动化就无法工作,因为所有人都允许输入错误。 借助代码生成,所有任务将自动执行且没有错误。
代码生成还有其他好处。 例如,它给出有关代码的信息或告诉您是否出了问题。 在测试阶段,代码生成将非常有用。 如果使用生成的代码,则可以看到工作代码的真实外观。 您甚至可以在测试期间运行代码生成,以简化工作。
结论:值得考虑的是代码生成可以解决错误。
现在,让我们看一下有助于代码生成的软件工具。
工具
- 分别用于Java和Kotlin的JavaPoet和KotlinPoet库 。 这些是代码生成的标准。
- 模式化。 一个流行的Java模板示例是Apache Velocity和iOS的Handlebars 。
- SPI-服务处理器接口。 它内置于Java中,允许您创建和应用接口,然后在JAR中声明它。 执行程序后,您可以获取接口的所有现成实现。
- 编译测试是Google提供的一个库,可帮助进行编译测试。 在代码生成方面,这意味着:“这是我所期望的,但是这是我最终得到的。” 编译将在内存中开始,然后系统将告诉您此过程是否已完成或发生了什么错误。 如果编译已完成,将要求您将结果与您的期望进行比较。 比较是基于编译后的代码,因此不必担心诸如代码格式之类的事情。
代码构建工具
有两个主要的代码构建工具:
- 注释处理 -您可以在代码中编写注释,并向程序询问有关它们的其他信息。 编译器甚至会在完成源代码处理之前就给出信息。
- Gradle是一个应用程序组装系统,在其代码组装生命周期中具有许多钩子(钩子-函数调用的拦截)。 它被广泛用于Android开发中。 它还允许您将代码生成应用于源代码,而与当前源代码无关。
现在考虑一些示例。
牛油刀
黄油刀是杰克·沃顿(Jake Wharton)开发的图书馆。 他是开发人员社区中的知名人物。 该库在Android开发人员中非常受欢迎,因为它有助于避免几乎每个人都面临的大量例行工作。
通常我们以这种方式初始化视图:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
使用Butterknife,它将看起来像这样:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
我们可以轻松地添加任意数量的视图,而onCreate方法不会增加样板代码:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
您不必每次都手动进行绑定,只需将@BindView批注以及为其分配的标识符(ID)添加到这些字段即可。
Butter Knife的有趣之处在于它将分析代码并生成与您相似的所有部分。 它还具有出色的新数据可伸缩性。 因此,如果出现新数据,则无需再次应用onCreate或手动跟踪某些内容。 该库也非常适合删除数据。
那么,从内部看,这个系统是什么样的呢? 通过代码识别搜索视图,然后在注释处理阶段执行此过程。
我们有这个领域:
@BindView(R.id.title) TextView title;
从这些数据来看,它们用于特定的FooActivity中:
她有自己的意思(R.id.title),它是目标。 请注意,在数据处理过程中,该对象在系统内部变为常数:
这很正常。 无论如何,这就是黄油刀应该使用的东西。 有一个TextView组件作为一种类型。 该字段本身称为标题。 例如,如果我们从此数据中创建一个容器类,则会得到如下所示的内容:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
因此,可以在处理过程中轻松获得所有这些数据。 它也与黄油刀在系统内部的操作非常相似。
结果,该类在这里生成:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
在这里,我们看到所有这些数据都收集在一起。 结果,我们有了Underscore Java库中的ViewBinding目标类。 在内部,该系统的排列方式是每次创建类的实例时,它将立即对您生成的信息(代码)进行所有绑定。 所有这些都是在注释处理期间以前静态生成的,这意味着它在技术上是正确的。
让我们回到我们的软件管道:
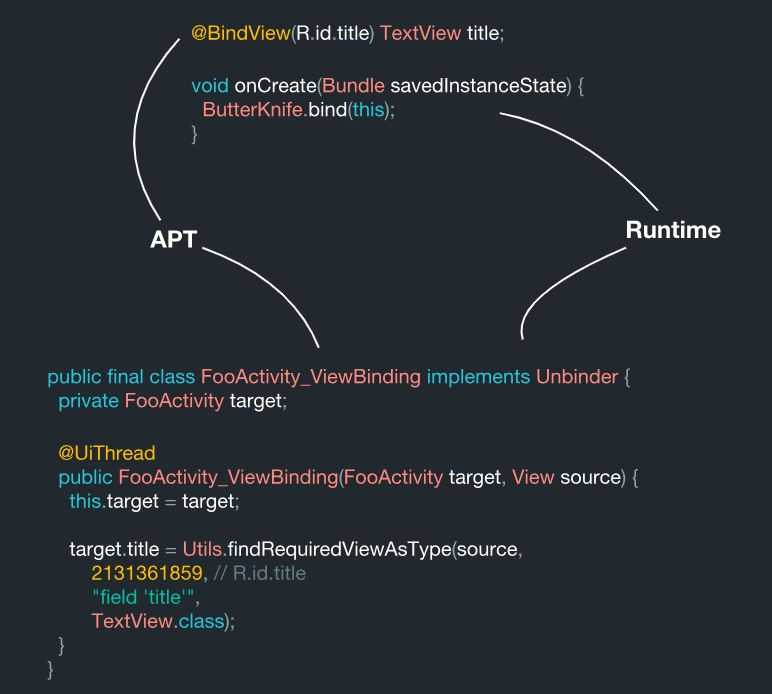
在注释处理期间,系统读取这些注释并生成ViewBinding类。 然后在bind方法期间,我们以一种简单的方式对相同的类执行相同的搜索:我们取其名称并在末尾附加ViewBinding。 就其本身而言,使用JavaPoet在指定区域中覆盖在处理过程中具有ViewBinding的部分。
绑定
RxBindings本身不负责代码生成。 它不处理注释,也不是Gradle插件。 这是一个普通的库。 它为Android API提供了基于反应式编程原理的静态工厂。 这意味着,例如,如果您有setOnClickListener,则将出现一个click方法,该方法将返回(可观察的)事件流。 它充当桥梁(设计模式)。
但是实际上RxBinding中存在代码生成:
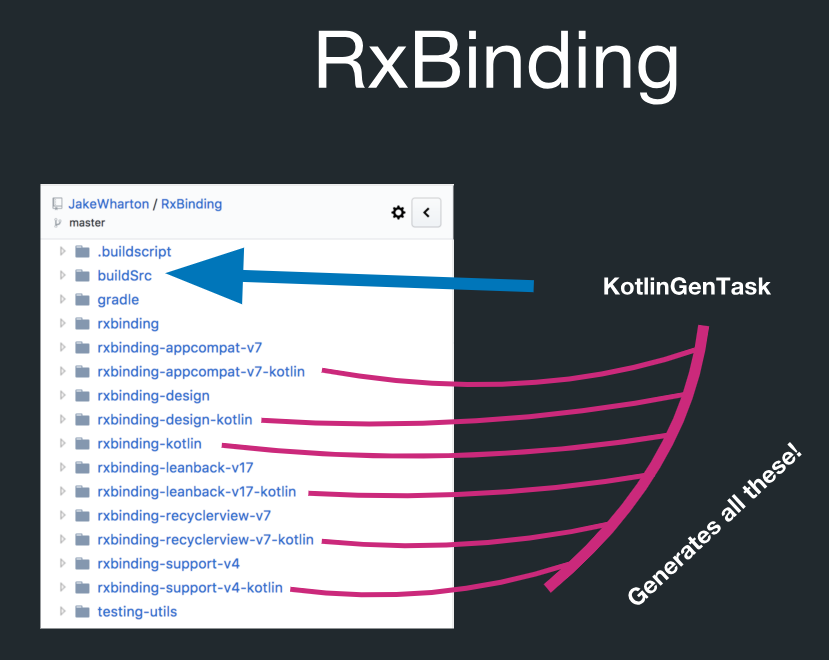
在名为buildSrc的目录中,有一个名为KotlinGenTask的Gradle任务。 这意味着所有这些实际上都是通过代码生成来创建的。 RxBinding具有Java实现。 她还拥有Kotlin工件,其中包含所有目标类型的扩展功能。 所有这些都严格遵守规则。 例如,您可以生成所有Kotlin扩展功能,而不必单独控制它们。
它到底是什么样的?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
这是一个完全经典的RxBinding方法。 此处返回可观察对象。 该方法称为点击。 使用点击事件是在“幕后”进行的。 我们忽略了多余的代码片段,以保持示例的可读性。 在Kotlin中,它看起来像这样:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
此扩展函数返回Observable对象。 在程序的内部结构中,它直接为我们调用了通常的Java接口。 在Kotlin中,您必须将其更改为Unit type:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
也就是说,在Java中,它看起来像这样:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Kotlin代码也是如此:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
我们有一个包含此方法的RxView类。 我们可以将目标属性,名称属性中的相应数据替换为方法的名称,所扩展的类型以及返回值的类型。 所有这些信息将足以开始编写以下方法:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
现在,我们可以将这些片段直接替换为程序内部生成的Kotlin代码。 结果如下:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
服务代
我们正在Uber开发ServiceGen。 如果您在公司工作并且处理后端和客户端的通用特征和通用软件接口,则无论您是开发Android,iOS还是Web应用程序,手动创建模型和服务都没有意义。团队合作。
我们将Google的
AutoValue库用于对象模型。 它处理注释,分析数据并生成两行哈希码,equals()方法和其他实现。 她还负责支持扩展。
我们有一个Rider类型的对象:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
我们具有ID,名字,姓氏和地址的行。 为了使用网络,我们使用Retrofit和OkHttp库,以及JSON作为数据格式。 我们还将RxJava用于响应式编程。 这就是我们生成的API服务的样子:
interface UberService { @GET("/rider") Rider getRider() }
如果愿意,我们可以手动编写所有这些内容。 长期以来,我们做到了。 但是需要很多时间。 最后,它花费了很多时间和金钱。
优步今天的工作方式
我团队的最后一个任务是从头开始创建文本编辑器。 我们决定不再手动编写随后进入网络的代码,因此我们使用
Thrift 。 它既像编程语言,又像协议。 Uber使用Thrift作为技术规范的语言。
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
在Thrift中,我们在后端和客户端之间定义API合同,然后简单地生成适当的代码。 我们使用
Thrifty库解析数据,并使用JavaPoet生成代码。 最后,我们使用AutoValue生成实现:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
我们用JSON完成所有工作。 有一个名为
AutoValue Moshi的扩展,可以使用静态jsonAdapter方法将其添加到AutoValue类中:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
节俭还有助于服务的发展:
service UberService { Rider getRider() }
我们还必须在此处添加一些元数据,以使我们知道想要达到的最终结果:
service UberService { Rider getRider() (path="/rider") }
代码生成后,我们将获得我们的服务:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
但这只是可能的结果之一。 一种模式。 我们从经验中知道,没有人曾经只使用过一种模型。 我们有许多模型可以为我们的服务生成代码:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
目前,我们大约有5-6个应用程序。 他们有很多服务。 每个人都经过相同的软件管道。 用手写下所有这些都是疯狂的。
在JSON序列化中,不需要在Moshi中注册“适配器”,并且如果您使用JSON,则无需在JSON中注册。 建议员工通过DI图重写代码来进行反序列化也是可疑的。
但是我们使用Java,所以我们可以使用通过
Fractory库生成的Factory模式。 之所以可以生成它,是因为在编译发生之前我们已经知道了这些类型。 Fractory生成这样的适配器:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
生成的代码看起来不太好。 如果伤到眼睛,可以手动重写。
在这里,您可以看到前面提到的带有服务名称的类型。 系统将自动确定要选择并调用的适配器。 但是这里我们面临另一个问题。 我们有6000个这些适配器。 即使您在同一模板中将它们分开,“ Eats”或“ Driver”模型也将属于“ Rider”模型或将在其应用程序中使用。 代码将伸展。 经过一定时间后,它甚至无法放入.dex文件中。 因此,您需要以某种方式分离适配器:

最终,我们将预先分析代码并为其创建一个工作子项目,如Gradle中所示:

在内部结构中,这些依赖性成为Gradle依赖性。 现在,使用Rider应用程序的元素依赖于它。 有了它,他们将形成所需的模型。 结果,我们的任务将得到解决,所有这些将由程序中的代码汇编系统进行调节。
但是这里我们面临另一个问题:现在我们有n个工厂模型。 它们都被编译成各种对象:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
在处理批注的过程中,将无法仅读取外部依赖项的批注,而仅对其进行附加代码生成。
解决方案:Fractory库中有一些支持,这以一种棘手的方式为我们提供了帮助。 它包含在数据绑定过程中。 我们使用Java归档文件中的classpath参数引入元数据以进一步存储它们:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
现在,每次您需要在应用程序中使用它们时,我们都会使用这些文件进入类路径目录的过滤器,然后以JSON格式从那里提取它们,以找出哪些依赖项可用。
它们如何融合在一起
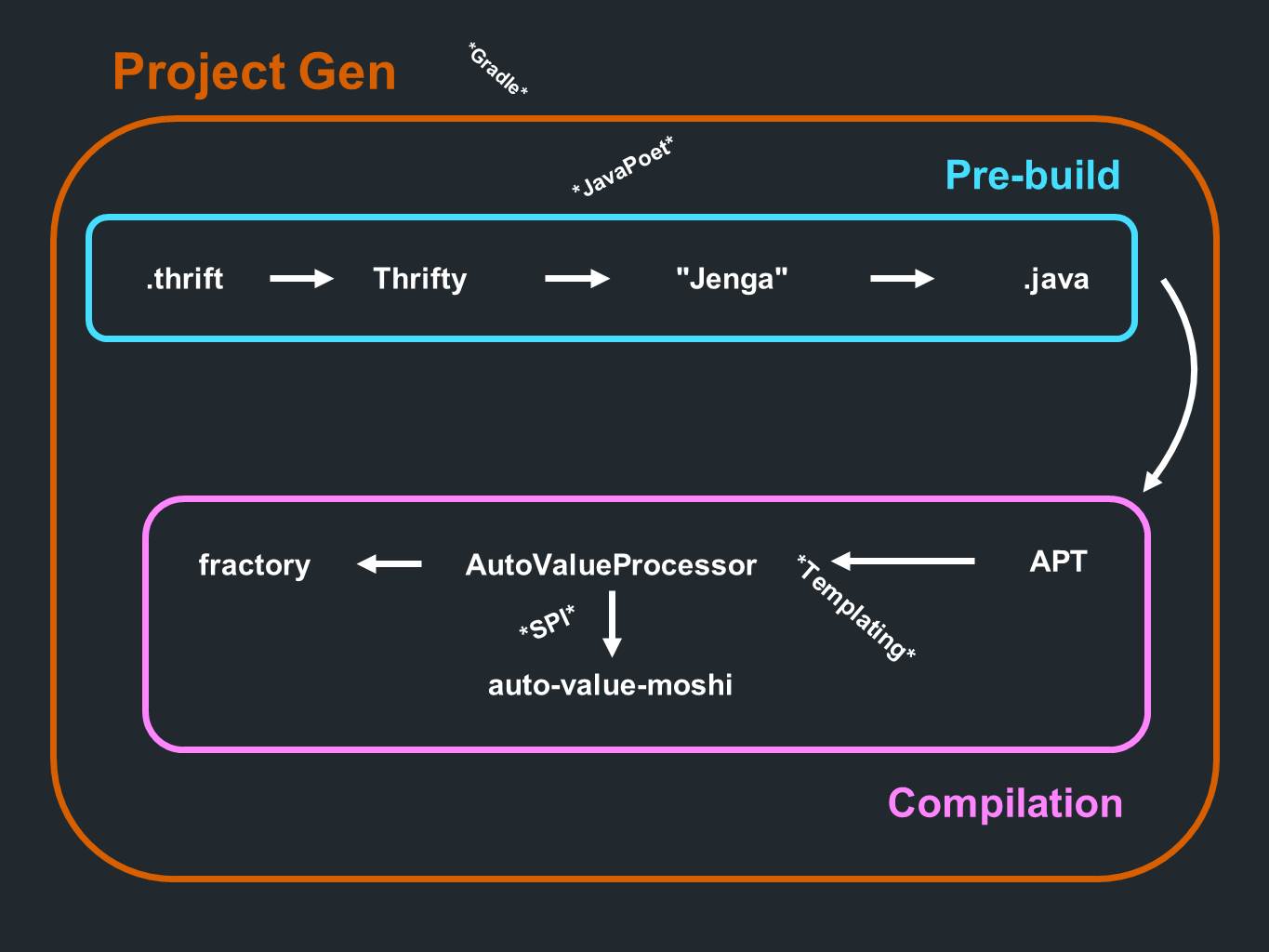
我们有
节俭 。 来自那里的数据进入
Thrifty并进行解析。 然后,他们通过一个称为
Jenga的代码生成程序。 它产生Java格式的文件。 所有这些都发生在处理的初级阶段或编译之前。 并在编译过程中处理注释。 现在该轮到
AutoValue生成一个实现了。 它还调用
AutoValue Moshi以提供JSON支持。
分形也
参与其中 。 一切都在编译过程中发生。 该过程之前是用于创建项目本身的组件,该组件主要生成
Gradle子项目。
现在您已经看到了全貌,您开始注意到前面提到的工具。因此,例如,有Gradle,用于创建代码的模板,AutoValue,JavaPoet。所有工具不仅可以单独使用,而且可以相互结合使用。代码生成的缺点
有必要告诉陷阱。最明显的减号是使代码膨胀并使它失去控制。例如,Dagger占用了应用程序中所有代码的大约10%。模型占据了很大的份额-约25%。在Uber,我们尝试通过丢弃不必要的代码来解决问题。我们必须对代码进行一些统计分析,并了解工作中真正涉及哪些领域。找到答案后,我们可以进行一些转换,看看会发生什么。我们希望将生成的模型数量减少约40%。这将有助于加快应用程序的安装和运行,并为我们节省资金。代码生成如何影响项目开发时间表
当然,代码生成可以加快开发速度,但是时间取决于团队使用的工具。例如,如果您在Gradle中工作,则很可能您正在以一定的步调进行操作。事实是Gradle每天生成一次模型,而不是在开发人员想要的时候生成模型。了解有关Uber和其他顶级公司发展的更多信息。
9月28日,第五届移动开发商MBLT DEV国际会议在莫斯科举行。800位参与者,顶尖演讲者,测验和拼图,供那些对Android和iOS开发感兴趣的人使用。会议的组织者是e-Legion和RAEC。您可以在会议网站上成为MBLT DEV 2018的参与者或合作伙伴。
举报视频