
去年夏天,kaggle网站上旨在对亚马逊森林的卫星图像进行分类的比赛结束了。 我们的团队在900多名参与者中排名第七。 尽管竞赛已经结束很长时间了,但是我们解决方案中的几乎所有方法仍然适用,不仅适用于竞赛,而且适用于训练销售的神经网络。 有关猫的详细信息。
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
任务说明
Planet准备了两种格式的一组卫星图像:
- TIF-16位RGB + N,其中N-近红外
- JPG-源自TIF的8位RGB,用于降低进入任务的阈值以及简化可视化。 在上一场Kaggle比赛中,有必要使用多光谱图像。 非可视的(即红外线)以及具有更长波长的通道极大地提高了网络和无监督方法的预测质量。
在地理上,数据取自亚马逊河流域的领土以及巴西,秘鲁,乌拉圭,哥伦比亚,委内瑞拉,圭亚那,玻利维亚和厄瓜多尔等国家的领土,从中选择了有趣的地面区域,并将照片提供给参加者。
从tif创建jpg后,所有场景均被切成256x256的小块。 根据Planet员工从柏林和旧金山办事处以及通过Crowd Flower平台收到的jpg图像,进行了标记。
参与者的任务是为每个256x256瓦片预测互斥的天气标记之一:
多云,部分多云,阴霾,晴朗
以及0或更多的恶劣天气:农业,主要,选择性伐木,栖息地,水,道路,轮耕,开花,常规采矿
共有4个天气和13个非天气,天气互斥,但没有天气,但是如果图片多云,则应该没有其他标签。

该模型的准确性由F2指标估算:
此外,所有标签的权重均相同,并且首先为每张图片计算F2,然后进行平均。 通常,他们的做法略有不同,也就是说,为每个类别计算特定指标,然后取平均值。 逻辑是后一种选择更具解释性,因为它允许您回答模型在每个特定类上的行为问题。 在这种情况下,组织者选择了第一种选择,这显然与他们的业务细节有关。
火车上有40k个样本。 在测试40k。 由于数据集较小,但是图片较大,因此可以说这是“类固醇上的MNIST”
抒情离题从描述中可以看到,该任务是可以理解的,解决方案不是火箭般的感觉:您只需要归档网格即可。 考虑到具体细节,您还可以在上面堆叠一堆模型。 但是,要获得金牌,您不仅需要以某种方式训练一堆模型。 必须拥有许多基本的多样化模型,每个模型本身都表现出出色的结果。 在这些模型之上,您还可以结束堆栈和其他攻击。
| 成员 | 网 | 1粒 | ta | 差异% |
|---|
| 阿诺 | 121 | 0.9278 | 0.9294 | 0.1736 |
| 尼芝卜 | 密网169 | 0.9243 | 0.9277 | 0.3733 |
| 罗慕尔 | vgg16 | 0.9266 | 0.9267 | 0.0186 |
| 特瑙 | 121 | 0.9232 | 0.9241 | 0.0921 |
| 阿尔布 | 121 | 0.9294 | 0.9312 | 0.1933 |
| 科斯蒂亚 | 资源50 | 0.9262 | 0.9271 | 0.0907 |
| n01z3 | resnext50 | 0.9281 | 0.9298 | 0.1896 |
该表显示了单个作物和TTA的所有参与者的F2评分模型。 如您所见,实际使用的差异很小,但对于竞争模式而言却很重要。
团队互动亚历山大·布斯拉耶夫·
阿尔布在参加比赛时,他领导了Geoscan的整个ml指导。 但是从那以后,他拖了一大堆比赛,成为语义分割中所有ODS的父亲,然后前往明斯克,在Mapbox中划船,有关该
文章的内容已
发表阿列克谢·诺斯科夫(Alexey Noskov
Alno)通用ml战斗机。 在邪恶的火星人工作。 现在转到Yandex。
康斯坦丁·洛普欣(Konstantin Lopukhin)
在Scrapinghub工作并继续工作。 从那时起,科斯蒂亚(Kostya)设法获得了几枚奖牌,而且没有5分钟的时间Kaggle Grandmaster
亚瑟·库辛
N01Z3参加比赛时,我在Avito工作。 但是在新的一年左右,
Dbrain的初创公司Lead Data Scientist
转向了区块链。 我希望我们不久将通过与码头工人和路灯标记的比赛使社区感到高兴。
叶夫根尼(Evgeny)Nizhibitsky
@nizhibRambler&Co.的首席数据科学家 通过这次比赛,尤金发现了在图片比赛中发现面孔的秘密能力。 是什么让他在Topcoder平台上拖了几场比赛。 我
谈论了其中之一。
鲁斯兰·
贝库洛夫·罗穆尔在康斯坦察从事体育赛事的跟踪。
弗拉基米尔·伊格洛维
科夫·特瑙斯您可能会记得
一篇有关英国情报局骚扰的动感十足的
文章 。 他曾在TrueAccord工作,但后来加入了时尚青年Lyft。 计算机视觉在无人驾驶汽车上的工作地点。 继续拖累比赛,最近收到了Kaggle Grandmaster。
我们的参与方式和参与方式可以称为典型。 之所以决定团结,是因为我们在排行榜上都取得了接近的结果。 我们每个人都看到了自己的独立管道,从头到尾都是完全自主的解决方案。 此外,合并后,一些参与者也参与了堆叠。
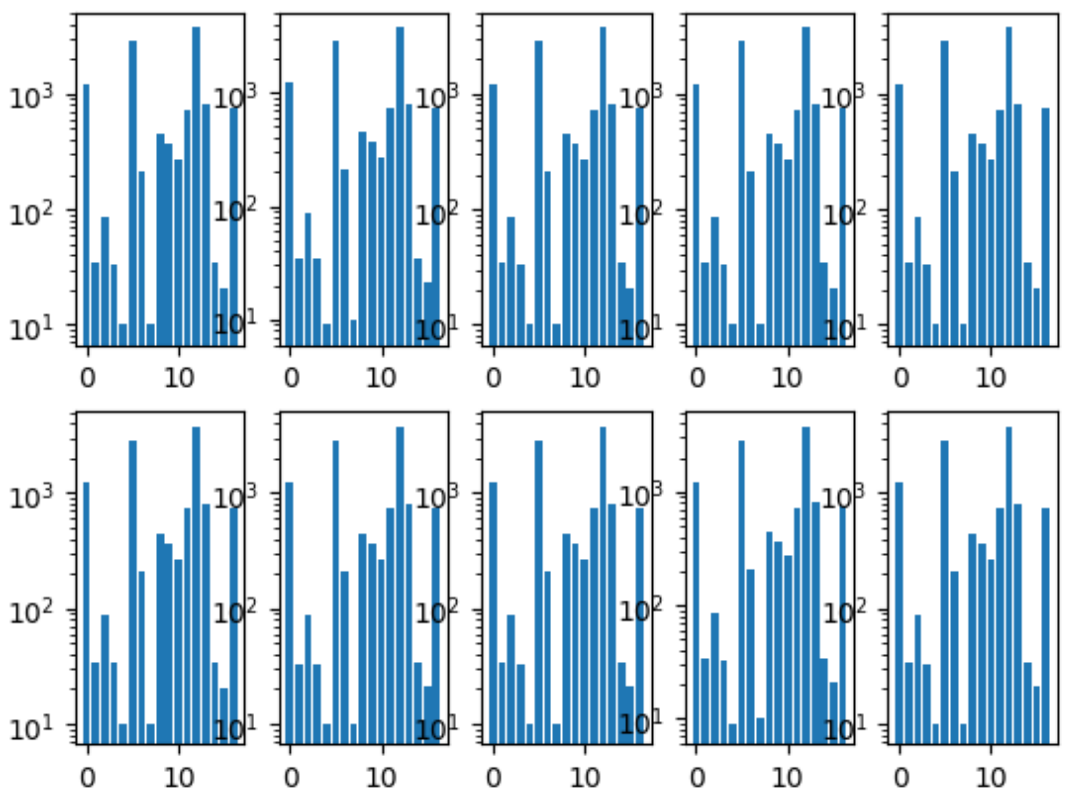
我们要做的第一件事是折页。 我们确保每个折叠中的类分布与整个数据集中的分布相同。 为此,首先选择了最稀有的类别,并对其进行了分层,因为剩余的图片被第二受欢迎的类别所分层,依此类推,直到没有照片为止。
折叠类别的直方图:
我们也有一个公共存储库,每个团队成员都有自己的文件夹,他可以根据需要在其中组织代码。
我们也同意预测的格式,因为这是组合模型的唯一交互点。
神经网络训练由于我们每个人都有独立的管道,因此我们是人为并行的最佳学习过程的网格样本。
一般方法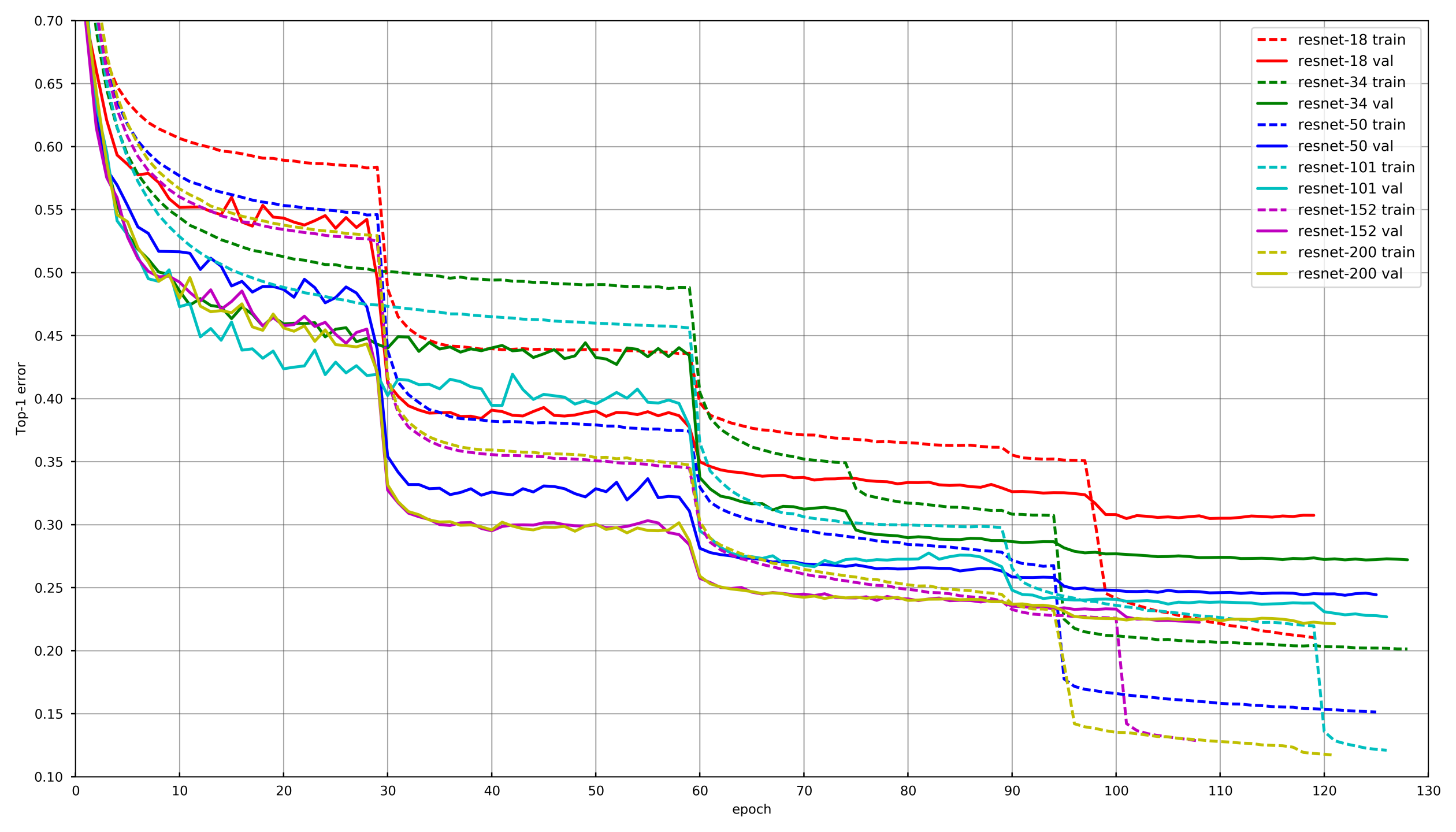
图片来自
github.com/tornadomeet/ResNet在Imagenet上的Resnet神经网络的训练时间表上提出了一个典型的学习过程。 他们从使用SGD(lr 0.1 Nesterov Momentum 0.0001 WD 0.9)随机初始化的权重开始,然后在30次擦除后将学习率降低10倍。
从概念上讲,我们每个人都使用相同的方法,但是,为了避免在训练每个网络时变老,如果验证未连续3-5个时代减少损失,则LR会降低。 或者,一些参与者只是简单地减少了每次LR伤害的时代数,并按照时间表降低了年龄。
增广在训练神经网络时,选择正确的增强非常重要。 扩充应反映数据性质的可变性。 按照惯例,增强可以分为两种类型:在数据中引入偏差的类型和不引入偏差的类型。 通过偏见,可以了解各种低级统计信息,例如颜色直方图或特征尺寸。 假设在这方面,HSV的增加和缩放会引入偏移,但随机作物不会。
在培训网络的第一阶段,您可能无法充分利用增强功能并使用非常困难的设置。 但是,在训练快要结束时,您必须关闭增强或仅保留那些不会引起偏见的增强。 这样一来,神经网络就可以在训练过程中过度拟合,并在验证中显示出更好的结果。
层冻结在绝大多数任务中,从头开始训练神经网络是没有意义的,而像Imagenet一样,摆弄预先训练的网络效率更高。 但是,您可以走得更远,而不仅仅是用所需的类数更改该层下的完全连接的层,而是首先冻结所有的卷积对其进行训练。 如果不冻结卷积并立即使用随机初始化的全连接层权重训练整个网络,则卷积的权重将受到破坏,神经网络的最终性能将降低。 在此任务上,由于训练样本的大小较小,这一点尤其明显。 在其他具有大量数据的比赛中,例如cdiscount,不可能冻结整个神经网络,而只能冻结最后的卷积。 这样,由于不考虑冻结层的梯度,因此可以大大加快训练速度。
循环退火这个过程看起来像这样。 在完成神经网络的基本训练过程后,将获得最佳权重并重复训练过程。 但是它以较低的学习率开始,并且发生时间很短,例如3-5个时代。 这允许神经网络下降到较低的局部最小值并显示出更好的性能。 这种稳定的运动可以在相当多的比赛中提高结果。
在
这里详细了解两次招待会
测试时间增加由于这是一场比赛,我们对推理时间没有正式的限制,因此您可以在测试过程中使用增强。 图像看起来像在训练期间一样发生了变形。 假设它在垂直,水平,旋转角度等情况下都被反射。 每次扩充都会给出一张新的图片,从中我们可以进行预测。 然后将一幅图像的这种失真的预测取平均(通常是通过几何手段)。 这也带来了利润。 在其他比赛中,我还尝试了随机增强。 说,您一次不能应用一个,而只是将随机转弯,对比度和色彩增强的幅度减小一半,固定种子并制作几张这样的随机失真的图片。 这也增加了。
快照整合(多检查点TTA)退火的想法可以进一步发展。 在退火的每个阶段,神经网络都会飞向稍微不同的局部最小值。 这意味着这些是可以平均的本质上略有不同的模型。 因此,在测试预测期间,您可以采用三个最佳检查点并将其预测取平均值。 我还尝试不采用最好的三个检查点,而是采取三个最多样化的检查点-情况更糟。 好吧,对于生产来说,这种技巧是不适用的,我试图平均模型的重量。 这带来了微不足道但稳定的增长。
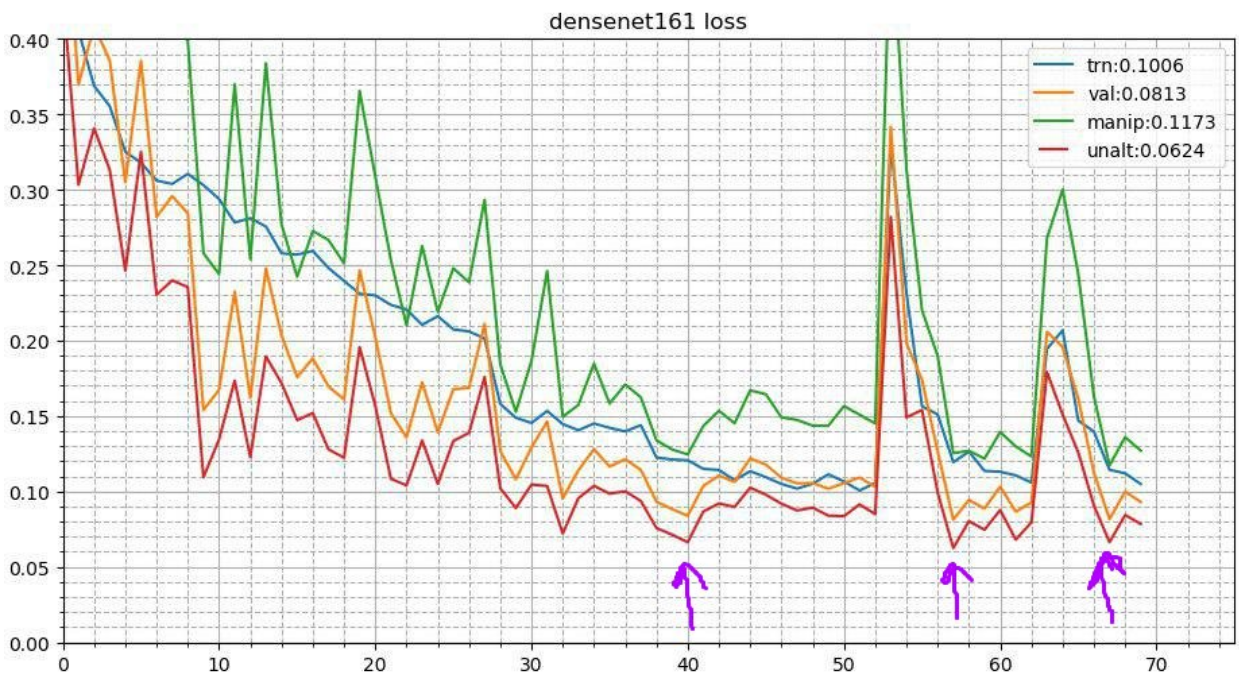 每个团队成员的做法
每个团队成员的做法因此,在某种程度上,我们团队的每个成员都使用了上述技术的不同组合。
| 尼克 | 转换冻结
时代 | 优化器 | 策略策略 | 奥格斯 | ta |
|---|
| 阿尔布 | 3 | 新元 | 15个时代的LR衰减,
圈出13个纪元 | D4
规模
偏移量
失真度
对比
模糊 | D4 |
|---|
| 阿诺 | 3 | 新元 | Lr衰减 | D4
规模
偏移量
失真度
对比
模糊
剪力
通道倍增 | D4 |
|---|
| n01z3 | 2 | 新元 | 投降LR,患者10 | D4
规模
失真度
对比
模糊 | D4、3个检查站 |
|---|
| 特瑙 | -- | 亚当 | 循环LR(1e-3:1e-6) | D4
规模
频道添加
对比 | D4
随机作物 |
|---|
| 尼芝卜 | -- | 亚当 | StepLR,60个历元,每个衰变20个 | D4
随机大小作物 | D4
4个角
中心
规模 |
|---|
| 科斯蒂亚 | 1个 | 亚当 | | D4
规模
失真度
对比
模糊 | D4 |
|---|
| 罗慕尔 | -- | 新元 | base_lr:0.01-0.02
lr = base_lr *(0.33 **(epoch / 30))
纪元:50 | D4,比例 | D4,中心作物,
角豆 |
|---|
堆叠与骇客我们用10折的每组参数训练每个模型。 然后,在非常规(OOF)预测中,我们教授了第二级模型:额外树,线性回归,神经网络和简单的平均模型。
在OOF上,二级模型的预测已经获得了混合权重。 您可以
在此处和
此处阅读有关堆叠的更多信息。
奇怪的是,在实际生产中,这种方法也会发生。 例如,当存在多模式数据(图片,文本,类别等)时,您想要组合模型的预测。 您可以简单地平均概率,但是训练二级模型可以得到最佳结果。
贝斯优化F2而且,最终的预测使用贝叶斯优化进行了调整。 假设我们有理想的概率,则可以通过以下公式获得具有最佳期望垫(即最优类型)的F2:
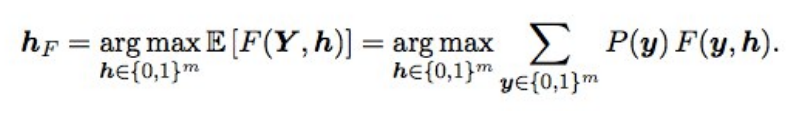
这是什么意思? 我们需要对所有组合进行分类(即对于每个标签0和1),计算每种组合的概率,然后乘以F2-得到期望的F2。 对于哪种组合更好,并且将给出最佳F2。 概率被简单地认为是单个标签的概率的乘积(如果标签为0,我们取1-p),并且为了不对2到17个选项进行分类,仅交错概率为0.05到0.5的标签-连续有3-7个标签,所以选项一点(提交在几分钟内完成)。 从理论上讲,获得标签组合的概率很酷,不仅可以乘以单个概率(因为标签不是独立的),而且还行不通。
它给了什么? 当模型变好时,在集成系统停止工作后选择阈值,这使得验证和公共/私有方面都出现了小而稳定的增长。
后记结果,我们训练了48种不同的模型,每个模型有10折,即 一级480个型号。 这样的人类教会使我在训练深度卷积神经网络时可以尝试不同的技术,但我仍然在工作和比赛中使用它。
是否有可能训练更少的模型并获得相同或更好的结果? 是的,相当。 我们来自第三名的同胞Stanislav
stasg7 Semenov和Roman
ZFTurbo Soloviev花费较少的第一层模型,而抵消了250多个第二层模型。 关于解决方案,您可以
查看分析并
阅读文章。
第一名是神秘的最佳拟合。 总的来说,这个家伙很酷,现在他已经参加了许多图片比赛,因此成为Keggle的头等功。 他一直保持匿名状态很长时间,直到Nvidia通过
采访他揭开面纱。 他承认有200名下属会向他汇报。还有一个关于这一决定的
职位 。
另一个有趣的事情:在狭窄的圈子里广为人知的
杰里米·霍华德 (
Jeremy Howard )的父亲
fastai完成了22m。 而且,如果您认为他只是为他的粉丝发送了几份意见书,那么您就不会猜到。 他参加了该团队并发送了111个包裹。
此外,当时正在参加传奇CS231n课程的斯坦福大学研究生,并被允许将此任务用作课程项目,使整个团队排在了排行榜的中间。
另外,我在Mail.ru
上讲了这篇文章的材料,这是弗拉基米尔·伊格洛维科夫在山谷会议上的另一场
演讲 。