或者我如何最终进入了Machines Can See 2018对抗竞赛的获胜团队。
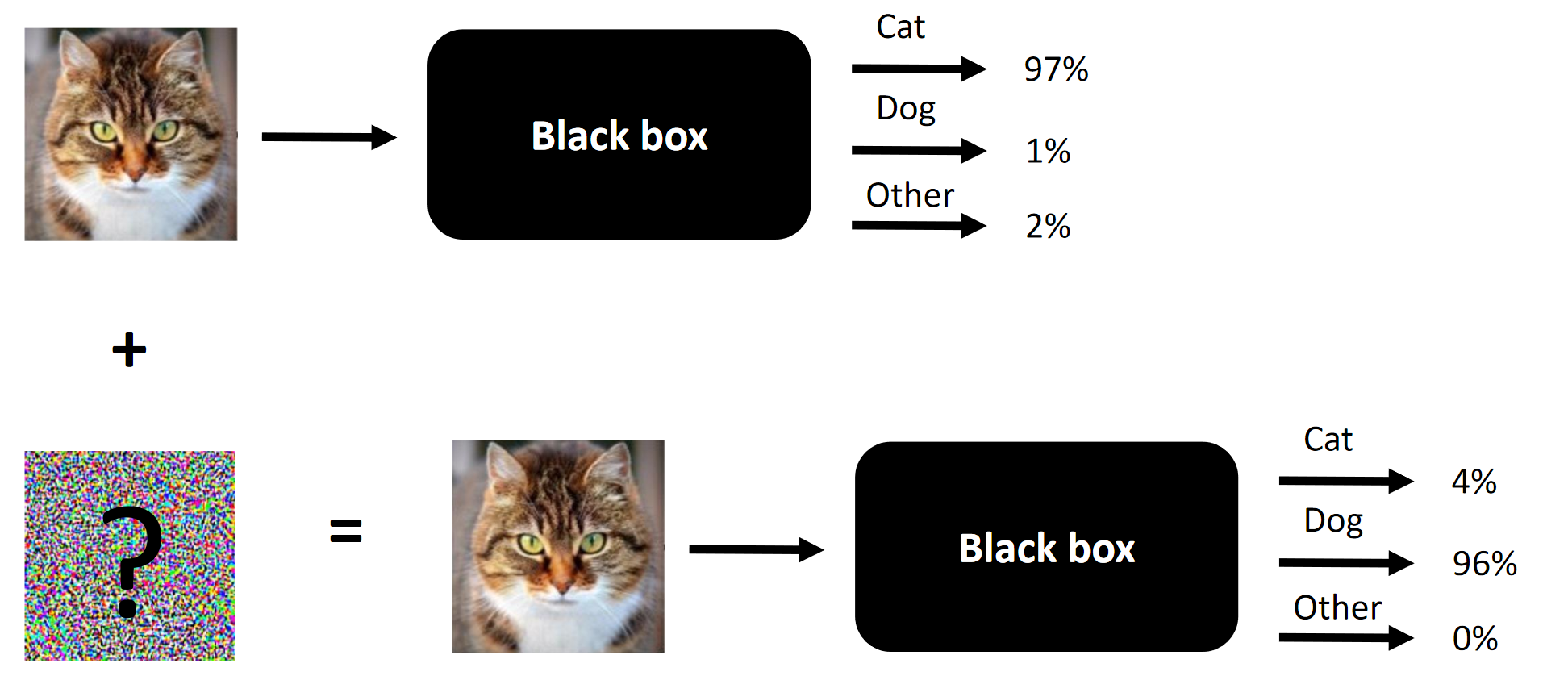 任何竞争性攻击的本质就是一个例子。
任何竞争性攻击的本质就是一个例子。碰巧我碰巧参加了Machines Can See 2018竞赛。我参加竞赛有点晚了(大约结束前一周),但最终以4人组成的团队结束了比赛,我们三个人(包括我)的贡献是胜利所必需的(删除一个组成部分,我们将是局外人)。
竞赛的目的是改变人们的面孔,以使组织者以黑匣子形式呈现的卷积神经网络无法区分源面孔和目标面孔。 允许的更改数量受到
SSIM的限制。
原始文章发布
在这里 。
注意事项 术语的笨拙翻译或它的缺乏取决于俄语中既有术语的缺乏。 您可以在评论中建议您的选项。 比赛的本质是改变入口处的面孔,以使黑匣子无法区分两个面孔(至少从L2 /欧氏距离的角度而言)
比赛的本质是改变入口处的面孔,以使黑匣子无法区分两个面孔(至少从L2 /欧氏距离的角度而言)在竞争性攻击中有效的方法以及在我们的案例中有效的方法:
- 快速渐变符号方法(FGSM)。 增加试探法会使它变得更好。
- 快速梯度值法(FGVM)。 增加试探法使其变得更好。
- 遗传差异进化(有关此方法的精彩文章 )+逐像素攻击;
- 模型集合(高端解决方案... 6个“堆叠” ResNet34);
- 智能绕过目标图像的组合;
- 本质上,在FGVM攻击期间尽早停止;
在我们的情况下无效的是:
- 在FGVM上添加“惯性矩”(尽管它对排名较低的团队有用,所以整合+启发式方法是否比添加时刻效果更好?);
- C&W 攻击 (本质上是针对白盒模型日志的端到端攻击)-适用于白盒(BY),不适用于黑盒(CN);
- 一种基于端到端暹罗LinkNet(类似于UNet,但基于ResNet的体系结构)的方法。 也仅适用于BY;
我们没有尝试的事情(没有时间,没有足够的努力或太懒惰):
- 用于学生学习的解释性增强测试(我也必须重新叙述这些描述符-很简单,但是这种简单的想法并没有马上出现);
- 攻击过程中的增强-例如,从左到右“镜像”图片;
关于一般比赛:
- 数据集“太小”(1000 5 + 5个组合);
- 学生网络培训数据集相对较大(超过100万张图片);
- CE是作为Caffe上的一组预编译模型提供的(自然,在我们的环境中,它们首先发布错误)。 由于QW不批量接受图像,因此也带来了一些复杂性。
- 比赛有一个出色的基准(基本解决方案),我认为没有这个基准,很少有人会直接参与其中。
资源:
- 具有代码的存储库 ,以重复我们的结果;
- 我们的介绍 ;
- 所有获奖者的介绍;
1.机器概述可以看到2018年比赛以及我如何参加比赛
竞争与方法
老实说,我被一个有趣的新领域所吸引,那就是GTX 1080Ti创始版的奖项以及相对较低的竞争(在任何一场竞赛中,4000人在Kaggle的整个ODS中都无法与每个团队使用20个GPU的ODS进行比较)。
如上所述,竞争的目的是欺骗CE模型,以便后者无法区分两个不同的人(就L2范数/欧几里得距离而言)。 好吧,因为这是一个黑匣子,所以我们不得不在提供的数据上提取学生网络,并希望QW和BYW的梯度足够相似以进行攻击。
如果您阅读了文章的评论(例如,
在这里和
那里 ,尽管这些文章并没有真正说出实际可行的方法)并汇编了高层团队取得的成就,那么您可以简要描述以下最佳实践:
- 在实施中最简单的攻击涉及BY或对进行攻击的卷积神经网络(或简单的体系结构)的内部结构的了解;
- 聊天中的某人建议跟踪CE上的推理时间并尝试猜测其架构。
- 可以访问足够数量的数据,您可以使用训练有素的QW来模拟QW
- 大概最先进的方法是:
- 端到端的C&W攻击(在这种情况下不起作用);
- 智能FGSM扩展(即惯性矩+棘手的合奏);
坦率地说,我们仍然感到困惑的是,两个完全不同的端到端方法(由团队中两个不同的人独立实施)愚蠢地不适用于CH。 从本质上讲,这可能意味着在我们对问题陈述的解释中,存在着我们没有注意到的数据泄漏(或者双手弯曲)。 在许多现代计算机视觉任务中,端到端解决方案(例如,样式转换,深层次的分水岭,图像生成,噪声和伪像的清理等)比以前要好得多,或者根本不起作用。 嗯
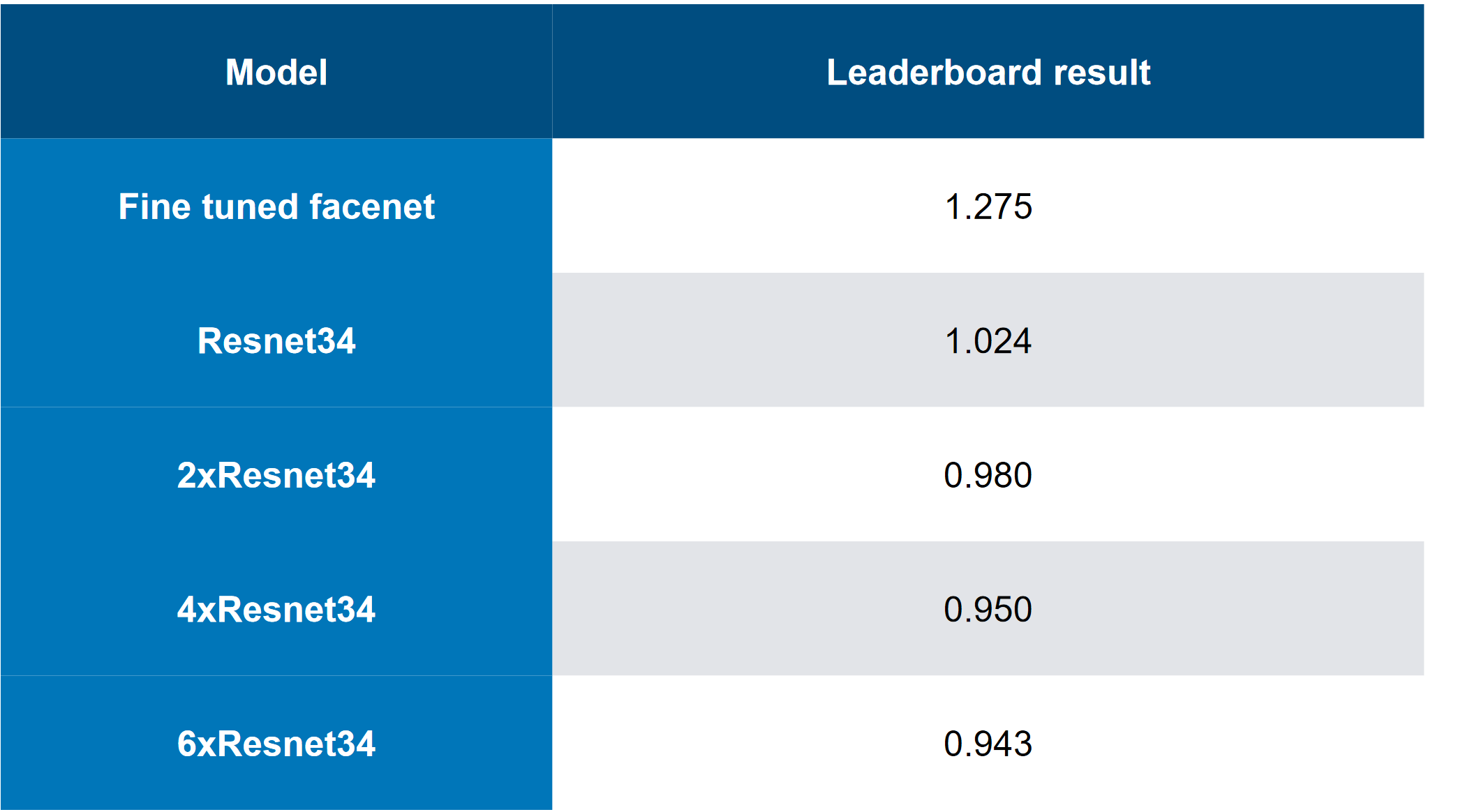
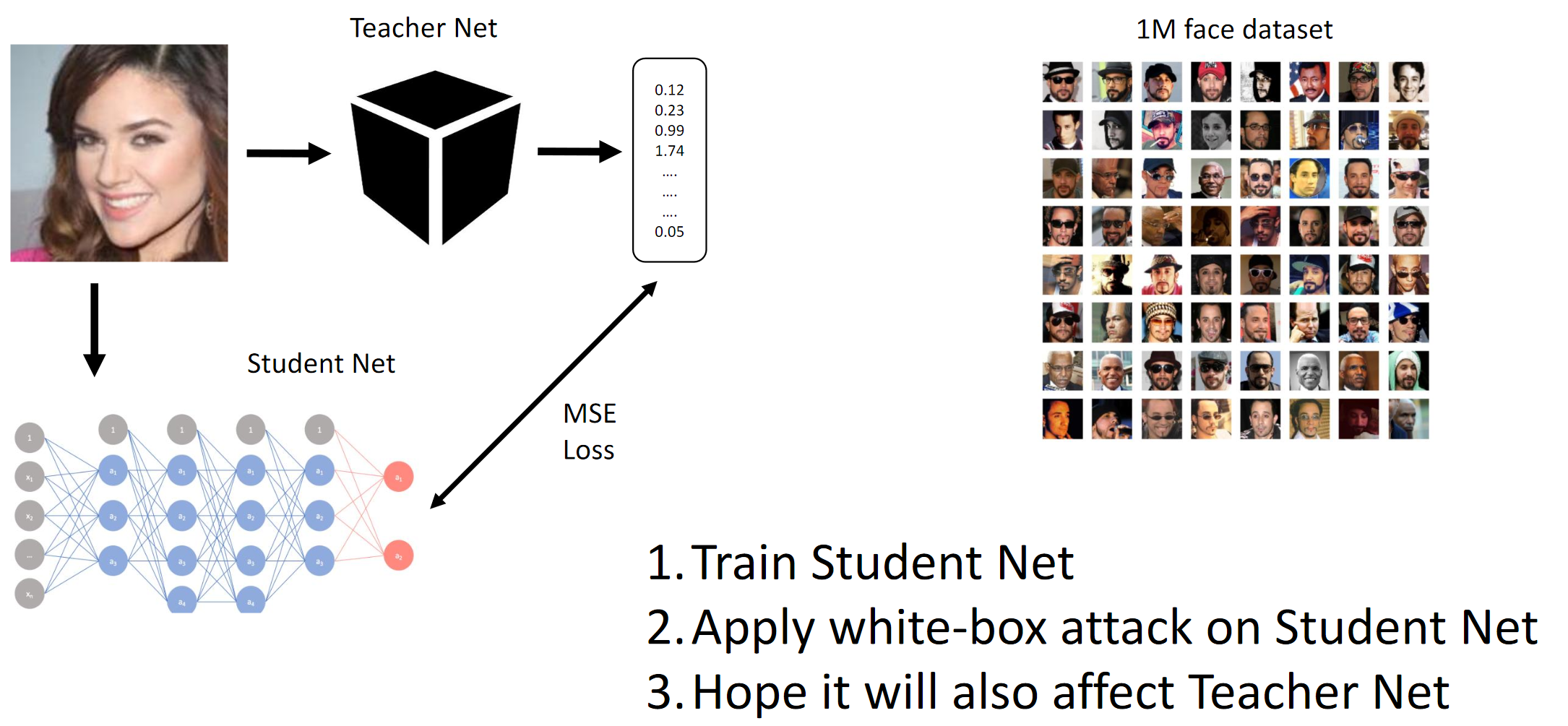 1.训练学生网。 2.对学生网进行BY攻击。 3.希望教师网攻击也能传播梯度法的工作原理
1.训练学生网。 2.对学生网进行BY攻击。 3.希望教师网攻击也能传播梯度法的工作原理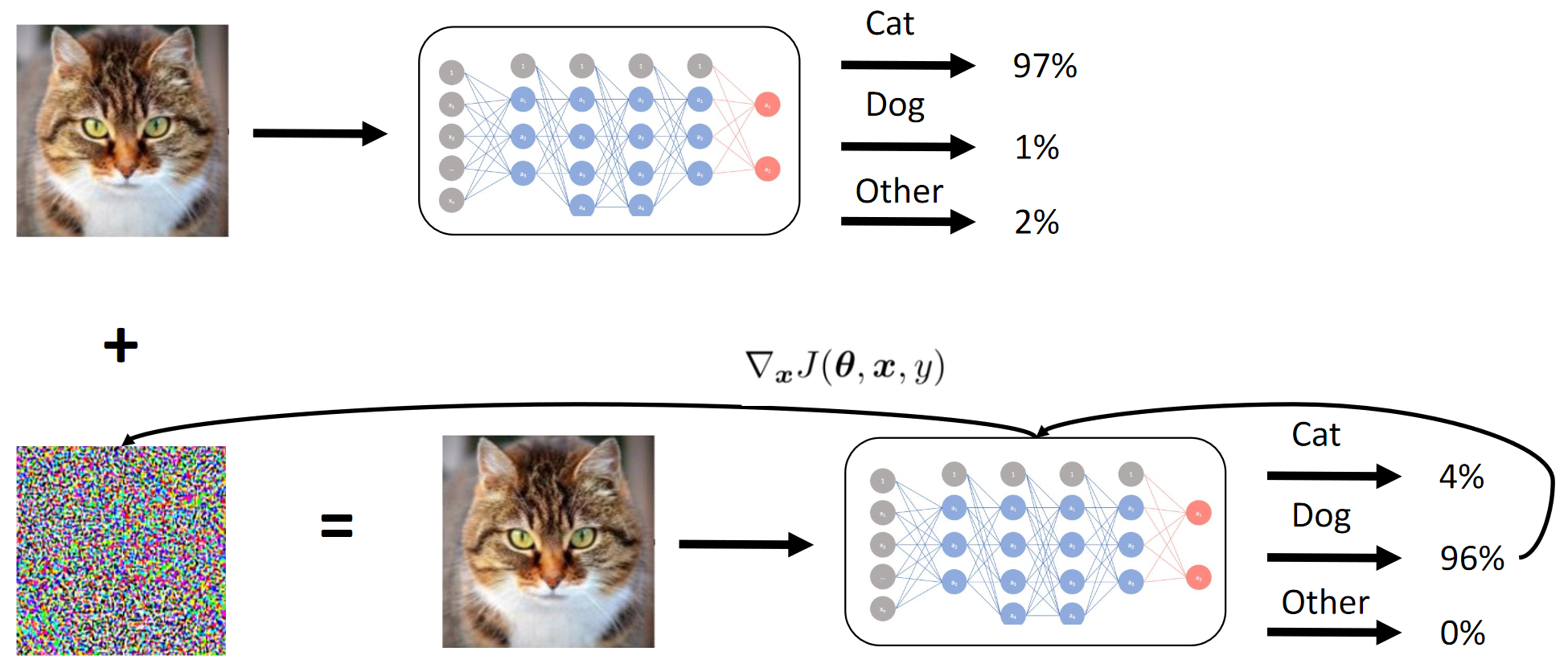
通过蒸馏,我们基本上实现了BY在模仿BY。 然后考虑输入图像相对于模型输出的梯度。 像往常一样,秘密在于启发法。
目标指标
目标度量是源图像和目标图像的所有25个组合之间的平均L2范数(欧氏距离)(5 * 5 = 25)。
由于平台(CodaLab)的局限性,私人分数(以及团队合并)很可能是手动计算的,这就是一个故事。

团队
在训练了学生网格之后,我加入了团队,这比排行榜上的其他所有人都好(据我所知),并且与
Atmyre进行了一些讨论(她为正确编写的QW提供了帮助,因为她本人也面临同样的问题)。 然后,我们共享了本地分数,而没有共享方法和代码,实际上,在终点之前2-3天发生了以下情况:
- 我的连续模型失败了(是的,在这种情况下也是);
- 我拥有最好的学生模型;
- 他们(团队)对FGVM的启发式变化最好(他们的代码基于基线)。
- 我只是试用了带有渐变的模型,并达到了1.1的局部速度-最初,我不想根据个人喜好使用基线(我挑战了自己);
- 他们当时没有足够的计算能力;
- 最后,我们尝试了运气并加入了我们的力量-我投入了我的计算能力/卷积神经网络/消融测试集。 团队输入了自己的代码库,并完善了几周。
我再次感谢她的宝贵建议和组织技巧。
团队组成:
github.com/atmyre-根据行动,最初是团队的队长。 在最后的提交中增加了遗传差异进化攻击;
github.com/mortido-FGVM攻击的最佳实现,具有出色的试探法,并使用基线代码训练了2个模型;
github.com/snakers4-除了进行任何测试以减少寻找解决方案的选择数量之外,我还训练了3个具有最佳度量标准的Student模型+提供的计算能力+在最终提交和呈现结果的阶段提供了帮助;
github.com/stalkermustang;结果,我们彼此都学到了很多东西,我很高兴我们在这次比赛中尝试了运气。 如果三分之二以上至少缺一分,将导致失败。
2.蒸馏学生CNN
在训练学生模型时,我设法获得了最佳速度,因为我使用了自己的代码而不是基线代码。
关键点/有效方法:- 为每种架构分别选择培训方案;
- 第一次训练使用Adam + LR衰减;
- 仔细监测不足和过拟合的能力以及模型能力;
- 手动调整训练模式。 不要完全相信自动方案:它们可以起作用,但是如果您对设置进行了很好的设置,则培训时间可以减少2-3倍。 这对于像DenseNet这样的重型模型尤为重要。
- 重型架构的性能优于轻型架构,不包括VGG。
- 使用L2损失而不是MSE进行训练也可以,但是更糟;
什么不起作用:- 基于初始的架构(由于高下采样和较高的输入分辨率而不合适)。 尽管排在第三位的团队能够以某种方式使用Inception-v1和完整图片(〜250x250);
- 基于VGG的体系结构(过度拟合);
- 轻量级架构(SqueezeNet / MobileNet-装修不足);
- 图像增强(无需修改描述符-尽管该团队以某种方式将其从第三位拉了下来);
- 处理全尺寸图像;
- 在竞赛组织者提供的神经网络的末尾,还存在一个批处理规范层。 这对我的同事没有帮助,我使用了我的代码,因为我不太了解为什么要使用该层。
- 将显着性地图与基于像素的攻击一起使用。 我想这更适合全尺寸图片(只需比较112x112x search_space和299x299x search_space);
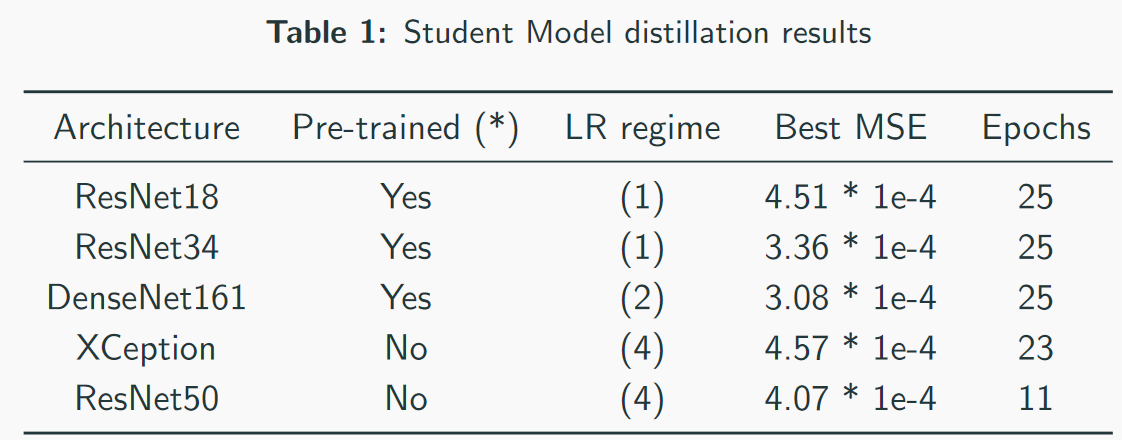 我们的最佳型号-请注意,最佳速度为3 * 1e-4。 从模型的复杂性来看,可以粗略地认为QW是ResNet34。 在我的测试中,ResNet50 +的性能比ResNet34差。
我们的最佳型号-请注意,最佳速度为3 * 1e-4。 从模型的复杂性来看,可以粗略地认为QW是ResNet34。 在我的测试中,ResNet50 +的性能比ResNet34差。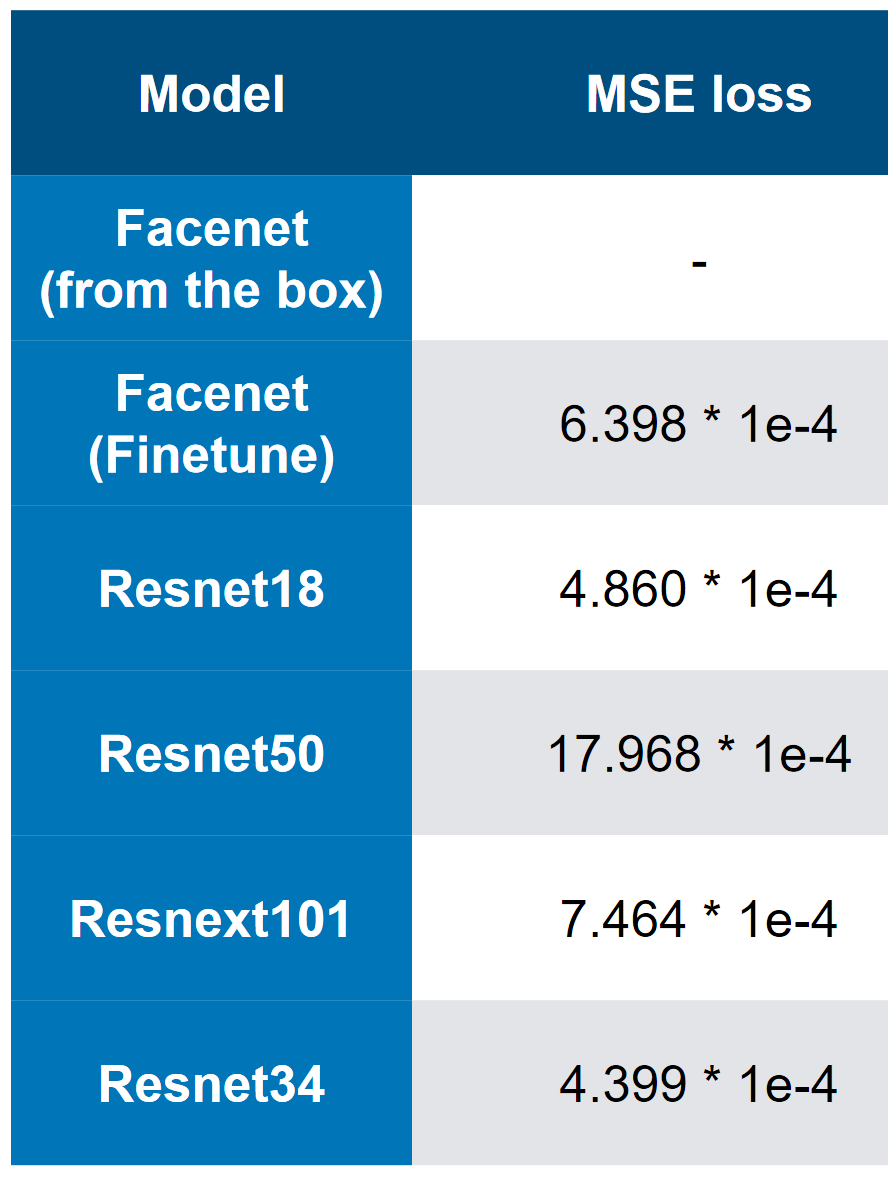 MSE第一名损失
MSE第一名损失3.最终速度和“消融”分析
我们这样收集速度:
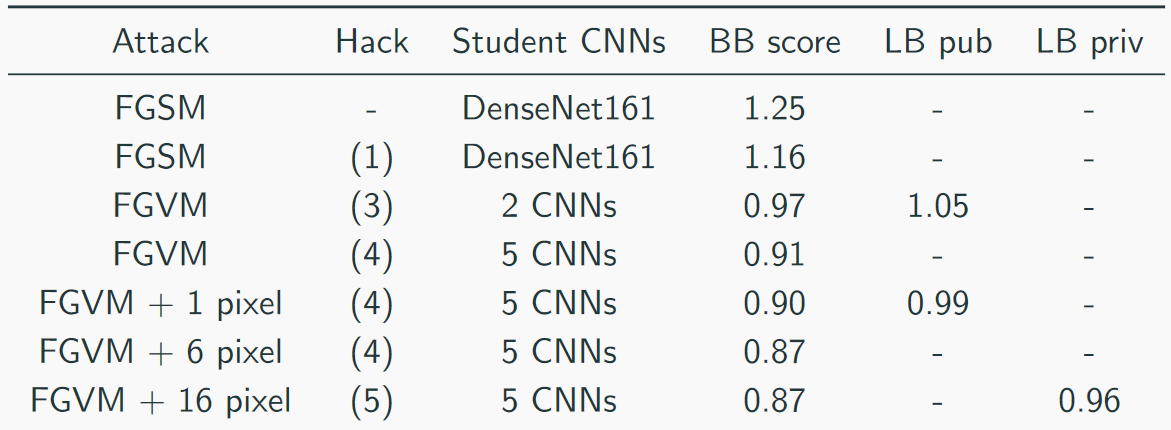
顶级解决方案看起来像这样(是的,有个笑话,就是仅仅堆叠屠宰,您可以猜测CH是屠宰):
其他团队的其他有用方法:
- 自适应参数epsilon;
- 数据扩充
- 转动惯量;
- 内斯特罗夫的时刻 ;
- 镜像
- 稍微“缺乏”数据-只有1000个独特的图像和5000个图像组合=>可以生成更多数据(不是5个目标,而是10个,因为重复了这些图像);
FGVM的有用启发式:
- 噪声产生的规则是:噪声= eps *钳位(grad / grad.std(),-2,2);
- 通过加权多个CNN的梯度来形成整体;
- 仅当更改减少平均损失时才保存更改;
- 使用目标组合以实现更一致的定位
- 仅使用高于均值+标准差的梯度(对于FGSM);
简短的Sammari:
- 首先是一个比较“笨拙”的决定
- 我们拥有最“多样化”的解决方案;
- 第三名是最“优雅”的解决方案。
端到端解决方案
即使它们失败了,将来也值得在新任务上再次尝试。 请参阅存储库中的详细信息,但实际上我们尝试了以下操作:
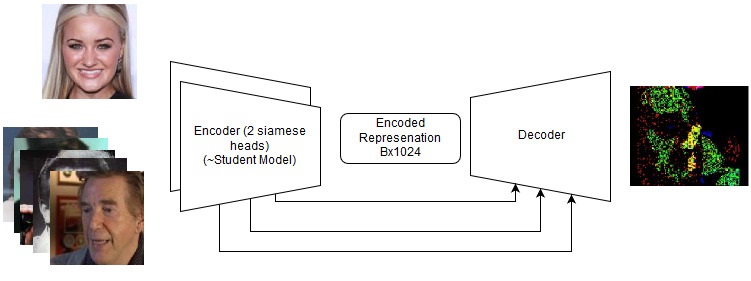 端到端模型
端到端模型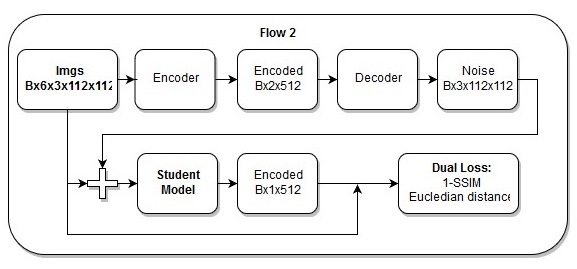 端到端模型中的动作顺序
端到端模型中的动作顺序我也认为我的
损失是美丽的。
5.参考资料和其他阅读材料
- 比赛页面;
- 我们的仓库 ;
- 有关VAE的一系列文章是类似的主题。
- SSIM资源
- 差异进化资源
- 简报
- 2最有用的文章:
- 2条评论文章“在顶部”: