2018年5月17日发布安装蜂箱后,我立即想到:“我想知道如何计算到达和离开的蜜蜂数量吗?”
一项小型研究表明:到目前为止,似乎没有人想出一种好的非侵入性系统来解决这一问题。 但是,拥有此类信息以检查蜂巢的健康状况可能会很有用。
首先,您需要收集数据样本。 Raspberry Pi,标准Pi相机和太阳能电池板:这种简单的设备足以每10秒记录一帧并每天保存5000+张图像(从早上6点到晚上9点)。

下面是一个示例图像...您可以数多少只蜜蜂?

到底是什么问题?
其次,有必要提出神经网络应该做什么的问题。 如果任务是“计算图像中的蜜蜂”,则可以尝试获取特定数字,但这似乎不是最简单的选择,并且在帧之间跟踪单个蜜蜂不会带来任何乐趣。 相反,我决定专注于定位图像中的每只蜜蜂。
快速检查标准逐帧检测器不会产生任何特定结果。 这不足为奇,特别是考虑到蜂巢入口附近的蜜蜂密度(提示:转移训练并不总是有效),但这是正常的。 因此,我的图像非常小,只有一类用于识别对象,因此边界框没有任何特殊问题。 只需确定是否有蜜蜂。 哪种解决方案会更简单?
v1:完全卷积网络上的“蜂吃/不吃”片段
第一个快速实验是“图片中的蜜蜂是/不是”检测器。 也就是说,在此图像片段上至少有一只蜜蜂的概率是多少。 以
完全卷积的网络形式在图片的很小片段上执行此操作意味着您可以轻松地以全分辨率处理数据。 该方法似乎可行,但是对于蜂密度很高的蜂巢入口区域却失败了。
v2:RGB图像→黑白位图
我很快意识到可以将问题简化为图像变换问题。 在输入处,摄像机信号为RGB,在输出处为单通道的图像,其中“白色”像素表示蜜蜂的中心。
 RGB输入(片段)和单通道输出(片段)
RGB输入(片段)和单通道输出(片段)打标
第三步是贴标签,即指定名称。 部署一个小的
TkInter应用程序以选择/
取消选择图像中的蜜蜂并将结果保存在SQLite数据库中并不是很困难。 我花了很多时间正确配置此工具:任何手动进行大量标记的人都会理解我:/
稍后,我们将幸运地看到,使用大量样本,您可以通过半自动方法获得不错的结果。
型号
网络体系结构是非常标准的u-net。
- 在半分辨率的片段上训练的全卷积网络 ,但在全分辨率的图像上工作;
- 编码是四个卷积3×3的序列,增量为2
- 解码-最近邻居的大小变化序列+以1的增量折叠3×3 +跳过与编码器的连接;
- 最终的卷积层1×1与步骤1一起激活了S型函数(即,每个像素的二进制选择“ bee is / is not”)。
经过一些经验实验,我决定返回半分辨率解码。 够了
我通过调整到最接近的邻居的大小来进行解码,而不是出于习惯而进行反卷积。
该网络是通过
Adam方法训练的,规模太小,无法进行
批量归一化 。 事实证明,该设计非常简单,只需几个过滤器就足够了。

我应用了标准的数据增强方法,随机旋转和颜色失真。 对片段进行训练意味着我们实际上得到了随机切片图像的变体。 我没有旋转图像,因为相机始终站在蜂巢的一侧。
后处理输出预测中有一些细微差别。 通过概率结果,我们得到了可能有蜜蜂的模糊云。 为了将其转换为每只蜜蜂一个像素的清晰图片,我添加了一个阈值,同时考虑了相关组件并使用
skimage度量模块检测了质心。 所有这些都必须手动安装并完全靠肉眼来配置,尽管从理论上讲,它可以作为学习的一部分添加到堆栈的末尾。 也许将来再做... :)
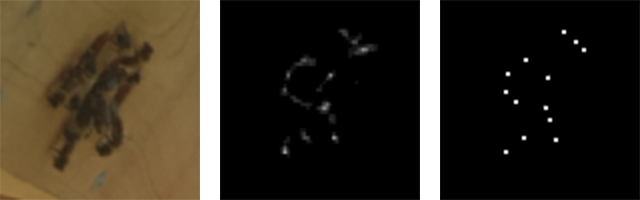 输入,原始输出和聚类质心
输入,原始输出和聚类质心几天概括
一日之内
最初,在短短的一天内对图像进行了实验。 事实证明,从带有少量标记图像(约30张)的数据中获得良好模型很容易。
 第一天收到三个样品
第一天收到三个样品好多天了
当我开始考虑几天的较长时间时,事情变得更加复杂。 关键差异之一是照明的差异(一天中的时间和不同的天气)。 另一个原因是我每天都手动安装相机,只是将其粘在魔术贴上。 第三个也是最出乎意料的差异是,随着草的生长,蒲公英的芽看起来像蜜蜂(也就是说,在第一轮中,训练有素的模型没有看到芽,然后它们出现并提供了连续不断的假阳性)。
大多数问题已通过数据扩充解决,但没有一个问题变得很关键。 通常,数据变化不大。 这很棒,因为它允许您将自己局限于简单的神经网络和训练方案。
 三天内获得的样品
三天内获得的样品预测范例
该图显示了一个预测示例。 有趣的是,蜜蜂比我手动标记的任何图片都要多。 这是一个很好的确认,即对小片段进行学习的完全卷积方法确实有效。

该网络可以在多种选项中正常工作。 我想这里有一个统一的背景会有所帮助,并且在任意配置单元上启动网络都不会取得如此好的效果。
 从左至右:入口周围密度高; 不同大小的蜜蜂; 蜜蜂高速!
从左至右:入口周围密度高; 不同大小的蜜蜂; 蜜蜂高速!标签技巧
半控制训练
立即获得大量图像的可能性暗示了使用半控制训练的想法。
一个非常简单的方法:
- 拍摄10,000张图像。
- 标记100张图像和训练
model_1 。 - 使用
model_1标记剩余的9900张图像。 - 在“已标记”的10,000张图像上训练
model_2 。
结果,
model_2显示出比
model_1更好的结果。
这是一个例子。 请注意,
model_1显示了一些假阳性(左中和草叶)和假阴性触发器(蜂巢入口周围的蜜蜂)。
 左模型_1,右模型_2
左模型_1,右模型_2通过修复不良模型进行标记
这样的数据也是一个很好的例子,说明修复不良模型比从头开始标记要快得多……
- 我们标记10张图像并训练模型。
- 我们使用该模型标记接下来的100张图像。
- 我们使用标记工具来校正这100张图像上的标记。
- 用110张图片重新训练模型。
- 我们重复...
这是一种非常常见的学习模式,有时它会迫使您稍微修改标签工具。
数数
检测蜜蜂的可能性意味着我们可以算出它们! 为了娱乐,请绘制有趣的图形来显示白天的蜜蜂数量。 我喜欢他们整天工作的方式,并在下午4点左右回家。 :)
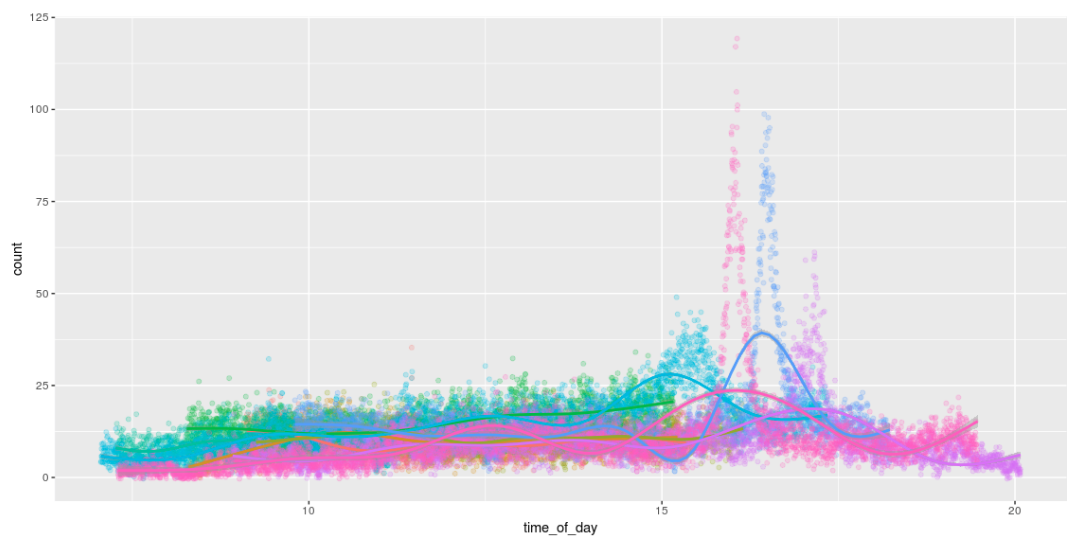
树莓派输出
在Pi上启动模型是该项目的重要组成部分。
直接上铁皮
最初计划冻结TensorFlow图并直接在Pi上运行它。 这可以正常工作,但是只有Pi每秒仅拍摄1张图像。 :/
在Movidius计算模块上运行
我对使用
Movidus神经计算棒在Pi上启动模型的机会非常感兴趣。 这是一个了不起的小工具。
不幸的是,什么都没有发生:/。 将TensorFlow图转换为其内部模型格式的API不支持我的解码方法。 因此,有必要使用反卷积而不是在最近的邻居上调整大小来增加大小(放大)。 除了什么都没有发生之外,没有任何问题。 由于
虫子成倍增加 ,因此存在许多小的困难。 修复它们后,您可以返回此主题...
v3型:RGB图像→蜜蜂计数这使我想到了模型的第三个版本:我们可以直接从RGB输入进行蜜蜂计数吗? 这样,尽管结果不太可能像质心模型v2一样好,但我们将避免Movidus神经计算棒上不受支持的操作引起的任何问题。
起初,我很害怕尝试这种方法:我认为它将需要更多的标签(它不再是基于片段的系统)。 但是! 拥有一个可以很好地搜索蜜蜂的模型以及许多未标记的数据,您可以通过应用v2模型并简单地计算检测次数来生成一组良好的合成数据。
这样的模型很容易学习,并且给出有意义的结果……(尽管它仍然不如对v2模型检测到的质心的简单计算那样好)。
| 一些测试样品中蜜蜂的实际和预测数量 |
| 真正的 | 40 | 19 | 16 | 15 | 13 | 12 | 11 | 10 | 8 | 7 | 6 | 4 |
| v2(质心)预测 | 39 | 19 | 16 | 13 | 13 | 14 | 11 | 8 | 8 | 7 | 6 | 4 |
| v3(简单计算)预测 | 33.1 | 15.3 | 12.3 | 12.5 | 13.3 | 10,4 | 9.3 | 8.7 | 6.3 | 7.1 | 5.9 | 4.2 |
...不幸的是,该模型
仍无法在神经计算棒上运行(也就是说,它可以运行,但只能给出随机结果)。 我又做
了一些错误报告,然后再次推迟了该小工具,以便以后……有一天……
接下来是什么?
与往常一样,一堆小东西仍然存在...
- 在神经计算棒(NCS)上启动; 现在我们正在等待他们的一些工作...
- 将所有内容移植到内置的JeVois相机 。 我对她有些困惑,但首先我想在NCS上发布一个模型。 我想以120 FPS的速度追踪蜜蜂!!!
- 在多个帧/摄像机之间跟踪蜜蜂以可视化光流。
- 更详细地探索半控制方法的好处,并训练较大的模型为较小的模型标记数据。
- 探索NCS功能; 设置超参数怎么办?
- 继续开发小型版本的FarmBot,以对CNC幼苗进行一些基因实验(即完全不同的东西)。
代号
所有代码都
在Github上发布。