哈Ha 今天,我想提出
变分优化的主题,并介绍如何将其应用于修剪神经网络中非信息通道的任务(修剪)。 使用它,可以相对轻松地提高神经网络的“发射率”,而无需改动其体系结构。
减少机器学习算法中冗余元素的想法并不是什么新鲜事。 实际上,它早于深度学习的概念:决定性树的树枝被切割,现在在神经网络中权重才更早。
基本思想很简单:我们在网络中找到无用权重的子集并将其归零。 没有详尽的搜索,很难说出哪些权重真正参与了预测,哪些权重只是假装的,但这不是必需的。 各种正则化方法,最佳脑损伤和其他算法都可以正常工作。 为什么要去掉所有的砝码? 事实证明,这提高了网络的泛化能力:通常,不重要的权重要么只是将噪声引入预测中,要么针对训练数据集的迹象(即再训练的伪像)进行了专门的锐化。 从这个意义上讲,可以将连接的减少与网络训练期间断开随机神经元(丢失)的方法进行比较。 此外,如果网络有很多零,它将占用档案中较少的空间,并且在某些体系结构上能够更快地读取。
听起来不错,但更有趣的是,不丢掉单独的权重,而是丢掉完全连接的层或通道中的神经元。 在这种情况下,可以更清楚地观察到网络压缩和预测加速的效果。 但这比破坏单个体重更复杂:如果尝试进行“最佳脑部伤害”,而不是一个连接,而是整个捆绑,结果可能不会很令人印象深刻。 为了能够无痛地移除神经元,有必要将其制作成没有任何有用的连接。 为此,您需要以某种方式诱导“强”神经元变强,而“弱”神经元变弱。 这项任务已经为我们所熟悉:实际上,我们迫使网络变得稀疏,并对权重分组施加一些限制。
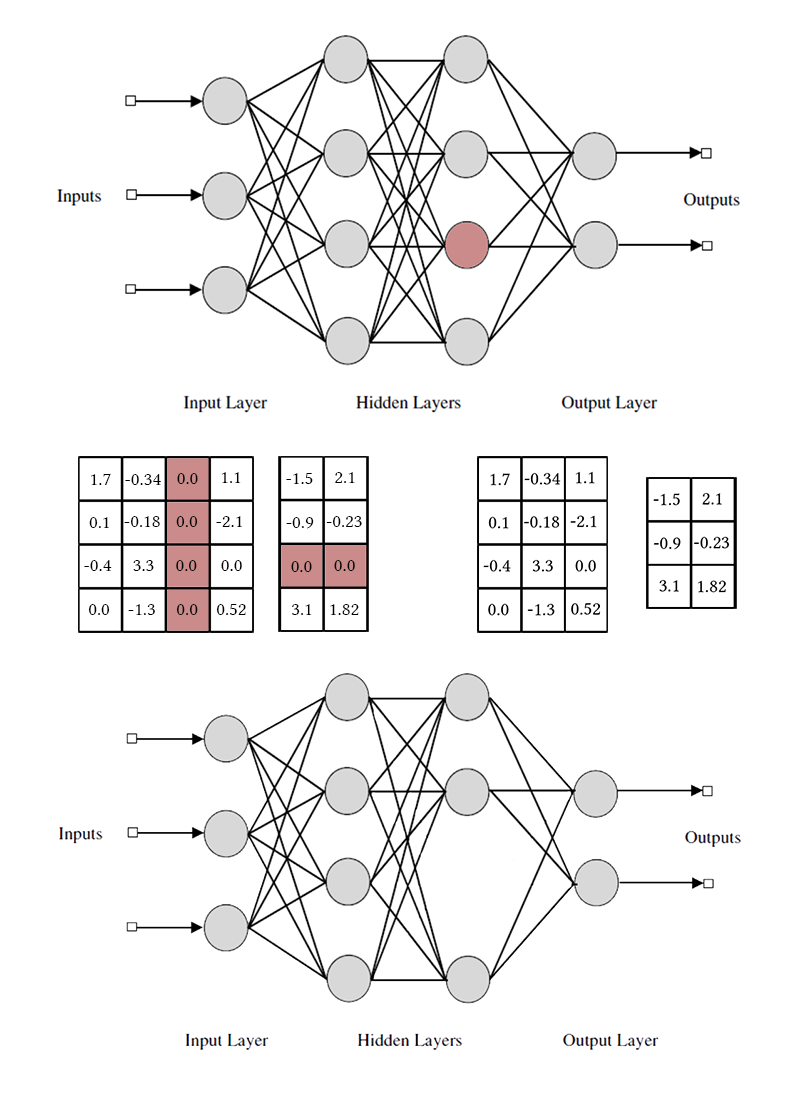
请注意,要删除一个神经元或卷积通道,您需要修改两个权重矩阵。 我不会区分卷积通道和神经元:它们的作用是相同的,只是去除的特定权重和移位方法不同。
简单方法:组L1正则化
首先,我将向您介绍从网络中删除多余神经元的最简单有效的方法-组LASSO-regularization。 通常,它用于使网络中无用的权重保持接近零。 它简单地归纳为逐个案例的情况。 与常规正则化不同,我们不直接对权重或图层激活进行正则化,这个想法有些棘手。 [通道修剪,用于加速非常深的神经网络; 何益辉等; 2017]
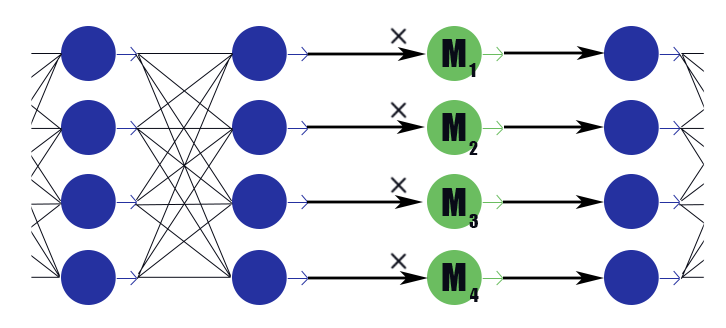
考虑具有权重向量的特殊蒙版层
M=( beta1, beta2,\点, betan) 。 他的结论只是零散的工作
M 根据上一层的结论,他没有激活功能。 我们将掩膜层放置在每一层之后的通道中,将要丢弃的通道放置在这些层中,并对这些层中的权重进行L1正则化。 因此,面膜的重量
betai 乘以该层的第i个输出就暗含了对该结论所依赖的所有权重的限制。 如果在这些权重中,说一半有用,则
betai 将保持更接近统一,这个结论将能够很好地传递信息。 但是,如果只有一个或根本没有,
betai 它会降为零,这将重置神经元的输出,并且实际上将重置此结论所依赖的所有权重(在激活函数等于零时为零的情况下)。 请注意,以这种方式,如果合法的权重较大或法律上的强烈回应,则该网络所受到的负面强化就会减少。 整个神经元的有用性至关重要。
原来这个公式:
哪里
lambda -损失'网络和稀疏'的加权常数。 看起来像通常的L1正则化公式,只有第二项包含掩蔽层的向量,而不包含网络的权重。
经过网络训练后,我们遍历了神经元及其掩盖值。 如果
betai 超过某个阈值,然后将神经元权重乘以
betai 如果更少,则从传入和传出权重的矩阵中删除与神经元相对应的元素(如图中稍高一些)。 此后,可以删除掩码并完成网络。
在组LASSO的应用中,有一些微妙之处:
- 正常正则化。 连同掩码权重的正则化,L1 / L2正则化应应用于所有其他网络权重。 如果不这样做,在不饱和激活函数(ReLu,ELu)的情况下,掩盖重量的减少将很容易通过增加重量来补偿,并且无效效果将不起作用。 是的,对于普通的乙状结肠,这可以使您以积极的反馈更好地开始这一过程: Mi 无关紧要的输出变小,这就是为什么优化器必须更认真地考虑每个特定权重的原因,这会使输出变得更无用的信息,这就是为什么 Mi 减少更多,依此类推。
- 文章的作者还建议对层的重量施加球形限制 |Wi|2=1 。 这可能应该有助于从弱神经元到强神经元的平衡“流动”,但是我没有注意到有太大的区别。
- 推拉训练。 本文的作者建议交替训练神经网络的正常权重和掩盖权重。 它比一次教所有内容要长,但结果似乎好一点吗?
- 固定掩模后,不要忘记对网络进行长时间微调(微调),这一点非常重要。
- 仔细监控您的口罩的站立状态:激活功能之前或之后。 当参数为零(例如,S型)时,激活可能不等于零,可能会遇到问题。
- 修剪对batchnorm不友好,其原因与丢弃对它不友好的原因相同:从规范化的角度来看,当数据包中有32个值时,其中32个值为零,而当数据包中有20个值是非常不同的情况时。 撕掉归零余额后,batchnorm层学习到的分布不再有效。 您需要在所有batchnorm层之后插入修剪层,或以某种方式修改后者。
- 将信道减少应用于分支体系结构和残差网络(ResNet)也存在困难。 在合并分支过程中修剪了多余的神经元后,尺寸可能会不一致。 这很容易通过引入缓冲层来解决,在缓冲层中我们不会拒绝神经元。 此外,如果网络分支承载的信息量不同,则设置不同的值是有意义的。 lambda 这样就不会发现修剪只切除了信息最少的分支中的所有神经元。 但是,如果所有神经元都被切除,那不是那么重要的分支吗?
- 在问题的原始陈述中,对非零通道的数量进行了严格限制,但在我看来,仅更改初始损失的权重参数和掩蔽权重的L1损失就足够了,然后让优化器确定要保留多少个通道。
- 捕获口罩。 这不是原始文章中的内容,但是在我看来,这是提高收敛性的良好实用机制。 当遮罩的值达到某个预定的较低值时,我们将其重置,并禁止更改遮罩的这一部分。 因此,在模型训练期间,较弱的权重已完全停止对预测做出贡献,并且不会在相应的量中引入任何杂散值。 从理论上讲,这可能会阻止潜在有用的渠道恢复服务,但是我认为这实际上并没有发生。
困难的方法:L0正则化
但是我们不是在寻找简单的方法,对吗?
使用L1正则化的信道拒绝并不完全公平。 它允许通道在“强响应”-“弱响应”-“零响应”的范围内移动。 仅当掩膜权重足够接近零时,我们才使用捕获掩膜丢弃通道。 这样的运动极大地扭曲了画面,并在训练过程中改变了其他通道:在前一个神经元完全关闭时,他们必须学会如何系统地给出较弱的响应时才能做些什么,然后才能学习该做什么。
让我提醒您,理想情况下,我们希望从网络中选择信息最少的频道,继续学习没有它的网络,删除下一个信息最少的频道,再次调整网络,依此类推。 las,以这种表述,即使对于相对简单的网络,该任务在计算上也是难以承受的。 而且,这种方法不会给通道带来第二次机会-一旦远端神经元无法再次恢复操作。 让我们稍微改变一下任务:我们有时会移除神经元,有时会留下它。 此外,如果神经元整体上有用,那么它通常会被保留,但如果它没有用,反之亦然。 为此,我们将使用与L1正则化相同的掩膜层(并非没有理由引入它们!)。 只有它们的权重不会在吸引子为零的情况下沿整个实轴移动,而是集中在0和1周围。不是说它变得简单得多,而是至少解决了神经元分类去除的问题。
网络培训师的本能表明,通过穷举搜索来解决问题是不值得的,但是您需要将当前运行层中活跃神经元的数量添加到损失函数中。 但是,这样的损耗项将是逐步恒定的,并且梯度下降无法使用它。 有必要以某种方式教导学习算法,尽管没有梯度,但要定期排除一些神经元。
我们有一种临时去除神经元的方法:我们可以对蒙版层应用一个滤除。 在训练期间
betai=1 很有可能
pi 和
betai=0 很有可能
1− pi 。 现在,在损失函数中,您可以将总和
pi 这是一个实数。 在这里,我们面临另一个障碍:分布是离散的,尚不清楚反向传播是如何工作的。 通常,这里有特殊的优化算法可以为我们提供帮助(请参阅REINFORCE),但是我们将采用不同的方法。
然后是
变分优化开始
起作用的时刻:我们可以通过连续的1来近似掩蔽层中零和一的离散分布,并使用常规的反向传播算法优化后者的参数。 这就是[通过L0正则化学习稀疏神经网络; Christos Louizos等; 2017]。
连续分布的作用将由坚硬的混凝土分布来发挥[混凝土分布:离散随机变量的连续松弛; 克里斯·麦迪逊; 2017],这是一个近似于伯努利分布的对数中的棘手事情:
alpha -相对于中心的偏移分布,以及
beta -温度。 在
Beta rightarrow0 分布越来越接近真实伯努利分布,但失去了可微性。 在
0< beta<1 分布密度是凹的(这是我们感兴趣的情况),
beta>1 -凸 我们通过刚性S形传递此分布,以便它可以以有限的非零概率熟练地给出
z=0 和
z=1 ,并且在区间(0,1)上具有连续的可微分密度。 修剪完成后,我们查看分布朝哪个方向移动并替换随机变量
z 到特定的掩码值
beta 我们把已经确定的模型带到了条件上。
为了感觉更好的分布,我将给出一些针对不同参数的密度示例:
分布密度 a l p h a = 0.0 , b e t a = 0.8 :
 a l p h a = 1.0 , b e t a = 0.8
a l p h a = 1.0 , b e t a = 0.8 :
 a l p h a = 2.0 , b e t a = 0.8
a l p h a = 2.0 , b e t a = 0.8 :
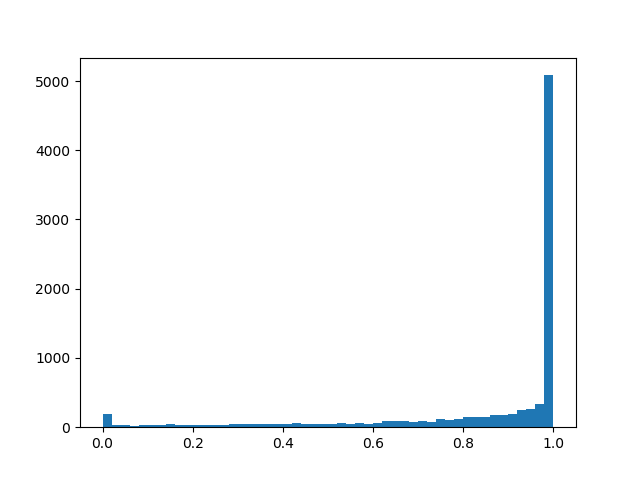 alpha=0.0, beta=0.5
alpha=0.0, beta=0.5 :
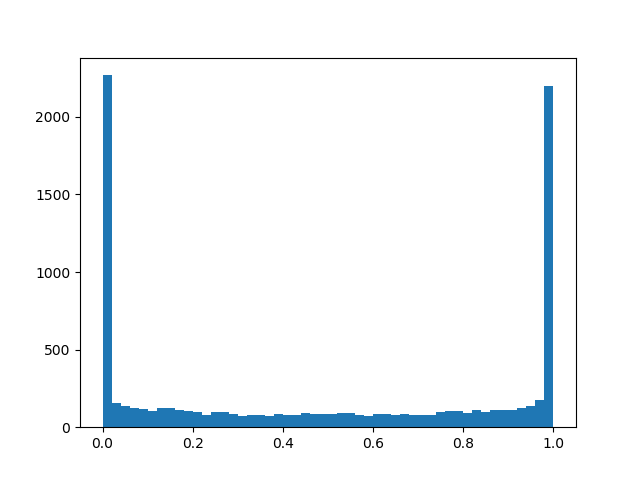 alpha=1.0, beta=0.5
alpha=1.0, beta=0.5 :
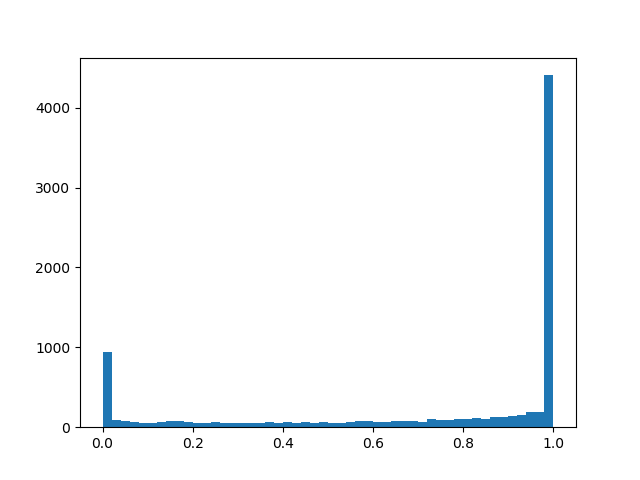 alpha=2.0, beta=0.5
alpha=2.0, beta=0.5 :
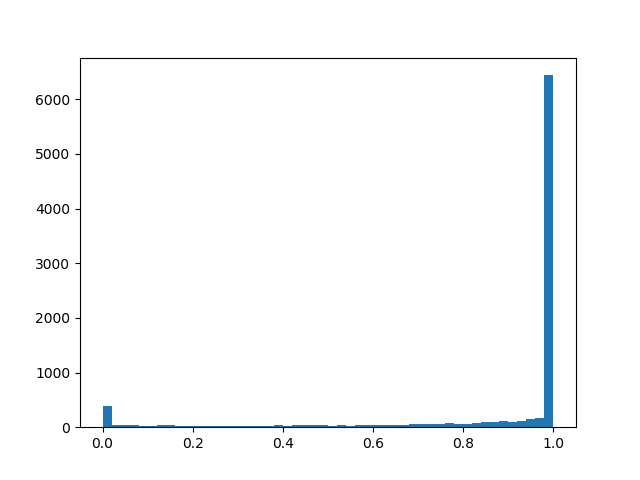 alpha=2.0, beta=0.1
alpha=2.0, beta=0.1 :
 alpha=2.0, beta=2.0
alpha=2.0, beta=2.0 :
从本质上讲,我们有一个“智能”辍学层,可以了解应该更频繁地抛弃哪些结论。 但是我们到底在优化什么呢? 在损失中,应将分布密度的积分放在非零区域(简单地说,在训练过程中蒙版最终变为非零的概率):
下列功能已添加到推挽式训练,正则正则化和有关L1正则化一章中提到的其他实现细节中:
- 再一次:我们的“智能”辍学层以某种明显的概率重置了输出,有些则保留了它的原样,此外,取决于 beta, xi, gamma 输出将被一个0到1的随机数相乘。最后一部分对我们的最终目标来说是寄生的,而不是有用的,但是没有任何形式-反向传播回传是必需的。
- 一般而言 alpha 和 beta -训练参数,但是在我的实验中,我觉得如果你问一点 beta (0.05),并且在学习过程中仍会线性减少,算法的收敛性要好于您诚实地学习算法。 alpha 最好设置足够大 log alpha\约2.5 这样一来,最初保存的神经元多于丢弃的神经元,但其大小不足以使损失的乙状结肠饱和。
- 如果替换为公式 \日志 alpha 只是 alpha 好像网络在训练期间融合得更好,并且不太可能碰到NaN。 通过这种操作,一定不能忘记更改损失函数和初始化中的项。
- 另外,如果您作弊并用损失较大的硬质合金代替损失中的普通乙状结肠, log alpha in[−4,4] ,正规化将更好地融合并发挥更大的作用。
- 到 alpha 和 beta 您还可以应用正则化来进一步增加稀疏性。
- 训练后,您应该对结果进行二值化,并使用确定的掩码持续训练网络,直到val精度达到常数为止。 这篇文章提供了一个更准确的公式,通过该公式可以在验证过程中确定神经元的输出或将网络释放为释放状态,但是看来在训练结束时 alpha 事实证明,这种极化足以使简单的启发式方法起作用: alpha<0 -遮罩0, alpha geq0 -遮罩1(但这不准确)。 使用确定性蒙版后,您将看到质量的飞跃。 不要忘记我们来到这里是零权重,并且在某个权重阈值以下,您仍然需要将掩蔽权重替换为零。
- L0方法的另一个优点-屏蔽层开始像辍学一样工作,这为网络带来了强大的正则化效果。 但这是一把双刃剑:如果您开始训练太少, alpha 可能会破坏预先训练的网络结构。
实验
对于实验,请使用CIFAR-10数据集和一个相对简单的网络(由四个卷积层组成),然后是两个完全连接的层:Conv2D,Mask,Conv2D,Mask,Pool2D,Conv2D,Mask,Conv2D,Mask,Pool2D,Flatten,Dropout(p = 0.5) ,密集,蒙版,密集(登录)。 人们认为修剪的算法在较厚的网络上可以更好地工作,但是在这里我遇到了一个纯粹的技术问题,即缺乏计算能力。 作为优化器,使用了学习率= 0.0015和批量大小= 32的Adam。此外,还使用了常规的L1(0.00005)和L2(0.00025)正则化。 没有应用图像增强。 该网络在收敛之前经过了200个时期的训练,之后被保留下来,并对其应用了神经元减少算法。
除了应用上述算法进行修剪外,我们还设置了一个琐碎的参考点以确保算法完全可以完成某些工作。 让我们尝试扔掉每一层的第一层
k 神经元并结束生成的网络。
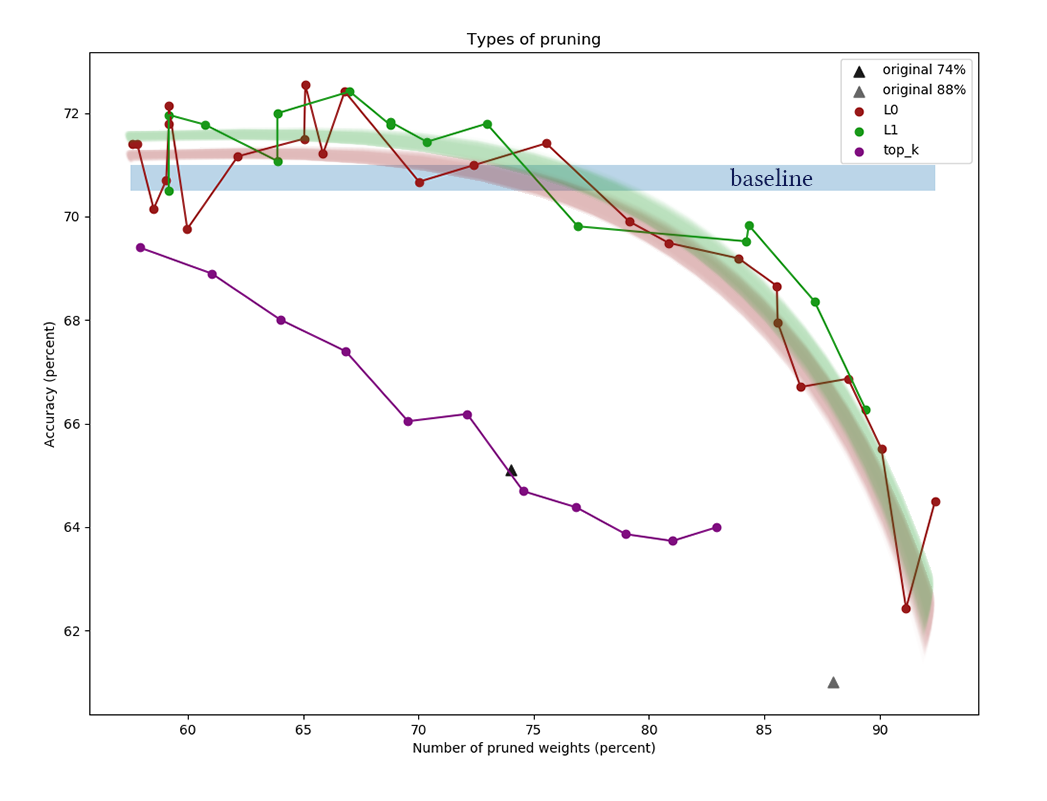
该图显示了在使用不同正则化功率常数进行的一系列实验之后,比较L1和L0通道缩减算法的结果。 x轴
表示应用算法后
重量减少的百分比。 在Y轴上,验证样本中切割网络的精度。 中间的蓝色条表示尚未切断神经元的网络的近似质量。 绿线代表一种简单的L1掩模学习算法。 红线是L0修剪。 紫线-第一次移除
k 渠道。 黑色三角形-训练最初权重较小的网络。
CIFAR-100的另一个示例,它具有近似相同的体系结构和相似的训练参数,且网络稍长且较宽:
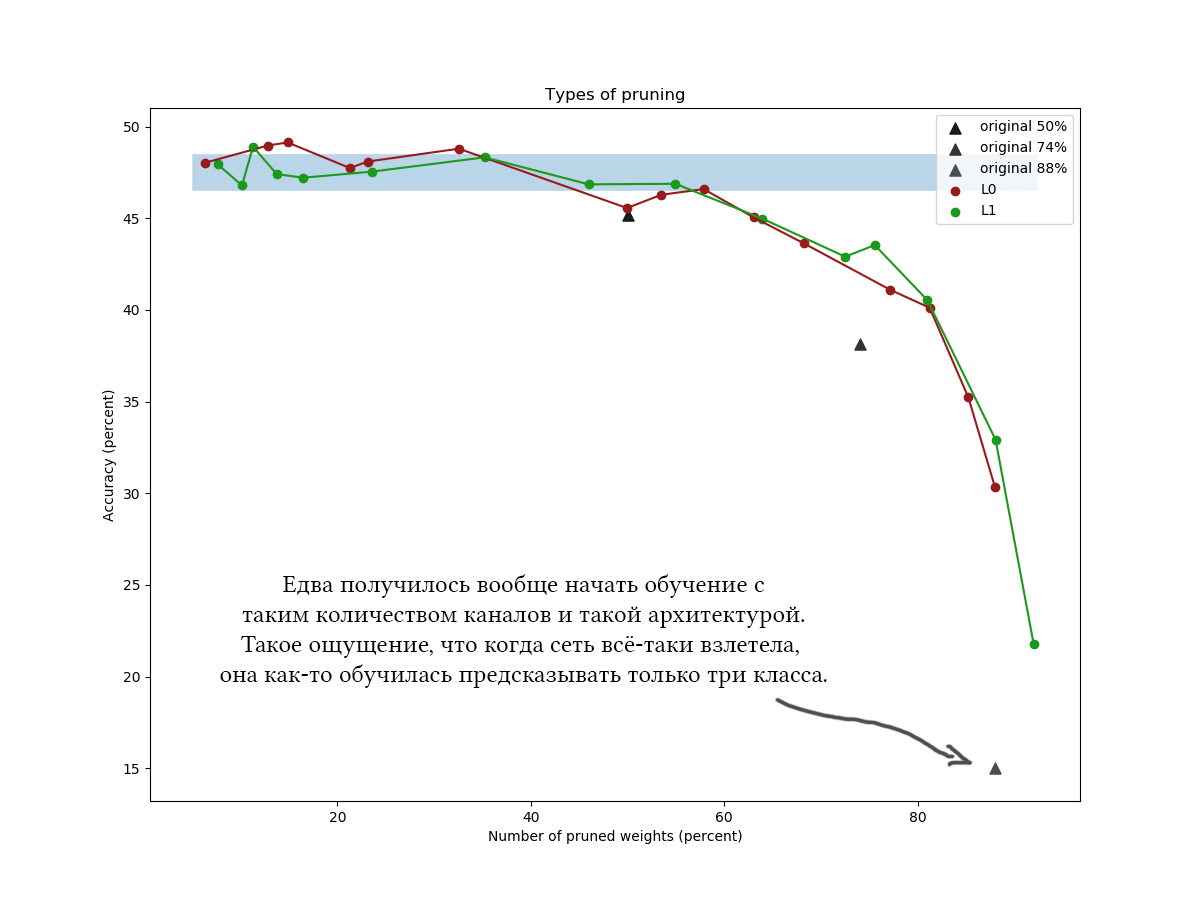
在图中可以清楚地看到,简单的L1算法可以应付狡猾的变分优化,并且在低压缩值下甚至可以提高网络质量。 通过其他数据集和网络体系结构的一次性实验也证实了该结果。 这是绝对预期的结果,当我开始进行网络还原实验时就可以依靠它。 老实说 igh
好吧,老实说,我有些惊讶,并尝试使用算法和网络:不同的体系结构,网络超参数,精确的公式,具体的硬分布,初始值
alpha 和
b e t a,中间调整的时期数。 L0规范化在理论上看起来很酷,但是在实践中,获取超参数更加困难,而且需要更长的时间,因此,我建议您在没有其他实验和文件处理的情况下使用它。请不要考虑花费在阅读本文上的时间:L0修剪看起来确实非常可信,我想说我宁愿将算法错误地应用于某个地方,也没有收到承诺的收益。此外,变分优化是更高级的约简算法的基础(例如,使用变分信息瓶颈压缩神经网络,2018年)。通常,可以得出以下结论:- . 30-50% . «» , . [The Lottery Ticket Hypothesis: Training Pruned Neural Networks, J. Frankle and M. Carbin, 2018] ( , , , ).
- , . . , ?
- , . 60-90% . k <7%, .
- , (<60%) : , !
- L1 L0 (APoZ), , .. , k .
- , . , , , , . , , . pruning' , . - , .
还记得我在博文开头写过的话,即完成修剪算法之后,您可以“完全切断多余的网络部分”吗?因此,切断多余的网络绝非易事。 Tensorflow和其他库构建了一个计算图,并且在已经运行时不能轻易更改它。您必须使用计算出的蒙版保存网络,从中删除必要权重的列表,根据需要转置权重,删除置零的组,转置回去,并根据输出的张量集创建新网络。生成的网络应具有与原始网络相同的布局,但它将具有较少的神经元。在创建初始和最终网络的功能方面,要保持相同的网络方案会让人头疼,尤其是当它们不是线性的而是分支的时。为了方便遮罩,您可能必须创建自己的图层。这很容易,但是要小心,向哪些集合添加掩膜选项。容易出错,并且不小心训练了频道缩减参数以及所有其他比例。应当指出,架构不是很深的网络的权重的很大一部分通常集中在从卷积部分到完全连接的部分的过渡上。这是由于以下事实:最后一个卷积层被弄平了,其结果是在其中形成了神经元的(通道数)*(宽度)*(高度),并且下一个权重矩阵非常宽。这些重量不太可能减少。此外,不应该这样做,否则网络的最后一层将被“盲目”到某些地方发现的功能。在这种情况下,请尝试减小最终通道数,并使用maxpool'ing甚至使用完全卷积或完全完全连接的体系结构。谢谢大家的关注,如果有人有兴趣在CIFAR-10和CIFAR-100上重复实验,该代码可以在github上获取。祝您工作愉快!