第一部分,“ Cavium ThunderX2评估:Arm Server的梦想成真”在
这里测试配置和方法
为了进行ThunderX2审查,我们所有的测试均在Ubuntu Server 17.10,Linux 4.13 64位内核上进行。 我们通常使用LTS版本,但是由于Cavium随附了此特定版本的Ubuntu,因此我们没有冒险更改操作系统。 Ubuntu发行版包含GCC 7.2编译器。

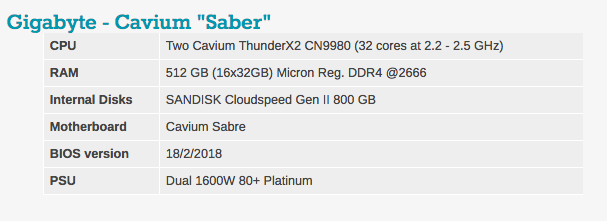
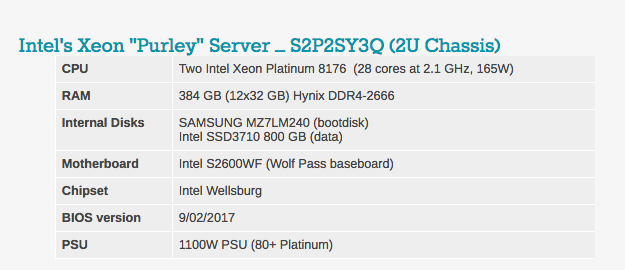
您会注意到,在我们的服务器配置中,DRAM的数量有所不同。 原因很简单:英特尔有6个内存通道,而Cavium的ThunderX2有8个内存通道。
典型的BIOS设置可以在下面看到。 值得注意的是,其中包括超线程和英特尔虚拟化技术。
其他注意事项两台服务器均根据欧洲标准-230 V(最大16安培)供电。 我们的Airwell CRAC仪器将室内空气温度控制和维持在23°C。
能源消耗
值得一提的是,如果技嘉“ Sabre”系统仅运行Linux(即大部分处于空闲状态),则消耗500瓦。 但是,在负载下,该系统消耗约800 W的功率,这基本上满足了我们的期望,因为内部有两个180 W的TDP芯片。 与早期测试系统通常一样,我们无法进行准确的功率比较。
实际上,Cavium声称,惠普,技嘉和其他公司的当前系统将效率更高。 所使用的Sabre测试系统在电源管理方面存在多个问题:风扇固件控制不当,BMC错误以及电源单元(1600 W)过多。
内存子系统:带宽
随着核心和内存通道数量的增长,在最新处理器上使用John McCalpin的Stream带宽基准测试基准变得越来越难以衡量系统带宽的全部潜力。 从下面的结果中可以看到,估计吞吐量并不容易。 结果在很大程度上取决于所选设置。

从理论上讲,ThunderX2的带宽比Intel Xeon多33%,因为SoC具有8个内存通道,而Intel却只有6个通道。 仅在非常特定的条件下才能实现这些高吞吐量,并且需要进行一些调整以避免使用远程内存。 特别是,我们必须确保流量不会从一个插座传送到另一个插座。
首先,我们试图在两种体系结构上都达到最佳效果。 在英特尔的情况下,ICC编译器通过在流循环内进行一些低级别的优化始终可以产生更好的结果。 对于鱼子酱,我们遵循了鱼子酱的指示。 粗略地说,所得到的结果是这些处理器在峰值时可以达到的带宽的想法。 老实说,采用理想设置(AVX-512),您可以达到200 GB / s。
但是,很明显,ThunderX2系统可以为其处理器内核提供15%到28%的带宽。 结果是235 GB / s,或每个插槽约120 GB / s。 反过来,这大约是原始ThunderX的3倍。
内存子系统:延迟
尽管带宽测量仅适用于服务器市场的一小部分,但几乎每个应用程序都高度依赖于内存子系统的延迟。 为了衡量缓存和内存延迟,我们使用了LMBench。 结果,我们希望看到的数据是“随机加载时的延迟,步进= 16字节”。 请注意,由于我们没有确切的L3缓存时钟值,因此我们将L3延迟和DRAM时间延迟表示为纳秒。
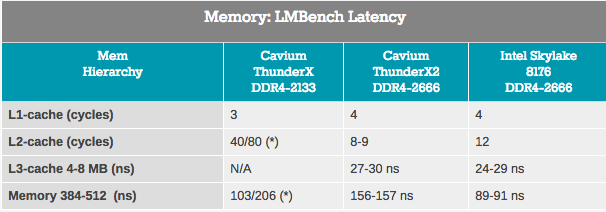
ThunderX2 L2缓存的访问延迟非常低,并且在使用单个流时,L3缓存看起来像是英特尔集成L3缓存的竞争对手。 但是,当我们使用DRAM时,英特尔显示出明显更少的延迟。
内存子系统:TinyMemBench
为了更深入地了解各自的体系结构,我们使用了开源测试TinyMemBench。 使用GCC 7.2编译了源代码,并且将优化级别设置为-O3。 测试策略在基准手册中有很好的描述:
测量各种大小的缓冲区中随机存储器访问的平均时间。 缓冲区越大,TLB缓存未命中,L1 / L2和DRAM访问的相对贡献就越大。 所有数字表示需要添加到L1缓存的延迟中的额外时间(4个周期)。
我们测试了一次和两次随机读取(没有大页),因为我们想了解内存系统如何处理多个读取请求。
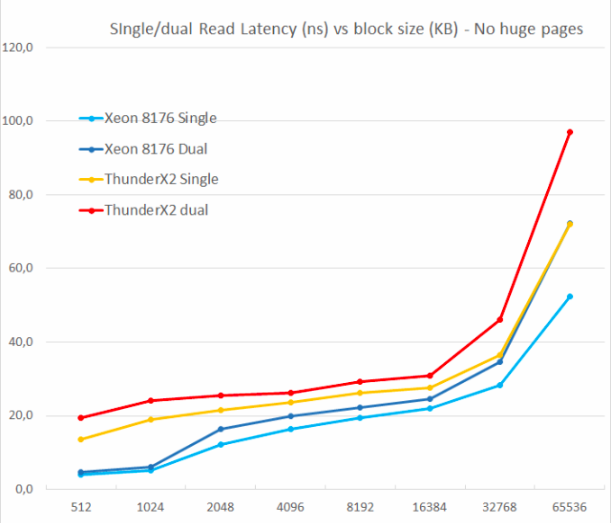
原始ThunderX的主要缺点之一是无法支持多个未命中事件。 内存级并发是任何高性能现代处理器内核的重要功能:借助其帮助,它可以避免可能导致后端“饥饿”的缓存丢失。 因此,无阻塞缓存是大型内核的关键功能。
凭借其非阻塞式缓存,ThunderX2根本不会遭受此问题的困扰。 就像至强8176中的Skylake核心一样,二读将总延迟仅增加15-30%,而不是100%。 根据TinyMemBench,Skylake内核具有明显更好的延迟。 512KB参考点很容易解释:Skylake内核仍在从其快速L2中检索,而ThunderX2内核必须访问L3。 但是1和2 MB的数字表明Intel预取器具有很大的优势,因为延迟是L2和L3缓存的平均值。 延迟率在8到16 MB范围内相似,但是一旦我们超过了L3(64 MB),英特尔的Skylake就会提供较低的延迟内存。
单线程性能:SPEC CPU2006
从测量实际的计算性能开始,我们从SPEC CPU2006软件包开始。 经验丰富的读者将指出,当SPEC CPU2017出现时,不建议使用SPEC CPU2006。 但是由于有限的测试时间以及我们无法重新测试ThunderX的事实,我们决定继续使用CPU2006。
鉴于SPEC与硬件几乎一样是编译器基准,因此我们认为制定我们的测试理念将是适当的。 您需要评估实际指标,而不是增加测试结果。 因此,在以下情况下尽可能创造“类似于现实世界”的条件非常重要(欢迎对此问题进行建设性批评):
- 64位gcc:Linux上最常用的编译器,一个不错的编译器,不会尝试“中断”测试(libquantum ...)
- -Ofast:许多开发人员可以使用的编译器优化
- -fno-strict-aliasing:编译一些子测试时需要
- 基本运行:每个子测试的编译方式相同
首先,您需要测量由于“恶意多线程环境”而由于某种原因而导致延迟的应用程序的性能。 其次,您需要了解与英特尔的Skylake架构相比,ThunderX LLC架构在单线程下的性能如何。 请注意,在特定的Skylake型号中,您可以将频率超频到3.8 GHz。 该芯片将在几乎所有情况下(2.8个活动线程)以2.8 GHz的频率运行,并通过14个活动线程支持3.4 GHz。
通常,Cavium将ThunderX2 CN9980($ 1795)定位为“优于6148”($ 3072),该处理器工作在2.6 GHz(20个线程)并达到3.3 GHz且没有任何问题(最多激活16个线程) ) 另一方面,在许多情况下(3.3 GHz与2.5 GHz),Intel-SKU在时钟速度上将具有30%的显着优势。
Cavium决定通过提供32个内核来补偿频率不足,提供32个内核-比Xeon 6148(20个内核)多60%。 值得注意的是,大量内核会导致许多应用程序(例如,Amdahl)的收益降低。 因此,如果Cavium希望通过ThunderX2撼动英特尔的主导地位,那么每个内核至少应提供具有竞争力的实际性能。 或者在这种情况下,ThunderX2应该提供至少66%(2.5对3.8)的单线程Skylake性能。
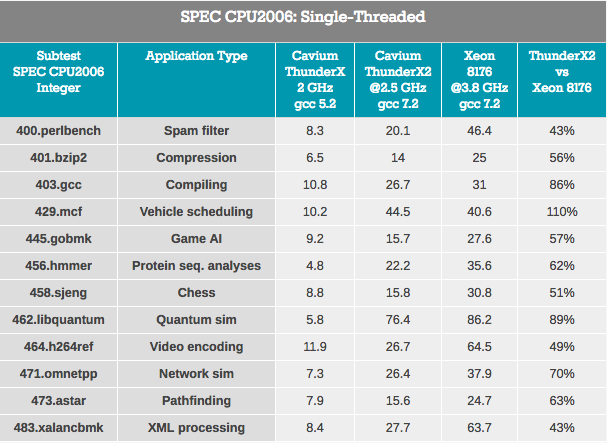
结果是模糊的,因为ThunderX2使用ARMv8代码(AArch64),而Xeon使用x86-64代码。
指针跟踪测试-XML处理(也是大型OoO缓冲区)并查找通常依赖于大型L3缓存以减少访问延迟影响的路径对于ThunderX2而言最糟糕。 可以假设DRAM系统的较高等待时间降低了性能。
分支预测的影响较高的工作负载(至少在x86-64上:选择错误的分支的百分比更高)-gobmk,sjeng和hmmer-不是ThunderX2的最佳负载。
还值得注意的是,众所周知,perlbench,gobmk,hmmer和h264ref指令受益于Skylake更大的L2缓存(512KB)。 我们仅向您展示一些难题,但它们可以一起帮助您将图片拼凑起来。
从好的方面来说,ThunderX2对于gcc效果很好,它主要在L1和L2缓存内工作(因此依赖于低L2延迟),并且分支预测器性能的影响最小。 通常,对TunderX2最好的测试是mcf(公共交通中的车辆分配),如您所知,依靠L2缓存,它几乎完全跳过了L1数据缓存,这就是ThunderX2的强项。 Mcf还要求内存带宽。 Libquantum是最需要内存带宽的测试。 Skylake提供相当平庸的单线程带宽的事实可能也是ThunderX2在libquantum和mcf上表现如此出色的原因。
SPEC CPU2006 Cont:具有SMT的基于内核的性能
除了单线程性能之外,还应考虑单个内核中的多线程性能。 Vulcan处理器体系结构最初设计为使用SMT4来保持其内核加载并提高整体吞吐量,现在我们将进行讨论。
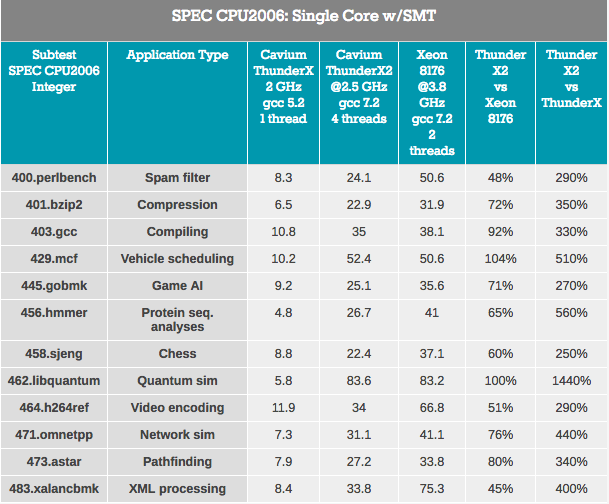
首先,ThunderX2内核相对于第一个ThunderX内核已“接受”了许多重大改进。 即使考虑到libquantum,在对编译器进行一些改进和优化之后,该测试也可以轻松地在较早的ThunderX内核上运行3倍的速度。 好吧,新款ThunderX2的速度至少比其老兄快3.7倍。 IPC的这种优势消除了以前的ThunderX的任何优势。
从SMT的影响来看,平均而言,我们发现4路SMT将ThunderX2性能提高了32%。 范围从视频编码的8%到寻路的74%。 同时,英特尔从其2向SMT中获得了18%的收益,在相同情况下从4%上升至37%。
总体而言,ThunderX2的性能提高了32%,这是相当不错的。 但是,这里出现了一个明显的问题:它与其他SMT4架构有何不同? 例如,还支持SMT4的IBM POWER8在同一场景中显示了76%的增长。
但是,这并不是相似与相似的比较,因为IBM芯片的后端要宽得多:它可以处理10条指令,而ThunderX2内核每个周期限于6条指令。 POWER8内核更加繁琐:在22 nm工艺下,处理器只能容纳190 W的功率预算中的10个“超宽”内核。 使用SMT4进一步提高性能可能需要更大的内核,进而严重影响ThunderX2内部可用的内核数量。 不过,有趣的是,未来将增长32%。
在下一个(3)部分中:
- Java性能
- Java性能:庞大的页面
- Apache Spark 2.x基准测试
- 总结
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或将其推荐给您的朋友来支持我们,
为我们为您发明的入门级服务器的独特模拟,为Habr用户提供
30%的折扣: 关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) ! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?