流复制出现在2010年,已经成为PostgreSQL的突破性功能之一,目前,如果不使用流复制,几乎没有安装可以完成。 它可靠,易于配置且不需要资源。 然而,尽管具有积极的品质,但在操作过程中可能会出现各种问题和不愉快的情况。
Highload ++ 2017上的
Alexey Lesovsky (
@lesovsky )介绍了如何使用内置和第三方工具
诊断各种类型的问题以及如何解决它们 。 在削减的基础上,本报告基于螺旋原理进行解码:首先,我们列出所有可能的诊断工具,然后继续列出常见问题并进行诊断,然后查看可以采取哪些紧急措施,最后从根本上解决该问题。
关于演讲者 :Data Egret的数据库管理员Alexei Lesovsky。 Alexey在PostgreSQL中最喜欢的主题之一是流复制和使用统计信息,因此Highload ++ 2017上的报告致力于如何使用统计信息发现问题以及使用什么方法解决问题。
计划
- 一些理论,或者说复制在PostgreSQL中是如何工作的
- 故障排除工具或PostgreSQL和社区拥有的东西
- 故障排除案例:
- 问题:他们的症状和诊断
- 决定
- 采取措施以免出现这些问题。
为什么要这样? 本文将帮助您更好地理解流复制,学习如何快速查找和解决问题,以减少对不愉快事件的响应时间。
一点理论
PostgreSQL具有一个实体,例如预写日志(XLOG),事务日志。 数据库中与数据和元数据有关的
几乎所有更改都记录在此日志中。 如果突然发生任何事故,PostgreSQL将启动,读取事务日志,并将记录的更改恢复到数据。 这样可以确保可靠性-也是所有DBMS和PostgreSQL的最重要属性之一。
可以通过两种方式填充事务日志:
- 默认情况下,当后端在数据库中进行某些更改(INSERT,UPDATE,DELETE等)时,所有更改都同步记录在事务日志中:
- 客户端发送了COMMIT命令以确认数据。
- 数据记录在事务日志中。
- 修复发生后,将控制权交给后端,并且后端可以继续从客户端接收命令。
- 第二个选项是异步写入事务日志,当一个单独的专用WAL编写器进程以一定的时间间隔将更改写入事务日志时。 因此,由于不需要等待COMMIT命令完成,因此可以提高后端性能。
最重要的是,流复制基于此事务日志。 我们有几个流复制成员:
- 掌握所有更改的发生位置;
- 多个副本接受主数据库的事务日志,并在其本地数据上重现所有这些更改。 这是流复制。
值得记住的是,所有这些事务日志都存储在$ DATADIR的pg_xlog目录中,该目录包含主DBMS数据文件。 在PostgreSQL的第十版中,此目录被重命名为pg_wal /,因为pg_xlog /占用大量空间并不罕见,并且开发人员或管理员在不知不觉中将其与日志混淆,不小心删除了它,一切都变得很糟。
PostgreSQL有一些后台服务涉及流复制。 让我们从操作系统的角度来看它们。
- 从主服务器一侧-WAL Sender过程。 这是一个将事务日志发送到副本的过程,每个副本将有自己的WAL发送者。
- 副本依次运行WAL接收器进程,该进程通过WAL发送者通过网络连接接收事务日志,并将它们传递给启动进程。
- 启动过程将读取日志,并在数据目录上重现记录在事务日志中的所有更改。
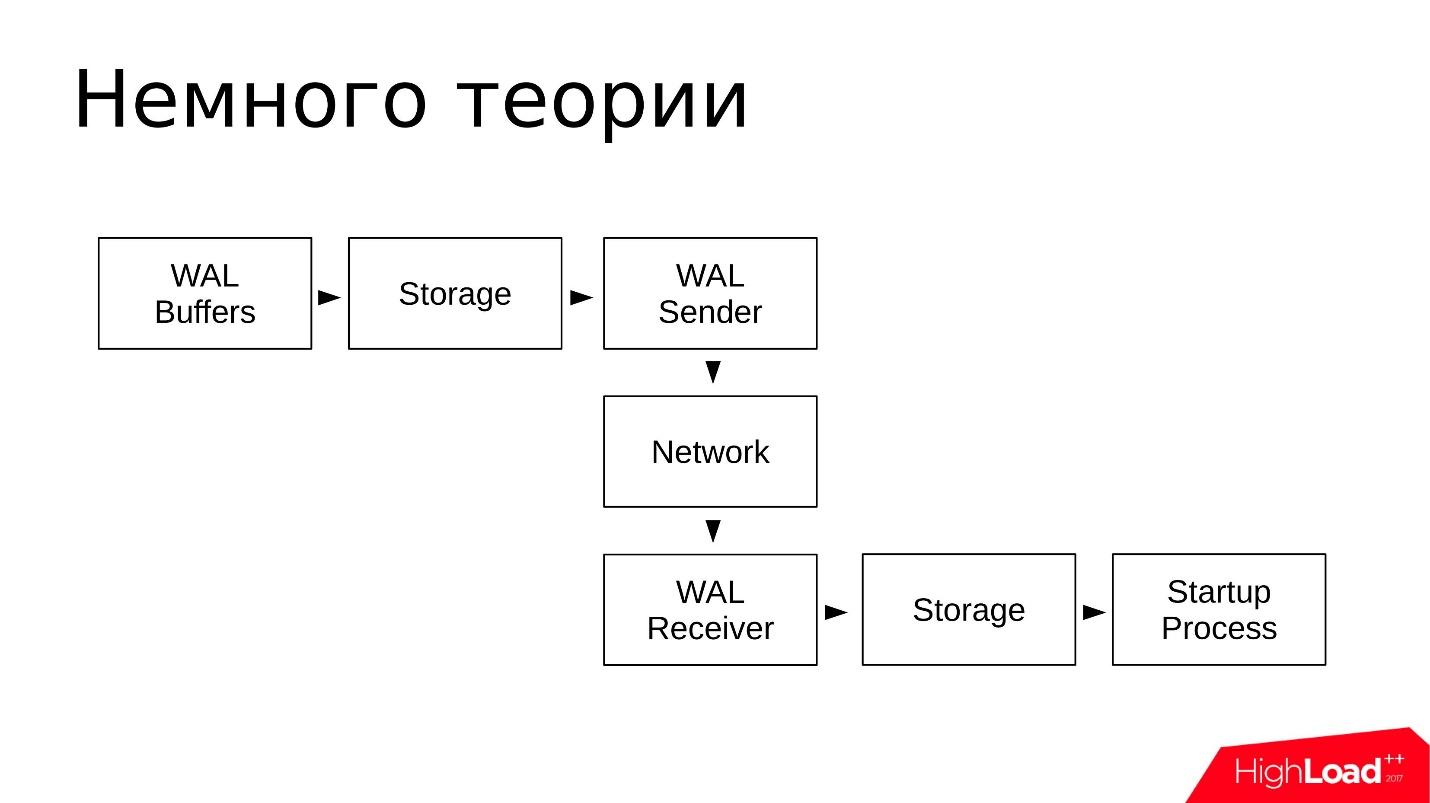
从示意图上看,它看起来像这样:
- 更改将写入WAL缓冲区,然后将其写入事务日志。
- 日志存储在pg_wal /目录中;
- WAL Sender从存储库中读取事务日志并通过网络传输它们;
- WAL接收器接收并存储在其存储中-本地pg_wal /;
- 启动过程读取被接受并复制的所有内容。
该方案很简单。 流复制工作非常可靠,并且已被广泛使用多年。
故障排除工具
让我们看看社区和PostgreSQL提供了哪些工具和实用程序,以调查流复制遇到的问题。
第三方工具
让我们从第三方工具开始。 这些实用程序具有相当
普遍的计划 ;它们不仅可以用于调查与流复制相关的事件。 这些通常
是任何系统管理员的实用程序 。
- procps软件包的顶部 。 作为top的替代,您可以使用任何实用程序,例如atop,htop等。 它们提供类似的功能。
在top的帮助下,我们看一下:处理器(CPU)的利用率,平均负载(平均负载)以及内存和交换空间的使用情况。
- sysstat和iotop中的iostat。 这些实用程序显示磁盘设备的利用率以及操作系统中的进程创建的I / O。
在iostat的帮助下,我们可以看到:存储利用率,当前多少iops,设备上的吞吐量,处理I / O请求的延迟时间(延迟)。 此相当详细的信息取自procfs文件系统,并以可视形式提供给用户。
- nicstat是iostat的类似物,仅适用于网络接口。 在此实用程序中,您可以观察接口的使用情况。
使用nicstat,我们看起来:接口利用率,接口上发生的一些错误,吞吐量也是一个非常有用的实用程序。
- pgCenter是仅适用于PostgreSQL的实用程序。 它在类似顶部的界面中显示PostgreSQL统计信息,您还可以在其中查看与流复制相关的统计信息。
在pgCenter的帮助下,我们可以看到:复制统计信息。 您可以观察复制滞后,以某种方式对其进行评估,并预测未来的工作。
- perf是一个实用程序,可用于更深入地调查“地下爆震”的原因,在运行时,PostgreSQL代码级会出现奇怪的问题。
在性能帮助下,我们寻找:地下敲门声。 为了使perf能够与PostgreSQL完全兼容,后者必须使用调试字符进行编译,因此您可以查看进程中的函数堆栈,以及哪些函数占用最多的CPU时间。
所有这些实用程序都需要用来
测试故障排除时出现的
假设 -放慢速度,放慢速度,需要修复和检查的地方和内容。 这些实用程序有助于确保我们走上正确的道路。
嵌入式工具
PostgreSQL本身提供什么?
系统视图
通常,有很多使用PostgreSQL的工具。 每个提供PostgreSQL支持的供应商公司都提供自己的工具。 但是,通常,这些工具是基于内部PostgreSQL统计信息的。 在这方面,PostgreSQL提供了系统视图,您可以在其中进行各种选择并获取所需的信息。 也就是说,使用常规客户端(通常为psql),我们可以进行查询并查看统计信息中发生了什么。
有很多系统视图。 为了处理流复制并调查问题,我们只需要:pg_stat_replication,pg_stat_wal_receiver,pg_stat_databases,pg_stat_databases_conflicts以及辅助pg_stat_activity和pg_stat_archiver。
它们很少,但是此设置足以检查是否有任何问题。
辅助功能
使用辅助功能,您可以从统计系统表示中获取数据,并将其转换为自己更方便的形式。 辅助功能也只有几部分。
- pg_current_wal_lsn()(pg_current_xlog_location()的旧版本)是最必需的功能,可让您查看事务日志中的当前位置。 事务日志是连续的数据序列。 使用此功能,您可以查看最后一点,获取现在停止事务日志的位置。
- pg_last_wal_receive_lsn(),pg_last_xlog_receive_location()与上述功能相似,仅适用于副本。 副本接收事务日志,您可以看到最后接收到的事务日志位置。
- pg_wal_lsn_diff(),pg_xlog_location_diff()是另一个有用的功能。 我们从事务日志中给她两个位置,然后显示diff-这两个点之间的距离(以字节为单位)。 此功能对于确定主副本与副本之间的延迟(以字节为单位)始终很有用。
可以使用psql元命令获得完整的功能列表:\ df *(wal | xlog | lsn | location)*。
您可以在psql中键入它,并查看wal,xlog,Isn和location包含的所有功能。 这样的功能大约有20-30个,它们还在交易日志上提供各种信息。 我建议您熟悉一下自己。
pg_waldump实用程序
在10.0版之前,它称为pg_xlogdump。 当我们想查看事务日志的各个部分,找出其中有哪些资源记录,以及PostgreSQL在那里写了什么时,需要pg_waldump实用程序,这是为了进行更详细的研究。
在10.0版中,所有包含单词xlog的系统视图,功能和实用程序都被重命名。 单词xlog和location的所有出现分别被单词wal和lsn代替。 pg_xlog目录也变成了pg_wal目录,做了同样的事情。
pg_waldump实用程序只是将XLOG段的内容解码为人类可读的格式。 您可以看到在PostgreSQL工作期间哪些所谓的资源记录落入了段日志中,哪些索引和堆文件已被更改,哪些备用信息将到达那里。 因此,可以使用pg_waldump查看很多信息。
但是官方文档中写有一个免责声明:PostgreSQL运行时pg_waldump可能显示稍微不正确的数据(服务器运行时可能给出错误的结果-意味着什么)
您可以使用以下命令:
pg_waldump -f - /wal_10 \ $(psql -qAtX - "select pg_walfile_name(pg_current_wal_lsn())")
这是tail -f命令的类似物,仅适用于事务日志。 此命令显示当前正在发生的事务日志的尾部。 您可以运行此命令,它将找到带有最新事务日志条目的最后一个段,连接到该段并开始显示事务日志的内容。 团队有些棘手,但是仍然有效。 我经常使用它。
故障排除案例
在这里,我们研究顾问的实践中出现的最常见问题,可能是什么症状以及如何诊断它们:
复制滞后是最常见的问题 。 最近,我们与客户建立了联系:
- 我们中断了两台服务器之间的主从复制。
-检测到2小时的延迟,pg_dump开始。
- 知道了 我们允许的延迟是多少?
-max_standby_streaming_delay为16小时。
-超过此延迟会发生什么? 警笛声?
-不,交易将被击败,WAL名单将恢复。
我们一直都有复制滞后的问题,几乎每个星期我们都会解决它们。
存储事务日志段
的pg_wal /目录的膨胀是一个不常发生的问题。 但是在这种情况下,必须立即采取措施,以使当副本掉落时问题不会变成紧急情况。
在副本上运行的
长查询会导致
恢复期间发生冲突 。 在这种情况下,当我们在副本上开始某种负载时,您可以在副本上执行读取查询,此时,这些查询会干扰事务日志的复制。 发生冲突,PostgreSQL需要决定是等待查询完成还是完成查询,然后继续播放事务日志。 这是复制冲突或恢复冲突。
恢复过程:100%的CPU使用率—在副本上恢复事务日志
的过程花费了100%的处理器时间。 这也是一种罕见的情况,但是非常不愉快,因为 导致复制滞后的增加,并且通常难以调查。
复制滞后
复制滞后是指在主服务器和副本服务器上执行的同一请求返回不同的数据时。 这意味着母版和副本之间的数据不一致,并且存在一些滞后。 副本需要重现部分事务日志,以便赶上向导。 主要症状看起来完全像这样:存在一个查询,并且它们返回不同的结果。
如何寻找这样的问题?- 在向导和副本pg_stat_replication上有一个基本视图。 它显示有关所有WAL Sender的信息,即有关发送事务日志的进程的信息。 每个副本都有单独的一行,显示该特定副本的统计信息。
- 辅助函数pg_wal_lsn_diff()允许您比较事务日志中的不同位置并计算相同的滞后。 有了它的帮助,我们可以获得特定的数字,并确定哪里存在较大的滞后,哪里存在较小的滞后,并且已经以某种方式对问题做出了响应。
- pg_last_xact_replay_timestamp()函数仅适用于副本,并允许您查看上次丢失事务的执行时间。 有一个众所周知的now()函数显示当前时间,我们从now()函数中减去pg_last_xact_replay_timestamp()函数显示给我们的时间,并获得时间滞后。
在pg_stat_replication的第10版中,出现了其他字段,显示了向导中已经存在的时间滞后,因此该方法已经过时,但是仍然可以使用。
有一个小陷阱。 如果向导上很长时间没有事务,并且它不生成事务日志,那么最后一个函数将显示出越来越大的延迟。 实际上,该系统只是闲置的,没有任何活动,但是在监视中,我们可以看到滞后现象正在加剧。 这个陷阱值得记住。
视图如下。

它包含有关每个WAL发送者的信息以及对我们很重要的几个字段。 这主要是
client_addr-连接的副本的网络地址(通常是IP地址)和一组
lsn字段(在旧版本中称为location),我将进一步讨论它们。
在第10版中,出现了
滞后字段-这是一种以时间表示的滞后,即一种更易于理解的格式。 延迟可以以字节或时间表示-您可以选择最喜欢的延迟。
通常,我使用此请求。

这不是pg_stat_replication以更方便易懂的格式打印的最复杂的查询。 在这里,我使用以下功能:
- pg_wal_lsn_diff()读取差异。 但是我认为差异之间是什么? 我们有几个字段-send_lsn,write_lsn,flush_lsn,replay_lsn。 通过计算当前字段与前一个字段之间的差异,我们可以准确地了解滞后的位置,确切的滞后发生的位置。
- pg_current_wal_lsn() ,它显示事务日志的当前位置。 在这里,我们查看了日志中当前位置与已发送位置之间的距离-生成但未发送多少个事务日志。
- sent_lsn , write_lsn-这是发送到副本但未记录的数量。 也就是说,它现在位于网络上的某个位置,或者已被副本接收,但尚未从网络缓冲区写入磁盘存储。
- write_lsn,flush_lsn-已写入,但不是由fsync命令发出-好像已写入,但可以位于操作系统页面缓存中RAM中的某个位置。 一旦执行fsync,数据就会与磁盘同步,进入持久性存储,一切似乎都是可靠的。
- replay_lsn,flush_lsn-数据已转储,已执行fsync,但未复制。
- current_wal_lsn和replay_lsn是一种包括所有先前位置的总滞后。
一些例子

副本10.6.6.8在上方突出显示。 她有一个
待处理的滞后 ,她生成了一些事务日志,但是它们仍然没有发送并且位于主数据库上。 最有可能的是,网络性能存在某种问题。 我们将使用nicstat实用程序对此进行验证。
如果那里有任何问题和错误,我们将启动nicstat,查看接口利用率。 因此我们可以检验这个假设。
 写入延迟
写入延迟标记在上方。 实际上,这种滞后非常罕见,我几乎看不到它会很大。 问题可能出在磁盘上,我们使用iostat或iotop实用程序-查看磁盘存储的利用率,该I / O由进程创建,然后找出原因。
 刷新并重放
刷新并重放延迟-延迟通常发生在副本计算机上的磁盘设备没有时间简单地丢失所有来自主服务器的更改时。
同样,使用iostat和iotop实用程序,我们将了解磁盘利用率的变化以及刹车的原因。
最后的
total_lag是监视系统的有用指标。 如果超过了阈值total_lag,则在监视中会出现一个复选框,我们将开始调查那里发生的情况。
假设检验
现在,您需要弄清楚如何进一步调查特定问题。 我已经说过,如果这是网络延迟,那么我们需要检查网络是否一切正常。
现在,几乎所有托管服务器都提供1 Gb / s甚至10 Gb / s,因此
带宽阻塞是最不可能发生的情况 。 通常,您需要查看错误。 nicstat包含有关接口错误的信息,您可以确定驱动程序存在问题,无论是网卡本身还是电缆。
我们使用iostat和iotop调查
存储问题 。 需要iostat来查看磁盘存储的一般情况:设备回收,设备带宽,延迟。 iotop-为了进行更精确的研究,当我们需要确定哪个进程正在加载磁盘子系统时。 如果这是某种第三方过程,则只需将其检测,完成,问题可能会消失。
首先,我们通过top或pg_stat_activity查看
恢复延迟和复制冲突 :正在运行的进程,正在运行的请求,其执行时间,运行时间。 如果这些查询很长,我们将研究为什么它们会长时间工作,进行射击,理解和
优化它们 -我们将自己检查查询。
如果这是向导生成的
大量事务日志 ,我们可以通过
pg_stat_activity来检测到它。 可能在那里开始了一些备份过程,已经开始进行某种清理(pg_stat_progress_vacuum),或者正在执行检查点。 也就是说,如果生成了太多的事务日志,而副本没有时间来处理它,则在某些时候它可能会掉下来,这对我们来说是个问题。
当然还有
pg_wal_lsn_diff()来确定延迟,并具体确定滞后在哪里-在网络,磁盘还是处理器上。
解决方案选项
网络/存储问题这里的一切都非常简单,但是从配置的角度来看,这通常无法解决。 您可以拧紧一些螺母,但通常有两种选择:
检查正在运行的请求。 也许启动了一些迁移,这些迁移会生成大量事务日志,或者它可以是数据传输,删除或插入。
任何生成事务日志的过程都可能导致事务滞后 。 向导中的所有数据都将尽快生成,我们对数据进行了更改,然后将其发送到副本,副本可以应付或失败-这与向导无关。 此处可能会出现滞后,您需要对此进行一些处理。
最愚蠢的选择-也许我们碰到了铁的性能,您只需要更改它。 它可以是旧磁盘或劣质SSD,也可以是RAID控制器性能的插件。 在这里,我们不再探索基础本身,而是检查腺体的性能。
恢复延迟如果由于长请求而导致任何类型的复制冲突,从而导致重放延迟增加,那么我们要做的
第一件事就是
拍摄在副本上运行的
长请求 ,因为它们会延迟事务日志的重放。
如果长查询与SQL查询本身的非最佳性有关(我们使用EXPLAIN ANALYZE可以找到此查询),则只需要以其他方式处理此查询并重写它即可。 或者,可以选择配置
单独的副本以报告查询 。 如果我们制作的报告可以长期使用,则需要将它们提交到单独的副本中。
仍然可以选择
等待 。 如果我们在几千字节甚至几十兆字节的水平上存在某种滞后,但是我们认为这是可以接受的,我们只是等待请求完成,并且滞后将自行解决。 这也是一种选择,它经常会被接受。
高音量WAL如果我们生成大量事务日志,则需要减少
每单位时间的事务日志
量 ,以使副本副本需要消耗更少的事务日志。
这通常是
通过配置完成的。 设置full_page_writes = off参数的部分解决方案。 此选项打开/关闭在事务日志中记录更改页面的完整图像。 这意味着,当我们执行写入检查点(CHECKPOINT)的服务操作时,下次我们更改共享缓冲区区域中的某些数据块时,此页面的完整映像将转到事务日志,而不仅仅是更改本身。 在同一页面上进行所有后续更改时,只有更改将记录在事务日志中。 依此类推,到达下一个检查点。
在检查点之后,我们记录页面的完整图像,这会影响记录的事务日志的数量。 如果每单位时间有很多检查点,那么说每小时要完成4个检查点,并且会有很多全页图像,这将是一个问题。 您可以禁用完整图像的录制,这将影响WAL的音量。 但这又是一半的措施。
注意:应该仔细考虑禁用full_page_writes的建议,因为作者在报告中忘记澄清说,在某些情况下,禁用参数可能在紧急情况下发生(损坏文件系统或其日志,部分写入块等)。可能损坏的数据库文件。 因此,请小心,禁用该参数可能会增加紧急情况下数据损坏的风险。另一半措施是
增加检查点之间的间隔 。 默认情况下,检查点每5分钟执行一次,这很常见。 通常,此间隔增加到30-60分钟-这是所有脏页都设法与磁盘同步的可接受时间。
但是,主要的解决方案当然是
查看我们的工作量 -正在进行什么样的繁重操作,这些操作与更改数据有关,并且也许尝试分批进行这些更改。
假设我们有一个表,我们想从中删除几百万条记录。 最好的选择不是一次请求就删除数百万个,而是将它们分成100-200,000个数据包,这样,首先,会生成少量的WAL;其次,真空有时间传递删除的数据,因此,延迟不是这样大而关键。
膨胀pg_wal /
现在,让我们谈谈如何发现pg_wal /目录已膨胀。
从理论上讲,PostgreSQL始终在某些配置文件级别上将其自身保持在最佳状态,通常,它不应超过某些限制。
有一个参数max_wal_size,它确定最大值。 另外还有wal_keep_segments参数-如果副本很长一段时间不可用,则主数据库为副本存储的额外段数。
计算了max_wal_size和wal_keep_segments的总和后,我们可以粗略估计pg_wal /目录将占用多少空间。 如果它迅速增长并且占用的空间比计算值大得多,这意味着存在一些问题,您需要对此进行一些处理。
如何发现此类问题?
在Linux操作系统上,有
du -csh命令 。 我们可以简单地监视值并监视那里有多少事务日志; 保持计算得出的标签,他欠多少钱,他实际赚多少钱,以及以某种方式应对数字变化。
我们要看的另一个地方是
pg_replication_slots和
pg_stat_archiver视图 。 pg_wal /占用大量空间的最常见原因是忘记了复制槽或损坏的归档。 其他原因也有待解决的地方,但在我的实践中,它们很少见。
而且,当然,与归档命令关联的PostgreSQL日志中总是存在错误。 不幸的是,没有其他原因与pg_wal /溢出有关。 我们只能在那里捕获存档错误。
问题选项:
重载CRUD-重载数据刷新操作-重载INSERT,DELETE,UPDATE,与更改几百万行相关。 如果PostgreSQL需要执行这样的操作,很明显将产生大量的事务日志。 它将存储在pg_wal /中,这将增加占用的空间。 就是说,再次如我之前所说,优良作法是将它们分成多个包,而不是更新整个数组,而是每个更新100、200、30万。
遗忘或未使用的复制插槽是另一个常见问题。 人们通常将逻辑复制用于某些任务:他们配置将数据发送到Kafka的总线,将数据发送到将逻辑复制解码为另一种格式并以某种方式处理它们的第三方应用程序。
逻辑复制通常通过插槽进行 。 碰巧我们设置了一个复制槽,与该应用程序一起使用,意识到该应用程序不适合我们,关闭了该应用程序,将其删除,
并且复制槽继续存在 。
每个复制插槽的PostgreSQL都会保存事务日志的段,以防远程应用程序或副本再次连接到该插槽,然后向导可以将这些事务日志发送给它们。
但是随着时间的流逝,没有人连接到插槽,事务日志被累积,并且在某些时候它们占据了90%的空间。 我们需要找出它是什么,为什么要占用这么多空间。 通常,只需删除此已遗忘和未使用的插槽,即可解决问题。 但是稍后会更多。
另一个选项可能是
损坏的archive_command 。 当我们为灾难恢复任务保留某种外部事务日志存储库时,通常会设置一个归档命令,而很少会设置pg_receivexlog。 在archive_command中注册的命令通常是单独的命令或某些脚本,这些脚本从pg_wal /中获取事务日志的各个部分并将其复制到归档存储中。
碰巧我们对系统软件包进行了某种升级,例如,在rsync中,版本已更改,标志已更新或已更改,或者在archive命令中使用的其他某些命令中,格式也已更改-以及在中指定的脚本或程序本身archive_command中断。 因此,归档文件不再被复制。
如果archive命令的输出不为0,则有关此消息的消息将被写入日志,该段将保留在pg_wal /目录中。
直到我们发现归档团队已经破产,分段才会累积起来 ,并且该地点也将在某个时刻结束。
一套应急措施(100%已用空间):1.
CRUD , — pg_terminate_backend().
- , , , .. , pg_wal/, .
2.
root — reserved space ratio (ext filesystems).
ext ext 5%. , , 5% — . , , 1% , tune2fs -m 1. PostgreSQL , . 100% .
3.
(LVM, ZFS,...).
LVM ZFS, LVM ZFS, , , . , .
4. —
, , HE pg_wal/ .
, , , . ! PostgreSQL , . , , , .
, pg_xlog/ pg_wal/ — log , , , , - — !
, 100% CPU, .
workload . , ? , - , -. : , tablespace, tablespace.
. , , , , , , .
— .checkpoints_segments/max_wal_size, wal_keep_segments . , , — 10-20 wal_keep_segments, max_wal_size. , . PostgreSQL pg_wal/ .
pg_replication_slots — . ,
, — . , , . .
WAL, ,
pg_stat_archiver , . ,
, , , .
checkpoint . , , . , PostgreSQL .
, checkpoint .
, , — . - , . , .
— PostgreSQL :
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
2 — , , . : , , . ( 30 ),
PostgreSQL — .
. , , . - , timeout . — ALTER, , .
. , tablespace , tablespace. , , - — .
?
pg_stat_databases, pg_stat_databases_conflicts . , . , .
,
. , . , . , , , .
?
, — :
- max_standby_streaming_delay ( ). , . .
- hot_stadby_feedback ( /). , vacuum - , . bloat . , , , hot_stadby_feedback .
- DBA — . , . , , , - , .
- , , , , DBA — , , . max_standby_streaming_delay . , . , , , . — , .
Recovery process: 100% CPU usage
, , ,
100% . , , 100%. , pg_stat_replication, , replay, , .
:
- top — — 100% CPU usage recovery process;
- pg_stat_replication — , , .
, . , :
- perf top/record/report ( debug—);
- GDB;
- pg_waldump.
, , . workload,
. , , PostgreSQL shared buffers ( ). .
,
. - workload, - , - : « , - ».
pgsql-hackers ,
pgsql-bugs , , . , .
—
- , , .
. , , , .
. , , , , , — .
,
, — . , , , .
, ,
— , , .
有用的链接
, Highload++ Siberia , 25 26 . , , .
- MySQL ClickHouse.
- , Oracle.
- 尼古拉·戈洛夫(Nikolay Golov)会告诉您,如果一项服务中有钱,另一项服务中有钱,并且每种服务都有自己独立的基础,则如何实施交易。
- 尤里Nasretdinov详细的解释,需要VK ClickHouse什么,有多少数据存储,等等。