本文将重点介绍一些搜索算法和特定图像点的描述。 在这里,这个话题已经
提出 ,而且
不止一次 。 我将认为读者已经熟悉了基本定义,我们将详细研究启发式算法FAST,FAST-9,FAST-ER,BRIEF,rBRIEF,ORB,并讨论作为其基础的闪闪发光的想法。 在某种程度上,这将是对几篇文章[1,2,3,4,5]的本质的免费翻译,其中会有一些“ try”的代码。

快速算法
FAST于2005年在[1]中首次提出,是最早的寻找奇异点的启发式方法之一,由于其计算效率高而受到欢迎。 为了决定是否将给定点C视为特殊点,此方法考虑了以点C和半径3为中心的圆上像素的亮度:

将圆形像素的亮度与中心C的亮度进行比较,对于每种像素,我们都会得到三种可能的结果(看起来更亮,更暗):
$内联$ \开始{array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $内联$
在此,I是像素的亮度,t是预定的亮度阈值。
如果一行中有n = 12个较暗的像素或12个比中心浅的像素,则该点被标记为特殊点。
实践证明,平均而言,要做出决定,有必要检查大约9点。 为了加快此过程,作者建议先检查仅四个带有数字的像素:1、5、9、13。如果其中三个像素较亮或更暗,则对16个点进行全面检查,否则,该点立即标记为“没什么特别的。” 这大大减少了工作时间,对于平均一个决定而言,仅轮询一个圆的大约4个点就足够了。
这里有些天真代码
可变参数(在代码中描述):圆半径(取值为1,2,3),参数n(原为n = 12),参数t。 代码打开in.bmp文件,处理图像,然后将其保存到out.bmp。 图片是普通的24位。
建立决策树,树FAST,FAST-9
在2006年的[2]中,有可能使用机器学习和决策树来发展一个原始思想。
原始的FAST具有以下缺点:
- 几个相邻的像素可以标记为特殊点。 我们需要某种程度的特征“强度”。 提出的首批措施之一是t的最大值,在该点处仍将t作为最大值。
- 对于n小于12的情况,不能进行快速的4点测试。因此,例如,在视觉上,如果n = 9,而不是12,则可以达到该方法的最佳结果。
- 我也想加快算法!
与其使用4点和16点的两个测试的级联,不建议一次通过决策树进行所有操作。 与原始方法类似,我们将比较中心点的亮度和圆上的点,但是以此顺序尽快做出决定。 事实证明,您平均只能做出2次(!!!)比较的决定。
最棘手的是如何找到比较点的正确顺序。 查找使用机器学习。 假设有人在图片中为我们指出了许多要点。 我们将它们用作一组训练示例,其想法是
急切地选择在此步骤中将提供最大信息量的一个作为下一个点。 例如,假设最初在我们的样本中有5个奇点和5个非奇点。 以这样的平板电脑形式:
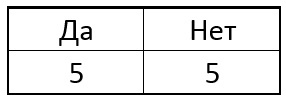
现在,我们选择圆的像素p之一,对于所有奇异点,我们将中心像素与所选像素进行比较。 根据每个特定点附近所选像素的亮度,该表可能会产生以下结果:
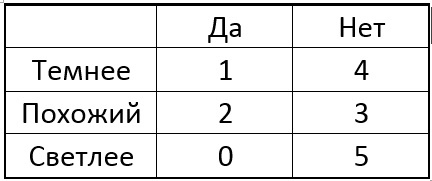
想法是选择一个点p,以使表的列中的数字尽可能不同。 如果现在对于一个新的未知点,我们得到的比较结果为“较亮”,那么我们可以马上说出该点为“不特殊”(见表)。 该过程递归地继续进行,直到分成“较暗的打火机”之后,只有一个类的点落入每个组。 结果是以下形式的树:
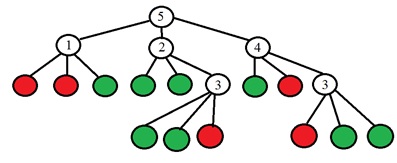
二进制值在树的叶子中(红色是特殊的,绿色不是特殊的),在树的其他顶点是需要分析的点的数量。 更具体地说,在原始文章中,他们建议通过改变熵来选择点数。 点集的熵计算如下:
$$ display $$ H = \左({c + \上划线c} \右){\ log _2} \左({c + \上划线c} \右)-c {\ log _2} c-\上划线c {\ log _2} \上划线c $$显示$$
c是奇异点的数量,
$ inline $ {\ bar c} $ inline $ 是集合中非奇点的数量
处理点p之后的熵变化:
$$显示$$ \ Delta H = H-{H_ {dark}}-{H_ {equal}}-{H_ {bright}} $$显示$$
因此,选择熵的变化最大的点。 当熵为零时,拆分过程停止,这意味着所有点都是奇异的,反之亦然-都不都是特殊的。 通过软件实现,所有这些操作之后,找到的决策树将转换为“ if-else”类型的一组构造。
该算法的最后一步是抑制非最大值以从几个相邻点获得一个的操作。 开发人员建议以这种形式的圆心与圆心之间的绝对差之和来使用原始度量:
$$ display $$ V = \ max \ left({\ sum \ limits_ {x \ in {S_ {bright}}}} {\ left | {{I_x}-{I_p}} \ right |-t,\ sum \ limit_ {x \ in {S_ {dark}}} {\左| {{I_p}-{I_x}} \右|-t}}} \右)$$显示$$
在这里
$ inline $ {S_ {bright}} $ inline $ 和
$ inline $ {S_ {dark}} $ inline $ 像素组分别更亮和更暗,t是阈值亮度值,
$ inline $ {I_p} $ inline $ -中央像素的亮度,
$ inline $ {{I_x}} $ inline $ -圆上像素的亮度。 您可以使用
以下代码尝试该算法。 该代码取自OpenCV,并摆脱了所有依赖关系,只需运行它即可。
优化决策树-FAST-ER
FAST-ER [3]是与前一作者相同的算法,类似地构造了一个快速检测器,还搜索了最佳点序列以进行比较,还建立了决策树,但是使用了不同的方法-优化方法。
我们已经知道,检测器可以表示为决策树。 如果我们有比较不同树木性能的标准,那么我们可以通过对树木的不同变体进行分类来最大化该标准。 并且作为这样的标准,建议使用“可重复性”。
重复性表明从不同角度检测场景的奇异点的能力。 对于一对图片,如果一个点在一个帧上找到并且理论上可以在另一帧上找到,则称为“有用”。 不要遮挡场景中的元素。 如果在第二帧中也发现该点,则称为“重复”(重复)。 由于相机光学元件不理想,因此第二帧上的点可能不在计算的像素中,而是在其附近的某个位置。 开发人员占据了5个像素的邻域。 我们将重复性定义为重复点数与有用点数之比:
$$显示$$ R = \ frac {{{N_ {repeated}}}} {{{N_ {useable}}}}} $$显示$$
为了找到最佳的检测器,使用了一种退火模拟方法。 关于哈布雷,已经有
一篇关于他的
出色文章 。 简而言之,该方法的实质如下:
- 选择了对该问题的一些初步解决方案(在我们的情况下,这是某种检测器树)。
- 考虑重复性。
- 该树是随机修改的。
- 如果修改后的版本以可重复性的标准为佳,则接受该修改,如果更糟,则该修改是否可以被接受还是不能接受,这取决于称为“温度”的实数。 随着迭代次数的增加,温度下降到零。
此外,探测器的构造现在不像以前那样涉及圆的16个点,而是涉及47个,但是含义完全没有改变:

根据模拟退火方法,我们定义了三个函数:
•成本函数k。 在我们的案例中,我们将可重复性作为价值。 但是有一个问题。 想象一下,将两个图像中的每个点都检测为奇异点。 事实证明,重复性是100%-荒谬。 另一方面,即使我们在两张图片中找到了一个特定的点,并且这些点重合-重复性也是100%,但这对我们也不感兴趣。 因此,作者建议将此作为质量标准:
$$ display $$ k = \左({1 + {{\左({\ frac {{{w_r}}} {R}} \右)} ^ 2}} \右)\左({1 + \ frac {1} {N} \ sum \ limits_ {i = 1} {{{\左({\ frac {{{{d_i}}} {{{w_n}}}}右)} ^ 2}}} \右)\左({1 + {{\左({\ frac {s} {{{w_s}}}}右)} ^ 2}} \右)$$显示$$
r是重复性
$ inline $ {{d_i}} $ inline $ 是在第i帧上检测到的角度数,N是帧数,s是树的大小(顶点数)。 W是自定义方法参数。]
•温度随时间变化的功能:
$$显示$$ T \左(I \右)= \ beta \ exp \左({-\ frac {{\ alpha I}} {{{I _ {\ max}}}} \右)$$显示$$
在哪里
$ inline $ \ alpha,\ beta $ inline $ 是系数,Imax是迭代次数。
•生成新解决方案的功能。 该算法对树进行随机修改。 首先,选择一些顶点。 如果选定的顶点是树的叶子,则我们以相同的概率执行以下操作:
- 用深度为1的随机子树替换顶点
- 更改此工作表的类别(单数-非奇数点)
如果这不是一张纸:
- 将测试点的编号替换为0到47之间的随机数
- 用具有随机类的图纸替换顶点
- 从该顶点交换两个子树
在迭代I处接受更改的概率P为:
$ inline $ P = \ exp \ left({\ frac {{k \ left({i-1} \ right)-k \ left(i \ right)}} {T}} \ right)$ inline $
k是成本函数,T是温度,i是迭代次数。
对树的这些修改允许树的生长及其减少。 该方法是随机的,它不能保证将获得最佳树。 多次运行该方法,选择最佳解决方案。 例如,在原始文章中,它们每100,000次迭代运行100次,这需要200个小时的处理器时间。 结果表明,该结果比Tree FAST更好,特别是在嘈杂的图片中。
简要描述符
找到奇异点后,计算它们的描述符,即 表征每个奇异点邻域的一组特征。 简述[4]是一种快速启发式描述符,它是根据
模糊图像中像素亮度之间的256个二进制比较建立的。 x和y点之间的二进制测试定义如下:
$$显示$$ \ tau \左({P,x,y} \右):= \左\ {{\开始{array} {* {20} {c}} {1:p \左(x \ right)<p \ left(y \ right)} \\ {0:p \ left(x \ right)\ ge p \ left(y \ right)} \ end {array}} \ right。$$显示$$

在原始文章中,考虑了几种选择点进行二进制比较的方法。 事实证明,最好的方法之一是使用围绕中心像素的高斯分布随机选择点。 这个随机的点序列被选择一次,并且不会进一步改变。 点的考虑邻域的大小为31x31像素,模糊光圈为5。
生成的二进制描述符可以抵抗光照的变化,透视失真,可以快速进行计算和比较,但对于图像平面中的旋转非常不稳定。
ORB-快速高效
所有这些想法的发展是ORB(定向的FAST和旋转的Brief摘要)算法[5],其中尝试改善图像旋转过程中的Brief摘要性能。 建议首先计算奇异点的方向,然后根据该方向进行二进制比较。 该算法的工作原理如下:
1)通过使用快速FAST树在原始图像和缩略图金字塔的多个图像中检测特征点。
2)对于检测到的点,计算哈里斯量度,丢弃具有低哈里斯量度的候选值。
3)计算出奇异点的取向角。 为此,首先计算奇点附近的亮度矩:
$ inline $ {m_ {pq}} = \ sum \ limits_ {x,y} {{x ^ p} {y ^ q} I \ left({x,y} \ right)} $ inline $
x,y-像素坐标,I-亮度。 然后是奇点的定向角:
$ inline $ \ theta = {\ rm {atan2}} \左({{m_ {01}},{m_ {10}}} \右)$ inline $
所有这些,作者称之为“质心取向”。 结果,我们获得了奇点附近的确定方向。
4)具有奇异点的方向角,在BRIEF描述符中用于二进制比较的点序列根据该角度旋转,例如:
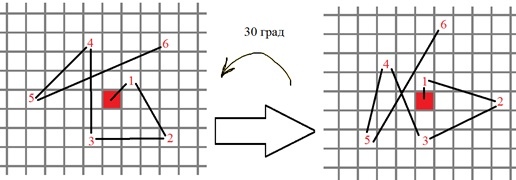
更正式地说,二进制测试点的新位置计算如下:
$$ display $$ \ left({\ begin {array} {* {20} {c}} {{x_i}'} \\ {{y_i}'} \ end {array}} \ right} = R \ left (\ theta \ right)\ cdot \ left({\开始{array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ right} $$显示$$
5)基于接收到的点,计算BRIEF二进制描述符
而且...还不是全部! ORB中还有另一个有趣的细节,需要单独解释。 事实是,当我们将所有奇异点“旋转”到零角度时,描述符中二进制比较的随机选择不再是随机的。 这导致一个事实,首先,一些二进制比较结果相互依赖,其次,它们的平均值不再等于0.5(在随机选择时,1较亮,0较暗,然后平均值为0.5),并且所有这些都大大降低了描述符在彼此之间区分奇异点的能力。
解决方案-您需要在学习过程中选择“正确的”二进制测试,这种想法与FAST-9算法的树训练具有相同的风格。 假设我们已经找到了一堆奇异点。 考虑二进制测试的所有可能选项。 如果邻域为31 x 31,并且二进制测试是一对5 x 5子集(由于模糊),那么有很多选择N =(31-5)^ 2的选项。 “好”测试的搜索算法如下:
- 我们计算所有奇异点的所有测试结果
- 根据它们与平均值0.5的距离排列整套测试
- 创建一个包含所选“良好”测试的列表,我们将其称为列表R。
- 将排序集中的第一个测试添加到R中
- 我们接受下一个测试,并将其与R中的所有测试进行比较。如果相关性大于阈值,则我们丢弃新测试,否则将其添加。
- 重复步骤5,直到输入所需的测试数量。
事实证明,选择测试的目的是,一方面,这些测试的平均值尽可能接近0.5;另一方面,不同测试之间的相关性也很小。 这就是我们所需要的。 比较它的状态和变成方式:
幸运的是,ORB算法在cv :: ORB类的OpenCV库中实现。 我正在使用2.4.13版本。 类构造函数接受以下参数:
nfeatures-最大奇异点数
scaleFactor-图像金字塔的乘数,不止一个。 值2实现了经典金字塔。
nlevels-图片金字塔中的级别数。
edgeThreshold-未检测到奇点的图像边界处的像素数。
firstLevel-保留零。
WTA_K-描述符的一个元素所需的点数。 如果等于2,则比较两个随机选择的像素的亮度。 这是需要的。
scoreType-如果为0,则将harris用作特征量度,否则-FAST量度(基于圆点上亮度差异的模和之和)。 FAST度量的稳定性略差,但速度更快。
patchSize-从中选择随机像素进行比较的邻域的大小。 该代码搜索并比较两张图片“ templ.bmp”和“ img.bmp”中的奇异点
代号cv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
如果有人帮助理解了算法的本质,那么它就不会白费。 对所有哈伯。
参考文献:
1.
融合点和线进行高性能跟踪2.
机器学习,用于高速角点检测3.
更快,更好:拐角检测的机器学习方法4.简介
:二进制健壮的独立基本特征5.
ORB:SIFT或SURF的有效替代品