在阅读了“
Google神经机器翻译 ”一文之后,我回顾了最近在互联网上运行的Google提供的最新的史诗失败机器翻译。 迫不及待的人,我们立即进入文章底部。
好吧,对于初学者来说,有一点理论:
GNMT是Google的神经机器翻译(
NMT )系统,它使用神经网络(
ANN )来提高翻译的准确性和速度,尤其是为Google Translate中的文本创建更好,更自然的翻译选项。
在GNMT的情况下,这就是所谓的基于示例的翻译方法(
EBMT ),即
该方法所
基于的ANN可从数百万个翻译示例中学习,并且与其他系统不同,该方法允许进行所谓的“
零镜头翻译” ,即从一种语言翻译为另一种语言而无需针对这对特定语言的显式示例在学习过程中(在训练样本中)。
 图 1.零射翻译
图 1.零射翻译此外,GNMT的主要目的是改善短语和句子的翻译,因为 仅在上下文翻译中,您不能使用翻译的原义版本,并且句子的翻译通常完全不同。
此外,返回零射翻译,Google试图突出显示一次可同时适用于多种语言的通用组件(在查找依赖项以及为句子和短语建立关系时)。
例如,在图2中,在日语,韩语和英语的所有可能对中显示了这种语言间的“社区”。
 图 2.国际语。 日语,韩语和英语的3维网络数据表示
图 2.国际语。 日语,韩语和英语的3维网络数据表示 。
(a)部分显示了此类翻译的一般“几何形状”,其中这些点按含义进行了着色(在几对语言中,相同的颜色用于相同的含义)。
(b)部分显示了其中一组的增加,而©部分则保留了原始语言的颜色。
GNMT使用大型的
ANN深度学习(
DNN ),该技术从数百万个示例中学习,应使用最合适的翻译选项使用上下文抽象近似来提高翻译质量。 粗略地讲,他在人类语言最合适的语法意义上选择了最好的结果,同时考虑到构建几种语言的链接,短语和句子的通用性(即分别突出显示和教授语言模型或语言层)。
但是,无论是在学习过程中还是在工作过程中,DNN通常都依赖于统计(概率)推断,并且很少受其他非概率算法的束缚。 即 为了评估从变速器产生的最佳结果,将选择统计上最佳(可能)的选项。
当然,所有这些都取决于训练样本的质量(和/或在自学习模型的情况下,算法的质量)。
考虑到零镜头翻译方法并记住某种国际语言成分,在一种语言存在某种肯定的逻辑深层连接,而其他语言则没有否定成分的情况下,学习过程中出现了一些抽象错误,因此,某一种语言对一种语言的翻译极有可能在其他语言甚至语言对中重复进行。
实际上是史诗般的失败
所有图像都是可单击的(作为相应Google Translate页面的证明)。德语: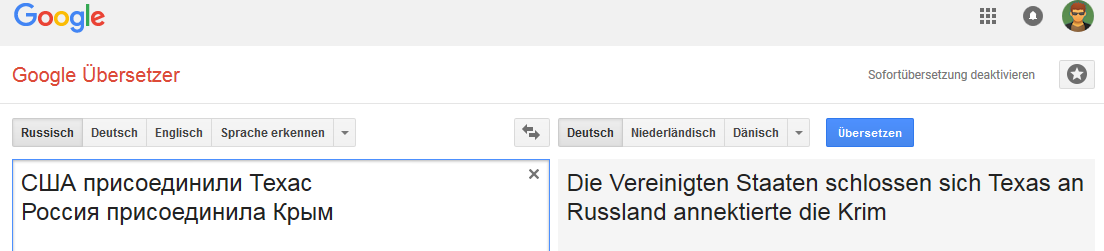 英文:
英文: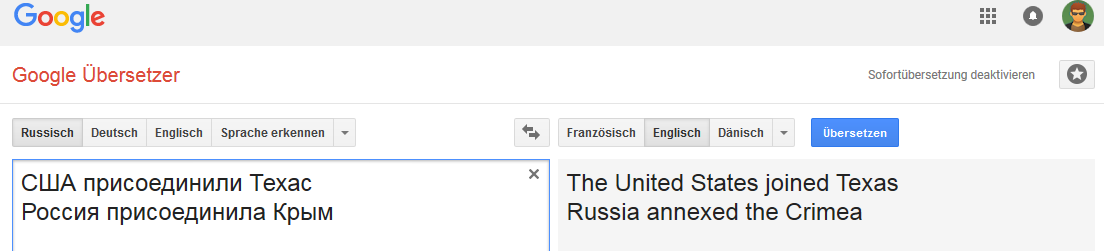 荷兰语:
荷兰语: 丹麦文:
丹麦文: 法语:
法语:
等等
而不是结论
对于俄罗斯一词,连接是稳定的(在某种意义上,例如当俄罗斯被俄罗斯帝国取代时,“转移”选项会发生变化)。
而且,某些短语的更改不是很稳定,这在翻译成英语时并不常见,但在俄语,德语和荷兰语中很常见。
不幸的是,这并不是唯一的例子,互联网上充斥着各种Google翻译错误。
在我看来,现有错误的相当一部分是由于多种因素的组合而表现出来的,从训练样本的质量到特定语言(尤其是学习模型)的语义和形态分析算法的质量,不等。
有一次,一位同事建议在kaggle上参加Google文本规范化挑战赛(俄语和英语)...
在达成协议之前,我对两种语言的所有代币的培训测试样本的质量进行了小幅分析……结果,我完全拒绝参加,因为我挖的越多,对比赛就像是彩票或中奖者的感觉就越强烈最准确地将能够重现在半手动创建Google培训集时所犯的所有错误。
我什至想写一篇关于“如何轻松抛出50K ...”的文章,但是时间-没关系。
如果有人突然有兴趣-我会尝试一下。
[UPD]为什么这实际上是一个文件。 不受歌词,“政治”潜台词和各种试图证明“一个人会以这种方式翻译”等主题的尝试所吸引。
1.这是错误的翻译。 重点。
2.在这种说明性的情况下,GNMT显示完全没有任何分类模型(就
CADM而言 ,谷歌必须大放异彩,因为它们来自世界各地的大量数据)。 就这两种情况下的主题是国家/州而言,补充语是地理实体(地区)。
即使是某些模糊K-nn分类的最愚蠢的合理性规则也永远不会犯这样的错误。 我们已经对用于(语义)关系的分类和构造的现代算法保持沉默。
俗话说,没有什么简单的数学运算法则……好吧,如果Google确实不加选择地决定将小报刊物的剪报提供给他的网络,那么我对他来说是个坏消息。
PS但是,正如我尊敬的一位教授曾经对我说的那样:“有时候很难证明啄木鸟是啄木鸟,尤其是在他确定自己比教授聪明的情况下。”