在明斯克举行的数据节2上,Lyft的机器视觉工程师Vladimir Iglovikov
完美地指出,学习数据科学的最佳方法是参加比赛,运行其他人的解决方案,将它们结合起来,取得成果并展示您的工作。 实际上,在这种范例的框架内,我决定更仔细地研究房屋信贷信用风险评估
竞赛 ,并向初学者,科学家以及首先向我自己解释如何正确地分析此类数据集并为其建立模型。
(图片
来自这里 )

住房信贷集团是由银行和非银行信贷组织组成的组织,在11个国家/地区开展业务(包括俄罗斯的住房信贷和金融银行有限责任公司)。 竞争的目的是创建一种方法来评估没有信用记录的借款人的信用度。 这看起来相当高尚-此类借款人通常无法从银行获得任何信贷,因此不得不转向骗子和小额贷款。 有趣的是,客户无需为模型的透明性和可解释性设置要求(就像银行通常这样),您可以使用任何东西,甚至可以使用神经网络。
训练样本包含300+千条记录,有很多符号-122,其中有很多分类(非数字)符号。 标志充分详细地描述了借款人,直至描述房屋墙壁的材料。 数据的一部分包含在6个附加表中(有关信贷局,信用卡余额和以前的贷款的数据),这些数据也必须以某种方式进行处理并加载到主要数据表中。
竞赛看起来像是一个标准的分类任务(TARGET字段中的1表示付款有困难,0表示没有困难)。 但是,不是0/1应该被预测,而是问题的概率(顺便说一句,可以通过所有复杂模型具有的predict_proba概率预测方法轻松解决)。
乍一看,数据集是机器学习任务的相当标准,组织者提供了7万美元的巨额奖金,结果,如今已有2600支队伍参加了比赛,而这场战斗的百分率是百分之一。 但是,另一方面,这种流行意味着要对数据集进行上下研究,并使用良好的EDA(探索性数据Analisys-研究和分析网络中的数据,包括图形化),特征工程(使用属性)来创建许多内核。并带有有趣的模型。 (内核是使用数据集的示例,任何人都可以布局该数据集以向其他杂耍演员展示其工作。)
内核值得关注:
为了处理数据,通常建议您遵循以下计划。
- 了解问题并熟悉数据
- 数据清理和格式化
- EDA
- 基本型号
- 模型改进
- 模型解释
在这种情况下,您需要考虑以下事实:数据相当广泛,并且不能立即进行过载,因此有必要分阶段进行操作。
让我们从导入分析中需要的库开始,以表的形式使用数据,构建图形并使用矩阵。
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
下载数据。 让我们看看我们都有什么。 顺便说一下,“ ../ input /”目录中的此位置与将内核放置在Kaggle上的要求有关。
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']有8个数据表(不包括包含字段说明的表HomeCredit_columns_description.csv),这些数据表的相互连接如下:
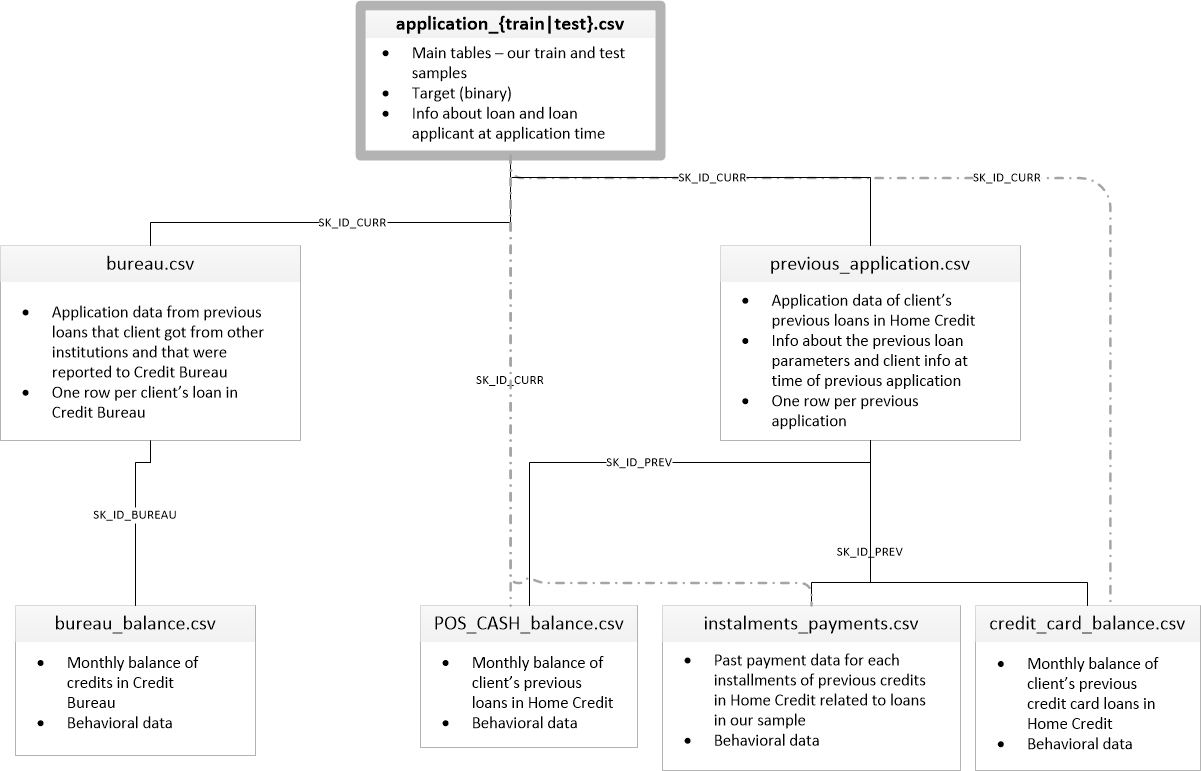
application_train / application_test:主数据,借方由字段SK_ID_CURR标识
局:有关征信局其他信贷机构以前的贷款数据
Bureau_balance:以前的局贷的月度数据。 每行是使用贷款的月份
previous_application:房屋信贷中的先前贷款申请,每个申请都有一个唯一字段SK_ID_PREV
POS_CASH_BALANCE:房屋信贷中的每月数据,以及发放现金和用于购买商品的贷款
credit_card_balance:房屋信贷中的每月信用卡余额数据
分期付款:在Home Credit上以前的贷款的付款历史。
让我们首先关注主数据源,看看可以从中提取哪些信息以及要构建哪些模型。 下载基本数据。
- app_train = pd.read_csv(PATH +'application_train.csv',)
- app_test = pd.read_csv(PATH +'application_test.csv',)
- 打印(“训练集格式:”,app_train.shape)
- 打印(“测试样本格式:”,app_test.shape)
- 训练样本格式:(307511,122)
- 测试样本格式:(48744,121)
总共,训练样本中有30.7万条记录和122个标志,测试中有4.9万条记录和121个标志。 差异显然是由于测试样本中没有目标属性TARGET,我们将对其进行预测。
让我们仔细看看数据
pd.set_option('display.max_columns', None)
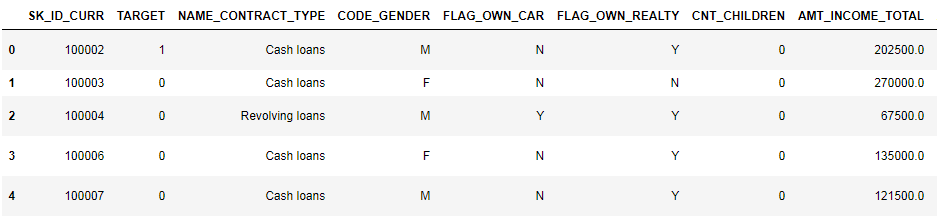
(显示前8列)
观看这种格式的数据非常困难。 让我们看一下列列表:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MB调用HomeCredit_columns_description文件中按字段的详细注释。 从信息中可以看到,部分数据不完整,部分是分类的,它们显示为对象。 大多数模型不适用于此类数据,我们将不得不对其进行处理。 至此,初步分析可以认为已经完成,我们将直接去EDA
探索性数据分析或主要数据挖掘
在EDA流程中,我们计算基本统计数据并绘制图表以查找数据中的趋势,异常,模式和关系。 EDA的目标是找出数据可以说明的内容。 通常,分析是从上到下进行的-从总体概述到吸引关注并可能引起关注的各个区域的研究。 随后,这些发现可用于模型的构建,特征的选择及其解释。
目标变量分布
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
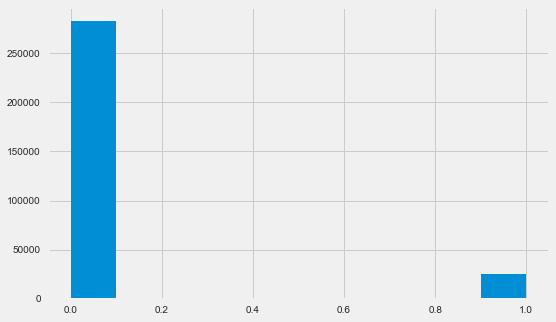
让我提醒您,1表示有回报的任何问题,0表示没有问题。 如您所见,主要是借款人的还款没有问题,有问题的份额约为8%。 这意味着类别不平衡,并且在构建模型时可能需要考虑这一点。
缺少数据研究
我们已经看到,缺乏数据是相当可观的。 让我们更详细地了解丢失的地方和内容。
122 .
67 .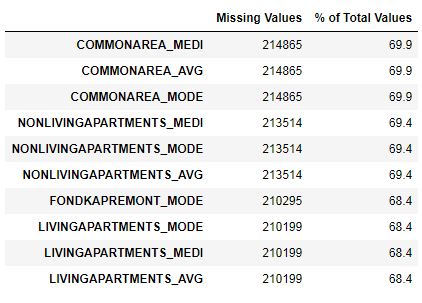
图形格式:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
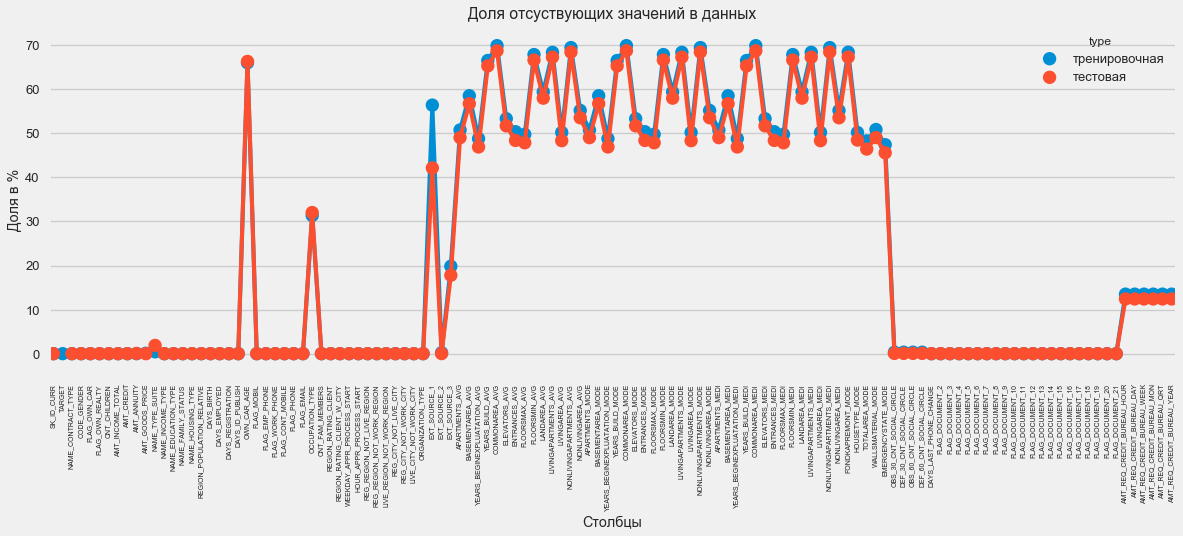
这个问题有很多答案。 您可以用零填充它,可以使用中间值,也可以删除没有必要信息的行。 这完全取决于我们计划使用的模型,因为其中一些模型可以完美地应对缺失的值。 虽然我们记住了这个事实,并保留了所有内容。
列类型和分类编码
我们记得。 列的一部分是对象类型,即它没有数字值,但反映了某些类别。 让我们更仔细地查看这些列。
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64我们有16列,每列有2到58个不同的值选项。 通常,机器学习模型无法对此类列执行任何操作(某些列除外,例如LightGBM或CatBoost)。 由于我们计划在数据集上尝试不同的模型,因此需要采取一些措施。 基本上有两种方法:
- 标签编码-为类别分配数字0、1、2等,并在同一列中写入
- 一键编码-根据选项的数量将一列分解为几列,这些列指示该记录具有的选项。
在流行的方法中,值得注意的
是平均目标编码 (感谢澄清的
roroorangepant )。
标签编码存在一个小问题-它分配与现实无关的数值。 例如,如果我们处理一个数值,那么借款人的100,000的收入肯定比20,000的收入更大,更好。但是,可以说,例如,一个城市比另一个城市更好,因为一个城市被赋值为100,另一个城市被赋值为200。 ?
另一方面,单热编码更安全,但可以产生“额外”列。 例如,如果我们使用One-Hot编码相同的性别,则将获得两列,“男性性别”和“女性性别”,尽管只要一列就足够了,“是男性”。
对于一个好的数据集,有必要使用Label Encoding以及其他所有方法(低热编码)对可变性低的符号进行编码,但为简单起见,我们根据One-Hot对所有数据进行编码。 实际上,它不会影响计算速度和结果。 熊猫编码过程本身非常简单。
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)由于选择列中的选项数不相等,因此列数现在不匹配。 需要对齐-您需要从训练集中删除不在测试集中的列。 这使得使用align方法时,您需要指定axis = 1(对于列)。
: (307511, 242)
: (48744, 242)数据关联
理解数据的一种好方法是计算相对于目标属性的数据的Pearson相关系数。 这不是显示功能相关性的最佳方法,但是它很简单,可以让您了解数据。 系数可以解释如下:
- 00-.19“非常弱”
- 20-.39“弱”
- 40-.59“平均”
- 60-.79强
- 80-1.0“非常强大”
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64因此,所有数据与目标之间的关联都很弱(目标本身除外,当然目标本身也相同)。 但是,年龄和某些“外部数据源”与数据有所区别。 这可能是来自其他信贷组织的一些其他数据。 有趣的是,尽管在制定信用决策时将目标声明为与此类数据无关,但实际上我们将主要基于这些数据。
年龄
显然,客户年龄越大,退货的可能性就越大(当然,达到一定的限制)。 但是出于某种原因,年龄是在发放贷款之前的负数天显示的,因此,它与未还款(这有点奇怪)呈正相关。 我们将其设为正值,并查看相关性。
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088让我们仔细看一下变量。 让我们从直方图开始。
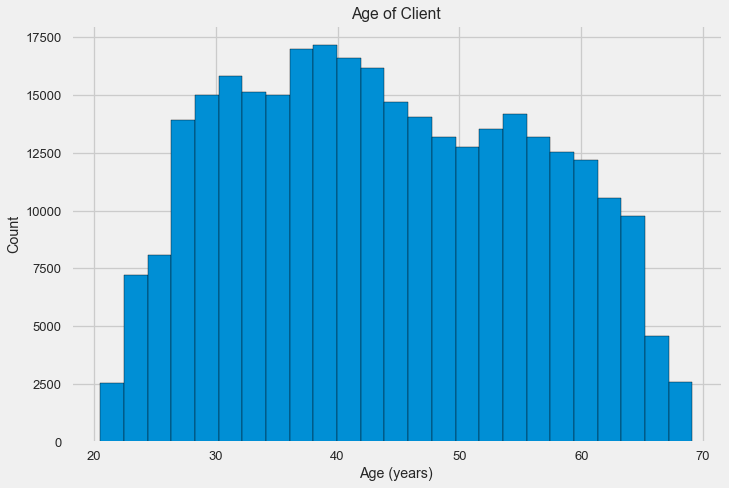
分布直方图本身可能会有点有用,除了我们看不到任何特殊的异常值,并且一切看起来或多或少令人信服。 为了显示年龄的影响对结果的影响,我们可以构建一个用目标属性颜色绘制的核密度估计(KDE)图-核密度分布。 它显示了一个变量的分布,可以解释为平滑的直方图(计算为每个点的高斯核,然后取平均值进行平滑)。
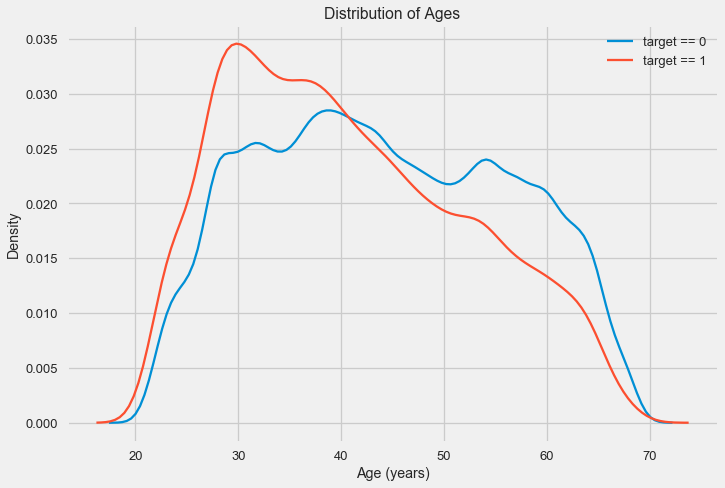
可以看出,年轻人的违约率更高,并且随着年龄的增长而降低。 这不是永远拒绝年轻人贷款的理由,这样的“建议”只会导致银行收入和市场损失。 这是一个考虑对此类贷款,评估以及可能的甚至对年轻借款人进行某种金融教育进行更彻底监控的机会。
外部资源
让我们仔细看看“外部数据源” EXT_SOURCE及其相关性。
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
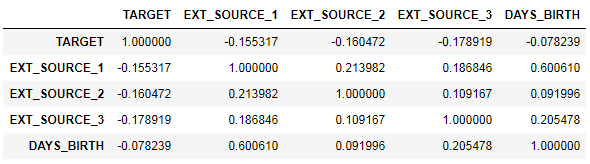
使用热图显示关联也很方便
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
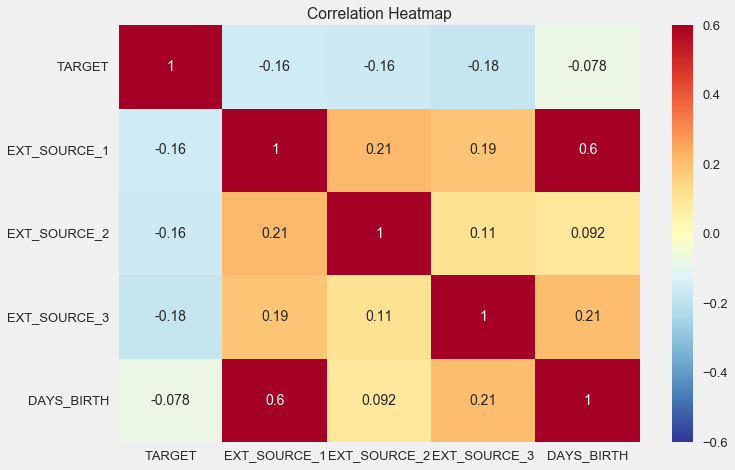
如您所见,所有源均与目标显示负相关。 让我们看一下每个源的KDE分布。
plt.figure(figsize = (10, 12))
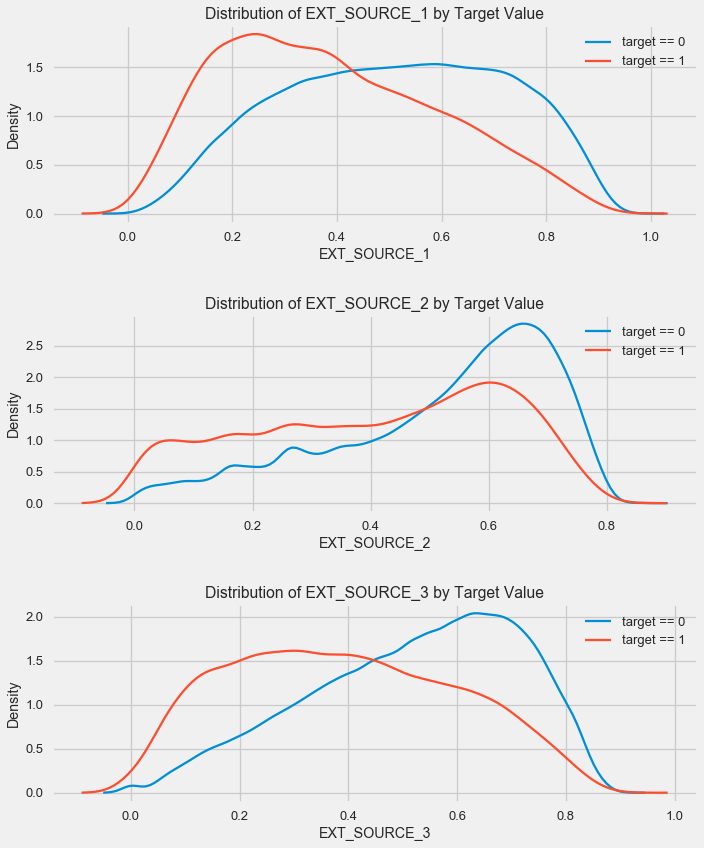
该图类似于按年龄分布-随着指标的增加,还贷的可能性增加。 在这方面,第三个来源是最强大的。 尽管从绝对意义上讲,与目标变量的相关性仍处于“非常低”的类别,但是在构建模型时,外部数据源和年龄将是最重要的。
配对时间表
为了更好地理解这些变量之间的关系,您可以构建一个对图,在其中我们可以看到每个对的关系以及沿对角线分布的直方图。 在对角线上方,可以显示散点图,在下方-2d KDE。
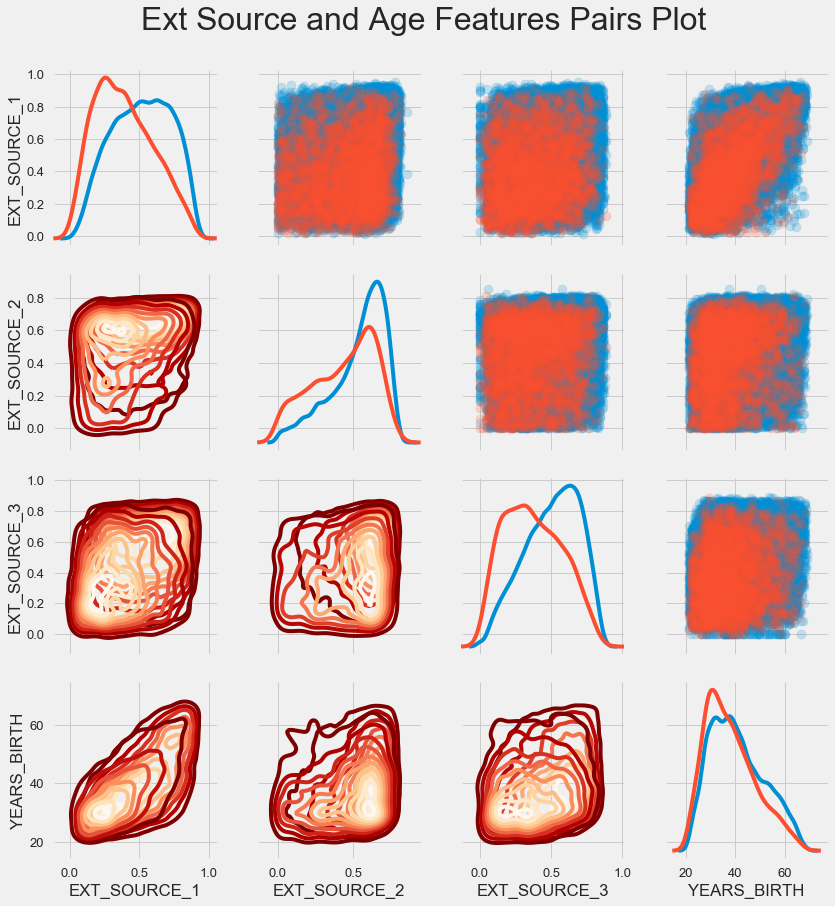
可偿还贷款显示为蓝色,不可偿还显示为红色。 要解释所有这些都是相当困难的,但是从这幅画中可以在T恤上或现代艺术博物馆中的一幅画上得到很好的印刷。
检查其他体征
让我们更详细地考虑其他功能及其对目标变量的依赖性。 由于有很多分类数据(并且我们已经设法对其进行编码),因此我们再次需要初始数据。 为了避免混淆,我们给它们起一些不同的称呼
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
我们还需要几个函数来精美地显示分布及其对目标变量的影响。 非常感谢他们为这个
内核的
作者 def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
因此,我们将考虑客户的主要迹象
贷款种类
plot_stats('NAME_CONTRACT_TYPE')
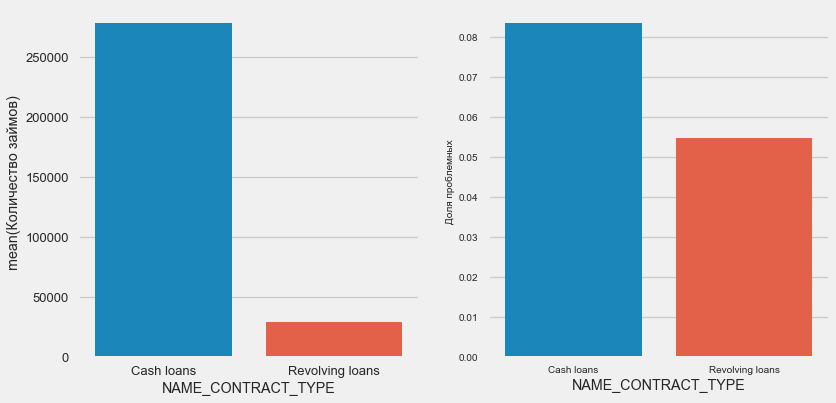
有趣的是,循环贷款(可能是透支之类的东西)占贷款总数的不到10%。 同时,它们之间的不归还比例要高得多。 修改甚至不再使用这些贷款的方法的一个很好的理由。
客户性别
plot_stats('CODE_GENDER')
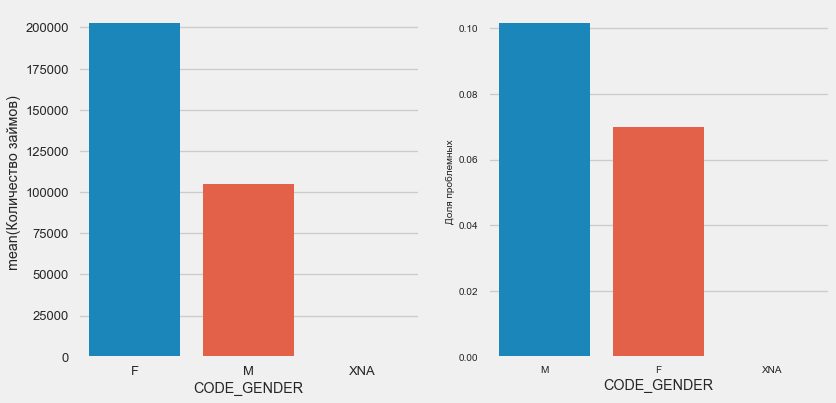
女性客户几乎是男性的两倍,而男性的风险更高。
汽车和财产所有权
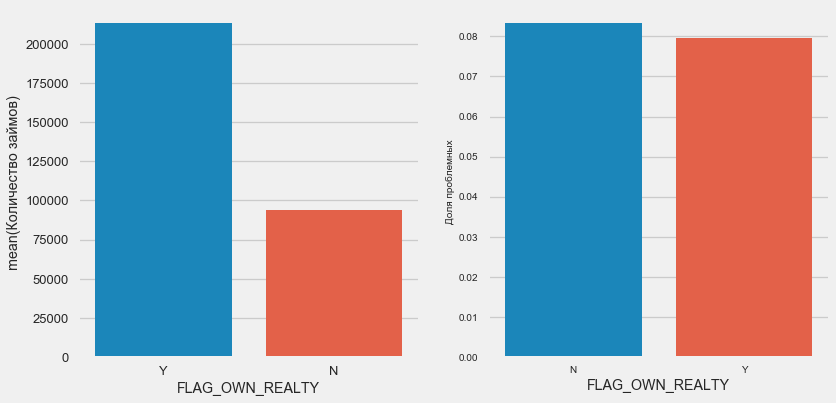
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
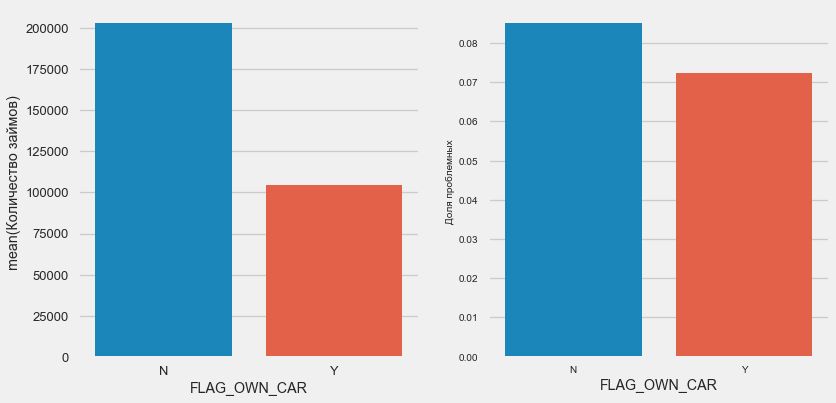
拥有汽车的客户只有“无马”的一半。 风险几乎相同,使用机器的客户支付的费用要好一些。
对于房地产而言,情况恰恰相反-没有房地产的客户就少一半。 财产所有者的风险也略低。
婚姻状况
plot_stats('NAME_FAMILY_STATUS',True, True)
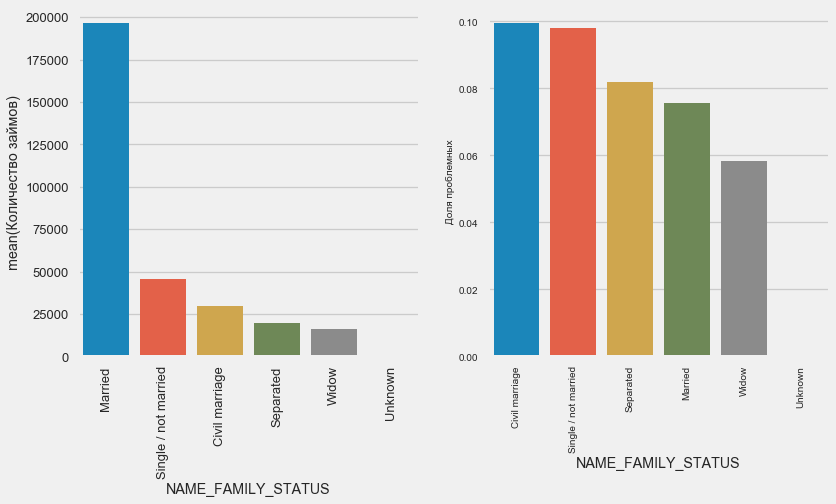
当大多数客户结婚时,风险最大的是民事客户和单身客户。 d夫病风险最小。
儿童人数
plot_stats('CNT_CHILDREN')
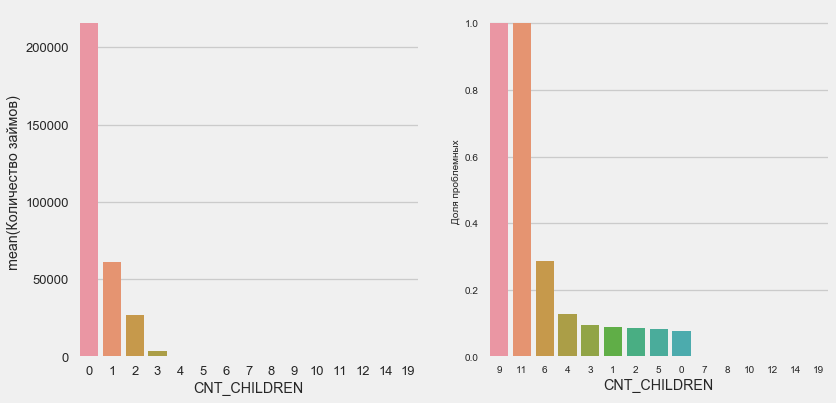
大多数客户没有孩子。 同时,有9个孩子和11个孩子的客户完全无法退款
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64如值的计算所示,此数据在统计上微不足道-两个类别中只有1-2个客户端。 但是,这三者都违约了,一半有六个孩子的客户也违约了。
家庭成员人数
plot_stats('CNT_FAM_MEMBERS',True)
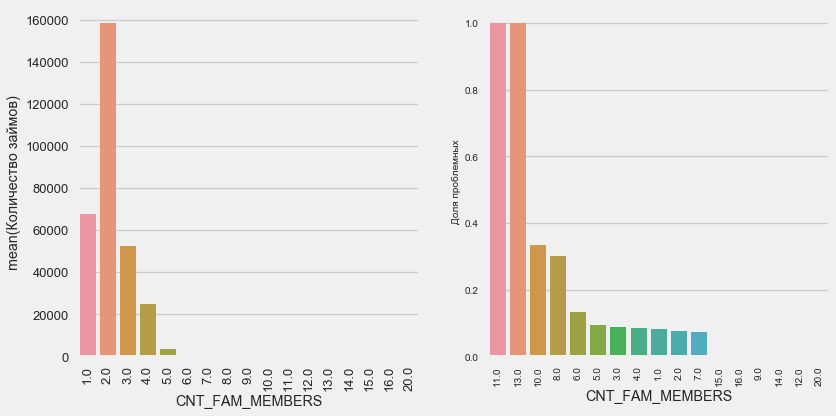
情况类似-嘴越少,回报就越高。
收入类型
plot_stats('NAME_INCOME_TYPE',False,False)
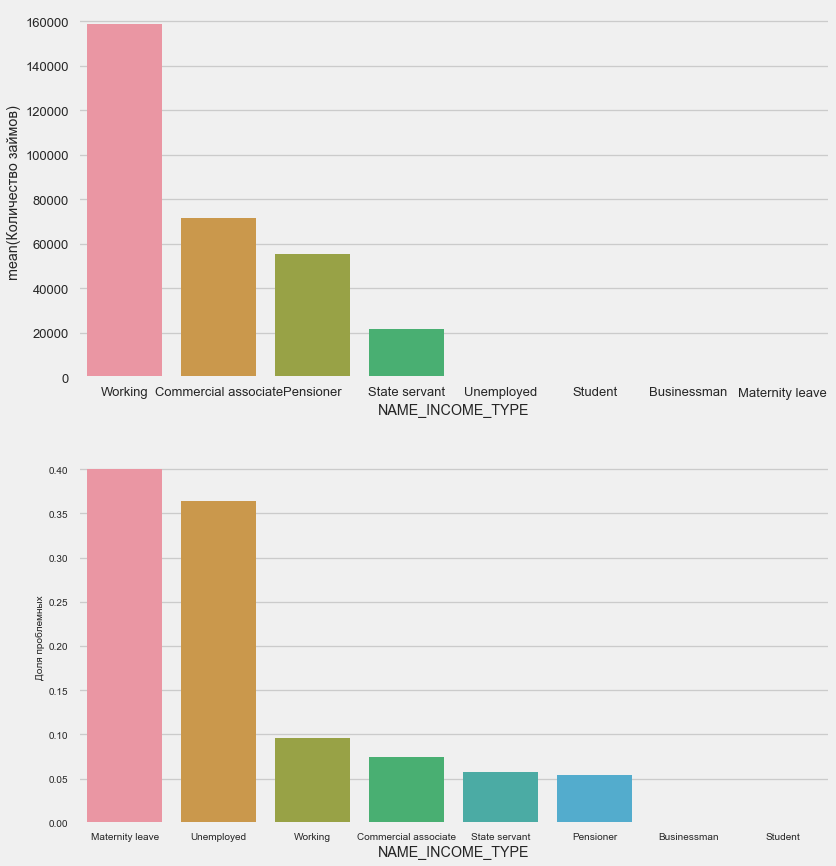
在申请阶段,单身母亲和失业者很可能会被裁掉-样本中她们太少了。 但是问题正在稳定显示。
活动类型
plot_stats('OCCUPATION_TYPE',True, False)
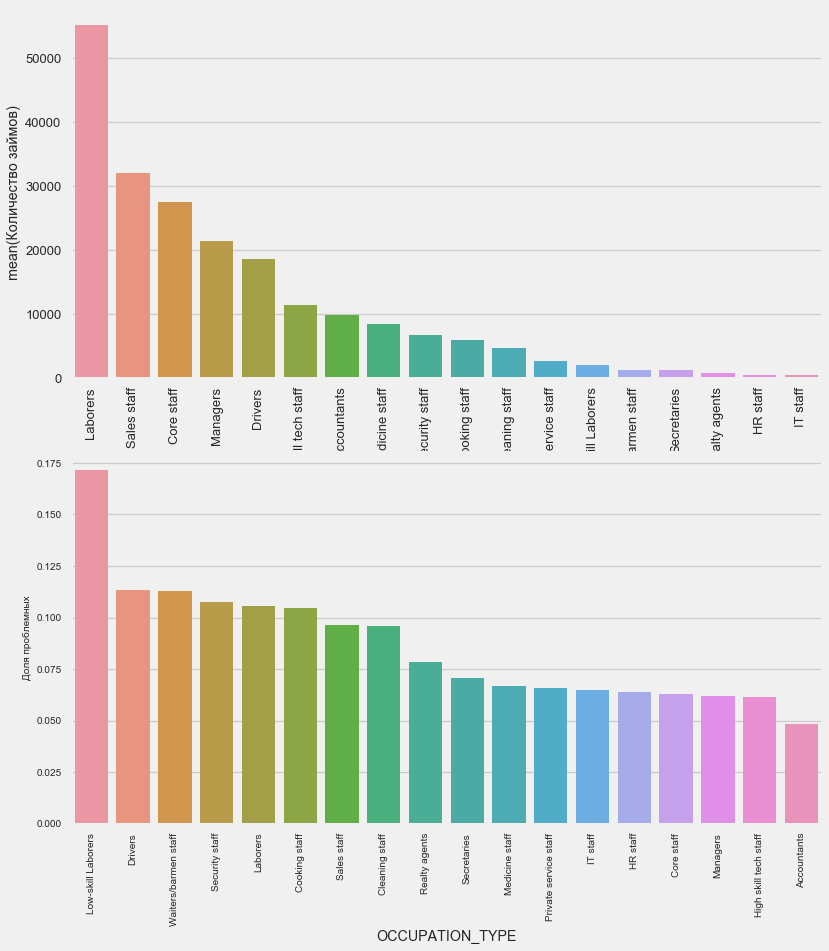
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64与其他类别的驾驶员和安全员相比,这些驾驶员和安全员人数众多且面临更多的问题,这是他们感兴趣的。
学历
plot_stats('NAME_EDUCATION_TYPE',True)
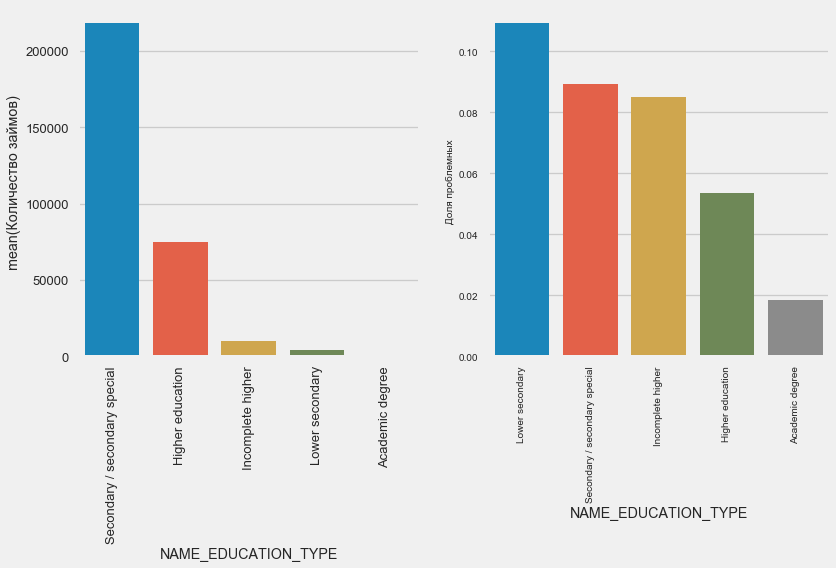
显然,教育程度越高,复发率越好。
组织类型-雇主
plot_stats('ORGANIZATION_TYPE',True, False)
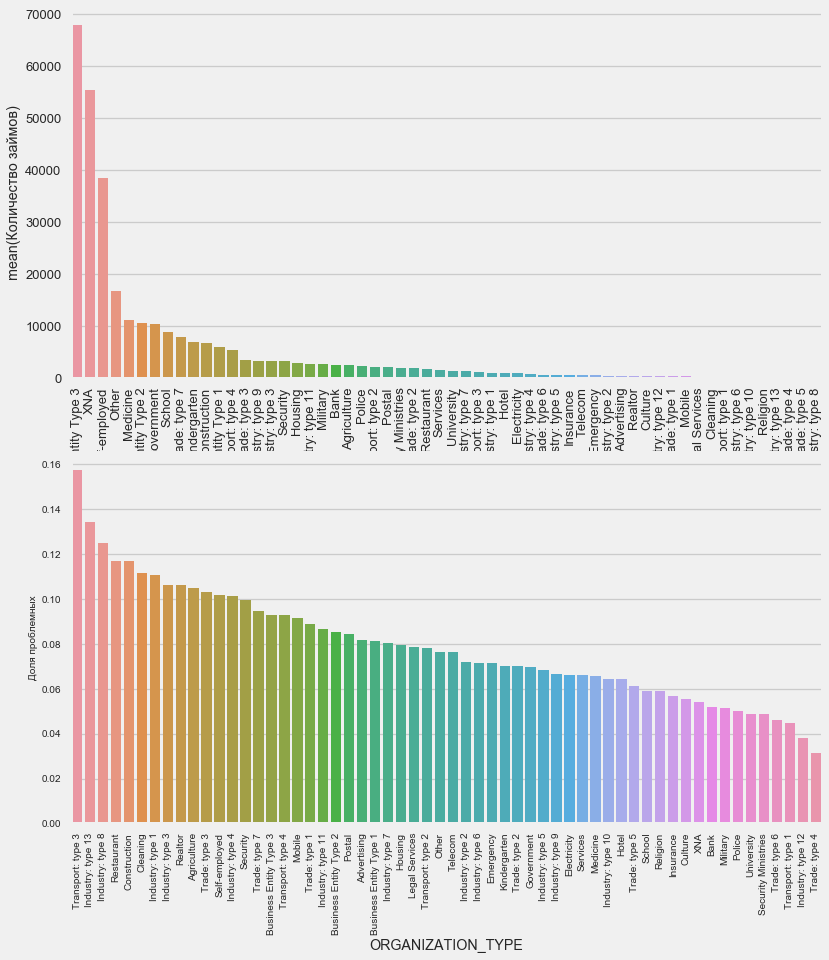
在运输:类型3(16%),行业:类型13(13.5%),行业:类型8(12.5%)和餐厅(高达12%)中观察到最高的不归还百分比。
贷款分配
考虑贷款额的分配及其对还款的影响
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
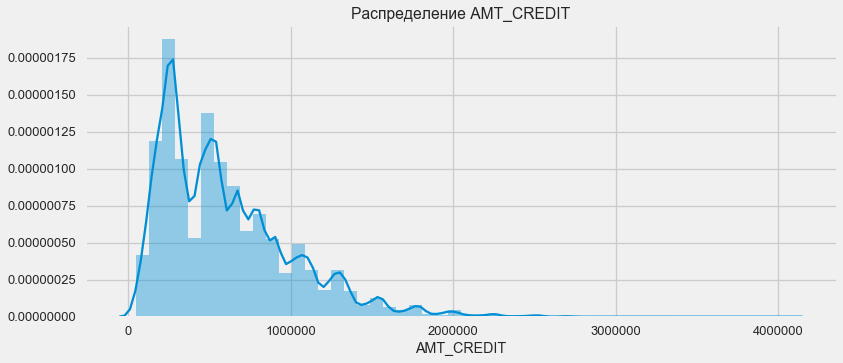
plt.figure(figsize=(12,5))
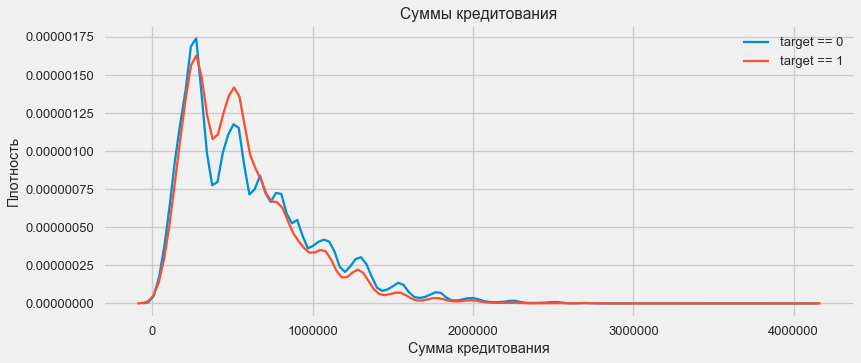
如密度图所示,坚固的数量返还率更高
密度分布
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
plt.figure(figsize=(12,5))
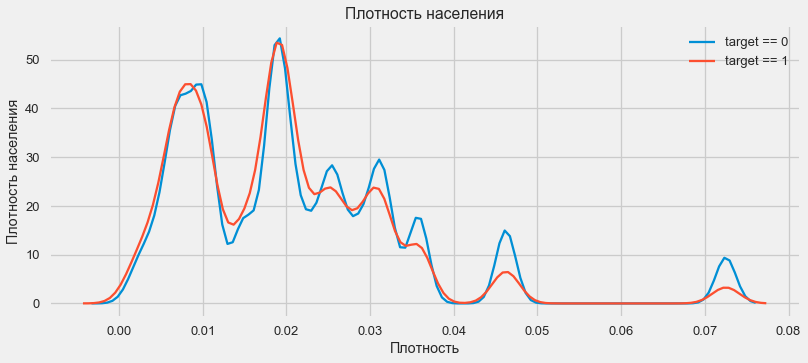
来自人口稠密地区的客户倾向于更好地偿还贷款。
因此,我们了解了数据集的主要特征及其对结果的影响。 我们不会对本文中列出的内容做任何具体的处理,但是它们可能在以后的工作中变得非常重要。
特征工程-特征转换
Kaggle的比赛是通过符号转换赢得的-可以从数据获胜中创建最有用的符号的竞赛。 至少对于结构化数据而言,胜出模型现在基本上是不同的梯度增强选项。 与设置超参数或选择模型相比,花时间转换属性通常更有效。 模型仍然只能从已传输到模型的数据中学习。 确保数据与任务相关是科学家约会的主要责任。
转换特征的过程可能包括创建新的可用数据,选择最重要的可用数据等。 这次我们将尝试多项式符号。
多项式符号
构造特征的多项式方法是,我们仅创建特征,即可用特征及其乘积的程度。 在某些情况下,此类构造的特征与目标变量的关联可能比其“父代”更强。 尽管此类方法通常用于统计模型中,但在机器学习中却很少见。 但是 没有什么可以阻止我们尝试它们的,特别是因为Scikit-Learn具有专门用于这些目的的类-PolynomialFeatures-创建多项式特征及其乘积,您只需要指定原始特征本身以及将其提高到的最大程度即可。 我们对4个属性和3级的结果使用最强大的效果,以免使模型过于复杂并避免过度拟合(模型过度训练-对训练样本的过度调整)。
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']共有35个多项式和导数特征。检查它们与目标的相关性。
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64因此,有些迹象表明相关性高于原始迹象。尝试在没有它们的情况下进行学习是有意义的(就像在机器学习中一样,这可以通过实验确定)。为此,请创建数据框的副本并在其中添加新功能。
: (307511, 277)
: (48744, 277)模型训练
基本水平
在计算中,您需要从模型的某些基本层次开始,然后再降至该基础层次即可。在我们的例子中,对于所有测试客户而言,这可能是0.5-这表明我们完全不知道客户是否会偿还贷款。在我们的案例中,初步工作已经完成,可以使用更复杂的模型。逻辑回归
要计算逻辑回归,我们需要获取具有编码分类特征的表,填写缺失的数据并对其进行规范化(将其设置为0到1的值)。所有这些都执行以下代码: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)我们使用Scikit-Learn的逻辑回归作为第一个模型。让我们采用一次校正的偏差模型-我们降低正则化参数C以避免过度拟合。语法是正常的-我们创建模型,对其进行训练,并使用predict_proba预测概率(我们需要概率,而不是0/1) from sklearn.linear_model import LogisticRegression
现在,您可以创建一个文件上传到Kaggle。根据客户ID和无退货的可能性创建一个数据框并上传。 submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
因此,我们的泰坦尼克号工作结果为:0.673,今天的最佳结果是0.802。改进模型-随机森林
Logreg表现不佳,让我们尝试使用改进的模型-随机森林。这是一个功能更强大的模型,可以构建数百棵树并产生更准确的结果。我们使用100棵树。使用该模型的方案是完全相同的,完全标准的-加载分类器,训练。预测。 from sklearn.ensemble import RandomForestClassifier
随机森林效果略好-0.683具有多项式特征的训练模型
现在我们有了一个模型。至少可以做些什么-是时候测试我们的多项式符号了。让我们对它们进行相同的操作并比较结果。 poly_features_names = list(app_train_poly.columns)
具有多项式特征的随机森林的结果变得更糟-0.633。这极大地质疑了使用它们的必要性。梯度提升
梯度提升是机器学习的“严肃模型”。几乎所有最新比赛都被“拖延”了。让我们建立一个简单的模型并测试其性能。 from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
LightGBM的结果是0.735,它落后于所有其他模型。模型解释-属性的重要性
解释模型的最简单方法是查看特征的重要性(并非所有模型都能做到)。由于我们的分类器处理了数组,因此将需要一些工作来根据此数组的列重新设置列名。
正如预期的那样,最重要的是所有相同的4个功能建模。属性的重要性并不是模型解释的最佳方法,但是它可以让您了解模型用于预测的主要因素feature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
从其他表添加数据
现在,我们将仔细考虑其他表以及如何使用它们。立即开始准备表格以备进一步培训。但是首先,从内存中删除过去的大量表,使用垃圾回收器清除内存,然后导入进行进一步分析所需的库。 import gc
导入数据,立即在单独的列中删除目标列 data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
立即对分类特征进行编码。我们之前已经这样做过,我们分别对训练样本和测试样本进行编码,然后对齐数据。让我们尝试一种稍微不同的方法-我们将找到所有这些分类符号,合并数据帧,从找到的列表中进行编码,然后再次将样本分为训练和测试样本。 categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)信贷局每月贷款余额的数据。
buro_balance.head()
 MONTHS_BALANCE-贷款申请日期之前的月数。仔细看看“状态”
MONTHS_BALANCE-贷款申请日期之前的月数。仔细看看“状态” buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64状态表示以下含义:-已关闭,即已偿还的贷款。X是未知状态。0-当前贷款,没有拖欠。1-延迟1-30天,2-延迟31-60天,依此类推,直到状态5-贷款出售给第三方或注销。例如,在这里可以区分以下符号:buro_grouped_size-数据库中的条目数buro_grouped_max-最大贷款余额buro_grouped_min-最小贷款余额可以对所有这些贷款状态进行编码(我们使用unstack方法,然后将接收到的数据附加到buro表中,因为SK_ID_BUREAU在这里和那里是相同的。 buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
有关征信机构的一般信息
buro.head()
 (显示了前7列)通常,您可以尝试使用One-Hot-Encoding进行简单地编码,按SK_ID_CURR分组,取平均值,并以相同的方式准备与主表的连接。
(显示了前7列)通常,您可以尝试使用One-Hot-Encoding进行简单地编码,按SK_ID_CURR分组,取平均值,并以相同的方式准备与主表的连接。 buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
有关先前申请的数据
prev.head()
 同样,我们对分类特征进行编码,对当前ID求平均值并合并。
同样,我们对分类特征进行编码,对当前ID求平均值并合并。 prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
信用卡余额
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64我们对分类特征进行编码,并准备要合并的表 le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
卡数据
credit_card.head()
 (前7列)类似的工作
(前7列)类似的工作 credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
付款资料
payments.head()
 (显示前7列)让我们创建三个表-包含该表的平均值,最小值和最大值。
(显示前7列)让我们创建三个表-包含该表的平均值,最小值和最大值。 avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
表联接
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)而且,实际上,我们将通过梯度增强功能使这张桌子翻倍! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
结果是0.770。好的,最后,让我们尝试一种更复杂的技术,将其折叠,交叉验证并选择最佳迭代。 folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845kaggle 0.783的最终得分接下来要去哪里
绝对会继续使用标志。浏览数据,选择一些标志,将它们组合,并以其他方式附加表格。您可以尝试使用超参数Mogheli-很多指南。我希望这个小编着为您展示研究数据和准备预测模型的现代方法。学习数据,参加比赛,变酷!并再次链接到帮助我编写本文的内核。这篇文章也以笔记本电脑的形式发布在Github上,您可以下载它,数据集并运行和试验。威尔·柯尔森。从这里开始:温和的介绍禁令。 HomeCreditRisk:广泛的EDA +基准[0.772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM