预处理是在传输数据模型之前对数据执行的所有操作的总称,包括居中,归一化,平移,旋转,修剪等。通常,在两种情况下需要进行预处理。
- 数据清理 。 假设图像中存在一些伪像。 为了促进模型训练,必须在预处理阶段删除工件。
- 数据加法 。 有时,小的数据集不足以进行高质量的深度模型训练。 数据补充方法对于解决此问题非常有帮助。 这是以各种方式转换每个数据样本并将此类修改后的样本添加到数据集的过程。 这样,可以增加数据集的有效大小。
让我们考虑一下预处理过程中的一些可能的转换方法,以及它们通过Keras实施的方法。

资料
在本文和后续文章中,将使用数据集来分析图像的情感色彩。 它包含1,500个图像示例,分为正反两类。 让我们看一些例子。
 负面的例子
负面的例子 积极的例子
积极的例子清洗转换
现在考虑一组通常用于清理数据,其实现和对图像的影响的可能转换。
所有代码段都可以在
Preprocessing.ipynb一书中找到。
重新缩放
图像通常以RGB(红色绿色蓝色)格式存储。 以这种格式,图像由三维(或三通道)阵列表示。
 图像的RGB分解。 图表取自Wikiwand
图像的RGB分解。 图表取自Wikiwand一个维度用于渠道(红色,绿色和蓝色),另外两个维度代表位置。 因此,每个像素用三个数字编码。 每个数字通常存储为8位无符号整数类型(0到255)。
重新定标是通过简单地将数据除以预定常数来更改数据数值范围的操作。 在深度神经网络中,由于可能的溢出,优化问题,稳定性等,可能有必要将输入数据限制为0到1的范围。
例如,我们从[0; 255]到[0; 1]。 在下文中,我们将使用Keras
ImageDataGenerator类,该类允许您即时执行所有转换。
让我们创建该类的两个实例:一个用于转换后的数据,另一个用于源:

(或用于默认数据)。 只需要指定比例常数。 此外,
ImageDataGenerator类允许您使用
flow_from_directory方法直接从硬盘驱动器上的文件夹中流式传输数据。
所有参数都可以在
文档中找到,但是主要参数包括:流的路径和目标图像大小(如果图像与目标大小不匹配,则生成器将对其进行剪切或构建)。 最后,我们从生成器中获取样本并考虑结果。
在视觉上,两个图像都是相同的,但这是因为Python *工具会自动调整图像大小
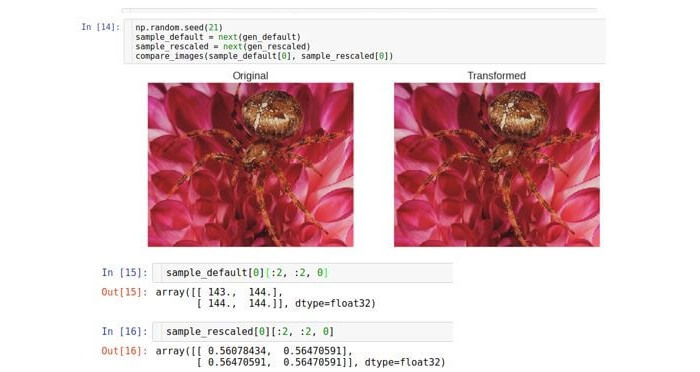
到默认范围,以便它们可以显示在屏幕上。 考虑原始数据(数组)。 如您所见,原始地块相差255倍。
灰阶
另一种可能有用的转换是
灰度 ,它将彩色RGB图像转换为所有颜色均以灰色阴影表示的图像。 常规图像处理可以结合随后的阈值使用灰度转换。 这对变换可以拒绝噪点像素并定义图像中的形状。 今天,所有这些操作都是由卷积神经网络(CNN)执行的,但是将灰度转换作为预处理步骤仍然有用。 使用相同的生成器类在Keras中运行此步骤。
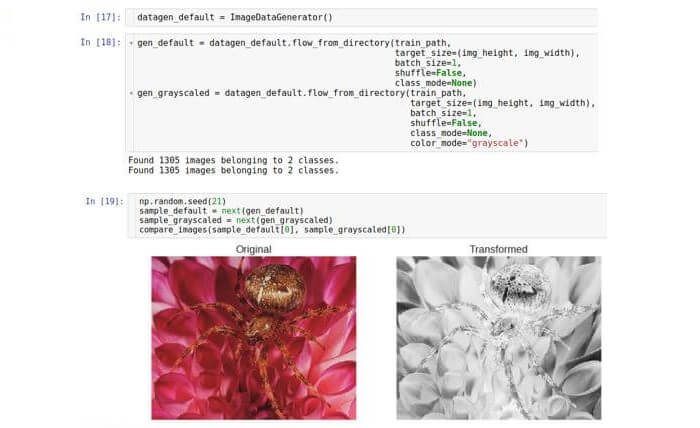
在这里,我们仅创建该类的一个实例,并从中获取两个不同的生成器。 第二个生成器将
color_mode参数设置为“灰度”(默认值为“ RGB”)。
居中样本
我们已经看到原始数据的值在从0到255的范围内。因此,一个样本是从0到255的三维数字数组。根据优化的稳定性原理(摆脱值消失或饱和的问题),
可能有必要对数据集进行标准化因此每个数据样本的平均值为0 。
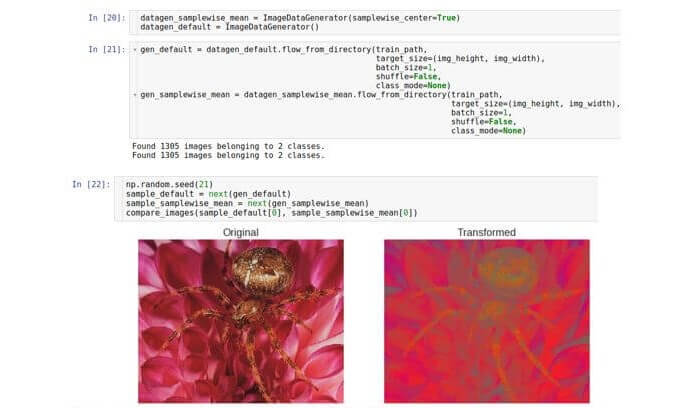
为此,有必要计算整个样本的平均值,然后从给定样本中的每个数字中减去该平均值。
在Keras中,这是使用
samplewise_center参数完成的。
样品标准偏差的归一化
此预处理阶段基于与样本居中相同的思想,但不是将平均值从设置为0,而是将标准偏差设置为1。
 标准
标准偏差的归一化由参数
samplewise_std_normalization控制。 应该注意的是,这两种标准化样本的方法经常一起使用。
此转换可用于深度学习模型中,以通过减少爆炸梯度的影响来提高优化稳定性。
功能中心
前两节使用归一化技术来查看每个单独的数据样本。 标准化过程还有另一种方法。 将图像数组中的每个数字视为一个符号。 那么
每个图像都是一个特征向量 。 数据集中有许多这样的向量。 因此,我们可以将它们视为未知
分布 。 此分布是多参数的,其尺寸将等于要素的数量,即宽度×高度×3。尽管数据的真实分布是未知的,但您可以尝试通过减去平均分布值来对其进行归一化。 应当注意,平均值是相同维度的向量,即,它也是图像。 换句话说,我们对整个数据集求平均值,而不是对一个样本求平均值。
有一个特殊的
Keras参数,称为
featurewise_centering ,但不幸的是,截至2017年8月,其实现存在错误; 因此,我们自己实施。 首先,我们考虑内存中的整个数据集(我们可以负担得起,因为我们要处理的是很小的数据集)。 为此,我们将数据包大小设置为数据集的大小。 然后,我们在整个数据集上计算平均图像,最后从测试图像中减去它。
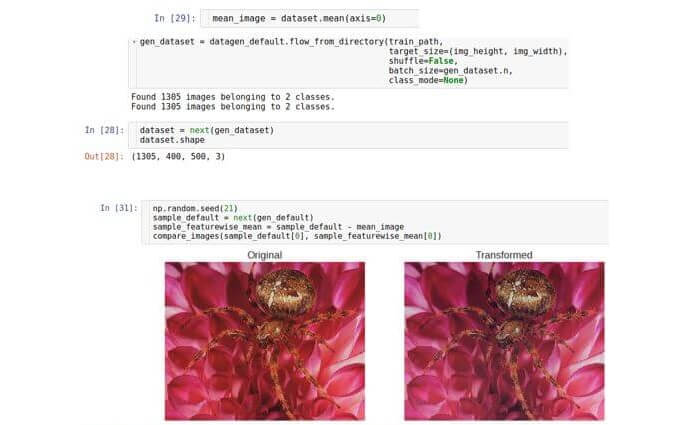
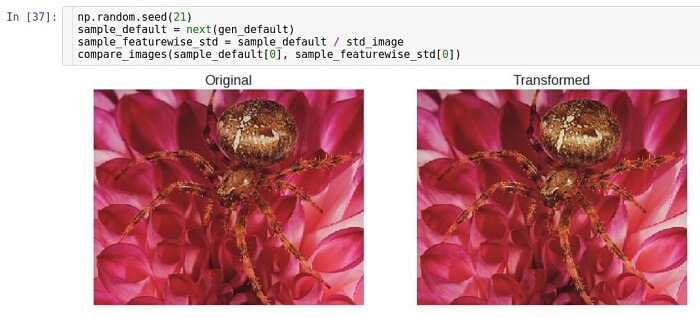
症状标准差的标准化
标准化标准差的想法与定心的想法完全相同。 唯一的不同是,我们不减去平均值,而是除以标准差。 在视觉上,结果没有太大不同。 发生了同样的事情

在重新缩放期间,由于标准偏差的归一化只不过是通过按某种方式计算的常数进行重新缩放,而对于简单的重新缩放,则手动指定该常数。 请注意,标准化数据包的类似想法是称为
BatchNormalization的现代深度学习技术的
核心 。
转型加法
在本节中,我们研究了几个依赖于数据的转换,这些转换明确地使用了数据的图形特性。 这些类型的转换通常在数据添加过程中使用。
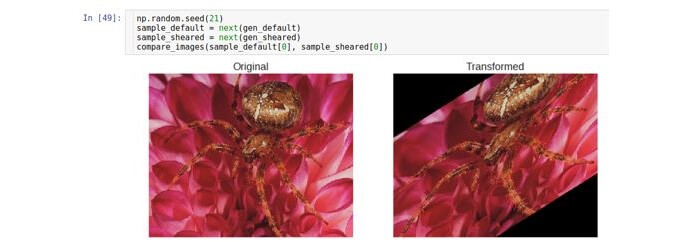
旋转角度
这种类型的变换会沿特定方向(顺时针或逆时针)旋转图像。
允许旋转的参数称为
rotation_range 。 它表示以均匀分布随机选择旋转角度的度数范围。 应该注意的是,在旋转过程中,图像尺寸不会改变。 因此,图像的某些部分可以被裁剪并填充一些。
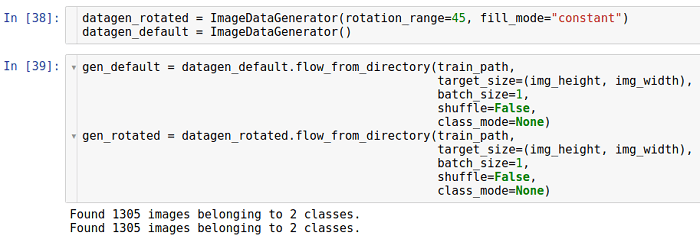
使用
fill_mode参数设置填充模式。 它支持各种填充方法,但是在这里我们以
常量方法为例。
水平移位
这种类型的变换会沿水平轴(左或右)在某个方向上移动图像。

移位的大小可以使用
width_shift_range参数确定,并作为总图像宽度的一部分进行测量。
垂直移位
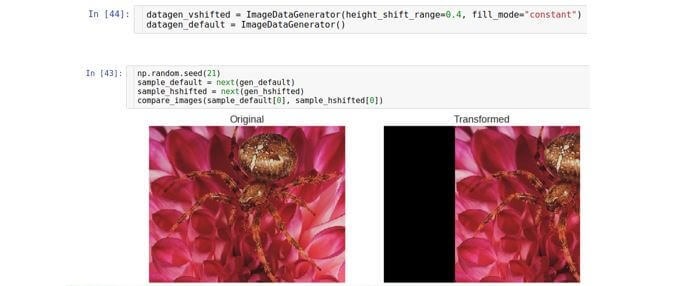
沿垂直轴(上或下)移动图像。 控制偏移范围的参数称为
height_shift生成器,并且也作为图像总高度的一部分进行测量。
修剪
裁剪转换或裁剪将每个点在垂直方向上移动与从该点到图像边缘的距离成比例的量。 注意,在通常情况下,方向不一定是垂直的,而是任意的。
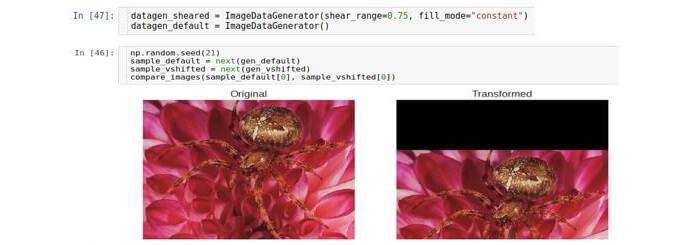
控制位移的参数称为
剪切范围 ,它对应于原始图像中的水平线与转换后图像中该线的图像(在数学意义上)之间的偏离角度(以弧度为单位)。
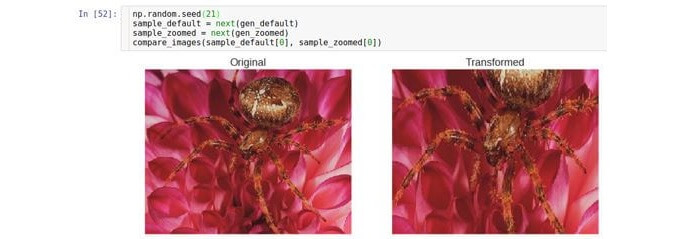
放大/缩小

这种类型的变换会近似或删除原始图像。
zoom_range参数控制缩放系数。
例如,如果
zoom_range为0.5,则将从范围[
0.5,1.5 ]中选择缩放系数。
水平翻转

相对于垂直轴翻转图像。 可以使用
horizontal_flip参数将其打开或关闭。
垂直翻转

围绕水平轴翻转图像。
vertical_flip参数(布尔类型)控制此转换的存在与否。
组合式
我们同时应用补全的所有上述转换类型,然后看看会发生什么。 回想一下,所有转换的参数都是从一定范围内随机选择的; 因此,我们必须获得一组具有高度多样性的样本。
我们使用所有可用参数启动
ImageDataGenerator并检查图像上的红色消火栓。

请注意,
恒定填充模式仅用于更好的可视化。 现在我们将使用一种更高级的填充模式,称为
Nearest ; 此模式将最接近的现有像素的颜色分配给空白像素。
结论
本文概述了图像预处理的基本技术,例如:缩放,归一化,旋转,移动和裁剪。 他们还演示了使用Keras的这些转换技术的实现以及它们在技术上(
ImageDataGenerator类)和意识形态上(数据补充)的深度学习过程介绍。